AI Agent 的“记忆革命”来了:真正的分水岭不是模型,而是记忆

AI Agent 的“记忆革命”来了:真正的分水岭不是模型,而是记忆

唐国梁Tommy
发布于 2026-06-25 21:39:33
发布于 2026-06-25 21:39:33
你有没有过这种体验:
昨天你刚跟 AI 聊完半小时项目背景,今天重新打开一个新对话框,它又像第一次见你一样,客客气气地问:“请问你的需求是什么?”
很多人第一反应是:模型还不够聪明。
但如果你认真拆开看,会发现问题根本不在“聪不聪明”,而在于它不记得你。
这其实是今天绝大多数 AI Agent 的共同短板。它们会推理、会调用工具、会写代码、会做任务,但一旦离开当前上下文,就像突然“失忆”。没有稳定的长期记忆,Agent 就很难真正变成一个持续为你工作的数字助手。
所以,接下来 AI Agent 竞争的关键,不只是模型参数,不只是工具调用,而是一个越来越重要的底层能力:
记忆系统。
最近我系统看了一批开源 Memory Framework,越看越觉得,这个方向已经不是“可选功能”,而是在重新定义下一代 Agent 的基本形态。
这一篇,我先聊 5 个最有代表性的项目:Text2Mem、Mem0、Letta、ReMe、memU。
