IEDM 2025台积电短课:AI驱动先进封装与芯粒技术的创新突破与系统协同

IEDM 2025台积电短课:AI驱动先进封装与芯粒技术的创新突破与系统协同

光芯
发布于 2026-01-26 17:02:21
发布于 2026-01-26 17:02:21

一、行业背景与技术演进脉络
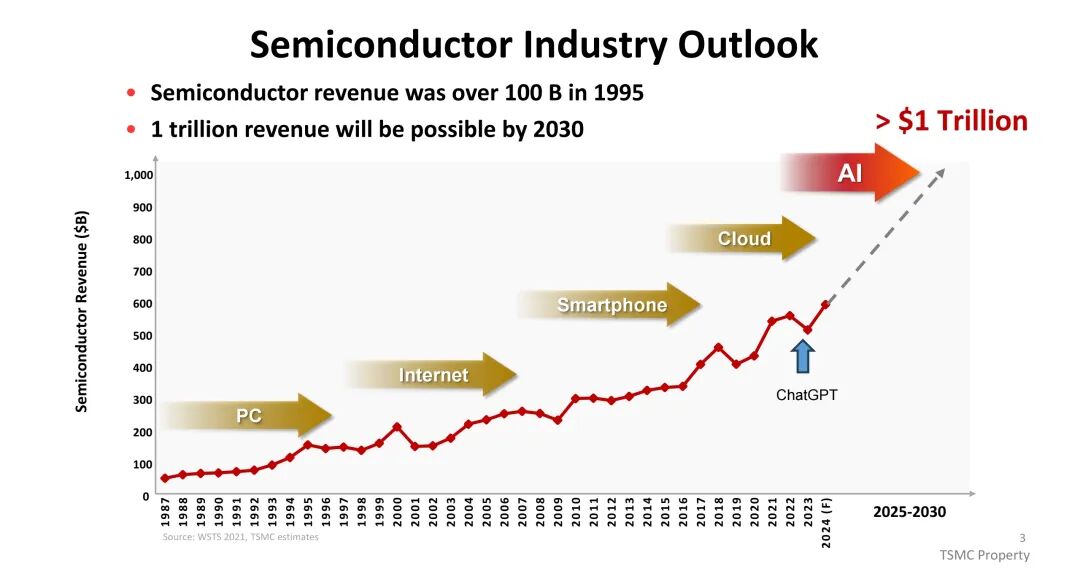
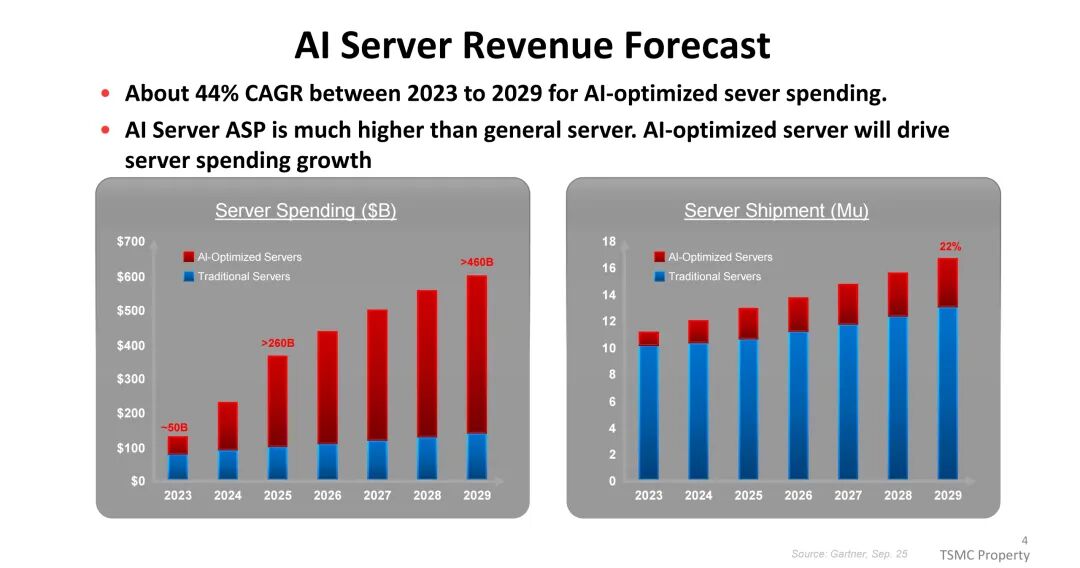
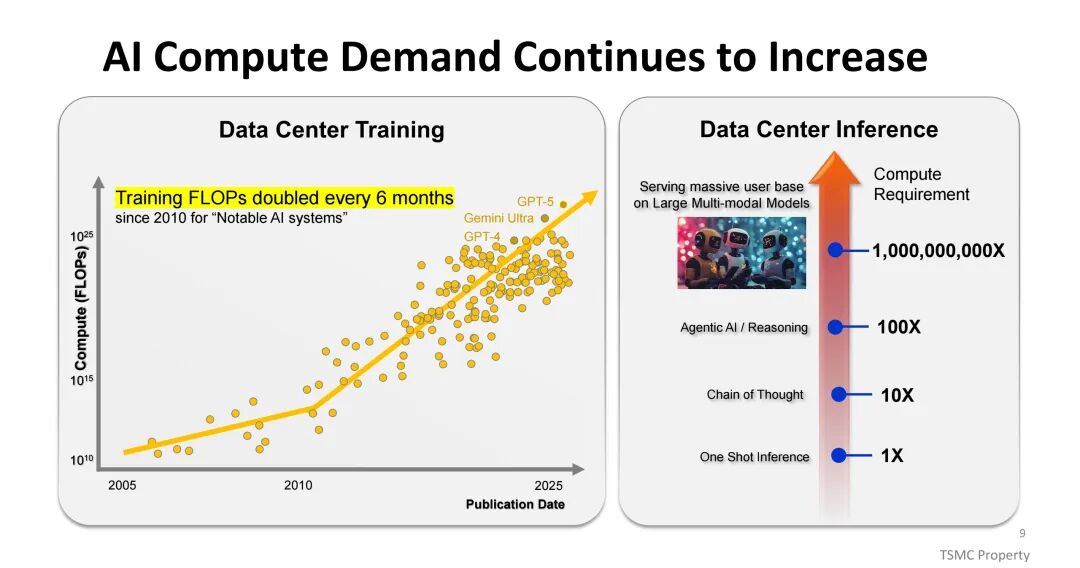
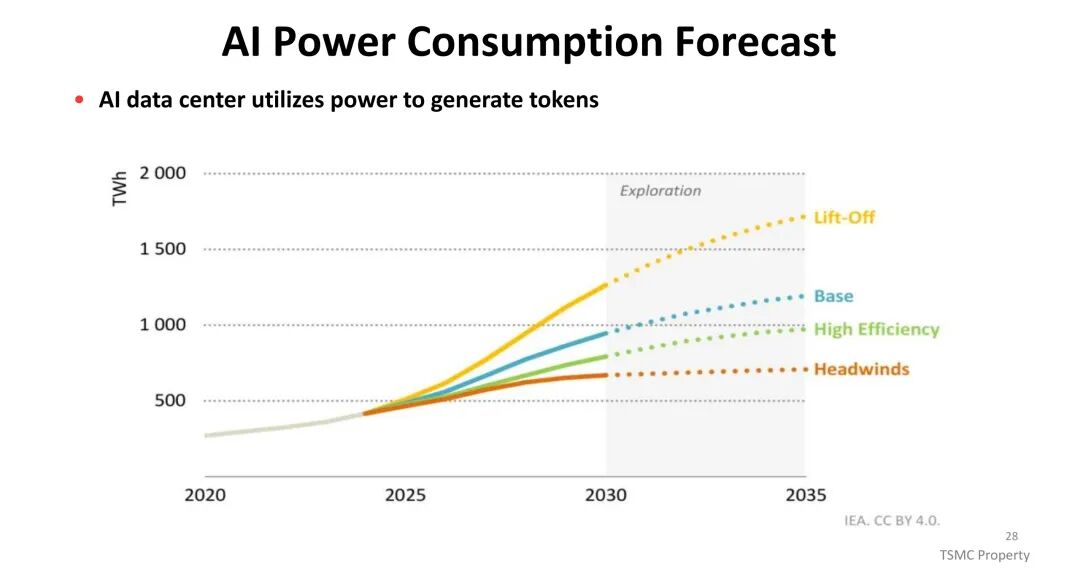
半导体行业正迎来AI驱动的爆发式增长,1995年行业营收已突破1000亿美元,预计2030年将迈入1万亿美元规模。其中,AI服务器成为核心增长引擎,2023至2029年间复合年增长率(CAGR)约达44%,其平均销售价格(ASP)显著高于传统服务器,成为服务器市场支出增长的主要驱动力。
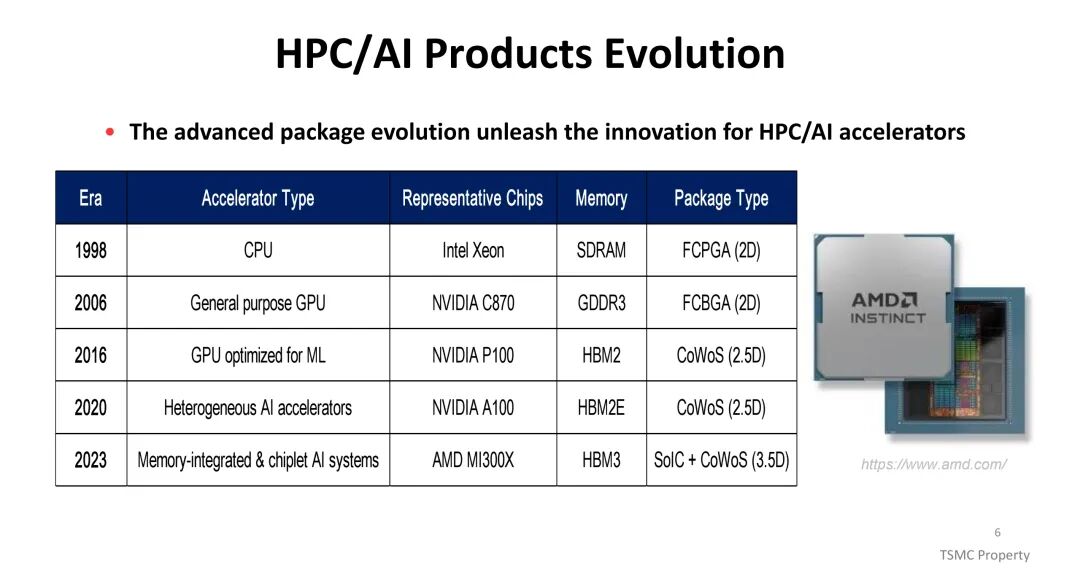
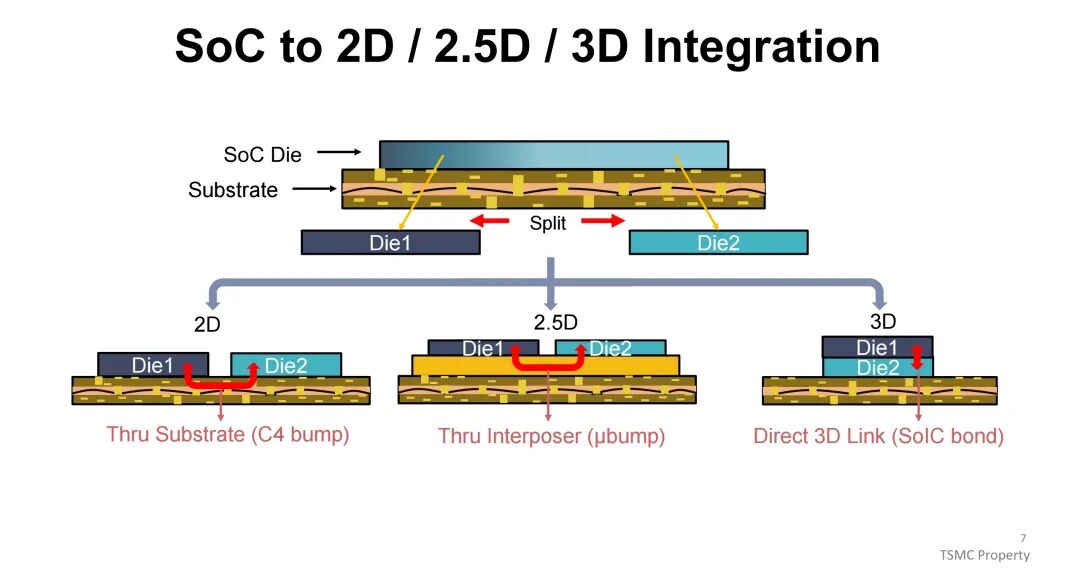
