OpenClaw 记忆系统:AI Agent 如何拥有持久记忆

OpenClaw 记忆系统:AI Agent 如何拥有持久记忆

唐国梁Tommy
发布于 2026-06-25 21:17:13
发布于 2026-06-25 21:17:13
深入剖析 OpenClaw 开源项目的 Memory 模块——一套融合向量检索、全文搜索与时间衰减的混合记忆引擎,看一个开源团队如何让 AI 真正"记住"你。
想象这样一个场景:你花了半小时向 AI 助手解释你的项目架构、编码偏好和团队规范,得到了一次满意的协作体验。第二天你带着新问题回来,它却一脸茫然——"请问您的项目使用什么技术栈?"
每一次对话从零开始,是当前 AI 助手最大的体验短板之一。
这不是模型不够聪明,而是它缺少一个关键能力:记忆。
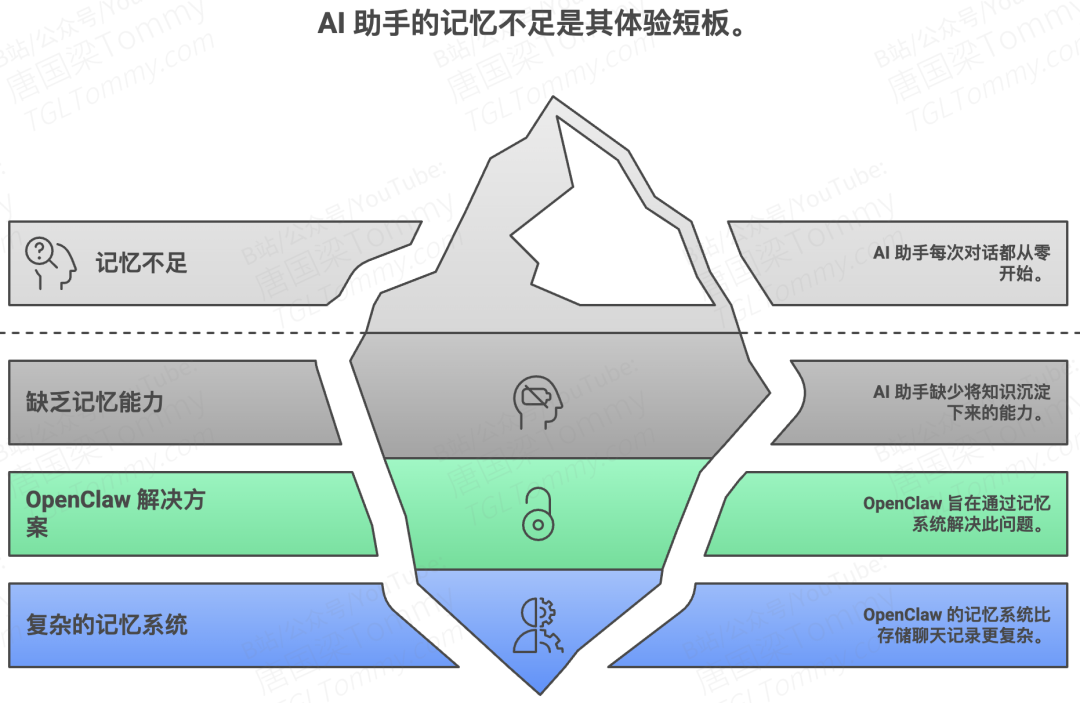
OpenClaw 是一个开源的个人 AI Agent 网关平台,它试图从根本上解决这个问题。在它的架构中,有一个专门的 Memory System(记忆系统),负责将你与 AI 交互中产生的知识沉淀下来,并在未来的对话中精准地"想起"你需要的内容。
这套系统的设计远比"存几条聊天记录"复杂得多。接下来,让我们深入源码,看看它是如何运作的。
架构:分层设计,各司其职