它们看起来都在做“记忆”,但本质上代表了 5 条完全不同的路线。
读完你会发现,AI 记忆这件事,远比“存聊天记录”复杂得多。
真正的问题,不是 AI 不会回答,而是它不会持续成长
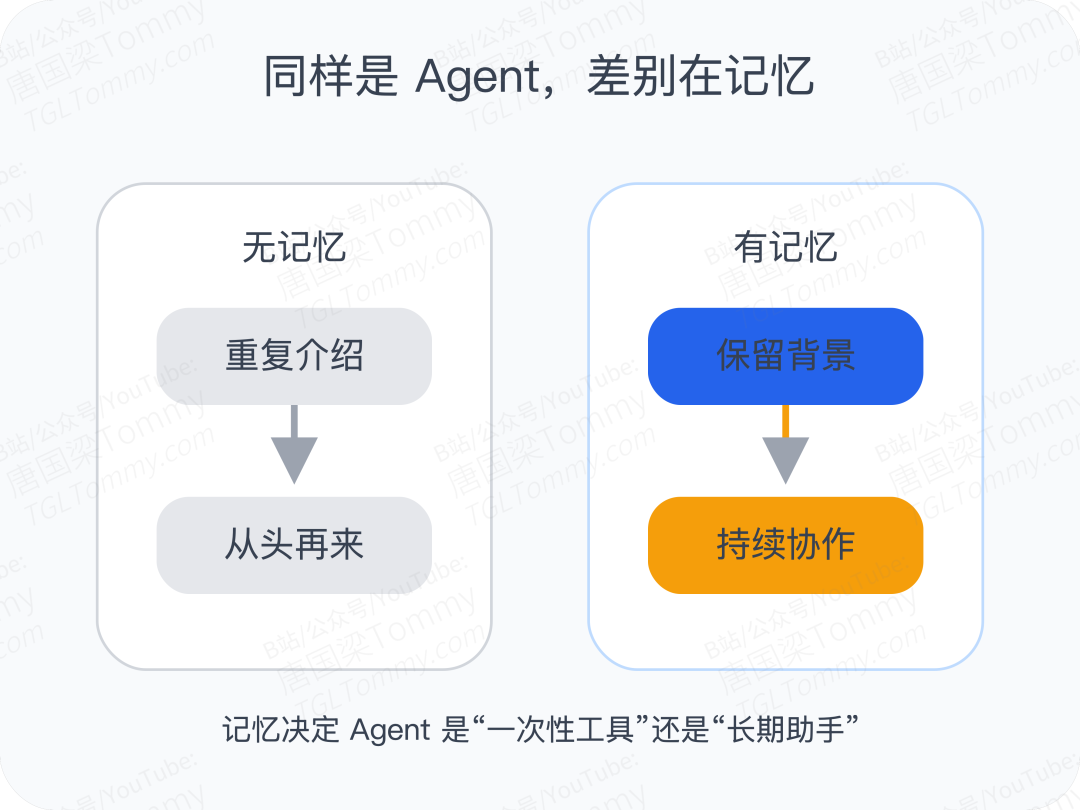
如果一个 Agent 每次都只能依赖当前上下文,那它本质上还是一个“短时工作者”。
你每次都要重新介绍背景、重复偏好、重讲规则,它当然也能完成任务,但这种体验很难称得上“智能”。
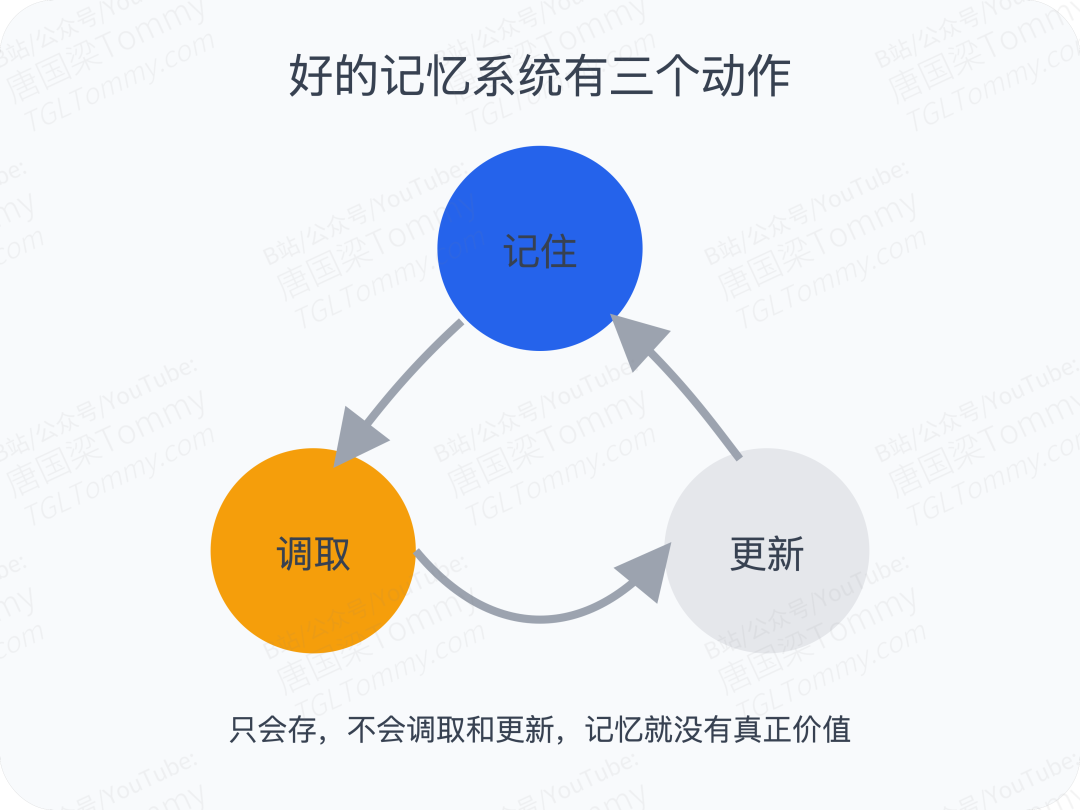
真正有价值的 Agent,应该具备三种能力:
第一,记住。 记住用户偏好、历史任务、重要事实、曾经失败过的方式。
第二,会调取。 不是机械地把所有历史塞回上下文,而是在合适的时候,把真正相关的记忆召回出来。
第三,会更新。 记忆不是档案柜,而是会变化的。旧理解会被修正,弱信息会淡化,关键经验会被强化。
问题就在这里: 今天市面上很多“带记忆”的 Agent,其实只做到了第一层,甚至只是“伪记住”。
而这 5 个项目的有趣之处,就在于它们分别在回答同一个问题:
Agent 的记忆,到底应该怎么设计?