在计算架构演进方面,HPC/AI加速器已完成多代迭代:1998年以Intel Xeon CPU为代表,采用2D封装的FCPGA形式搭配SDRAM;2006年进入通用GPU时代,NVIDIA C870采用FCBGA封装与GDDR3内存;2016年至2020年,面向机器学习优化的GPU(如NVIDIA P100、A100)开始采用2.5D的CoWoS封装,搭配HBM2/HBM2E内存;2023年,以AMD MI300X为代表的内存集成式芯粒AI系统,通过SoIC与CoWoS结合的3.5D封装方案,实现了与HBM3的高效集成。这种演进背后,是从单一系统级芯片(SoC)到2D、2.5D再到3D集成的技术跨越,互连方式也从基板介导的C4凸点、中介层介导的微凸点,升级为直接3D连接的SoIC键合,核心目标是突破性能、带宽与能效的瓶颈。
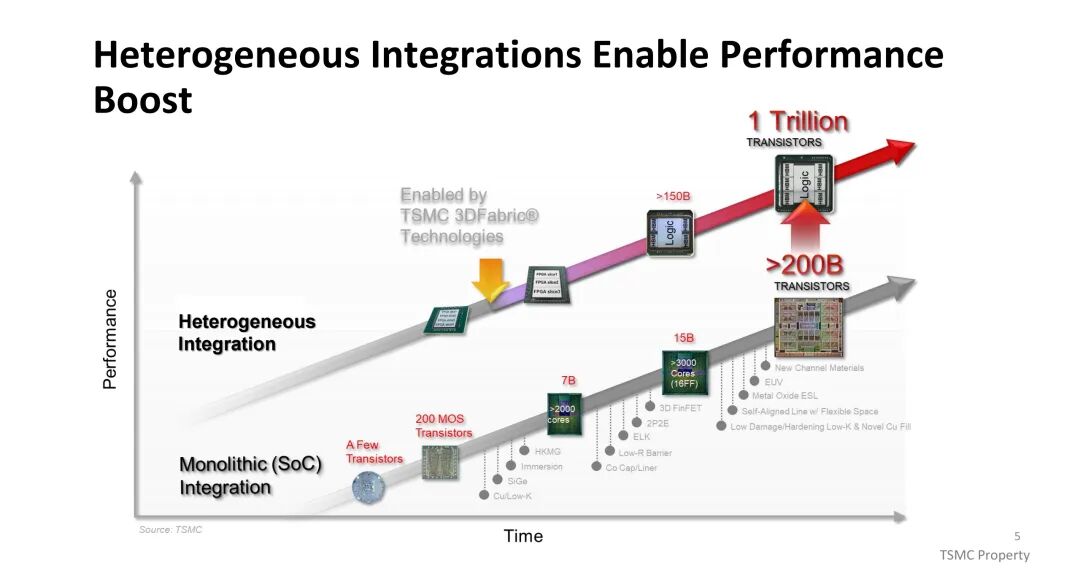
二、核心封装技术:CoWoS与SoIC的创新实践
(一)CoWoS封装:现代AI引擎的关键支撑
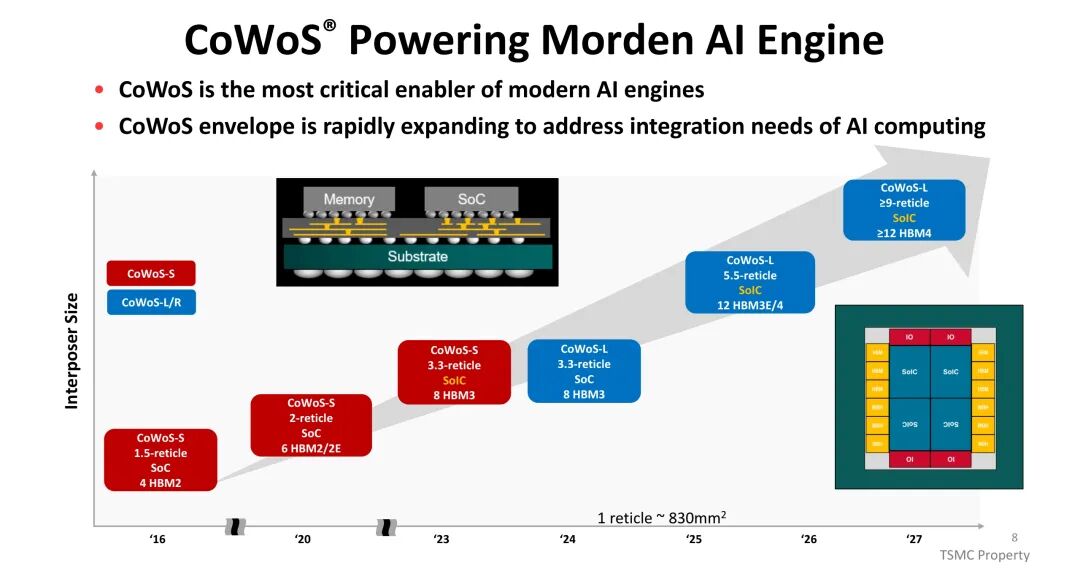
CoWoS是当前AI计算的核心封装技术,其封装尺寸持续扩展以满足日益增长的集成需求。从最初支持4颗HBM2、1.5倍晶圆面积(reticle)的基础版本,逐步演进至支持6颗HBM2/2E、2倍reticle面积的规格,再到适配8颗HBM3、3.3倍reticle面积的配置。最新演进方向显示,CoWoS将支持12颗HBM3E/HBM4,最大尺寸可达9倍reticle面积,通过与SoIC技术的结合,进一步提升集成密度。每颗晶圆面积约为830mm²,CoWoS的持续扩容直接响应了AI模型对高带宽、大容量内存集成的迫切需求。
