
LLM架构机制管窥:作为黑板的上下文窗口
本文是【LLM架构管窥 ◆ 系列小文】的第2篇。 【LLM架构管窥 ◆ 系列小文】旨在快速盘点LLM架构特点、特别是局限性,为后续【基于SDD的AI编程最佳实践】提供必要的认知准备。 --- ## 一、黑板架构模式 黑板模型是人工智能领域典型的结构模式,由黑板、知识源和控制组件构成,最初由美国Carnegie-Mellon大学于1973-1976年在HEARSAY-II语音识别系统中提出。 黑板架构模式是一种模仿多个专家系统协作解决问题的软件架构。其核心包含三个关键要素: 1. **黑板**:作为系统的核心数据结构,是一个共享的全局内存。它存储问题的当前状态、中间结果和最终解决方案,所有知识源都可以读取和写入黑板上的数据,但通常通过控制组件进行协调。 2. **知识源**:代表解决问题的不同策略和算法,每个知识源都是独立的模块,负责处理黑板上的一部分信息,并将结果写回黑板。知识源之间不直接通信,而是通过黑板进行间接协作。 3. **控制组件**:负责管理知识源的执行顺序,根据黑板的状态动态选择最合适的模块在当前状态下执行。控制策略可以是优先级驱动、数据依赖驱动等,以适应不同的求解路径。 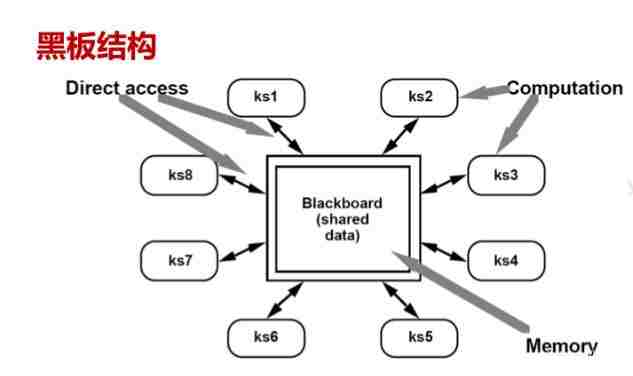 --- ## 二、上下文窗口 as 黑板 大型语言模型(LLM)在自然语言处理领域取得了巨大成功,其强大的文本生成、理解和推理能力令人瞩目。然而,LLM内部复杂的运算机制,尤其是上下文的处理方式,一直是探索改进的热点方向。 黑板架构模式作为一种经典的软件架构思想,在解决复杂、非结构化问题时展现出强大的协作与信息整合能力。将LLM的上下文与黑板架构模式相结合进行理解,有助于我们探索 LLM内部上下文管理 的改进方向。 借个图,来源:https://blog.csdn.net/qq_40762280/article/details/154998469?spm=1001.2014.3001.5502 <div align="center"><img src="https://developer.qcloudimg.com/http-save/yehe-11563618/13dddca0bdd8e834bdd436e2434f04b6.png" width="50%"></div> LLM的上下文整合了输入数据的各种特征和模型生成的信息。例如,每个注意力头(attention head)关注输入数据的不同方面,类似于不同的知识源采用不同的策略处理黑板上的信息。 不同的隐藏层可能负责提取不同层次的语义特征,类似于不同的知识源专注于解决问题的不同子任务。它们在处理上下文信息时,具有各自的特定功能和运算规则。 LLM的上下文是一组动态变化的数据,它贯穿于模型处理输入数据的整个过程。在模型生成文本、回答问题等任务中,上下文不断更新,为模型提供当前任务所需的信息。