Text2Mem:它不是在做记忆系统,而是在给“记忆操作”定义语法
我想先讲一个没那么火、但非常值得重视的项目:Text2Mem。
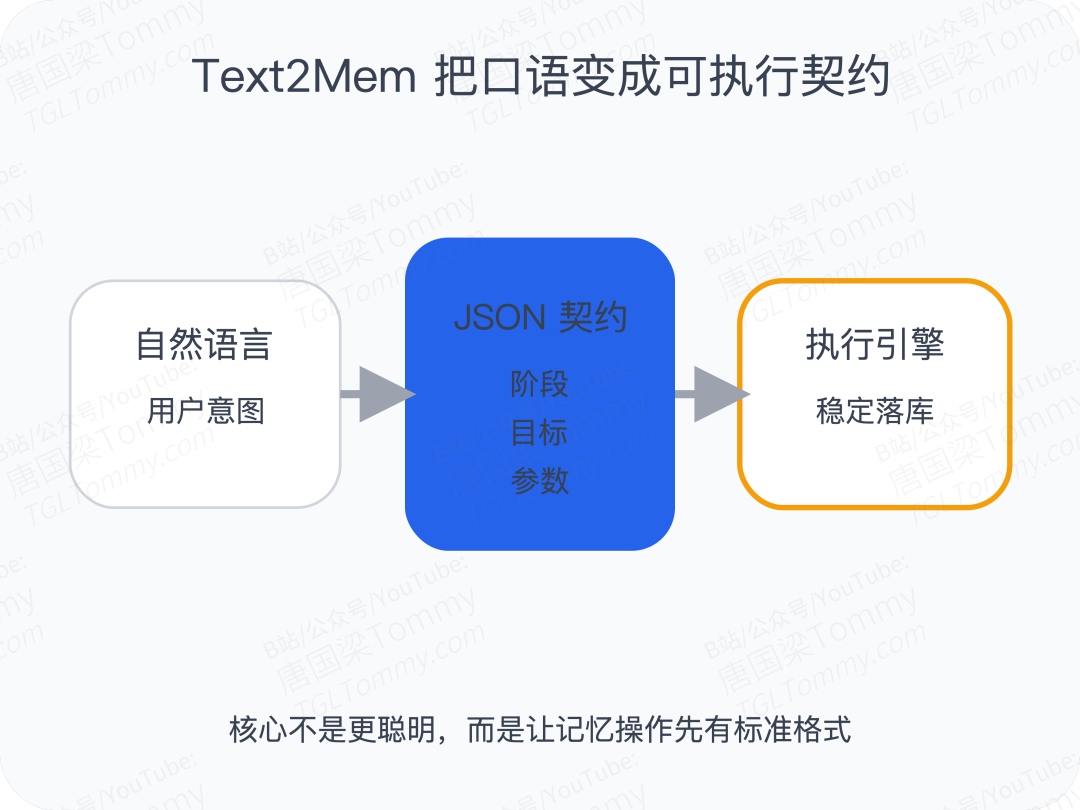
它最有意思的地方在于,它并没有直接去做一个大而全的 Memory 产品,而是在更底层回答一个问题:
如果 AI 要操作记忆,是否应该先有一套标准“指令集”?
这件事听起来很抽象,但非常关键。
因为自然语言本身是模糊的。 比如你对 Agent 说:
“把我上周那份会议纪要标成重要,30 天后归档。”
人能听懂,但系统很难稳定执行。 “上周”是哪几天? “那份纪要”对应哪条记录? “标成重要”是加标签、提权重,还是设提醒? “归档”是隐藏,还是删除?
Text2Mem 的思路很像计算机体系结构里的 ISA。 它希望在自然语言和底层存储之间,加一层结构化中间表示:先翻译成标准 JSON,再执行。
它把记忆操作收敛成 12 个原子动作,覆盖写入、检索、总结、更新、合并、拆分、删除、过期、锁定等完整生命周期。
这背后最大的意义不是“功能多”,而是:
它试图把记忆系统从“凭感觉调用”,变成“可验证、可治理、可审计的系统调用”。
尤其是它里面的两个安全设计,非常像成熟软件系统的风格:
一是 dry_run,先模拟执行;
二是 confirmation,高风险操作必须显式确认。
这相当于在承认一个现实:
LLM 会出错,所以系统不能只相信 LLM。
这也是 Text2Mem 最值得学习的地方。它的真正价值,不在于今天能不能直接大规模上线,而在于它在为整个行业回答一个更基础的问题:
未来 Agent 的记忆操作,是否应该先有统一语义层?
如果答案是“应该”,那 Text2Mem 这类项目,就是在打地基。

Mem0:它为什么会成为很多团队的第一选择?
如果说 Text2Mem 更像“标准层”,那 Mem0 就是目前最典型的“工程层”。
它之所以火,很简单,因为它解决的是一个特别现实的问题:
怎么给 Agent 快速补上一套能用的长期记忆?
