
openGauss 核心体系架构深度解析
openGauss 是一款高性能、高安全、高可靠的企业级开源关系型数据库。要掌握它的运维与调优,必须深入理解其底层的体系结构。本文将从配置文件、逻辑架构、内存结构和存储结构四个维度进行详细剖析。  ## <font color="navy">一、关键配置文件</font> 在启动数据库之前,我们首先要关注两个决定数据库行为的核心文件,它们通常位于数据目录下。 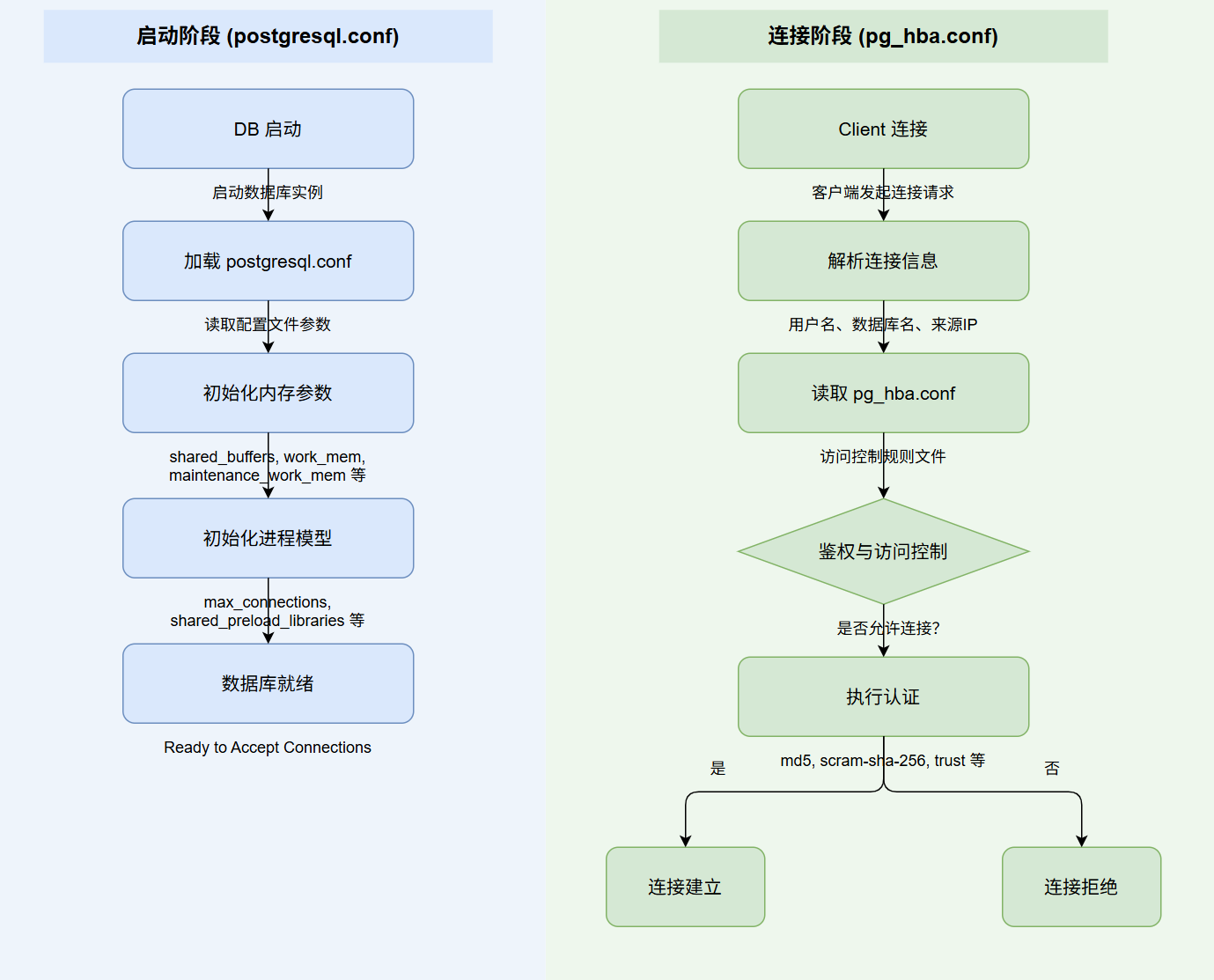 ### <font color="purple">1. 核心参数配置</font> 这是数据库的==总控文件==,相当于人的心脏 **作用**:决定了数据库的<font color="blue">内存分配</font>如 shared_buffers、<font color="green">连接限制</font>如 max_connections、<font color="purple">日志记录</font>以及<font color="teal">端口监听</font>等全局行为 **生效机制**:修改此文件中的大部分参数(尤其是涉及内存和端口的)需要<font color="darkred">重启</font>数据库才能生效,部分参数可通过 `reload` 在线生效 ### <font color="purple">2. 客户端认证策略</font> 这是数据库的==门卫文件==,全称为 Host-Based Authentication **作用**:它严格定义了<font color="olive">允许</font>哪些客户端 IP、通过什么<font color="brown">认证方式</font>如 md5, sha256, trust、访问哪个<font color="navy">数据库</font>以及使用哪个<font color="saddlebrown">用户名</font> **重要性**:配置错误会导致拒绝连接或产生严重的安全漏洞 ## <font color="navy">二、逻辑架构与进程结构</font> openGauss 的逻辑架构设计非常清晰,各组件分工明确,共同支撑起庞大的数据处理请求。 