(二)SoIC技术:3D互连的能效革命
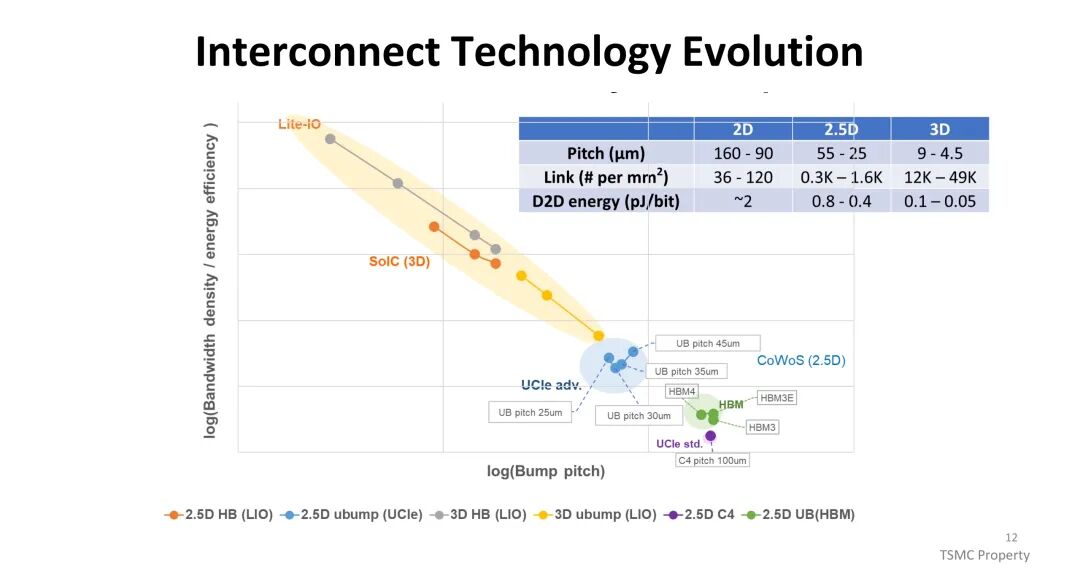
SoIC(系统级集成芯片)通过直接3D键合技术,构建了高效的芯片间互连通道,与2D、2.5D封装形成显著差异。在互连参数上,2D封装的凸点间距为160-90μm,每平方毫米链路数仅36-120条,数据传输能耗约2pJ/bit;2.5D封装通过微凸点实现55-25μm的间距,链路密度提升至0.3K-1.6K条/mm²,能耗降至0.8-0.4pJ/bit;而SoIC的3D互连将间距缩小至9-4.5μm,链路密度飙升至12K-49K条/mm²,能耗仅0.1-0.05pJ/bit,为芯粒系统的高性能、低功耗互连提供了核心支撑。
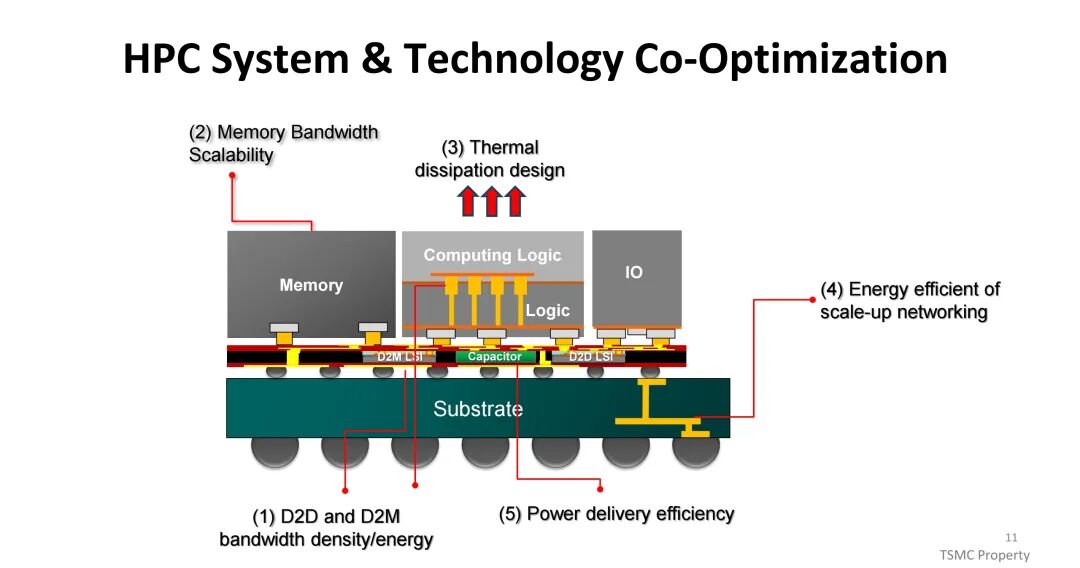
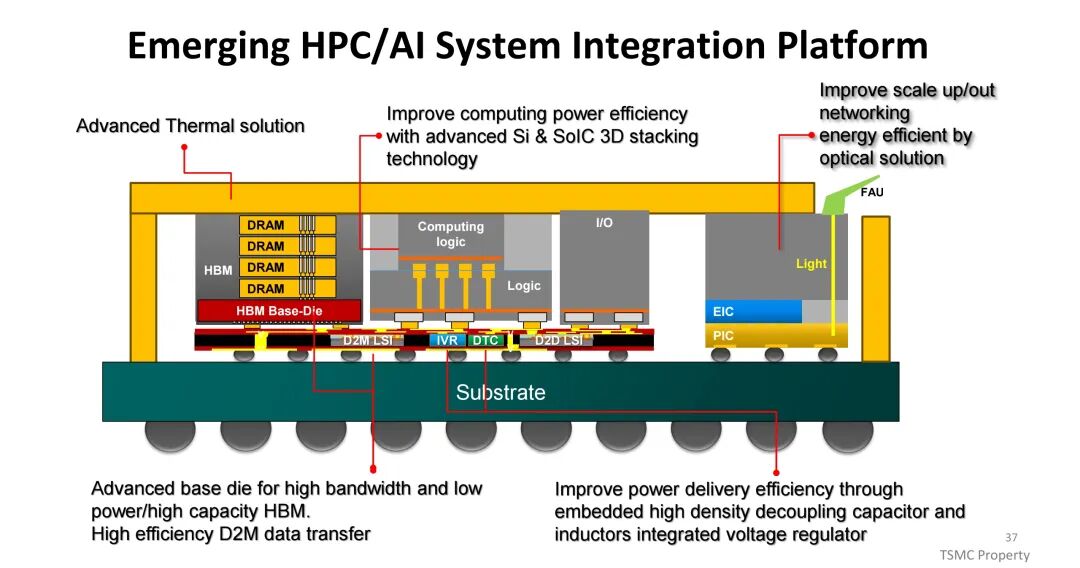
三、系统技术协同优化(STCO):突破AI/HPC的多维瓶颈
(一)互连技术:从物理连接到能效优化
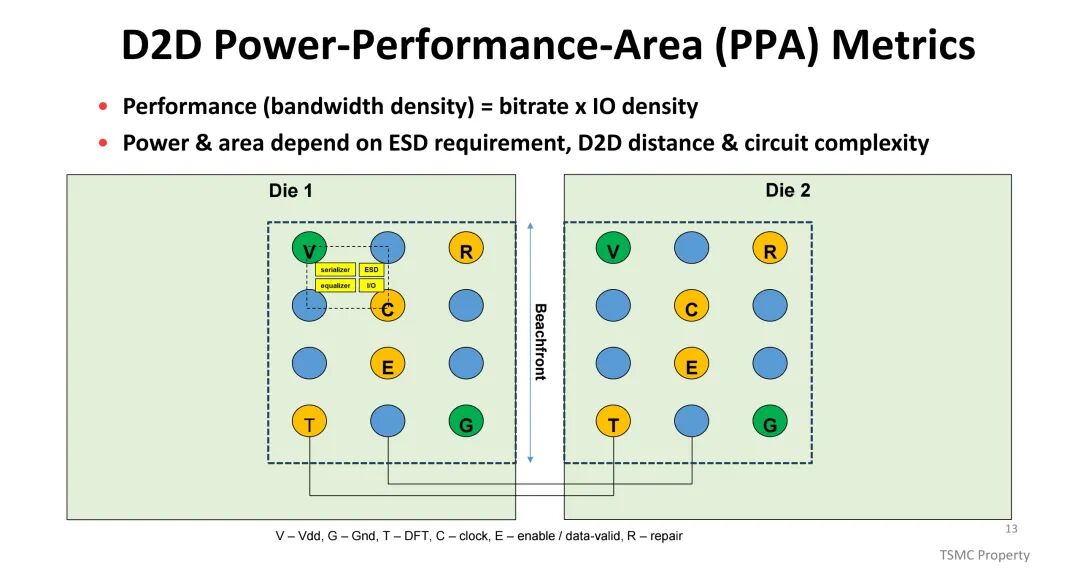