很多团队做产品时,真正卡住的不是“有没有理论创新”,而是“我明天能不能接进业务里”。
Mem0 的吸引力就在这里。 它把记忆做成了一套成熟的中间件:

- 上面是统一的 Memory API
- 中间是 LLM 推理、检索、重排
- 下面可以接各种向量库、图数据库、模型服务
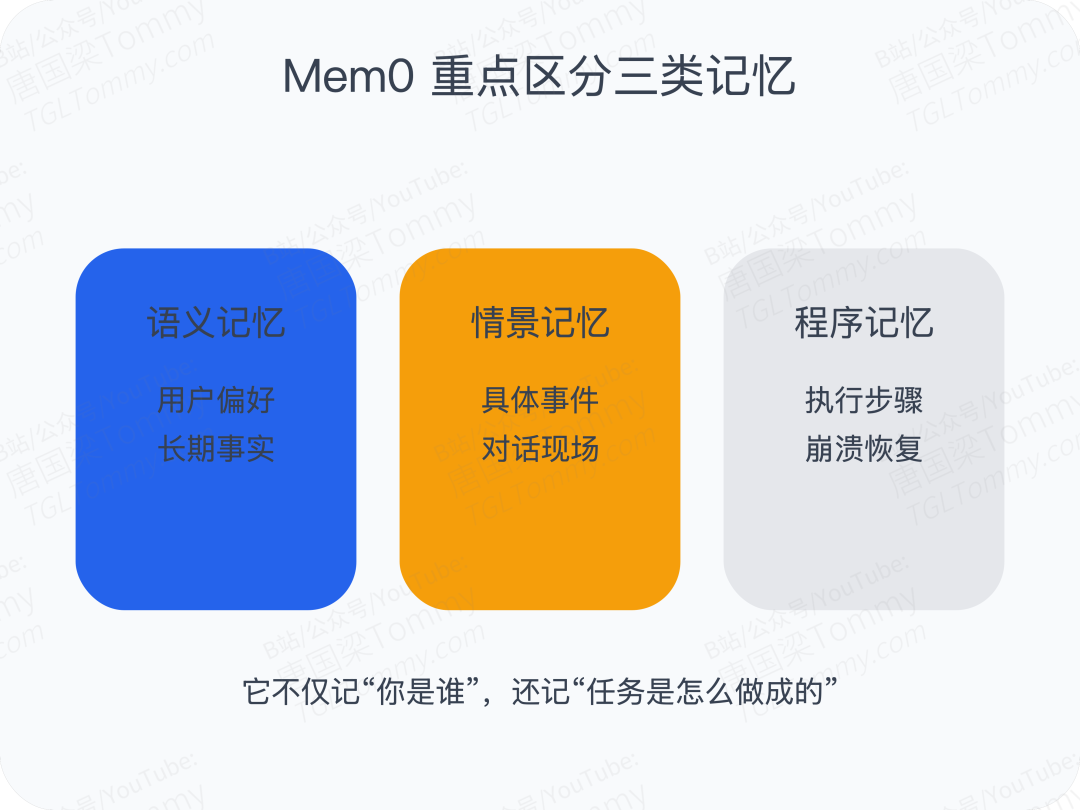
它还显式区分了三类记忆:
语义记忆,比如“用户喜欢简洁回复”; 情景记忆,比如“昨天用户刚讨论过新产品发布”; 程序记忆,比如“这个任务上次是怎么一步步执行成功的”。
这里最值得注意的是“程序记忆”。
很多人一提记忆,就只想到用户画像和偏好。但真正复杂的 Agent 系统里,还有一类极其重要的内容,是执行过程本身。如果一个多步骤任务中途崩了,Agent 能不能恢复现场,很大程度取决于程序记忆保存得够不够完整。
从这个角度说,Mem0 的设计是比较务实的。它不是在追求最炫的概念,而是在做真正能落地的基础设施。
当然,它的问题也很明确。
它的完整记忆更新链路会带来不低的 LLM 调用成本,而且随着历史记忆增多,单次写入的 token 开销会不断上升。也就是说,Mem0 很适合“对话级、用户级、中低频写入”的产品,但不一定适合那种高频实时写入、对成本极度敏感的场景。
所以我对 Mem0 的评价是:
它不是最先锋的,但它是最像“工业方案”的。
如果你现在就要给产品接入记忆层,Mem0 很可能仍然是最现实的起点之一。
Letta:这个项目最狠的地方,是把操作系统思维搬进了 Agent
接下来这个项目,我认为是这 5 个里“架构野心”最强的一个:Letta。
它的前身很多人可能更熟,叫 MemGPT。 如果你还记得那篇著名论文《MemGPT: Towards LLMs as Operating Systems》,那你大概能理解 Letta 的核心野心:
把 LLM 当成一个有限上下文的计算核心,再用类似操作系统的方式去管理它的记忆。

这是一个非常不一样的思路。
Letta 不是把记忆简单看成“外挂数据库”,而是把它拆成了三层:
Core Memory:始终在上下文里、每轮都能直接看到的核心记忆。 Archival Memory:需要时再检索的归档记忆。 Recall Memory:存放历史对话记录,支持回看和召回。
这套设计几乎就是在映射操作系统:
- Core Memory 像 RAM
- Archival Memory 像磁盘
- Recall Memory 像日志系统
更关键的是,当上下文快装不下时,Letta 不是简单裁掉旧消息,而是做“摘要压缩 + 外部存储 + 需要时再召回”的分层迁移。
这意味着: 信息不是被丢弃,而是被换层。
这和很多常见 Agent 的“超过窗口就没了”完全不是一个级别的设计。
Letta 还有一个很值得讲的点:它把记忆做成了可版本化对象。
也就是说,记忆不是“改了就改了”,而是像代码一样可以追踪历史、审计变更、回看演化过程。这个思路非常强,因为它让 Agent 的“认知变化”第一次变得可追溯。
某种意义上说,Letta 想做的已经不是“给 Agent 加记忆”,而是:
定义有状态 Agent 的操作系统。
它当然更重、更复杂、认知门槛更高,但如果你想研究“长期运行的 Agent 到底该怎么管理上下文和记忆”,Letta 是绕不过去的项目。
ReMe:记忆不应该是黑盒,用户应该看得见、改得动
前面几个项目,大多还是在系统内部处理记忆。 而 ReMe 最打动我的地方,是它把视角拉回到了人本身。
它的核心哲学可以概括成一句话:
文件即记忆。
什么意思?
