智谱&清华 ComputerRL 解读:AI Agent学会“使用电脑”的革命性一步

智谱&清华 ComputerRL 解读:AI Agent学会“使用电脑”的革命性一步

唐国梁Tommy
发布于 2026-06-25 21:00:05
发布于 2026-06-25 21:00:05
如何让AI真正学会“使用电脑”?我们已经见证了AI在语言、图像和代码生成领域的惊人成就,但一个看似简单却极具挑战的领域仍然是AI发展的“圣杯”——让AI像人类一样,通过图形用户界面(GUI)与操作系统、软件应用进行自然交互,自主完成复杂任务。
要实现这一愿同,我们面临着巨大的技术鸿沟。然而,一篇名为《COMPUTERRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents》 的最新研究,为我们点亮了前行的道路。

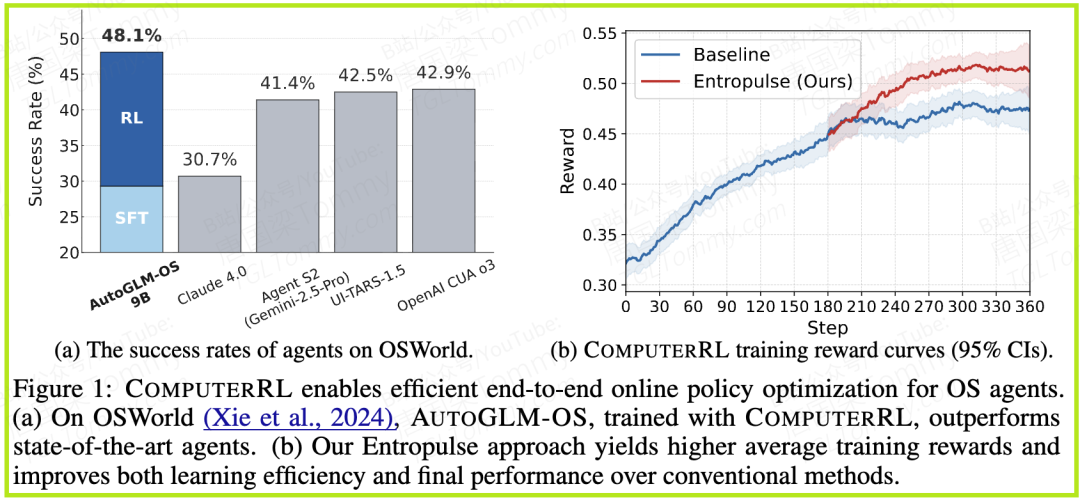
这项工作由清华大学、Zhipu AI和中国科学院的研究人员共同完成,他们提出了一个名为COMPUTERRL的端到端强化学习框架,并基于此训练出的AUTOGLM-OS模型,在权威的计算机操作基准测试OSWorld上取得了历史性的突破,以48.1% 的成功率刷新了SOTA(State-of-the-Art)记录,显著超越了来自OpenAI、Google等顶尖机构的方案。
AI智能体“使用电脑”的三大困境
在深入理解 COMPUTERRL 前,需要先弄清楚训练一个会熟练使用电脑的 AI 为什么如此困难。主要有三大挑战:

1. 界面鸿沟:
人机界面是为人类感知和操作习惯设计的,对 AI 却极不友好。它需要从像素中识别控件并模拟点击、输入等操作,一旦界面元素有微小变化,就可能导致识别失败。
2. 训练瓶颈:
- • 模仿学习(BC):简单直接,但依赖昂贵数据,泛化能力差,永远受限于“老师”的水平。
