Nat. Mach. Intell. | 利用元学习识别抗原特异性T细胞受体结合体

Nat. Mach. Intell. | 利用元学习识别抗原特异性T细胞受体结合体

DrugAI
发布于 2026-05-08 19:56:53
发布于 2026-05-08 19:56:53
准确预测抗原肽与T细胞受体(TCR)之间的结合关系,对于肿瘤免疫治疗、疫苗设计以及免疫诊断至关重要。然而,由于TCR与抗原序列具有极高多样性,实验筛选几乎无法穷举所有可能组合,因此研究人员越来越依赖人工智能模型进行高通量预测。
PanPep是一种基于元学习(meta-learning)的TCR结合预测框架,其目标是在仅有极少已知结合体甚至完全未知抗原的情况下,实现对新抗原特异性TCR的泛化预测。
在本研究中,研究人员系统评估了PanPep的可复用性与真实应用价值。研究人员不仅复现了PanPep原始论文中的结果,还构建了一个全新的独立测试集,并采用更加严格的评估方式,包括分类指标与虚拟筛选(virtual screening)评价。
结果显示,在“背景抽样负样本”条件下,PanPep相比其他方法在未知抗原上的泛化能力更强,尤其在few-shot与zero-shot场景中表现突出。然而,在更加困难的“重排负样本”设置下,其优势明显下降。
研究人员进一步将PanPep扩展到TCRα链以及TCRαβ双链预测任务中,证明了其在更真实免疫场景中的可扩展性。不过,研究人员同时发现,该模型在真实早期富集(early enrichment)能力、未知TCR鲁棒性以及负样本策略敏感性方面仍存在明显局限。
总体而言,这项研究建立了一个更加可复现、可扩展的TCR结合预测评估框架,并指出“可泛化TCR识别”仍然是一个尚未解决的重要挑战。