OpenClaw 的记忆系统位于 src/memory/ 目录下,由约 70 个 TypeScript 源文件组成。
整个模块采用三层类继承架构:
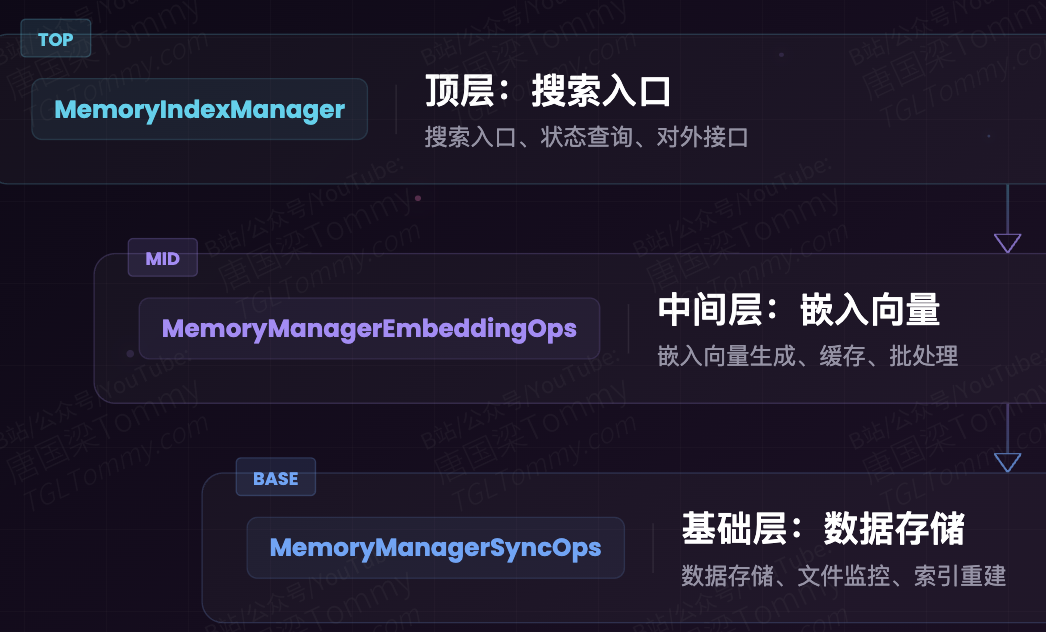
打个比方:基础层是图书馆的“书架管理员”,负责图书的入库、上架和盘点;中间层是“翻译官”,把文字转化为机器能理解的数学向量;顶层是“导览员”,面对读者的提问迅速找到最相关的书页。
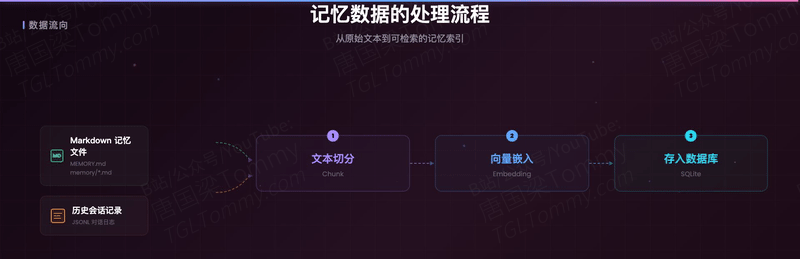
记忆的数据来源有两类:一是用户主动维护的 Markdown 记忆文件(如 MEMORY.md、memory/*.md),二是历史会话记录(JSONL 格式的对话日志)。系统将这些文本切分为 chunk(文本块),生成嵌入向量后存入 SQLite 数据库,建立起可被高效检索的记忆索引。
下面这张图展示了记忆从"写入"到"检索"的完整数据流:
混合搜索:让精确匹配与语义理解并肩作战
记忆存下来了,关键在于”怎么搜“。
假设你的记忆库里有一段关于 Python 装饰器的笔记。当你直接搜索"Python 装饰器"时,传统的全文检索就能轻松命中。但当你换一种说法——"怎么给函数加额外行为"——全文检索就无能为力了,因为查询中没有出现"装饰器"这个词。