- • 强化学习(RL):理论上能超越人类,但在复杂桌面环境中效率极低,收敛慢且不稳定。
3. 环境不足:
大规模 RL 需要高效可扩展的模拟环境。但现有桌面环境通常基于虚拟机,资源消耗大、不稳定,难以支撑大规模并行训练。
COMPUTERRL 的出现,正是为了解决这三大难题。
核心内容:COMPUTERRL的三大创新支柱
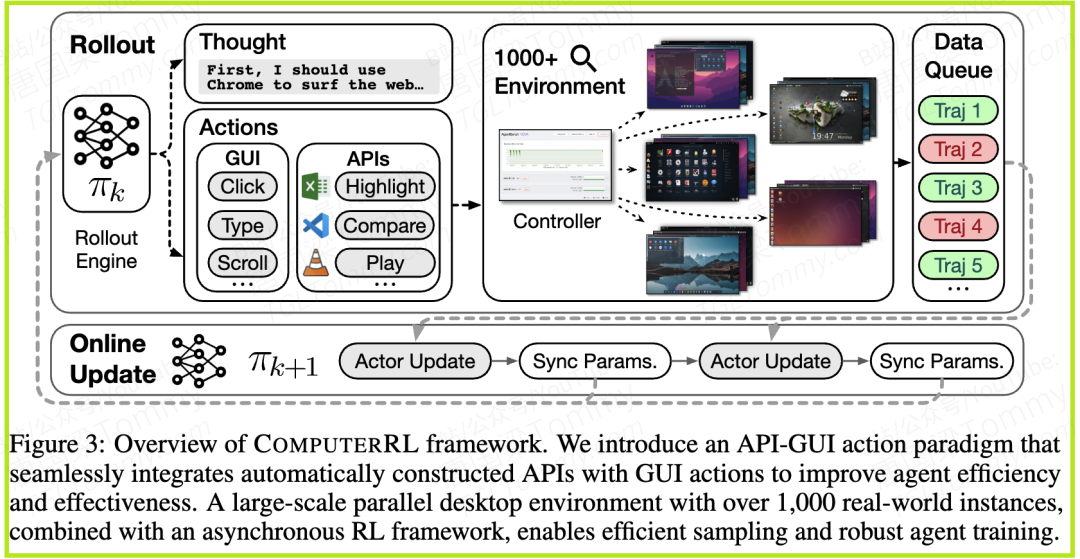
COMPUTERRL并非单一的算法改进,而是一个集成了交互范式、基础设施和训练策略的综合性解决方案。我们可以将其理解为三大创新支柱,共同支撑起高效的计算机智能体训练体系。
支柱一:API-GUI混合范式
面对GUI交互的低效,COMPUTERRL提出了一个优雅的解决方案:API-GUI混合范式。
- • 什么是API-GUI?
它不再强迫AI完全像人一样“点点点”,而是将两种操作方式结合起来:
- • API调用:对于那些有程序接口(API)的应用,AI可以直接调用API来完成任务。例如,在电子表格中设置单元格的值,不再需要模拟鼠标点击和键盘输入,只需一条命令
CalcTools.set_cell_value('B2', '=SUM(Sheet1.B2:B7)')即可完成,既快又准。 - • GUI操作:对于没有API或API功能不全的应用,AI则回退到传统的GUI操作模式,通过视觉识别和模拟键鼠来完成任务。
- • API调用:对于那些有程序接口(API)的应用,AI可以直接调用API来完成任务。例如,在电子表格中设置单元格的值,不再需要模拟鼠标点击和键盘输入,只需一条命令
这种混合模式,让AI在效率和通用性之间取得了完美的平衡。它优先使用高效的API,同时保留了GUI操作作为“万能后备”,确保能应对任何应用场景。论文的消融实验也用数据证明了这一点:在同一基座模型下,API-GUI范式的平均任务成功率(26.2%)是纯GUI范式(11.2%)的2.34倍,性能提升高达134%。