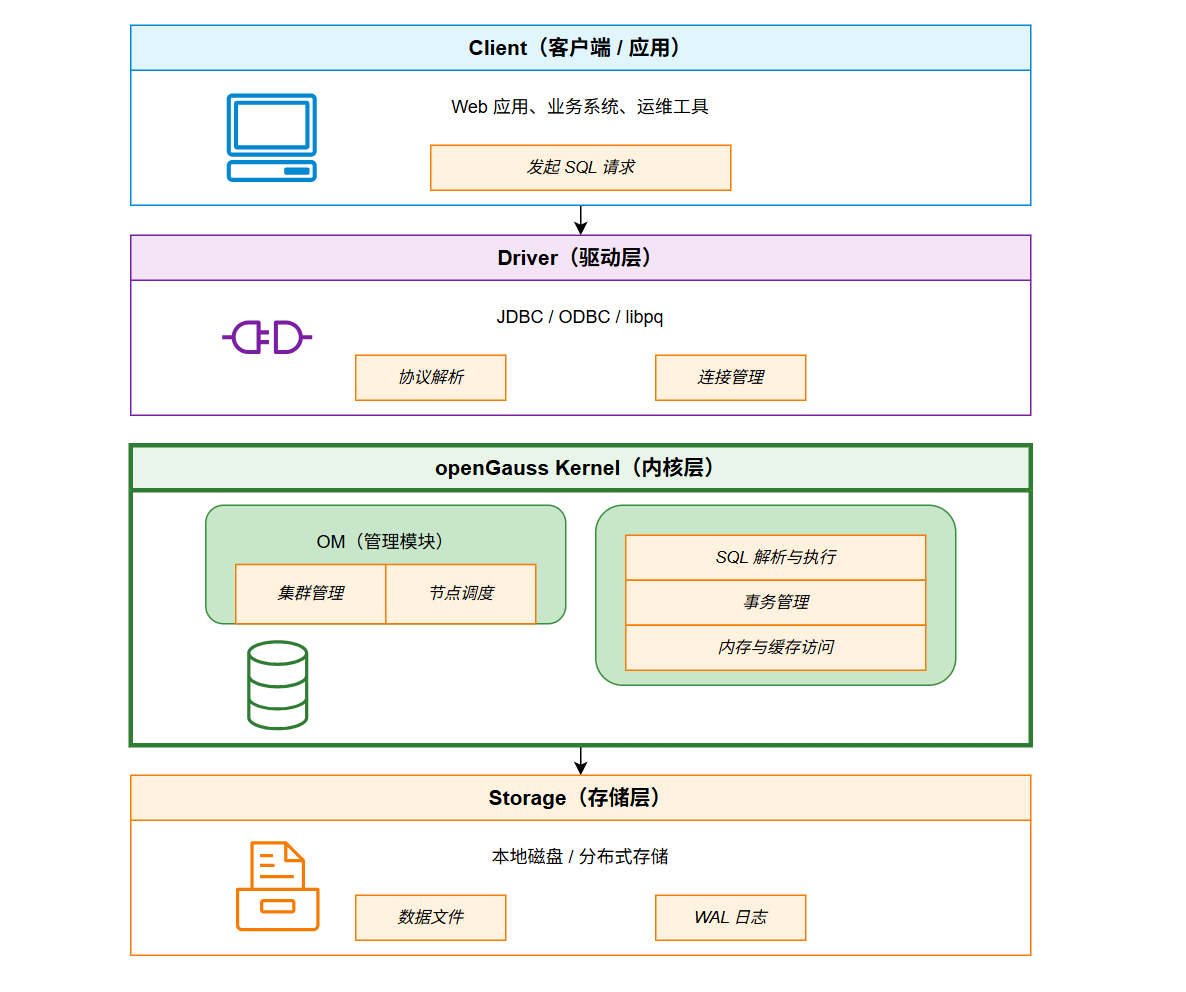 ### <font color="purple">1. OM</font> **角色**:<font color="darkgreen">大管家</font> **功能**:提供数据库<font color="darkcyan">日常运维</font>和<font color="orange">配置管理</font>的接口与工具 **场景**:我们日常使用的 `gs_om` 命令就是该模块的体现,用于执行集群的<font color="blue">启动</font>、<font color="red">停止</font>、<font color="purple">状态查询</font>等操作 ### <font color="purple">2. Client Driver</font> **角色**:<font color="darkgreen">联络员</font> **功能**:负责接收来自<font color="teal">应用层</font>的访问请求,并向应用返回执行结果 **机制**:它负责与 openGauss 实例建立<font color="navy">通信链路</font>,发送 SQL 命令。常见的驱动包括 JDBC、ODBC 和 Python 驱动 ### <font color="purple">3. Datanode</font> **角色**:<font color="darkgreen">核心工兵</font> **功能**:负责<font color="brown">存储</font>业务数据、执行<font color="firebrick">数据查询</font>任务 **高可用架构**:实例包含<font color="red">主Primary</font>、<font color="green">备 Standby</font>两种类型 **部署建议**:为了实现高可用,建议将主、备实例<font color="darkcyan">分散部署</font>在不同的<font color="darkslategray">物理节点</font>中,防止单点故障。 ### <font color="purple">4. Storage</font> **角色**:<font color="darkgreen">仓库</font> **功能**:指服务器的<font color="olive">本地存储资源</font>(即物理磁盘),用于<font color="saddlebrown">持久化</font>存储数据。 --- ## <font color="navy">三、内存结构:速度的桥梁</font> 内存是数据库性能的关键瓶颈所在,它充当了<font color="darkred">慢速磁盘</font>与<font color="darkgreen">快速 CPU</font> 之间的桥梁。 