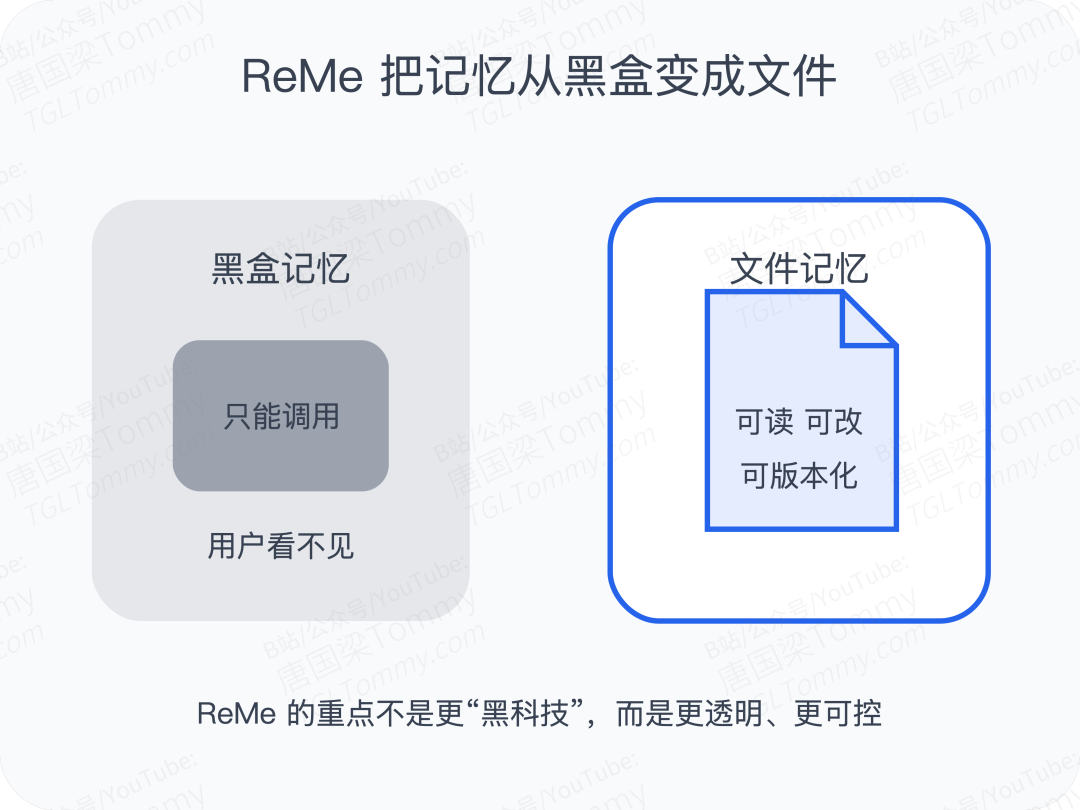
很多记忆系统把所有内容都存进数据库或者某个封装层,用户想知道 AI 记住了什么,必须通过接口去查。你本质上是在信任一个黑盒。
ReMe 不一样。 它直接把记忆写成 Markdown 文件,放在你能看见、能编辑、能版本控制的目录里。
这背后的价值非常大:
记忆的控制权,重新回到了用户手里。
你不需要猜 AI 是怎么理解你的。 你可以直接打开文件,看到它记了什么; 如果记错了,你也可以直接改。
这种设计在今天非常重要。因为随着 Agent 越来越深地参与个人工作流,记忆已经不是一个小功能,而是在逐渐变成“数字人格”的一部分。 如果这部分完全不可见、不可干预,长期来看其实是有风险的。
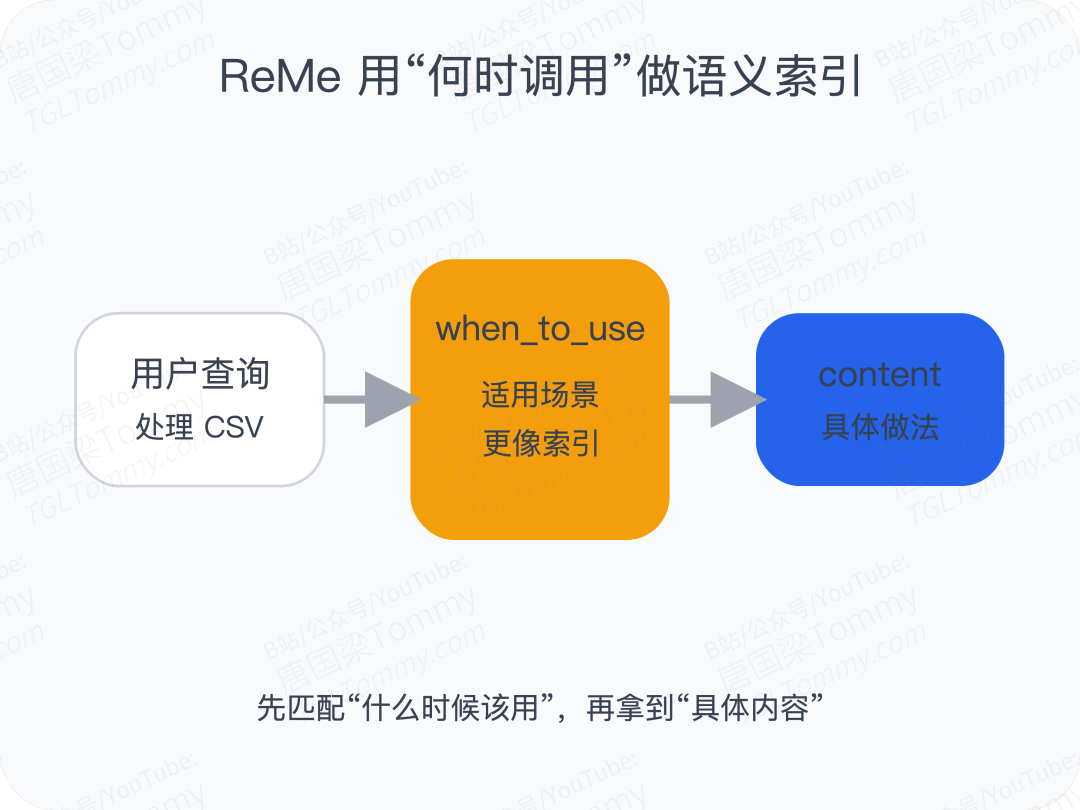
ReMe 还有一个很聪明的技术细节: 它把一条记忆拆成两部分:
content:记忆本身的内容when_to_use:这条记忆应该在什么情况下被召回
然后它主要用 when_to_use 去做向量检索。
这看起来反直觉,但非常聪明。因为用户发起查询时,说的往往是“我要做什么”,而不是“那段记忆本身长什么样”。把“使用场景”做成语义索引,检索效果反而更好。
所以 ReMe 代表的不是“更强自治”,而是另一条路线:
记忆系统不仅要服务 Agent,也要服务人。