互连技术的演进是系统性能提升的关键,其核心指标包括带宽密度、传输能耗与信号完整性。芯粒间(D2D)与芯粒-内存间(D2M)的互连性能直接决定系统整体表现,带宽密度由比特率与IO密度共同决定,而功耗与面积则受ESD要求、互连距离及电路复杂度影响。TSMC通过优化互连架构,在CoWoS中介层中增加布线资源,同时缩小HBM的微凸点间距,提升数据传输速率,配合高性能、低功耗的PHY逻辑与低电压设计,平衡带宽提升与热耗控制。
(二)内存层级与HBM演进:带宽与容量的双重突破
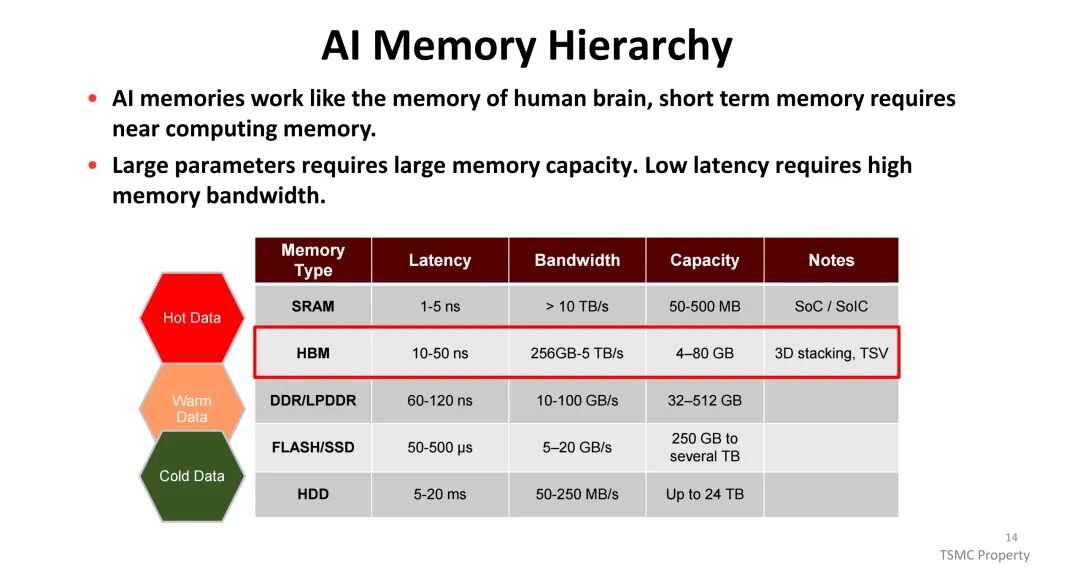
AI系统的内存层级类似人类大脑的记忆机制,需满足不同数据的存储需求:SRAM作为近计算内存, 时延仅1-5ns,带宽超10TB/s,但容量有限(50-500MB);HBM凭借3D堆叠与TSV技术,实现10-50ns的 latency与256GB-5TB/s的带宽,容量覆盖4-80GB,成为AI计算的核心内存;DDR/LPDDR、FLASH/SSD与HDD则构成中低速、大容量的存储层级。为进一步提升带宽,HBM通过缩小微凸点间距提升比特率,同时增加IO数量,2024年后演进速度加速,从8层堆叠向12层、16层、20层推进,带宽与容量实现多倍增长。
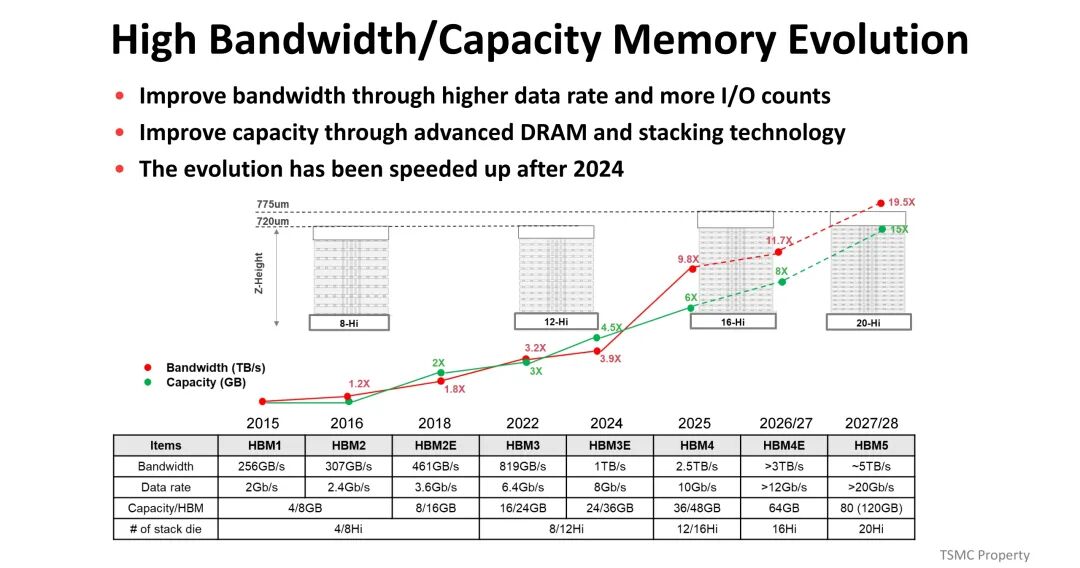
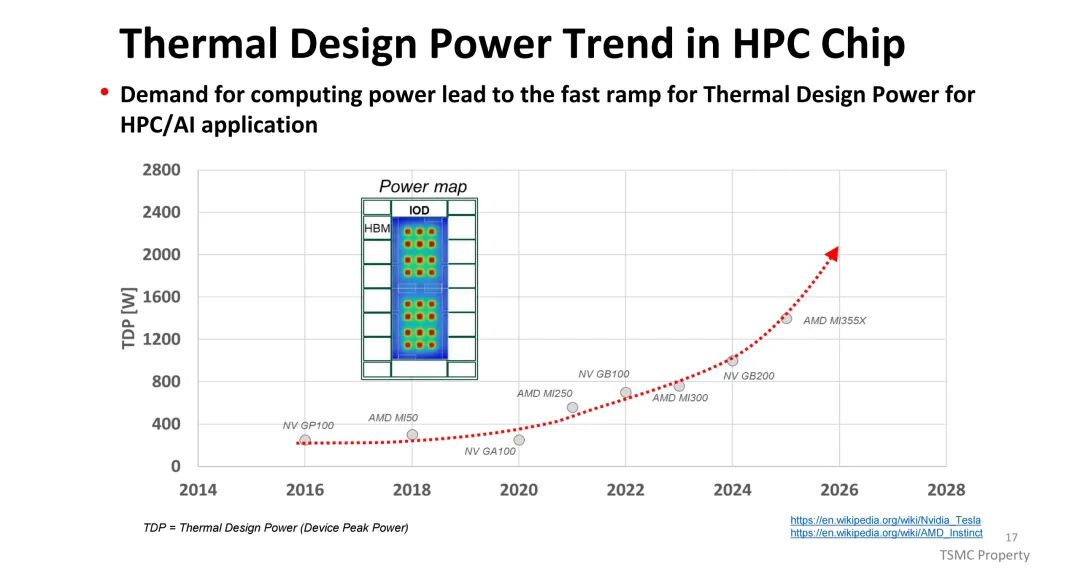
(三)热设计:应对高功耗密度挑战
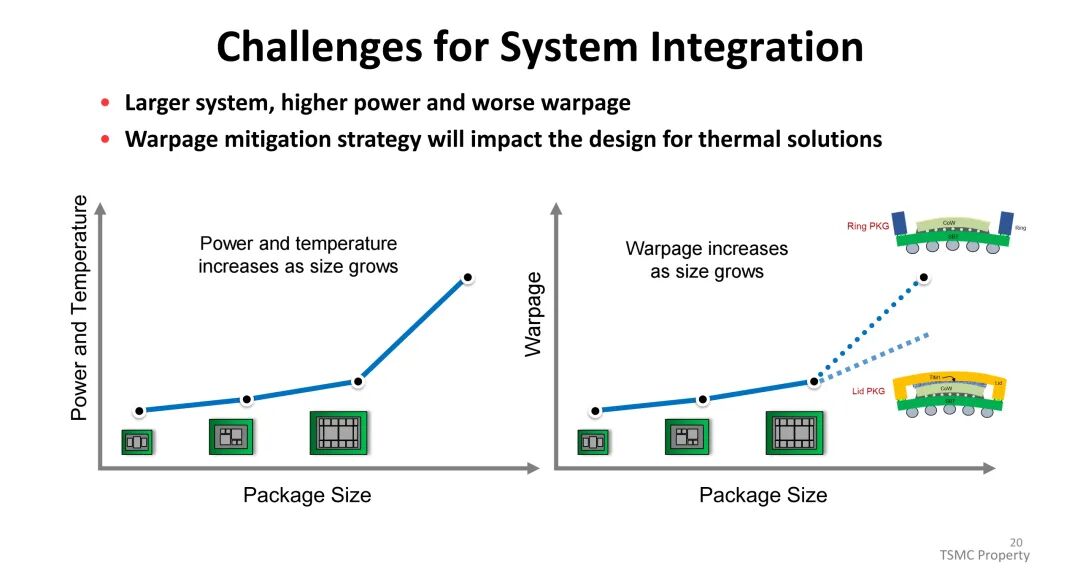