- • 如何解决API开发的难题? 你可能会问,为成千上万的应用开发API岂不是一项浩大的工程?COMPUTERRL巧妙地利用LLM本身的能力,设计了一套自动化API构建工作流:
- 1️⃣需求分析:开发者只需提供一些任务示例(比如,“在GIMP中调整图片对比度”),LLM就会自动分析出完成任务所需的核心功能。
- 2️⃣代码实现:接着,LLM会自动调用该应用的Python库(如果存在的话),编写出实现这些功能的API代码,甚至还会贴心地加入错误处理和日志记录。
- 3️⃣测试生成与修复:最后,LLM还会为生成的API编写单元测试用例,进行自动测试。如果测试失败,它会分析错误信息,并尝试自动修复代码,直到所有测试通过为止。
这个自动化流程极大地降低了API的开发门槛,使得为新应用快速构建一套专用API成为可能。
支柱二:分布式RL基础设施
为了解决训练环境的瓶颈,COMPUTERRL团队重构了底层的训练基础设施,将其从一个“单机作坊”升级为了一个“云端工厂”。
- • 核心技术:他们利用了
qemu-in-docker技术,将完整的Ubuntu桌面环境封装在轻量级的Docker容器中。这相比传统的虚拟机方案,大大降低了每个环境的资源消耗。 - • 分布式集群:基于gRPC(一种高性能的远程过程调用框架),他们将多个物理服务器节点连接成一个统一的、可集中管理的分布式集群。这使得系统能够轻松扩展,支持数千个桌面环境同时在线运行。
- • 解耦与监控:通过标准的AgentBench API,智能体的训练后端与环境执行前端完全解耦,互不干扰。同时,系统还提供了一个Web监控界面,让研究人员可以实时观察数千个AI的“训练实况”。
这个强大的基础设施,为大规模、高效率的强化学习数据收集奠定了坚实的基础,解决了以往RL训练中“僧多粥少”(智能体多,环境少)的窘境。
支柱三:Entropulse训练策略
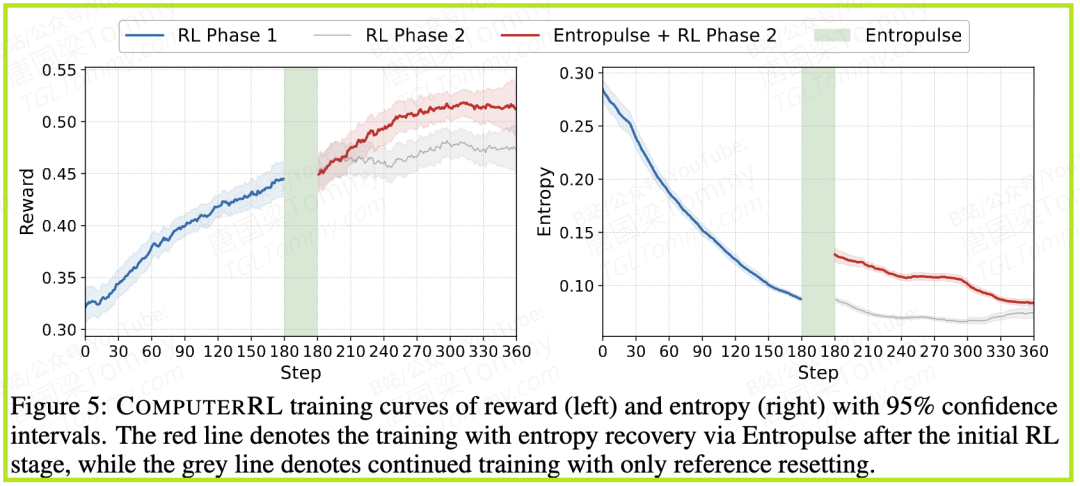
