NTT:基于空分复用+波分复用双轮驱动的可编程大规模光子处理器


可编程光子处理器凭借光在空间、频率和时间维度的固有并行性,实现了大规模并行计算与低能耗的完美结合,在机器学习张量处理和光通信领域展现出巨大潜力,成为突破电子处理器性能瓶颈的关键方向。本文将详细阐述可编程光子处理器的最新研究进展,包括多款核心硬件的研发与无梯度训练算法的创新,以及其在实际场景中的应用验证。
原文链接:https://www.ntt-review.jp/archive/ntttechnical.php?contents=ntr202511ra1_s.html
◆光的并行性赋能:光子计算的核心优势与研究脉络
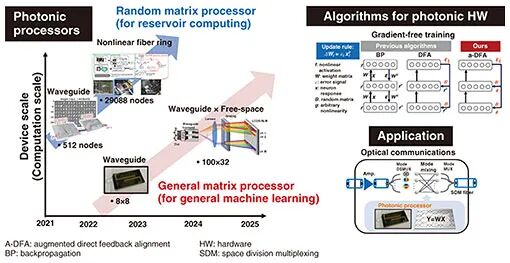
光子计算的核心优势源于光的固有特性——在空间、频率(波长)和时间维度的天然并行性,这使得可编程光子处理器能够实现并行化、宽带宽处理,相比电子处理器大幅降低延迟与能耗。针对机器学习中的线性处理瓶颈和光通信中的信号处理需求,研究团队围绕光子处理器展开了系统性研究,形成了清晰的技术演进脉络:2021年至2025年间,先后开发了29088节点的随机矩阵处理器、512节点的非线性光纤环、100×32混合波导-自由空间架构处理器及8×8通用矩阵处理器,同时在算法层面完成了从反向传播(BP)、直接反馈对齐(DFA)到增强型直接反馈对齐(a-DFA)的无梯度训练技术迭代,构建起硬件与算法协同优化的研究体系。
◆混合波导与自由空间融合:大规模光子张量处理器的实现
光子矩阵-向量乘法(MVM)是光子模拟机器学习的基础组件,基于波分复用(WDM)的张量处理是其典型实现方式。该架构由WDM发射器(Tx)、光子MVM器件和接收器(Rx)阵列组成,N路输入WDM信号被拆分为M个分支,经WDM解复用器(DMUX)色散后,通过可变光衰减器独立加权,再由WDM复用器(MUX)合并,最终由光电探测器(PD)检测。其运算速度(OPS)可通过公式OPS=2*N*M*B计算(N为WDM信道数,M为分支数,B为信号波特率), 拓展性由光子MVM器件的M×N值决定。
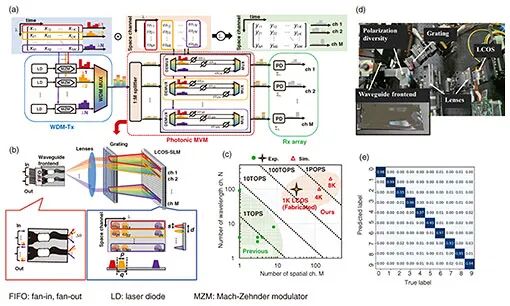
为突破拓展性限制,研究团队采用混合波导与自由空间光学技术,开发了可扩展光子MVM器件。该器件通过硅基液晶(LCOS)空间光调制器(SLM)控制每束光的波前,实现对密集复用WDM信号的独立调控。实验搭建的光学平台支持M=32、N=100的配置,在B=30 Gbaud的假设下,运算速度达到188 TOPS。为验证性能,团队在卷积神经网络(CNN)中执行卷积处理,在MNIST手写数字识别任务中达成95.8%的准确率,充分证明了该器件的实用价值。
◆ WDM兼容MZI网格:光通信领域的高效信号处理方案
马赫-曾德尔干涉仪(MZI)网格是另一类极具潜力的矩阵运算引擎,凭借空间并行性可对每个波长信道独立执行MVM运算。当MZI网格的权重不受波长变化影响时,输入WDM信号即可同时完成多个MVM运算,对应机器学习硬件中张量处理所需的矩阵-矩阵乘法(MMM)。研究团队基于硅基平面光波导电路(PLC)平台,集成了宽带MZI网格,成功研制出8×8集成式光子处理器。
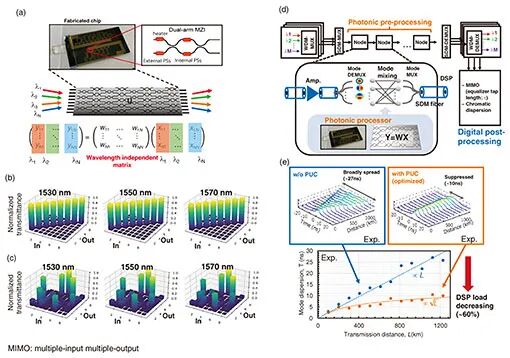
实验测试显示,该处理器在1530nm、1550nm和1570nm三个波长下,均能稳定构建单位矩阵和随机酉矩阵,展现出优异的波长兼容性。在>10 Gbaud运算速率与100个波长信道的配置下,其运算速度可超过128 TOPS。在光通信场景中,该处理器被用作每个光节点的光子预处理器,通过片上光子酉转换器(PUC)实现模式置换优化,支持从弱到强模式耦合机制的无缝切换,通过调控模式混合状态抑制模式色散。经参数优化后,该方案实现了1331km的三模传输,同时缩短了均衡器长度,使数字信号处理器(DSP)负载降低60%,有效缓解了光通信系统的信号处理压力。