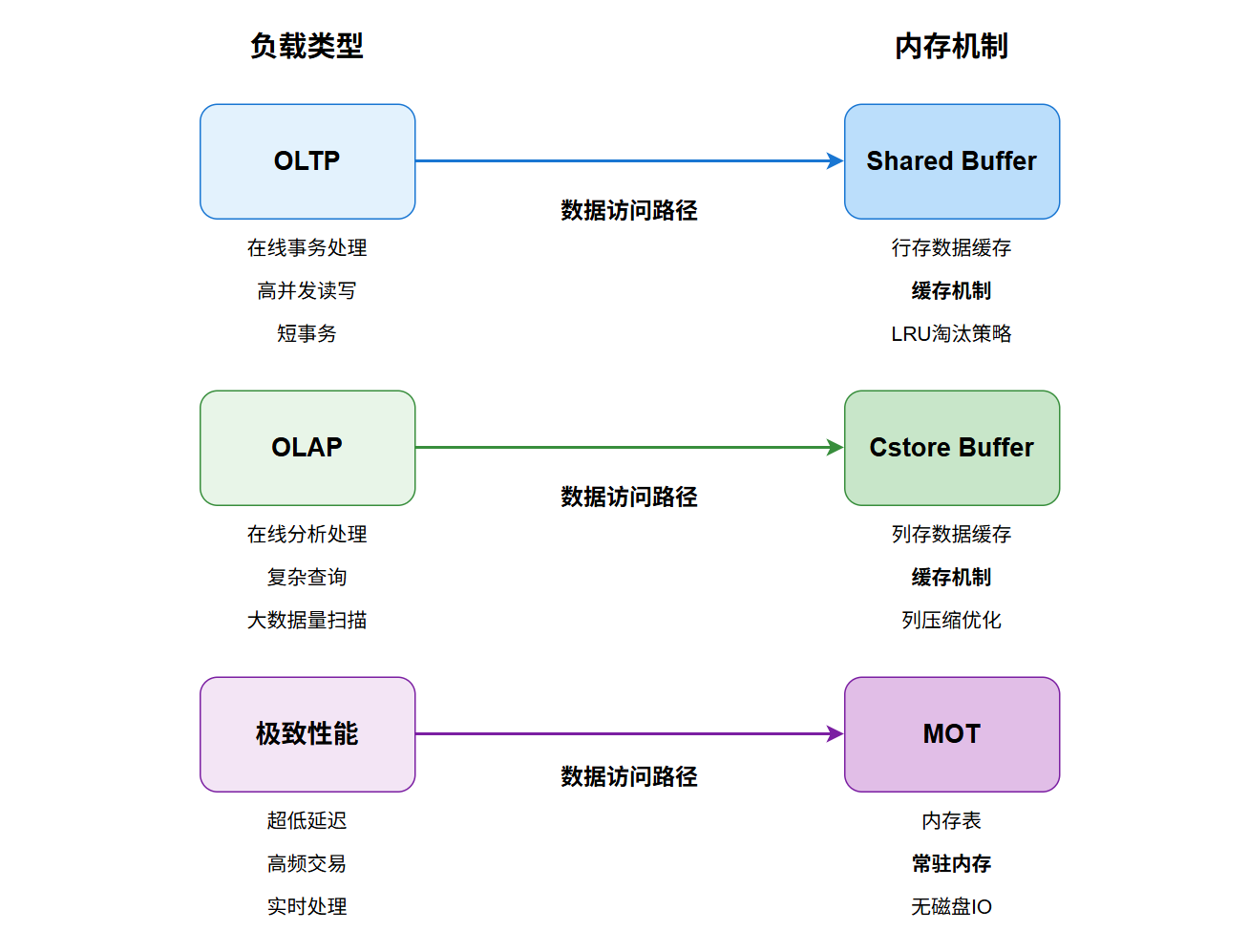 ### <font color="purple">1. Shared Buffer</font> **定义**:数据库服务器的<font color="blue">共享内存</font>缓冲区 **核心机制**:数据库中的读写操作都是针对<font color="purple">内存中</font>的数据。磁盘中的数据必须在处理前<font color="teal">加载</font>到此缓冲区中 **适用场景**:它是加速 I/O 访问速度的核心组件,主要服务于传统的<font color="navy">行存储</font>表(OLTP 场景) ### <font color="purple">2. Cstore Buffer</font> **定义**:专门为<font color="orange">列存储 (Column Store)</font> 表使用的共享缓冲区 **调优策略**:在以<font color="brown">列存表</font>为主的分析型场景(OLAP)中,几乎不用 shared buffer。此时应<font color="darkred">减少</font> `shared_buffers` 的配置大小,<font color="darkgreen">增加</font> `cstore_buffers` 的大小,以获得更好的分析性能 ### <font color="purple">3. MOT</font> **定义**:一种<font color="firebrick">全内存</font>存储引擎 **特点**:所有<font color="darkslategray">数据</font>和<font color="indigo">索引</font>都完全驻留在<font color="olive">内存</font>中,而非缓存机制 **优势**:在<font color="saddlebrown">高性能</font>(极低查询和事务延迟)、<font color="darkcyan">高可扩展性</font>(高吞吐量和并发量)以及<font color="purple">高资源利用率</font>方面拥有显著优势 ## <font color="navy">四、存储结构:数据的物理家园</font> 数据库节点负责存储数据,其逻辑结构呈现出清晰的<font color="blue">层级关系</font>,类似于文件系统的目录结构。 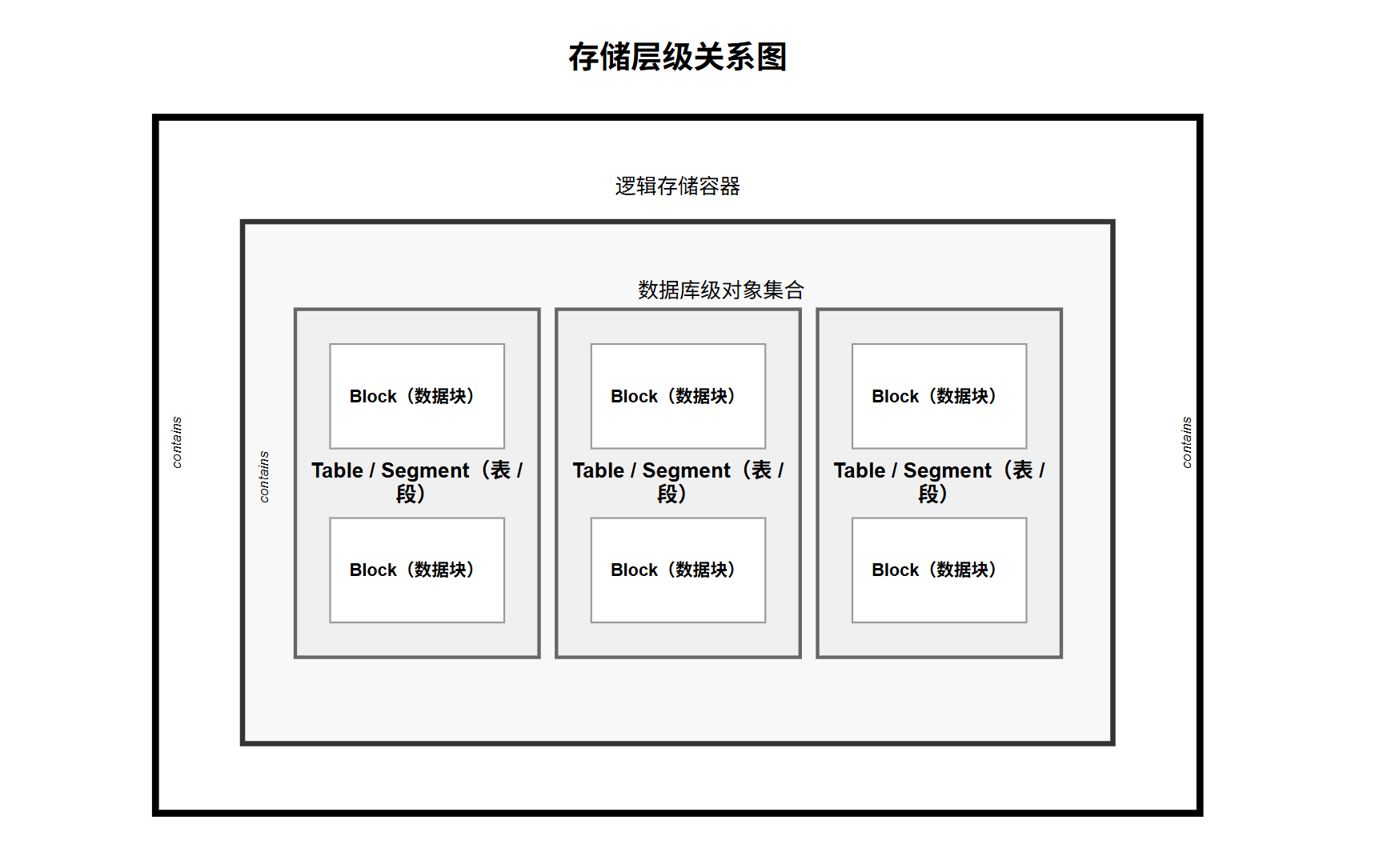 ### <font color="purple">1. 