这就是为什么 OpenClaw 实现了 BM25 + 向量语义的混合搜索(Hybrid Search):
- BM25 全文检索基于 SQLite FTS5 引擎,擅长精确的关键词匹配,速度极快。
- 向量语义检索通过嵌入模型将文本转化为高维向量,基于余弦相似度捕捉语义层面的关联。
两路结果通过加权融合汇成一条河:
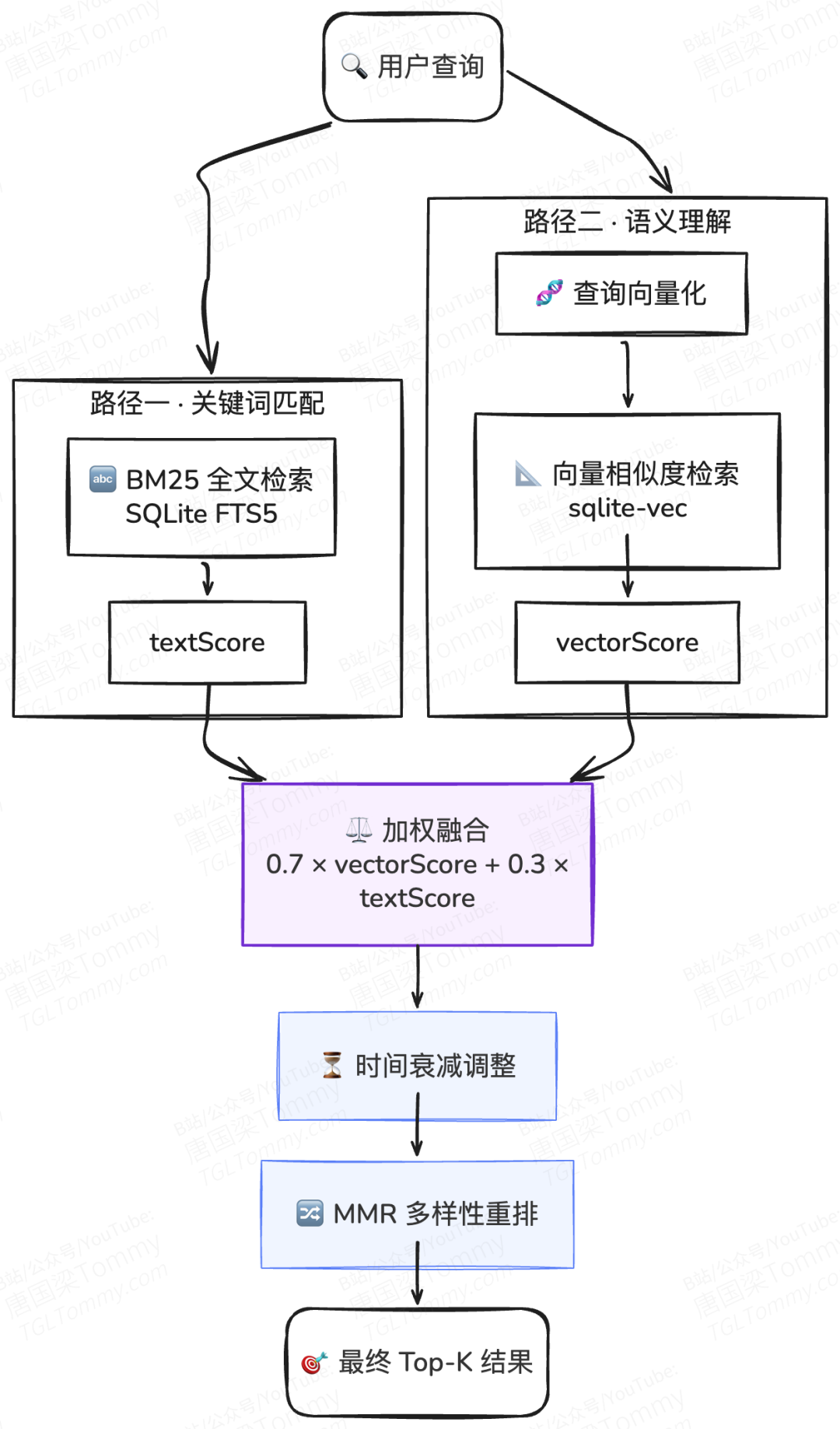
默认 7:3 的权重配比,让语义理解主导搜索方向,同时保留精确匹配的锚定能力。当用户搜索专有名词或特定代码片段时,BM25 的权重会自然发挥更大作用;而面对模糊的自然语言提问,向量检索则挑起大梁。
时间衰减:模拟人类记忆的"遗忘曲线"
混合搜索解决了"搜什么"的问题,但还有一个维度同样重要:时间。
三天前讨论的 bug 修复方案,和三个月前随口提到的一个想法,它们在记忆中的权重应该一样吗?显然不应该。
OpenClaw 引入了指数时间衰减模型,灵感直接来源于心理学中的遗忘曲线:
衰减后得分 = 原始得分 × e^(-λ × 天数)其中 λ 由半衰期决定(默认 30 天)。含义很直观:一条记忆经过 30 天后,检索权重衰减为原来的一半;60 天后只剩四分之一。近期内容被优先呈现,久远信息逐渐退居幕后。
但这里有一个值得细品的设计——常青记忆(Evergreen Memory)。
系统通过文件路径模式自动区分两类知识:
- 常青知识:
MEMORY.md(根级记忆文件)、memory/patterns.md(主题归纳)这类文件,承载的是长期稳定的核心认知,不受时间衰减影响。 - 时效信息:
memory/2024-01-15.md这类按日期命名的记录,代表某一天的具体细节,正常应用衰减。
这一区分巧妙地模拟了人类记忆的双重结构:你会忘记上周二午饭吃了什么,但不会忘记骑自行车的方法。 核心知识经久不衰,日常细节自然淡去。
MMR 重排:信息多样性的守护者
混合搜索加上时间衰减,已经能产出质量不错的结果。但还有一个隐患:信息冗余。
想象搜索"API 设计原则",如果你的记忆库中有一篇详细的 API 设计文档,前 10 条结果可能全部来自这篇文档的不同段落,内容高度重叠。这对 AI 理解上下文来说,信息密度非常低。
OpenClaw 用 MMR(Maximal Marginal Relevance,最大边际相关性)算法来对抗这种冗余。它的核心思想可以用一句话概括:
每次选择下一条结果时,不仅要与查询相关,还要与已选结果尽可能不同。
算法以贪心策略逐一挑选:
MMR(d) = λ × 相关性(d) - (1-λ) × max(与已选结果的相似度)这里有一个务实的工程决策值得注意:衡量结果间相似度时,OpenClaw 没有选择计算成本更高的余弦相似度(那需要再次调用嵌入 API),而是采用了 Jaccard 集合相似度——将文本分词后比较 token 集合的交并比。