AI/HPC芯片的热设计功耗(TDP)持续飙升,从早期NVIDIA GP100的较低水平,发展到AMD MI300、NVIDIA GB100的千瓦级水平,2026年后预计将进一步突破。热阻主要由热界面材料(TIM1、TIM2)、散热器设计及芯片本身特性决定,其中TIM1与TIM2的热阻占比显著。
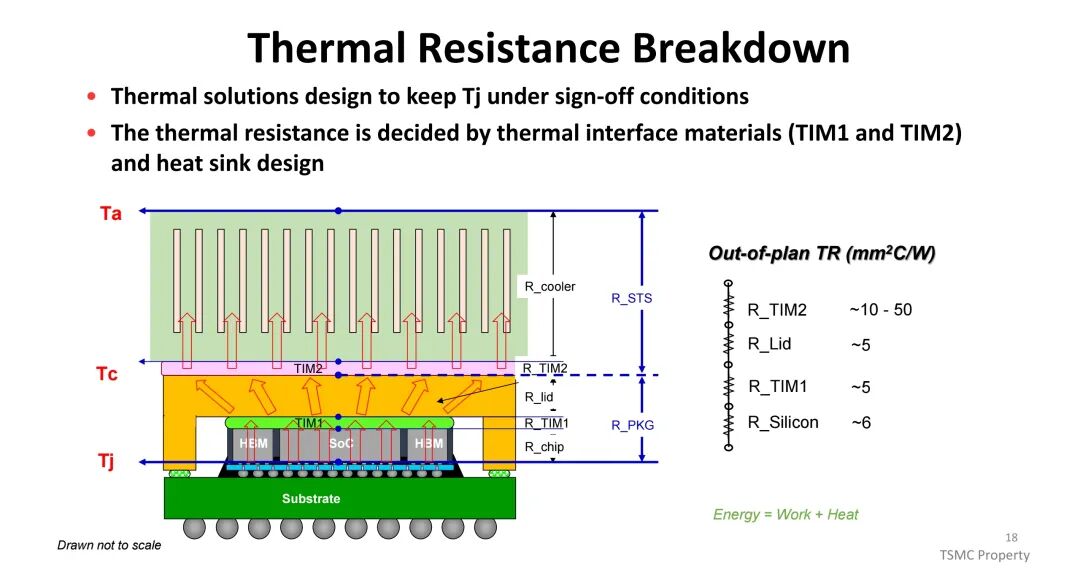
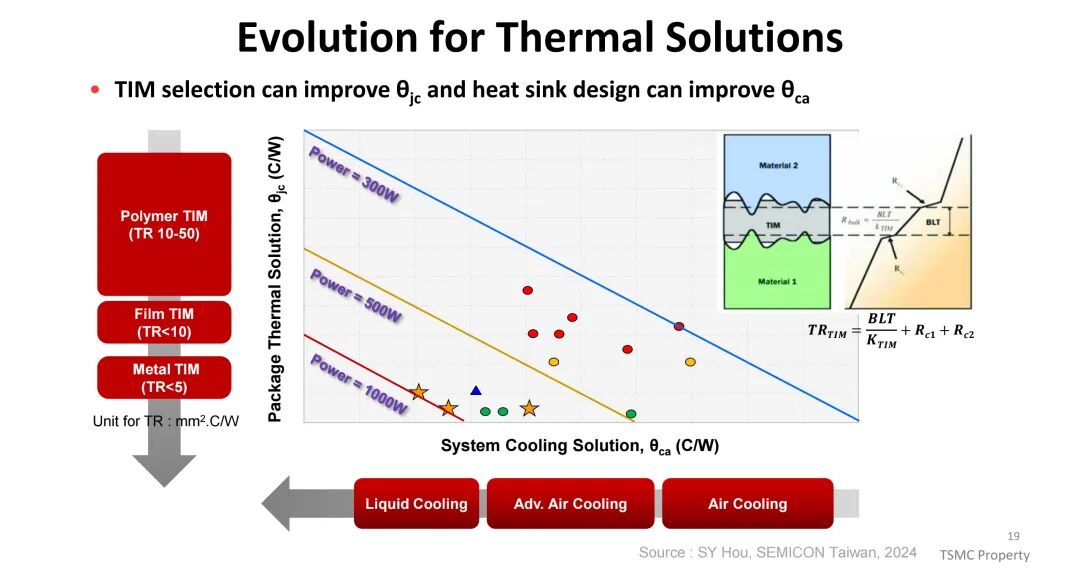
为应对这一挑战,散热方案从传统聚合物TIM(热阻10-50mm²·C/W)逐步升级至薄膜TIM(热阻<10mm²·C/W)与金属TIM(热阻<5mm²·C/W);冷却方式则从风冷向先进风冷、液冷、喷射冲击冷却及相变冷却演进,其中相变冷却与浸没冷却具备更高的热传导系数,成为高功耗场景的关键解决方案。封装形式上,环形封装(Ring-PKG)在热性能上优于盖式封装(Lid-PKG),可减少热界面材料覆盖不均导致的散热差异。
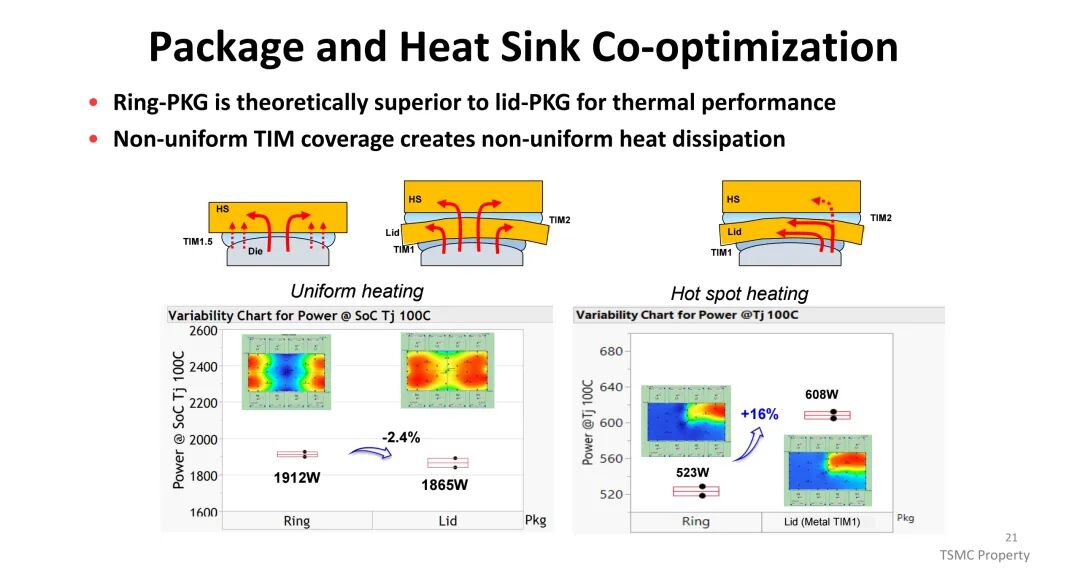
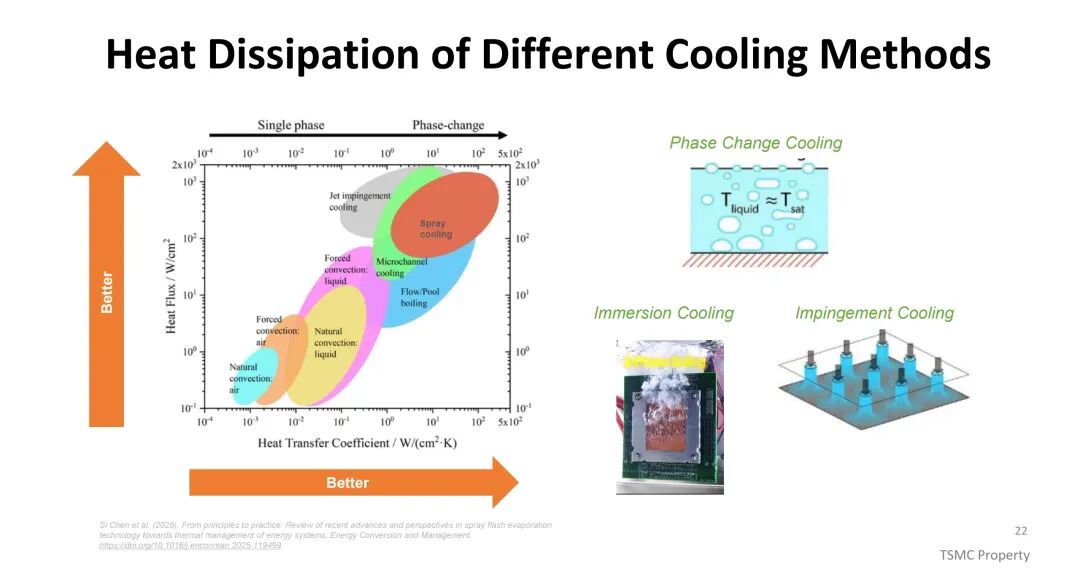
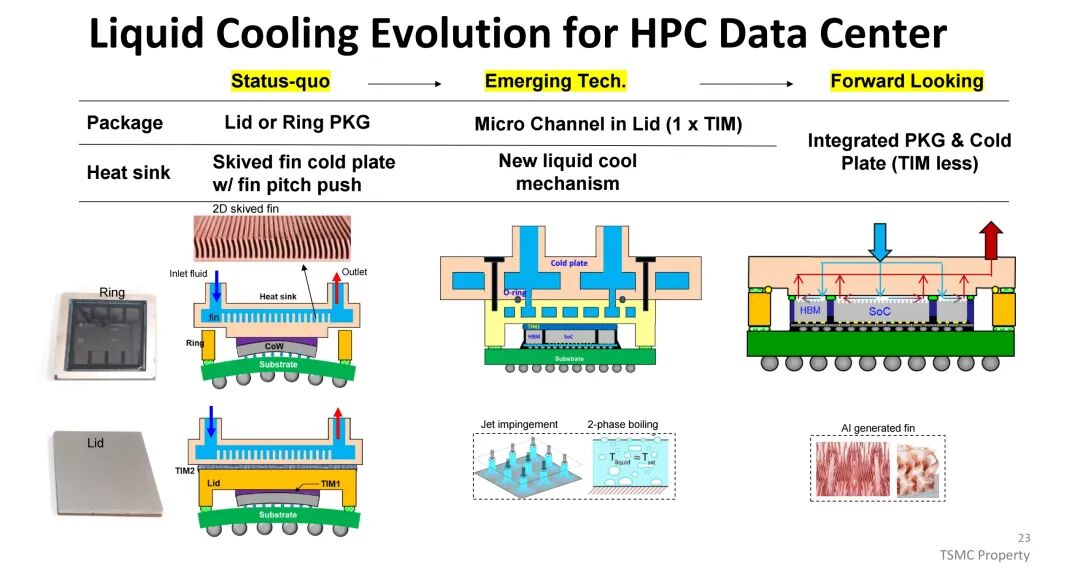
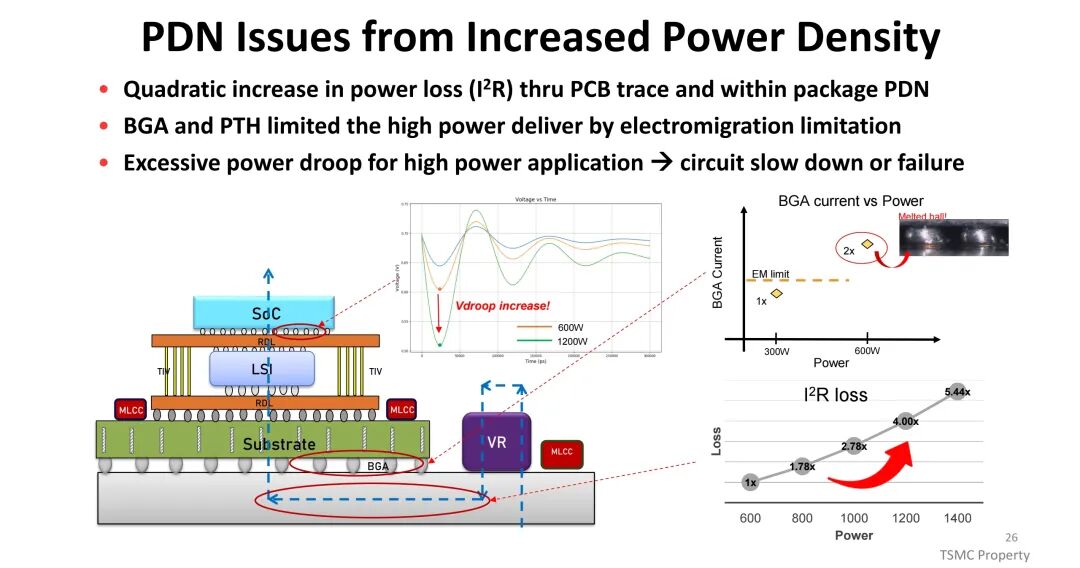
(四)功耗与电源管理:破解PDN瓶颈