表空间</font> **本质**:是一个<font color="darkred">目录</font>,系统可以存在多个表空间。 **作用**:里面存储的是它所包含的数据库的各种<font color="green">物理文件</font>。通过表空间,可以将不同库的数据映射到不同的物理磁盘上(如将热数据放在 SSD) **关系**:每个表空间可以对应<font color="orange">多个</font> Database(多对多关系的物理承载方) ### <font color="purple">2. 数据库</font> **作用**:用于<font color="purple">管理</font>各类数据对象(如表、索引、视图)。 **隔离性**:各数据库间<font color="teal">相互隔离</font>,无法直接跨库访问。 **分布**:一个数据库管理的对象可以分布在<font color="brown">多个</font> Tablespace 上。 ### <font color="purple">3. 数据文件</font> **对应关系**:通常每张表只对应<font color="navy">一个</font>数据文件。 **自动切分**:如果某张表的数据量<font color="firebrick">大于 1GB</font>,系统会自动将其<font color="darkslategray">切分</font>为多个后缀名为 `.1`, `.2` 的数据文件进行存储,以便于操作系统管理。 ### <font color="purple">4. 表</font> **归属**:每张表只能属于<font color="indigo">一个</font>数据库。 **约束**:每张表只能对应到<font color="olive">一个</font> Tablespace。也就是说,一张表的所有数据文件必须在同一个表空间目录下。 ### <font color="purple">5. 数据块</font> **定义**:是数据库管理的<font color="saddlebrown">基本单位</font>,也称为 Page(页) **默认大小**:<font color="darkcyan">8KB</font> **I/O机制**:所有的磁盘 I/O 操作都不是按行读写,而是按<font color="darkslategray">Block</font> 进行批量读写,以提高效率。 --- ## <font color="navy">五、练习题</font> **1. 在 openGauss 中,负责接收应用访问请求并返回执行结果的组件是?