从某种意义上说,LLM的上下文就如同一个不断演变的“信息容器”或“黑板”,承载着模型处理问题的关键线索。 在Transformer架构中,上下文信息通过自注意力机制在各个隐藏层之间传递,类似于知识源从黑板上读取信息并进行处理后再写回黑板。 ## 三、上下文窗口黑板模式的优点 #### 3.1 问题求解的渐进性 系统通过知识源不断地对黑板数据进行更新和完善,逐步逼近问题的解。LLM就是这种渐进式的求解方式。 #### 3.2 知识的独立性和封装性 每个知识源都是独立的模块,封装了自己的知识和处理逻辑。它们只需要关注自己所负责的任务和黑板上与自己相关的数据,降低了系统的复杂性和耦合度。 #### 3.3 灵活性和可扩展性 便于引入更多“知识源”(MoE LLM中引入采用新算法的Expert),以增强模型处理复杂任务的能力。 <div align="center"><img src="https://developer.qcloudimg.com/http-save/yehe-11563618/d282637cfb7b3df3b02199a47899f7f9.jpg" width="60%"></div> --- ## 四、“上下文”在LLM各层眼中的样子(逻辑含义) * 高层(深层FFN附近):上下文 = 语义逻辑与意图。 * Token已经高度抽象化,不再是具体的词,而是“概念”。 * 例子:模型不再关注具体的字,而是理解了用户在“询问理财建议”,并调动相关的知识库。 * 中层(Attention层):上下文 = 句法结构与指代。 * 模型开始解决代词指代(“它”指“银行”)、修饰关系(“红色的”修饰“苹果”)。 * 例子:如果上文有“取钱”,模型知道这个“银行”是金融机构。 * 底层(Embedding层附近):上下文 = 邻居。 * 模型只看到字面相邻的Token。 * 例子:看到“银行”,不知道是河岸还是取钱的地方。 <div align="center"><img src="https://developer.qcloudimg.com/http-save/yehe-11563618/b56fe4e8f5e91d19e1b65df51c63c155.jpg" width="50%"></div> --- ## 五、LLM 各层处理“上下文”的技术原理 1. **物理载体统一**:从Embedding层到高层FFN,数据的存储和运算形态都是向量/矩阵,区别仅在于向量**语义编码的丰富度**。 2. **语义分层递进**:底层向量只编码字面和相邻信息,中层融入句法与指代关联,高层则升维到逻辑与意图,是一个**从“字面”到“抽象”**的过程。 3. **向量的增量信息补充**:LLM的前向传播过程,本质就是**向量不断吸收新信息、更新语义表征**的过程——后续层的运算会基于前一层向量,叠加新的关联特征,最终让向量的语义更完整、更精准。 #### 向量增量补充信息的例子:**“红色的苹果很好吃”** 中的`苹果`向量 | 层级 | 向量的信息增量 | 最终语义 | |------|----------------|----------| | 底层 | 字面特征(苹果=水果名词)+ 邻居(红色的、很) | 一个被“红色的”修饰的名词 | | 中层 | 补充修饰关系(红色的→苹果) | 红色的、作为食物的苹果 | | 高层 | 补充逻辑(好吃→苹果的属性) | 具有“红色、可食用、美味”属性的水果 | #### 向量增量补充信息的例子:**“我去银行取钱,它的利率很高”**中的`银行`向量 我们以**“我去银行取钱,它的利率很高”**这句话中的`银行`向量为例,拆解其在各层的信息增量过程: #### 1. **Embedding层(底层):初始向量仅含字面+邻居信息** - 输入Token序列:`我` `去` `银行` `取` `钱` `,` `它` `的` `利` `率` `很` `高` - `银行`的初始向量:仅编码了 **“银行”这个词的字面特征** + **相邻Token(去、取)的字面关联**。 - 此时向量的语义:**无法区分“金融银行”还是“河岸”**,仅知道它是一个名词,前后是动作“去”和“取”。 - 信息增量状态:**无额外关联信息,语义最单薄**。 #### 2. **Attention层(中层):向量补充“指代+句法”信息** - Attention机制会计算Token间的关联权重: - 发现`它`和`银行`的注意力权重极高 → 确定`它`指代`银行`; - 发现`取钱`与`银行`的关联度高于其他词 → 强化“银行”和“取钱”的动作绑定。 - `银行`的向量更新:在底层向量基础上,**增量融入“指代关系(它→银行)”和“动作关联(取钱→银行)”**。 - 此时向量的语义:**明确“银行”是“可以取钱的金融机构”**,彻底排除“河岸”的歧义。 - 信息增量状态:**补充了句法和指代信息,语义消除歧义**。 #### 3. **深层FFN层(高层):向量补充“逻辑+意图”信息** - FFN(前馈网络)会基于Attention输出的向量,结合模型预训练的知识库,进一步抽象: - 从“取钱”“利率”这些特征,关联到“金融服务”“储蓄业务”等概念; - 结合整句话的逻辑,推断出用户的意图是 **“提及一家利率高的金融银行”**。 - `银行`的向量更新:在中层向量基础上,**增量融入“金融业务属性”和“用户意图关联”**。 - 此时向量的语义:**不再是单纯的“金融机构”,而是“与用户取钱需求相关、利率有吸引力的金融机构”**。 - 信息增量状态:**补充了逻辑和意图信息,语义升维到概念层面**。 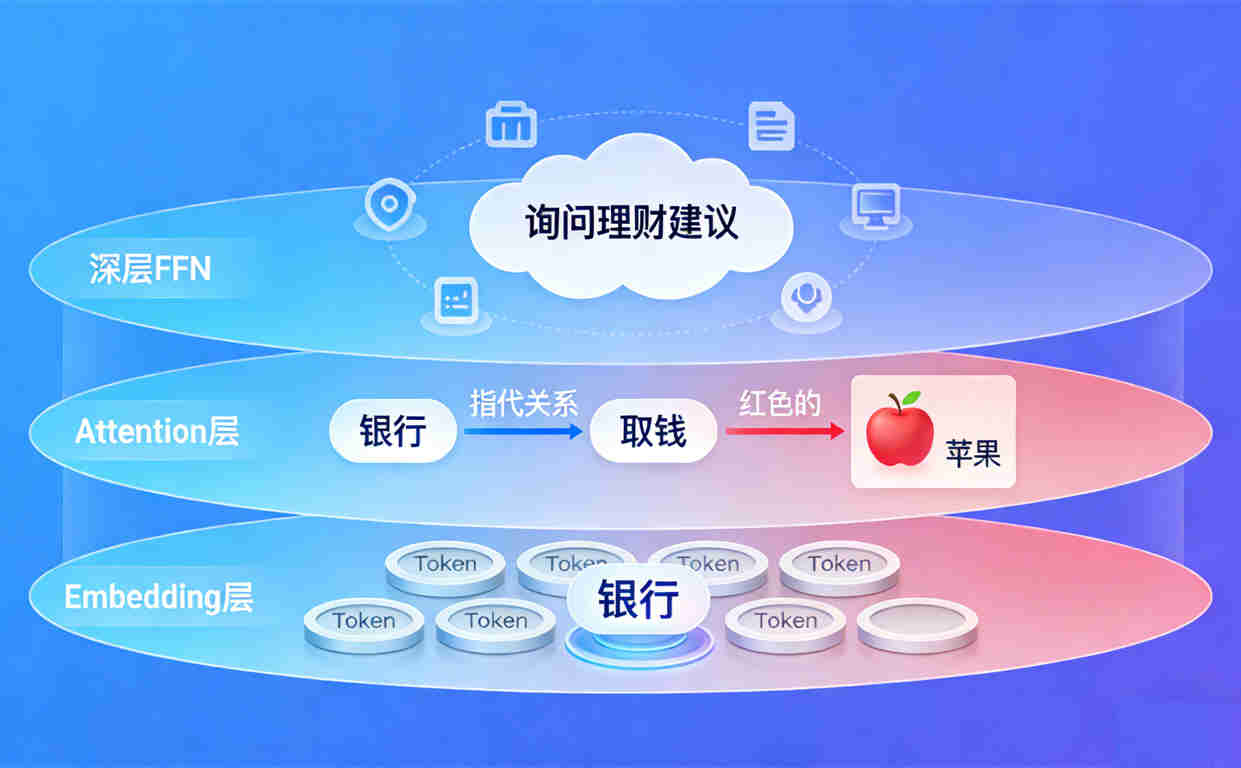
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号