这是COMPUTERRL在算法层面的核心创新,它巧妙地解决了强化学习中一个棘手的问题——熵崩溃(Entropy Collapse)。
- • 什么是熵崩溃? 在RL训练的后期,智能体的策略会逐渐收敛,倾向于反复使用那些它认为最有效的少数几个动作(即“套路”)。这会导致策略的熵(可以理解为动作选择的随机性或多样性)急剧下降。虽然这能提高在已知任务上的表现,但也让智能体失去了探索新策略的能力,陷入了局部最优,无法取得进一步的突破。就像一个游戏玩家只练习一种战术,虽然熟练,但遇到能克制这种战术的对手时就束手无策。
- • Entropulse如何解决? Entropulse策略的灵感来源于一个观察:监督微调(SFT)和强化学习(RL)的目标是不同的。RL旨在“利用”现有知识以获得最高奖励,而SFT旨在“模仿”多样化的专家数据。Entropulse巧妙地将二者结合,形成了一个“RL → SFT → RL”的训练流程: 1️⃣第一轮RL训练:首先,让智能体进行标准的RL训练。在这个过程中,收集所有成功完成任务的轨迹。这些轨迹来自不同训练阶段的策略,因此包含了非常多样化的、行之有效的解决方案。 2️⃣Entropulse(SFT阶段):当模型性能开始停滞、策略熵下降时,暂停RL。用上一步收集到的成功轨迹数据集,对模型进行一次监督微调。这相当于让模型“复习”一遍所有已知的成功经验,强行将多样化的行为模式注入到当前单一化的策略中。 3️⃣第二轮RL训练:经过SFT“充电”后,模型的策略熵会显著回升(见论文图5),探索能力被重新激活。此时再进行第二轮RL训练,模型就更有可能跳出此前的局部最优,达到新的性能高峰。
这个过程就像一位遇到瓶颈的运动员,通过观看自己和其他顶尖选手的比赛录像(SFT),学习多样的战术,然后再回到训练场(RL),从而突破自我。
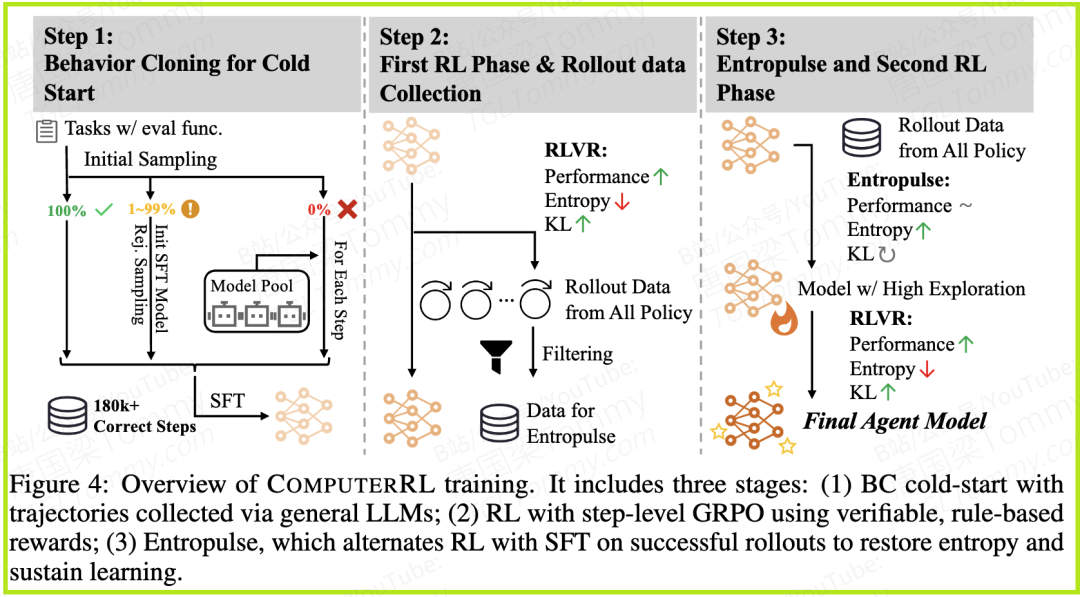
方法解析:COMPUTERRL的“三步走”训练流程