** A. OM B. Client Driver C. Storage D. Shared Buffer **2. 关于 Shared Buffer 的描述,下列哪项是正确的?** A. 专门用于存储列存表数据 B. 所有数据和索引必须永久驻留在其中 C. 充当慢速磁盘与快速 CPU 之间的桥梁 D. 在列存场景下应尽可能调大 **3. 如果业务场景以列存表 (Column Store) 为主,应该如何调整内存参数?** A. 增加 shared_buffers,减少 cstore_buffers B. 减少 shared_buffers,增加 cstore_buffers C. 同时增加 shared_buffers 和 cstore_buffers D. 禁用 shared_buffers **4. MOT (Memory-Optimized Table) 的主要特点是?** A. 数据存储在磁盘,索引存储在内存 B. 仅用于缓存临时数据 C. 所有数据和索引都在内存中 D. 性能低于行存表,但节省空间 **5. openGauss 中数据块 (Block) 的默认大小是多少?** A. 4KB B. 8KB C. 16KB D. 32KB **6. 当一张表的数据文件超过多大时,系统会自动将其切分为多个文件?** A. 512MB B. 1GB C. 2GB D. 4GB **7. 关于 Database (数据库) 的描述,错误的是?** A. 数据库之间相互隔离 B. 一个数据库可以分布在多个表空间上 C. 一个表空间只能对应一个数据库 D. 用于管理各类数据对象 **8. 哪个配置文件主要负责控制数据库的连接权限和认证方式?** A. postgresql.conf B. pg_hba.conf C. cluster_config.xml D. backup.conf **9. OM (Operation Manager) 模块的主要功能不包括?** A. 数据库日常运维 B. 配置管理 C. 执行 SQL 数据查询 D. 提供管理接口工具 **10. 为了保证高可用,建议将 openGauss 的主、备实例如何部署?** A. 部署在同一个物理节点的不同目录下 B. 部署在同一个物理节点的同一个目录下 C. 分散部署在不同的物理节点中 D. 均部署在内存中 **11. Tablespace (表空间) 在文件系统层面对应的是什么?** A. 一个具体的文件 B. 一个目录 C. 一个磁盘分区 D. 一个内存区域 **12. 下列关于 Table (表) 与 Tablespace 的关系,说法正确的是?