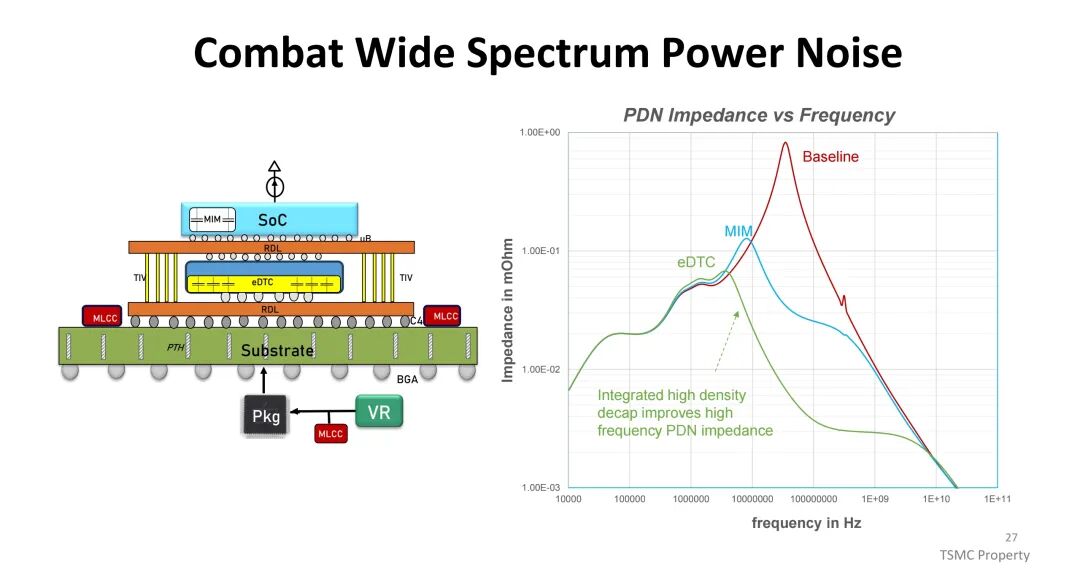
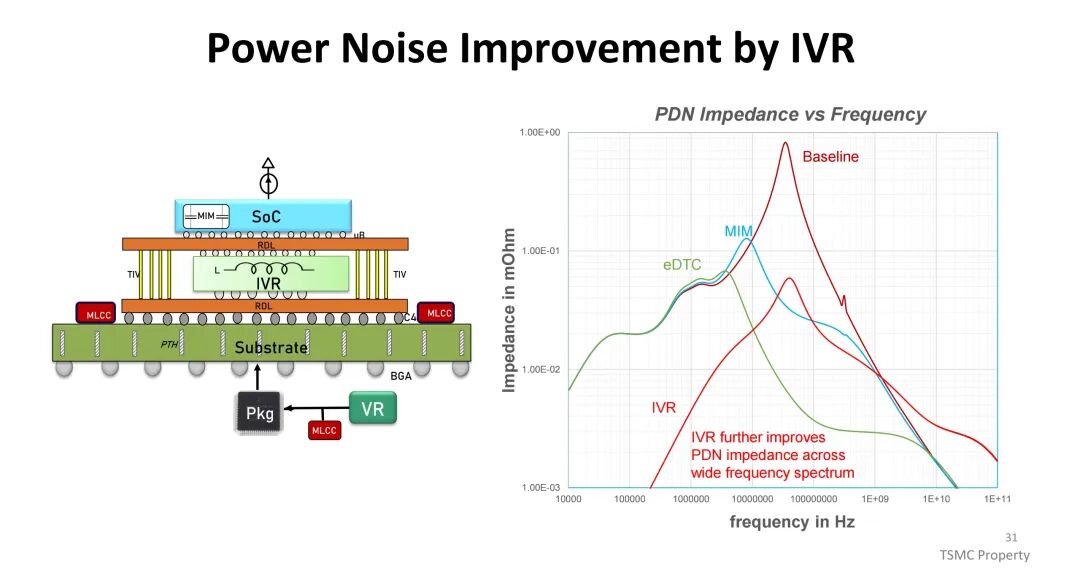
高功率密度带来电源分配网络(PDN)的严峻挑战,PCB走线与封装内的功率损耗(I²R)随电流平方增长,BGA与过孔的电迁移限制进一步制约高功率传输,易引发电压跌落导致电路性能下降或失效。TSMC通过集成高密度去耦电容(如eDTC、MIM),优化宽频率范围内的PDN阻抗;同时推出集成电压调节器(IVR),将PMIC与电感集成于CoWoS中,相比传统板级VR,IVR降低了PDN损耗与电压跌落 overhead(从20%降至5%),提升了电源传输效率与响应速度,为高功耗芯片提供稳定供电。
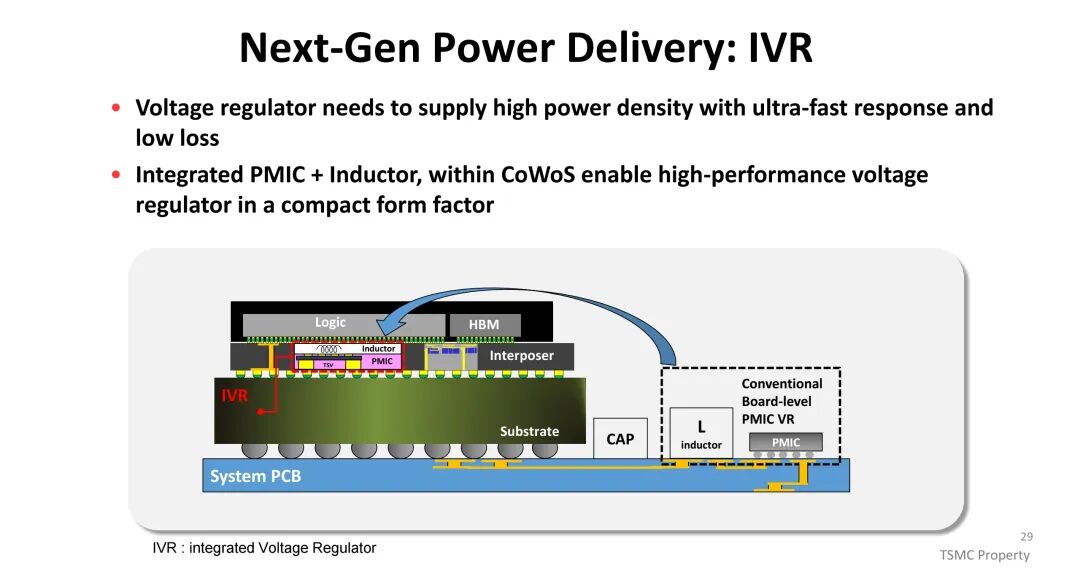

(五)网络扩展:从铜基到光互连的转型

铜基互连在长距离传输中面临显著瓶颈,随着通信距离增加,功率消耗飙升、带宽密度下降,信号插入损耗随数据速率升高而快速增长,Cu线路在每通道400G速率下将停止缩放。例如,1m的铜缆传输能耗超30pJ/bit,而30cm的PCB传输能耗达6pJ/bit。
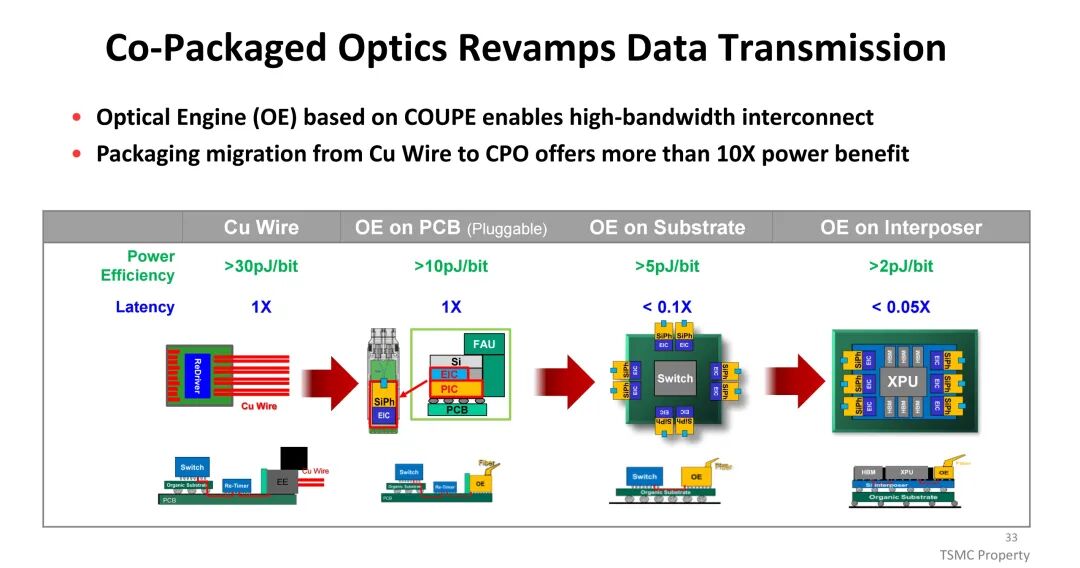
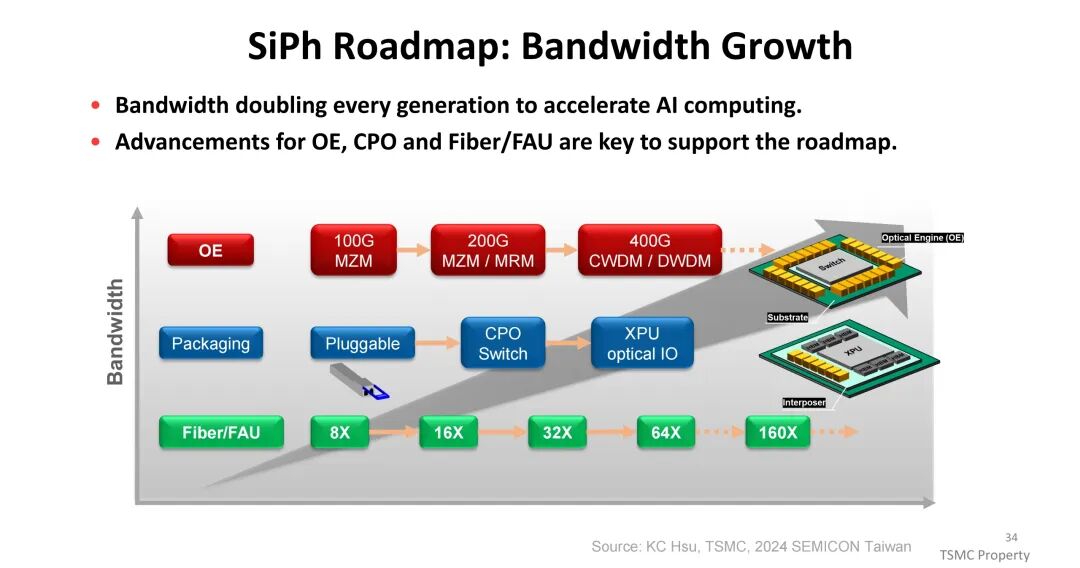