这种方法计算极其轻量,对短文本片段效果足够好,完美契合了"在后处理阶段快速去冗余"的需求。
五种嵌入源与四级降级:永不空手而归
语义检索的质量取决于嵌入向量的质量,而嵌入向量需要依赖模型来生成。OpenClaw 在这一环节展现了极强的灵活性和韧性。
系统内置了五种嵌入提供商:
提供商 | 默认模型 | 特点 |
|---|---|---|
OpenAI | text-embedding-3-small | 业界主流,质量稳定 |
Gemini | gemini-embedding-001 | 支持 API Key 自动轮换 |
Voyage | voyage-4-large | 高维度,擅长长文本 |
Mistral | mistral-embed | 多语言能力出色 |
本地 | embeddinggemma-300m (GGUF) | 完全离线,数据不出本机 |
在默认的 auto 模式下,系统按优先级链式尝试:本地模型 → OpenAI → Gemini → Voyage → Mistral。任何一个成功即可。
但真正体现工程功力的,是它的四级降级链条——当一切都不顺利时,系统如何保持服务不中断:
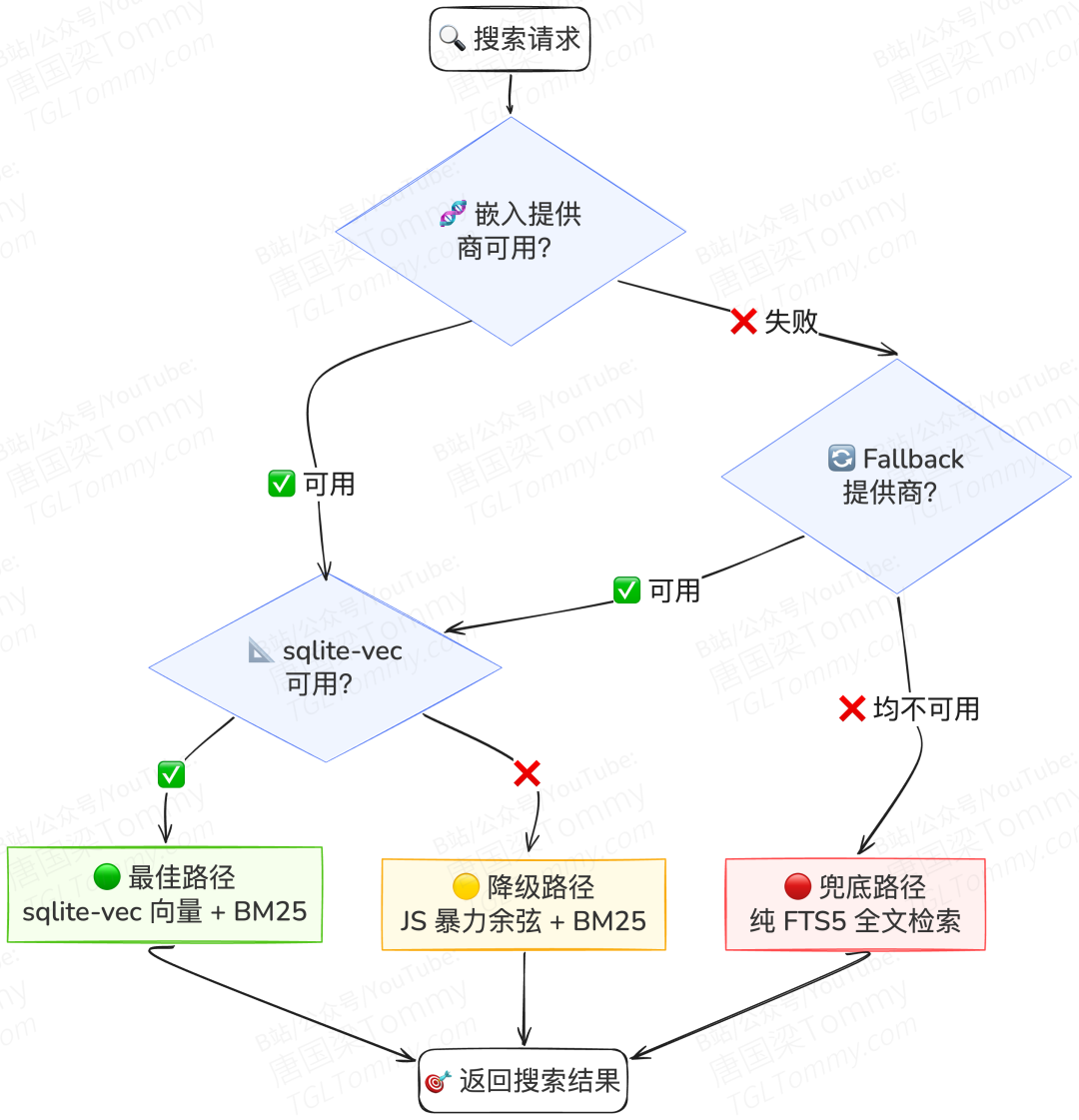