COMPUTERRL的整个训练流程设计得非常系统化,可以概括为以下三个阶段(见论文图4):
阶段一:行为克隆冷启动
任何AI的训练都需要一个初始模型。COMPUTERRL通过行为克隆来构建这个“种子选手”。但与传统方法不同,它追求的是数据的多样性和高质量。
- • 多模型数据采集:他们没有依赖单一的教师模型,而是使用了多个业界领先的闭源大语言模型(如GPT-4系列)来为同一个任务生成不同的解决方案。这确保了初始数据集的广度和多样性,避免了单一模型的偏见。
- • 分层抽样与数据增强:收集到的数据会根据任务完成度被分为三类:完全解决、部分解决、未解决。
- • 对于未解决的任务,他们会组建一个“模型专家团”,在任务的每一步随机选择一个表现最好的模型来执行下一步动作,通过“集体智慧”来攻克难题。
- • 对于部分解决的任务,他们会先用这些轨迹对基座模型进行微调,然后让这个“特长生”模型再去尝试解决这些任务,从而生成更高质量的轨迹。
通过这种精细化的数据策略,他们为模型打下了一个极其坚实的基础。
阶段二:基于可验证奖励的强化学习(RL Phase 1)
有了强大的初始模型后,就进入了第一轮强化学习。
- • 奖励设计:他们采用了一种非常直接且可解释的稀疏奖励机制。对于智能体执行的一整条轨迹(一系列动作),系统会自动调用一个验证函数来判断任务是否成功。
- • 如果成功,那么这条轨迹中每一个格式正确且对解决问题有贡献的动作,都会获得+1的奖励。
- • 如果失败,所有动作的奖励都为0。
这种设计避免了复杂的人工奖励工程,将智能体的行为与最终的任务目标紧密挂钩。
- • 优化算法:他们使用的是一种名为步级分组相对策略优化(Step-Level Group Relative Policy Optimization, StepGRPO) 的算法。这是一个专门为智能体训练设计的RL算法,其核心思想是在计算损失时,将同一个任务下的所有动作步骤聚合起来进行归一化,使得学习信号更加稳定。其损失函数如下:
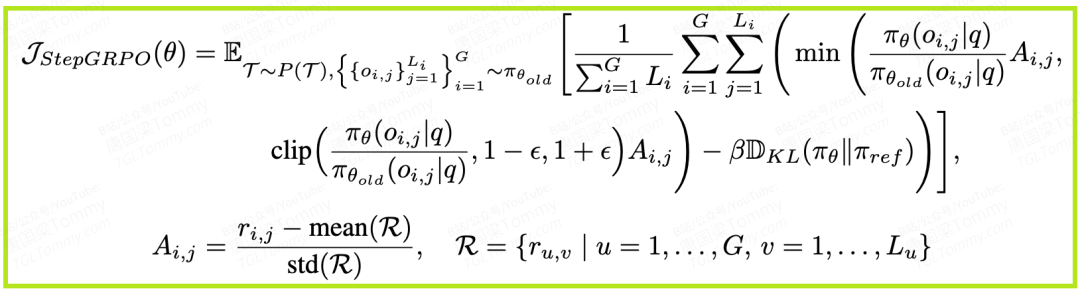
这里,代表了在第条轨迹的第个步骤上,新策略相对于旧策略的优势(Advantage),项则是为了防止新策略偏离参考策略太远而加入的惩罚。
阶段三:Entropulse与第二轮RL(Entropulse and RL Phase 2)
这正是前文提到的核心创新。当第一轮RL训练遭遇瓶颈时,启动Entropulse策略。通过SFT恢复策略的多样性后,再进行第二轮RL训练,向着更高的性能发起冲击。
实验结果与分析:数据证明一切
COMPUTERRL的强大之处不仅在于其精巧的设计,更在于其令人信服的实验结果。
- 实验设置:
- • 基准:实验在OSWorld上进行。这是一个极具挑战性的基准,它在一个真实的Ubuntu桌面环境中包含了数百个需要与文件系统、终端和各种办公软件(如LibreOffice)交互的真实任务。
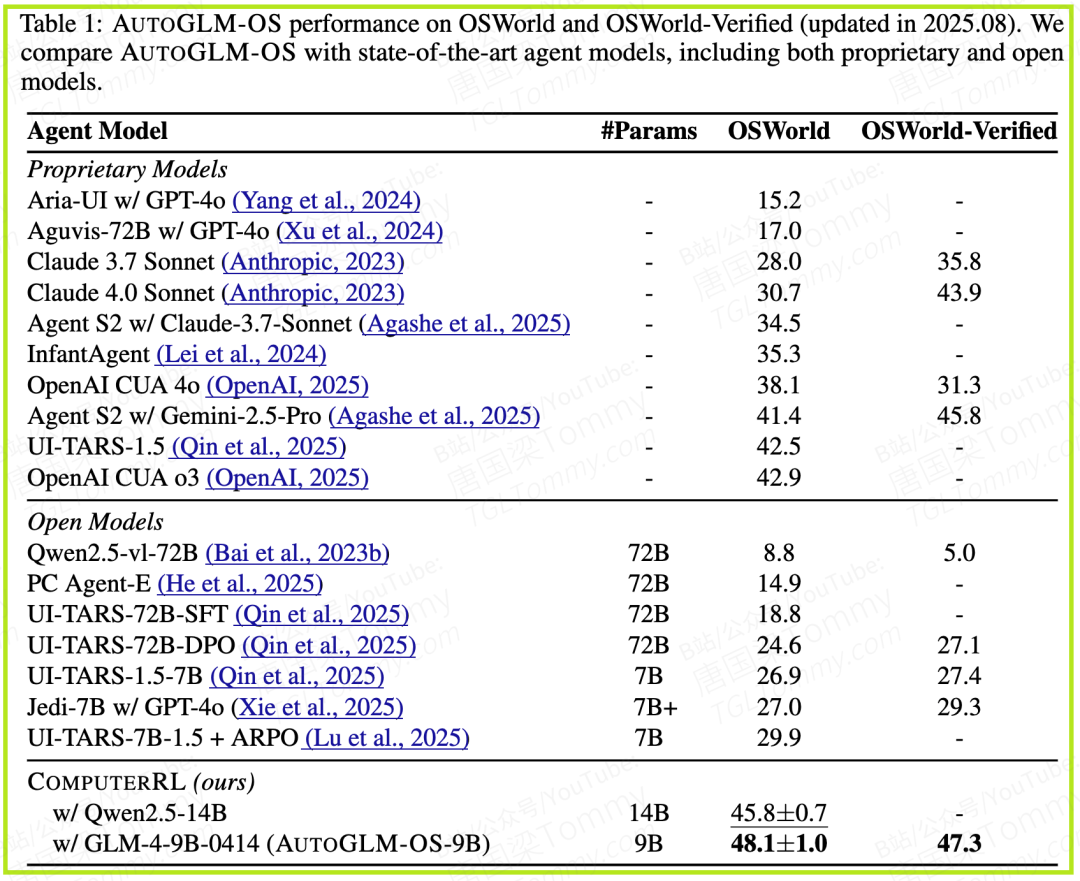
• 模型:研究人员将COMPUTERRL框架应用在了两个开源模型上:GLM-4-9B-0414和Qwen2.5-14B,训练出了AUTOGLM-OS系列模型。
• 对比对象:他们将自己的模型与包括OpenAI CUA 03、Agent S2(基于Gemini-2.5-Pro)、Claude 4.0 Sonnet在内的多个业界顶尖的闭源和开源模型进行了比较。
- 关键结果解读:
- • SOTA表现(表1):搭载了GLM-4-9B的AUTOGLM-OS-9B模型,在OSWorld上取得了48.1% 的成功率,在OSWorld-Verified(一个更严格的子集)上取得了47.3% 的成功率,全面登顶,将之前的记录保持者远远甩在身后。这证明了COMPUTERRL框架的整体优越性。
- • 消融研究(表2):这是最能体现其方法论含金量的部分。
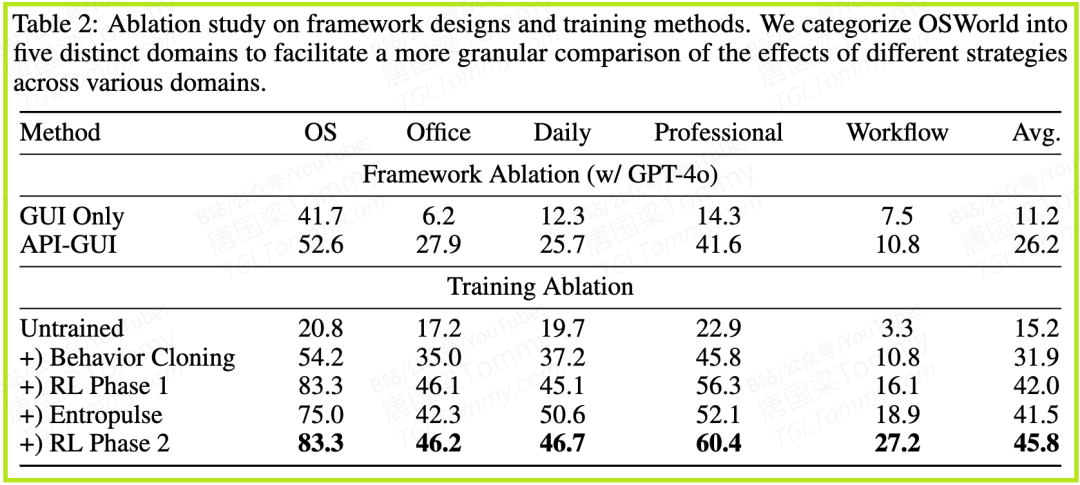