为解决这一问题,TSMC推出共封装光学(CPO)方案,基于SoIC堆叠技术将电子集成电路(EIC)与光子集成电路(PIC)集成形成紧凑通用光子引擎(COUPE),传输能耗可降至2pJ/bit以下, latency显著降低,成为大规模AI集群高效互连的核心方向。Si光子技术路线图显示,带宽将每代翻倍,依赖光学引擎、CPO及光纤/FAU的技术突破。
四、新兴技术与生态构建:面向未来的AI/HPC平台
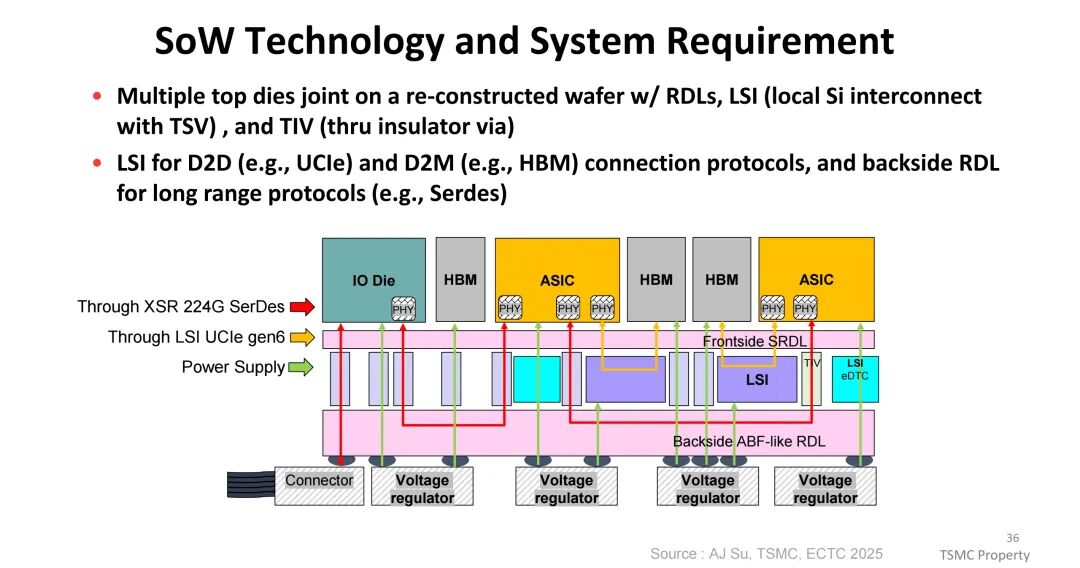
(一)Wafer级系统(SoW):突破集成规模限制
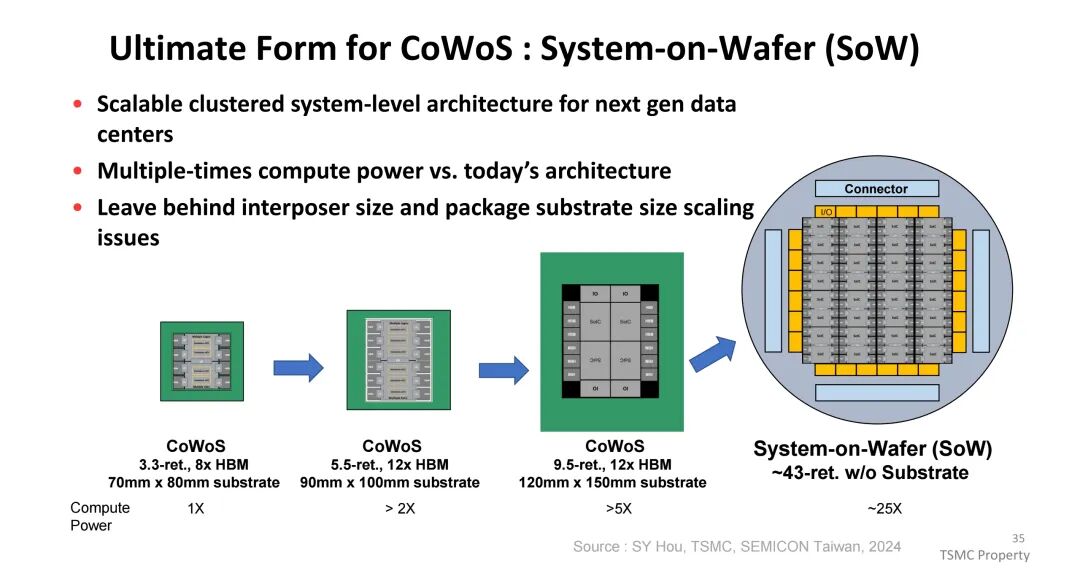
System-on-Wafer(SoW)是CoWoS的终极形态,通过重构晶圆整合多个顶部芯片,集成重新分布层(RDL)、本地硅互连(LSI)与穿绝缘体通孔(TIV),彻底摆脱中介层与基板尺寸的限制。相比当前最大5.5倍reticle面积、12颗HBM的CoWoS方案,SoW可实现43倍晶圆面积的集成规模,计算能力提升25倍以上。其架构支持通过LSI实现UCIe gen6等D2D/D2M协议互连,通过背侧RDL支持224G SerDes等长距离协议,为下一代数据中心提供可扩展的集群化系统架构。
(二)设计工具与产业生态:加速技术落地
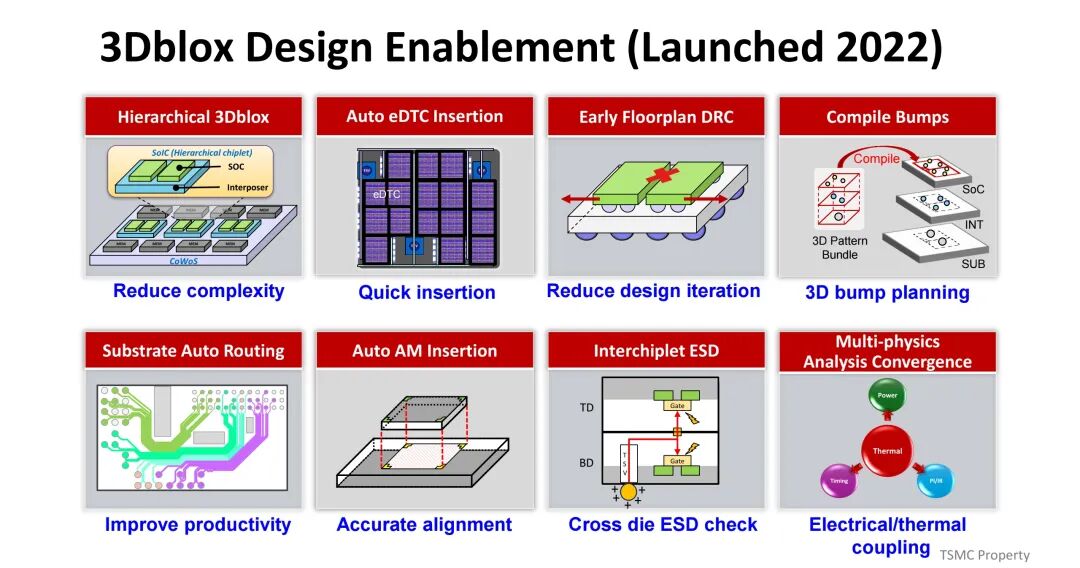
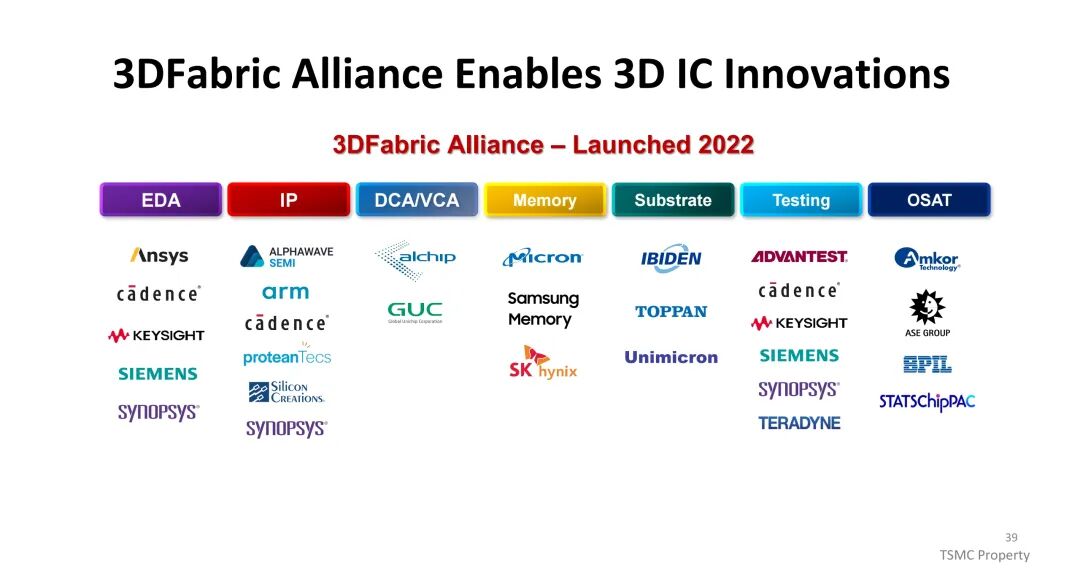