即便在最极端的情况下——没有任何 API Key,没有本地模型,没有向量扩展——系统依然能通过 SQLite FTS5 全文检索提供基本的记忆搜索。这种"绝不崩溃"的韧性设计,是面向终端用户产品不可或缺的品质。
Embedding 缓存与原子化重建:成本控制的艺术
Embedding API 调用既耗时又烧钱。如果每次索引更新都重新计算所有文本的向量,成本将不可接受。
OpenClaw 通过 embedding_cache 表实现了内容感知的缓存:以 provider + model + 文本内容哈希 为主键,同一段文本只需计算一次嵌入。当文件内容未变时,索引更新直接命中缓存,跳过 API 调用。缓存条目设有上限,按 LRU 策略淘汰最旧的记录。
更精巧的是索引全量重建的处理方式。当嵌入模型变更或配置调整需要重建索引时,系统采用"双数据库原子交换"策略:
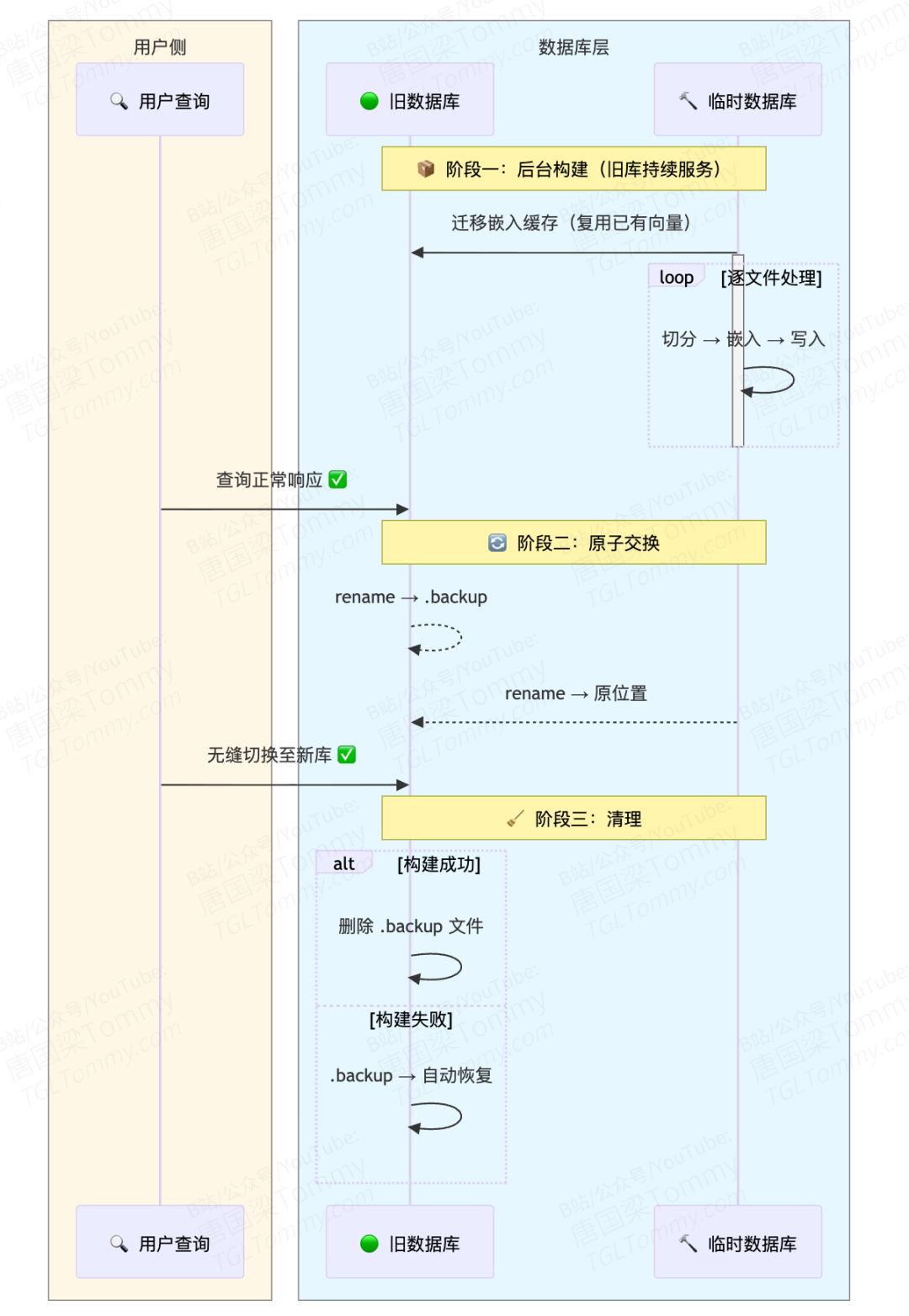
整个过程中,旧索引始终可用于查询,用户感知不到任何服务中断。这是一种典型的蓝绿部署思想在嵌入式数据库层面的应用。
实时同步:三条通道保持记忆鲜活
记忆系统不是一次性的离线构建,它需要随着用户活动持续演进。
OpenClaw 设计了三条并行的同步通道:
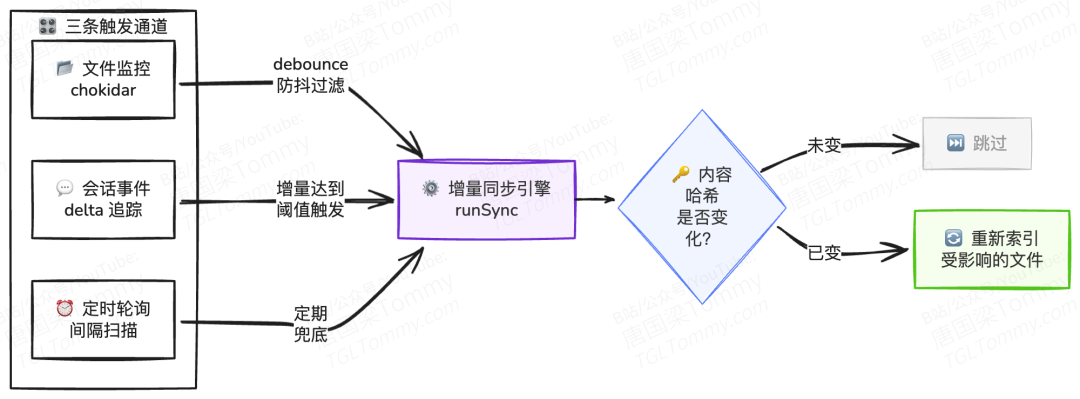
- 文件监控(chokidar):实时监听
MEMORY.md和memory/目录下的文件变化,通过防抖机制避免高频写入时的重复触发。 - 会话增量同步:最精细的一条通道。系统为每个会话文件维护 delta 追踪器,记录自上次同步以来的新增字节数和消息条数,只有当增量达到阈值时才触发索引更新,在实时性和性能之间取得平衡。
- 定时轮询:兜底机制,按配置间隔定期扫描变更,确保即使前两条通道遗漏,记忆最终也会被同步。
三条通道互为补充,构成了一个既灵敏又不过度消耗资源的同步体系。
中文检索:轻量但实用的分词方案
值得一提的是,OpenClaw 的查询扩展模块对中文做了专门的适配。
在 FTS-only 降级模式下,全文检索依赖关键词匹配,而中文的无空格连写特性让分词成为必须。引入 jieba 这样的专业分词库会增加包体积和依赖复杂度,这对一个追求轻量安装体验的 CLI 工具来说代价偏高。
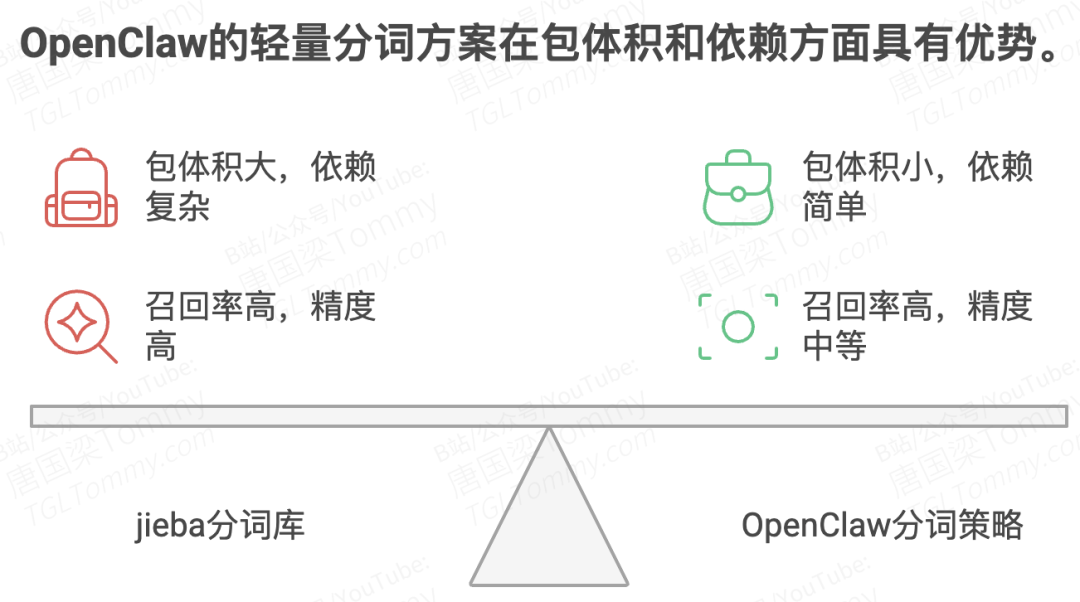
OpenClaw 选择了一种务实的折中——无词典的字级别 + bigram 策略:
输入:"之前讨论的API方案"