如果说 Letta 更像“系统工程师的答案”,那 ReMe 更像“用户主权视角下的答案”。
memU:最激进的变化来了,记忆本身开始变成一个 Agent、改得动
最后一个项目,是我觉得最有“范式转换”意味的:memU。
前面讲的 Text2Mem、Mem0、Letta、ReMe,虽然路线不同,但有一个共同点:
记忆始终是被调用的。
用户说一句话,系统去写一条; 用户问一个问题,系统去查一次; 本质上,记忆还是一个“等着被使用的对象”。
但 memU 想做的,是把这个关系反过来。
它的思路是:
让记忆自己成为一个持续运行的后台 Agent。
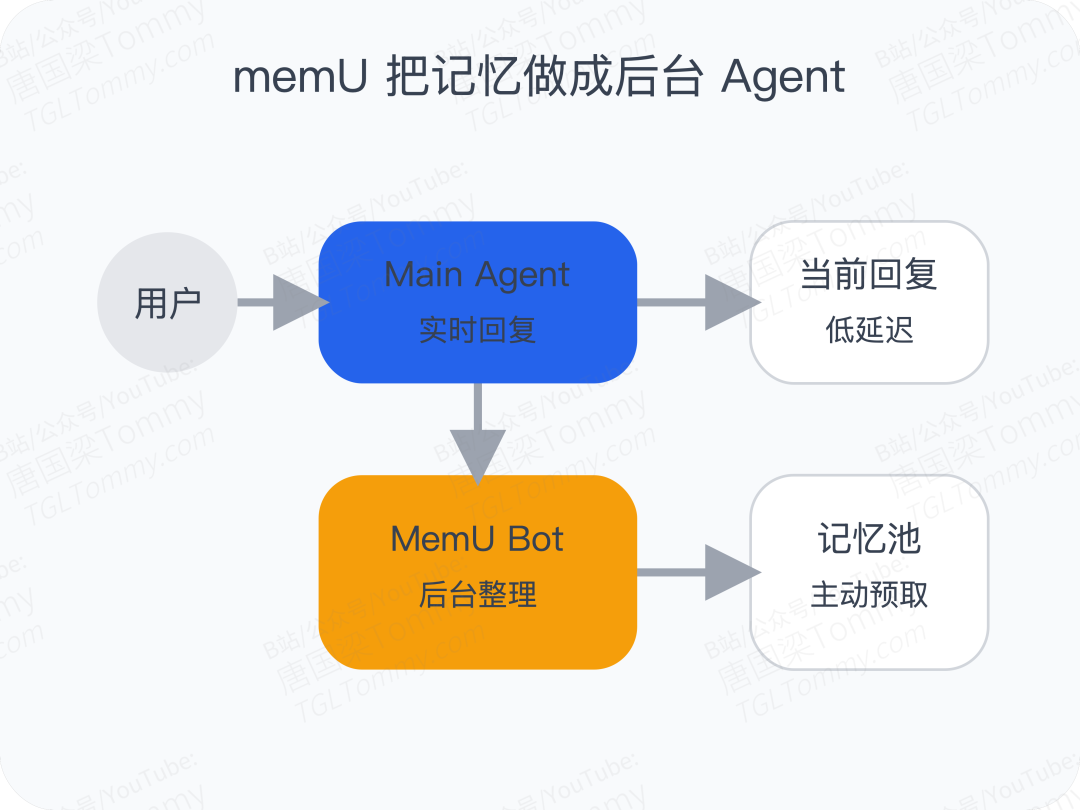
在它的架构里,前台有 Main Agent 负责对话和执行; 后台有 MemU Bot 持续观察交互、整理信息、提取记忆、预测下一步需要什么上下文。
这件事听上去像是一个小变化,但实际上非常大。
因为它意味着,记忆不再只是“存储层”,而变成了一个主动工作的智能体。 它不是等用户发问才检索,而是在用户还没发问之前,就开始准备。
这种模式特别适合什么场景?
就是那些真正强调长期陪伴、长期学习的场景:
- 个人 AI 助手
- 企业客服
- 研究型助手
- DevOps Agent
- 交易或策略类 Agent
因为这些场景的核心价值,从来都不是“一次性回答”,而是越来越懂你、越来越像你身边那个一直在线的协作者。