◆ 时空复用集成:片上光子储层计算机的高性能突破
基于MVM功能,研究团队将神经网络运算从简单线性代数拓展至光子电路,开发了集成于PLC平台的片上光子储备池计算机(RC)。在储层计算框架中,仅需训练输出权重,光学权重随机设定,无需在训练过程中微调光学系统,且训练时间由前向传播决定,可借助光子技术实现加速。尽管非线性激活函数仅部署在输入和输出端,但相干系统中的复数值演化确保了丰富的动态特性,性能堪比非相干非线性系统。
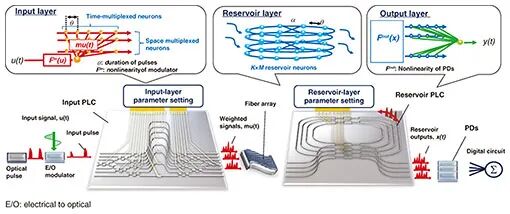
与传统片上储备池计算机不同,该方案的输入和储层权重均在时空域进行光学编码,实现了紧凑型芯片上的可扩展集成。依托WDM技术,处理器可利用>太赫兹(THz)的超宽光学带宽作为计算资源,具备极强的并行处理能力。实验验证表明,该光子储层计算机在混沌时间序列预测和图像分类等基准任务中表现优异,处理28×28像素图像仅需17.1ns。其单波长运算速度达21.12T MAC·s⁻¹,通过WDM并行技术,单块光子芯片即可实现拍级运算速度。此外,该方案还成功应用于光通信信号处理,完成了非线性均衡、信号格式识别和相位恢复等实用场景的技术验证。
◆ 无梯度训练革新:光子神经网络的高效学习方案
光子神经网络虽能模拟大脑的模拟信息处理过程,但受限于反向传播(BP)等标准训练算法难以在光子硬件中实现,其学习过程仍依赖为数字处理优化的方法,这限制了光子处理在训练阶段的应用。为此,研究团队提出了无BP的光子深度学习方法,采用受生物启发的增强型直接反馈对齐(a-DFA)训练算法。
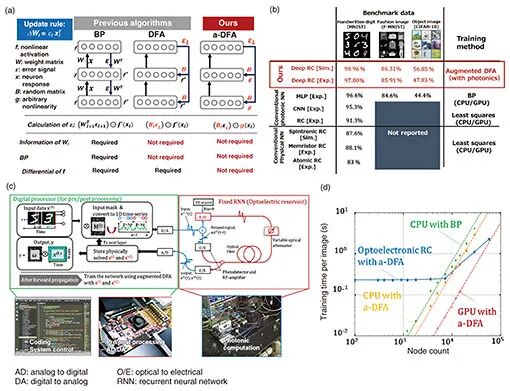
该算法摒弃了BP和DFA算法所用的反向误差信号,而是对最终输出层的误差信号进行固定随机线性变换,并以任意非线性函数g(a)替代物理非线性激活函数的导数f’(a)。对于标准多层感知器(MLP)网络(x(l+1) = f(a(l)),其中a(l) = W(l)x(l),W(l)为第l层权重,x(l)为第l层输入),每层误差e(l)可表示为e(l) = [B(l)e(L)] ⨀ g(a(l))(B(l)为第l层随机投影矩阵,e(L)为最终层误差),权重梯度则为δW(l) = -e(l)x(l)ᵀ。该机制无需获取原始网络信息,仅通过最终误差和随机非线性投影即可完成网络更新,且随机非线性投影可在可扩展光子引擎上执行。
该方法具有良好的可拓展性,可适配MLP-mixer、ResNet、Transformer等现代网络,以及脉冲神经网络、储层计算机等光子硬件友好型网络。数值模拟显示,在MNIST数据集上,a-DFA算法训练的各类模型准确率与BP算法(基准)相当;在光子储层计算机上的实验也验证了其有效性。基准测试表明,这种受生物启发的深度学习方法在运算速度上具备显著优势,为光子硬件的高效训练提供了全新路径。
◆ 总结:光子计算的规模化突破与未来展望
研究团队通过空间与波长的密集并行复用技术,成功实现了光子计算平台的规模化升级,矩阵乘法专用光子处理器的运算速度已达到亚拍级水平。同时,完成了片上光子储层计算机的集成研发,并创新提出受生物启发的无梯度训练算法,为模拟光子硬件提供了适配性强、效率高的学习方案。
依托光在空间、波长、时间维度的多重复用优势,可编程光子处理器在延迟、能耗和并行性上构建了对电子处理器的比较优势,既满足了机器学习对大规模张量运算的需求,又适配了光通信系统对高带宽、低损耗信号处理的要求。从实验室的技术验证到光通信、图像识别等场景的实际落地,可编程光子处理器正逐步打破传统计算的性能边界,未来随着硬件工艺的持续优化与算法的深度协同,有望成为下一代信息技术的核心支撑,开启低能耗、高并行的计算新纪元。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号