为简化3D IC设计流程,TSMC于2022年推出3Dblox设计工具,提供分层设计、自动去耦电容插入、早期布局规划DRC检查、跨芯片ESD验证等功能,减少设计复杂度与迭代次数,提升设计效率与准确性。同时,TSMC发起3DFabric联盟,整合EDA工具、IP、内存、基板、测试、OSAT等产业链环节的核心企业(如Ansys、Cadence、Micron、SK hynix等),构建协同创新的产业生态,推动3D IC技术的规模化应用。
五、总结
AI与HPC的爆发式增长,推动半导体行业向1万亿美元规模迈进,也对封装与芯粒技术提出了前所未有的性能、带宽、能效与集成度要求。TSMC通过CoWoS与SoIC两大核心技术,构建了从2.5D到3D的先进封装体系,并通过系统技术协同优化(STCO),在互连、内存、热设计、功耗管理与网络互连等维度突破瓶颈。

面向未来,COUPE光子引擎、SoW晶圆级系统等新兴技术将进一步拓展性能边界,而3Dblox设计工具与3DFabric联盟则为技术落地提供生态支撑。能效已成为AI相关平台的核心性能指标,TSMC的3DFabric平台通过逻辑、内存与封装技术的深度整合,以及系统级的协同优化,为下一代AI与HPC应用提供了全面的技术解决方案,持续驱动行业创新与发展。
完整报告:





本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号