memU 里还有一个我很喜欢的机制,叫显著性感知记忆。 简单说,就是一条记忆被检索得越频繁,它的权重越高,之后也越容易再次被召回。
这很像人类记忆: 你越常想起的事情,就越牢; 长期不用的事情,就会自然淡化。
所以 memU 最值得注意的,不只是性能数字,而是它背后的方向感:
从“Agent 拥有记忆”,走向“记忆本身就是一个 Agent”。
这可能是未来几年最值得盯紧的一条路线。
这 5 个项目,实际上对应了 5 种完全不同的记忆哲学
如果把它们放在一起看,会很清楚:
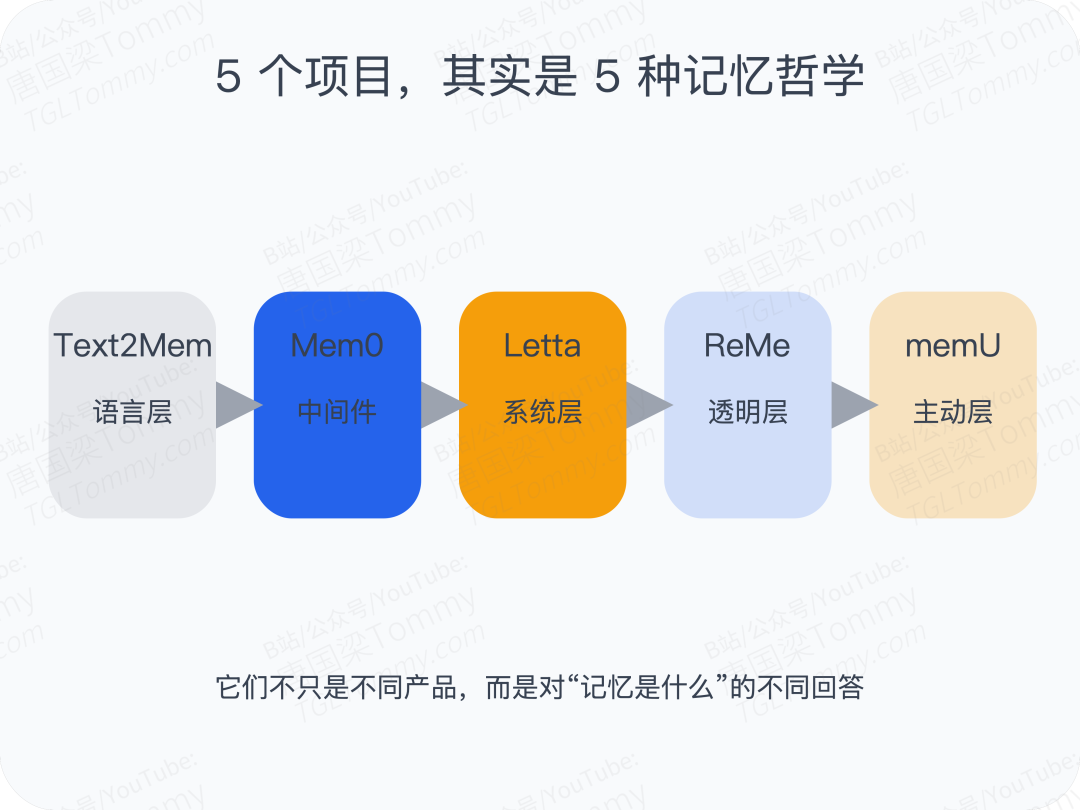
Text2Mem 在回答的是: 记忆操作能不能先标准化?
Mem0 在回答的是: 能不能把记忆做成开箱即用的基础设施?
Letta 在回答的是: 能不能像操作系统一样管理 Agent 的有限上下文?
ReMe 在回答的是: 记忆能不能透明、可编辑、真正属于用户?
memU 在回答的是: 记忆能不能不再被动等待,而是主动运行?
这也是为什么我越来越觉得,AI 记忆这件事的竞争,已经不只是“谁召回更准”,而是:
你相信哪一种 Agent 未来。
你相信的是一个“有外挂存储”的工具? 还是一个“能自我管理认知”的系统? 或者一个“始终在后台默默学习你”的数字协作者?
这背后其实不是技术选型而已,而是产品哲学。
如果你今天就要选一条路线,我的建议很直接