分词:["之", "前", "讨", "论", "方", "案", "之前", "讨论", "方案", ...]单字保证召回率(不会遗漏任何潜在关键字),bigram 捕捉常见的双字词组合。在记忆检索场景下——尤其是配合向量语义检索的补充——这已经是一个性价比很高的方案。同时系统还内置了约 80 个中文停用词("的""了""着""是"等),过滤掉无搜索价值的虚词,进一步提升检索精度。
结语:让 AI 从"工具"进化为"伙伴"
回顾 OpenClaw 的记忆系统,它的每一个设计决策都指向同一个目标:让 AI 助手与你的交互,从一次次孤立的对话,演变为一段持续积累的关系。
这套系统给我们带来的启发,不仅在于具体的技术方案,更在于它背后的工程哲学:
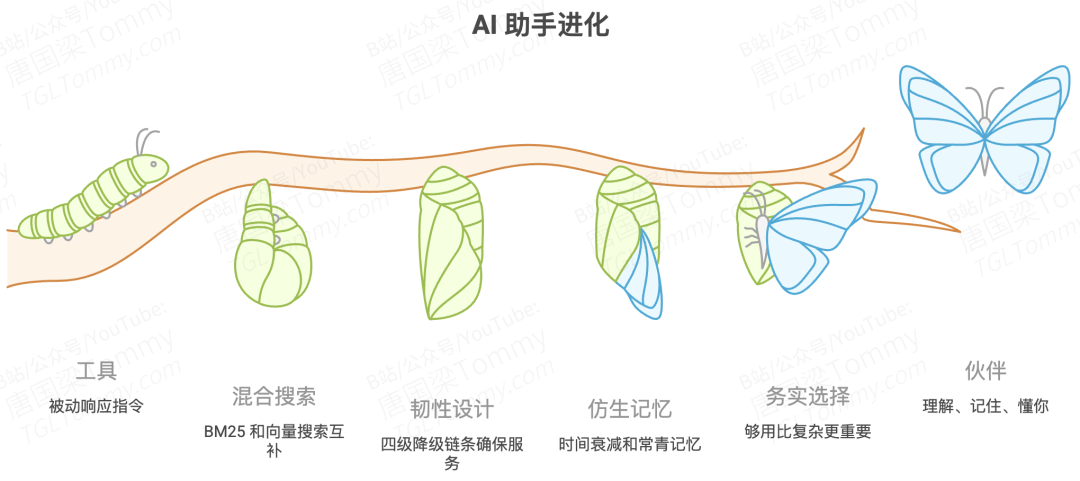
- 混合优于单一——BM25 和向量搜索各有盲区,融合才能互补
- 韧性优于性能——四级降级链条确保任何环境下都能提供服务
- 仿生优于机械——时间衰减与常青记忆模拟人类认知的自然规律
- 务实优于完美——Jaccard 替代余弦相似度、bigram 替代专业分词,在够用和复杂之间选择前者
当 AI 开始拥有记忆,它就不再只是一个被动响应指令的工具,而是一个能够理解你的偏好、记住你的上下文、随着时间推移越来越懂你的伙伴。这或许就是个人 AI 助手最迷人的前景。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号