** A. 一张表的数据文件可以跨越多个 Tablespace B. 一张表对应的数据文件必须在同一个 Tablespace 中 C. 一张表可以不属于任何 Tablespace D. 一张表可以属于多个 Database **13. `postgresql.conf` 文件中的参数修改后,通常需要进行什么操作才能生效?** A. 立即自动生效 B. 重启数据库或重载配置 C. 重新安装数据库 D. 修改客户端驱动 **14. 在 openGauss 进程结构中,哪个组件负责持久化存储数据?** A. Storage B. Client Driver C. OM D. Memory **15. 为什么说内存充当了桥梁的作用?** A. 因为内存比 CPU 慢 B. 因为磁盘 I/O 速度远低于 CPU 处理速度 C. 因为内存容量无限大 D. 因为所有数据必须永久保存在内存中 --- ## <font color="navy">六、答案与解析</font> 1.**<font color="darkgreen">B. Client Driver</font>** > **解析**:Client Driver 负责与 openGauss 实例通信,发送 SQL 命令并接收执行结果。OM 是运维模块。 2.**<font color="darkgreen">C. 充当慢速磁盘与快速 CPU 之间的桥梁</font>** > **解析**:Shared Buffer 是行存共享缓冲区,用于缓存从磁盘读取的数据页,解决 CPU 与磁盘速度不匹配的问题。 3.**<font color="darkgreen">B. 减少 shared_buffers,增加 cstore_buffers</font>** > **解析**:Cstore buffer 是专门为列存表设计的。在列存场景下,几乎不使用 shared buffer,因此应减少其大小以释放内存给 cstore buffer。 4.**<font color="darkgreen">C. 所有数据和索引都在内存中</font>** > **解析**:MOT 是内存优化表,其核心特征就是数据和索引完全驻留内存,以此获得高性能和低延迟。 5.**<font color="darkgreen">B. 8KB</font>** > **解析**:openGauss 默认的数据块(Block/Page)大小为 8KB,这是 I/O 的基本单位。 6.**<font color="darkgreen">B. 1GB</font>** > **解析**:Datafile Segment 机制规定,如果某张表的数据大于 1GB,会分为多个数据文件存储。 