如果你是产品团队,想尽快给 Agent 补长期记忆能力,优先看 Mem0。 它最像成熟中间件,接得快,工程路径也清晰。
如果你想研究“真正有状态的 Agent”怎么做,重点看 Letta。 它代表的是更系统级的答案。
如果你特别在意记忆透明度、可迁移性、可人工干预,ReMe 很值得关注。 它对“人和 AI 如何共同维护记忆”这个问题,给出了很有启发性的方案。
如果你更关心主动记忆、后台学习、长期陪伴,memU 是最该盯的项目。 它可能代表下一阶段的 Agent 形态。
而如果你做的是研究、协议、框架抽象,Text2Mem 的意义会非常大。 它不是最热闹的那个,但很可能是未来很多系统都会回头参考的那个。
结语:下一个分水岭,不是更大的模型,而是更好的记忆
过去两年,大家都在追模型能力。 谁更强,谁上下文更长,谁推理更快。
但走到今天,一个越来越明显的事实已经浮出水面:
没有记忆的 Agent,很难真正成为“长期协作对象”。
它可以惊艳你一次, 但很难持续理解你。
而一旦记忆系统成熟,事情就会变得完全不同。 AI 不再只是一次次响应,而会开始积累关系、沉淀经验、修正判断,甚至形成自己的“认知历史”。
那时候,Agent 才不只是一个会回答问题的模型。 它会更像一个真正和你一起长期工作的数字伙伴。
这,才是“记忆革命”真正值得关注的地方。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号