- API-GUI范式的威力:如前所述,API-GUI范式相比纯GUI范式带来了134%的巨大性能提升,尤其是在需要大量程序化操作的“办公(Office)”和“专业(Professional)”任务类别中,提升分别达到了惊人的350%和191%。
- 训练阶段的价值:模型的性能随着训练阶段的推进稳步提升,从初始的15.2%(未训练)一路跃升至最终的45.8%(完成所有阶段)。这清晰地展示了从行为克隆、到第一轮RL、再到Entropulse和第二轮RL,每一步都贡献了不可或缺的价值。
- • Entropulse的有效性(图5):论文中的训练曲线图直观地展示了Entropulse的魔力。在右侧的熵值图中,可以看到策略熵在第一轮RL后持续下降,而在Entropulse阶段被显著拉升。在左侧的奖励图中,可以看到经过Entropulse“重启”后的第二轮RL,最终达到的奖励值和性能,都超过了没有该阶段的持续训练。这为Entropulse策略的有效性提供了最直接的证据。
总结
COMPUTERRL的成功为我们描绘了通往通用计算机智能体的清晰路线图,但前路依然漫长。
总而言之,《COMPUTERRL》不仅仅是一次SOTA的刷新,它更像是一份详尽的“施工图纸”,系统性地解决了训练高效计算机智能体在交互、环境和算法层面的一系列核心难题。它所提出的API-GUI混合范式、可扩展的分布式基础设施和创新的Entropulse训练策略,无疑将对整个自主智能体领域产生深远的影响。
论文名称:ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents
第一作者:智谱&清华大学
论文链接:https://www.arxiv.org/abs/2508.14040
最新日期:2025年8月19日
github:无本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号