7.**<font color="darkgreen">C. 一个表空间只能对应一个数据库</font>** > **解析**:这是错误的说法。每个表空间可以对应多个 Database,即多个数据库可以共用一个表空间。 8.**<font color="darkgreen">B. pg_hba.conf</font>** > **解析**:pg_hba.conf (Host-Based Authentication) 是专门用于配置客户端认证策略(黑白名单)的文件。 9.**<font color="darkgreen">C. 执行 SQL 数据查询</font>** > **解析**:执行 SQL 查询是 openGauss 实例(Datanode)的工作,OM 负责运维和配置管理(如启动、停止)。 10.**<font color="darkgreen">C. 分散部署在不同的物理节点中</font>** > **解析**:为了容灾和高可用,主备实例不能在同一台物理机上,否则物理机故障会导致整个集群不可用。 11.**<font color="darkgreen">B. 一个目录</font>** > **解析**:Tablespace 在物理层面就是一个目录,用于指定数据文件在文件系统中的存储路径。 12.**<font color="darkgreen">B. 一张表对应的数据文件必须在同一个 Tablespace 中</font>** > **解析**:一张表只能属于一个 Database,也只能位于一个 Tablespace 中。 13.**<font color="darkgreen">B. 重启数据库或重载配置</font>** > **解析**:`postgresql.conf` 是核心参数文件,大多数参数(尤其是涉及内存和端口的)修改后需要重启 (`gs_om -t stop/start`) 或重载 (`gs_om -t reload`) 才能生效。 14.**<font color="darkgreen">A. Storage</font>** > **解析**:Storage 指的是服务器的本地存储资源(磁盘),负责数据的持久化。 15.**<font color="darkgreen">B. 因为磁盘 I/O 速度远低于 CPU 处理速度</font>** > **解析**:这是数据库引入缓冲区的根本原因。CPU 处理极快,磁盘 I/O 极慢,必须通过内存作为中间缓冲来加速访问。
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号