T细胞受体(TCR)通过识别由主要组织相容性复合体(MHC)呈递的抗原肽,从而启动适应性免疫反应。寻找能够识别特定抗原的TCR,对于癌症免疫治疗、个体化疫苗以及新抗原发现具有关键意义。
然而,TCR与抗原之间存在极端组合复杂性。理论上,人体中可能存在数十亿种不同TCR,而抗原肽空间同样巨大。因此,完全依赖实验手段寻找匹配关系几乎不可行。
早期方法通常基于序列相似性聚类,例如GLIPH和GIANA等工具。这些方法在有限场景中有效,但泛化能力较差。随后,深度学习模型开始将TCR识别视为序列建模问题,例如DLpTCR、ERGO、pMTnet以及TEIM等方法。
尽管如此,大多数模型仍存在一个核心问题:它们容易过拟合于“已有大量结合数据”的抗原,而难以泛化到新抗原。
为了解决这一问题,研究人员此前提出PanPep。该框架利用元学习学习“跨抗原共享模式”,从而在少样本甚至零样本条件下预测新的TCR结合关系。
不过,PanPep虽然在原始论文中表现优异,但其真实世界可复用性尚未被严格验证。例如,不同负样本构造策略会显著影响结果,而现有研究普遍缺乏独立测试集评估。
因此,本研究旨在系统回答一个关键问题:PanPep是否真的具备泛化能力。
方法
研究人员设计了五类不同场景,用于系统测试PanPep的可复现性、泛化能力以及可扩展性。
首先,研究人员直接使用PanPep原始模型权重和原始测试集,评估推理层面的复现能力。随后,研究人员构建了一个全新的独立测试集,其中包含PanPep训练集中从未出现的新抗原与新TCR,以测试其真实泛化性能。
在评估指标方面,研究人员不仅采用传统ROC-AUC和PR-AUC分类指标,还引入“虚拟筛选”评价框架。该方法更接近真实免疫筛选场景,即:给定一个抗原,从整个TCR库中寻找真正结合体,并重点关注模型是否能够在排序最前列富集真实binder。
此外,研究人员进一步将PanPep扩展到TCRα以及TCRαβ双链预测任务中,以评估其在更接近真实生理环境中的适用性。
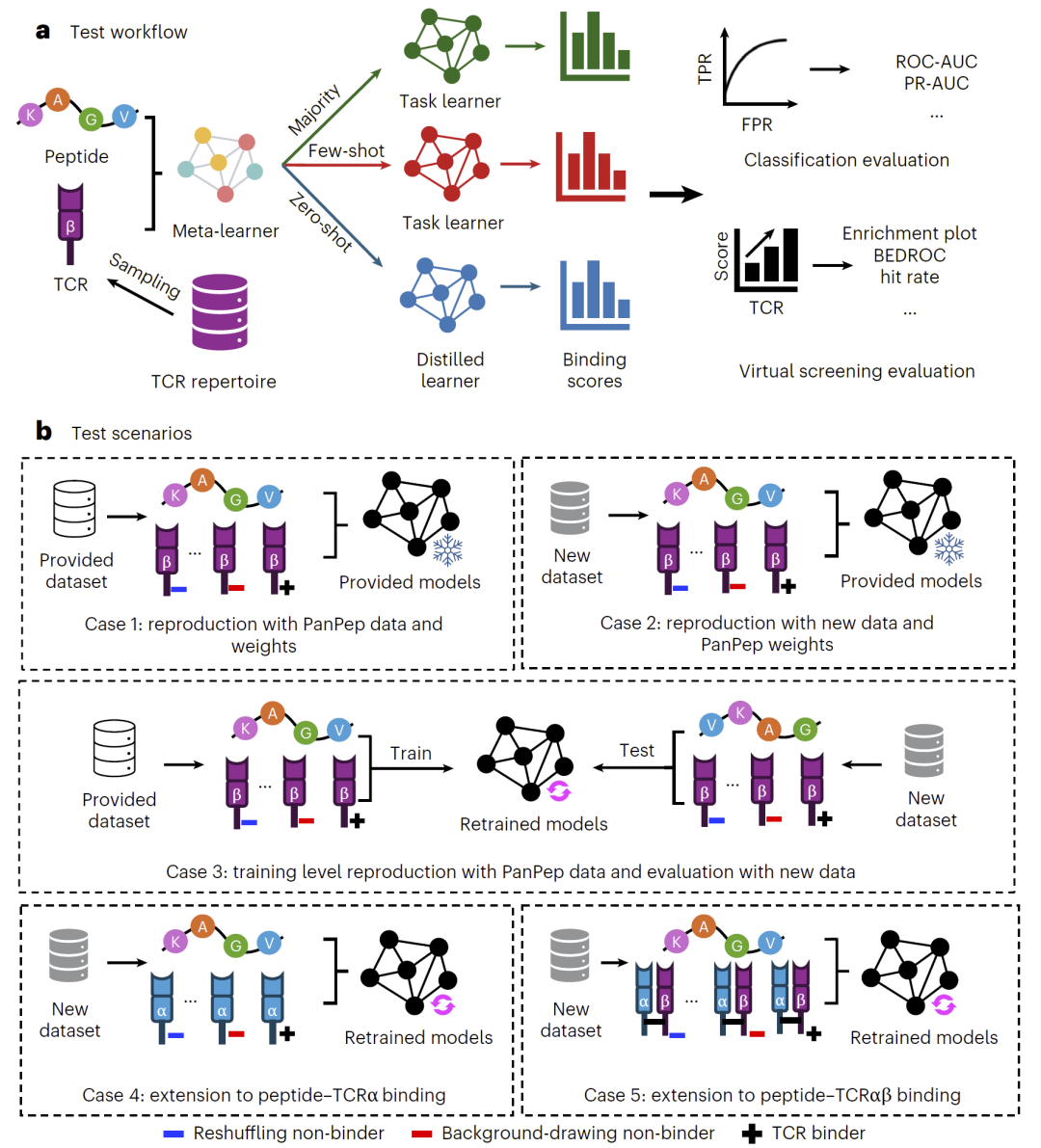
图1:PanPep元学习框架与五类可复用性评估场景。
结果
PanPep原始结果的可复现性
研究人员首先验证了PanPep原始模型是否能够被稳定复现。
结果显示,在使用原始数据集和模型权重时,研究人员基本成功重现了原论文中的ROC-AUC和PR-AUC结果。特别是在few-shot与zero-shot场景中,PanPep明显优于DLpTCR和ERGO-II。
不过,当研究人员采用“重排负样本(reshuffling negatives)”策略时,模型性能显著下降,甚至在某些zero-shot任务中接近随机猜测。
研究人员分析发现,这是因为重排负样本构造了更加困难的“hard negatives”,这些负样本在序列层面与真实binder高度相似,从而暴露出PanPep对于TCR模式的过拟合倾向。
与此同时,在更贴近真实应用的虚拟筛选评估中,PanPep在早期binder富集方面仍明显优于对照模型。
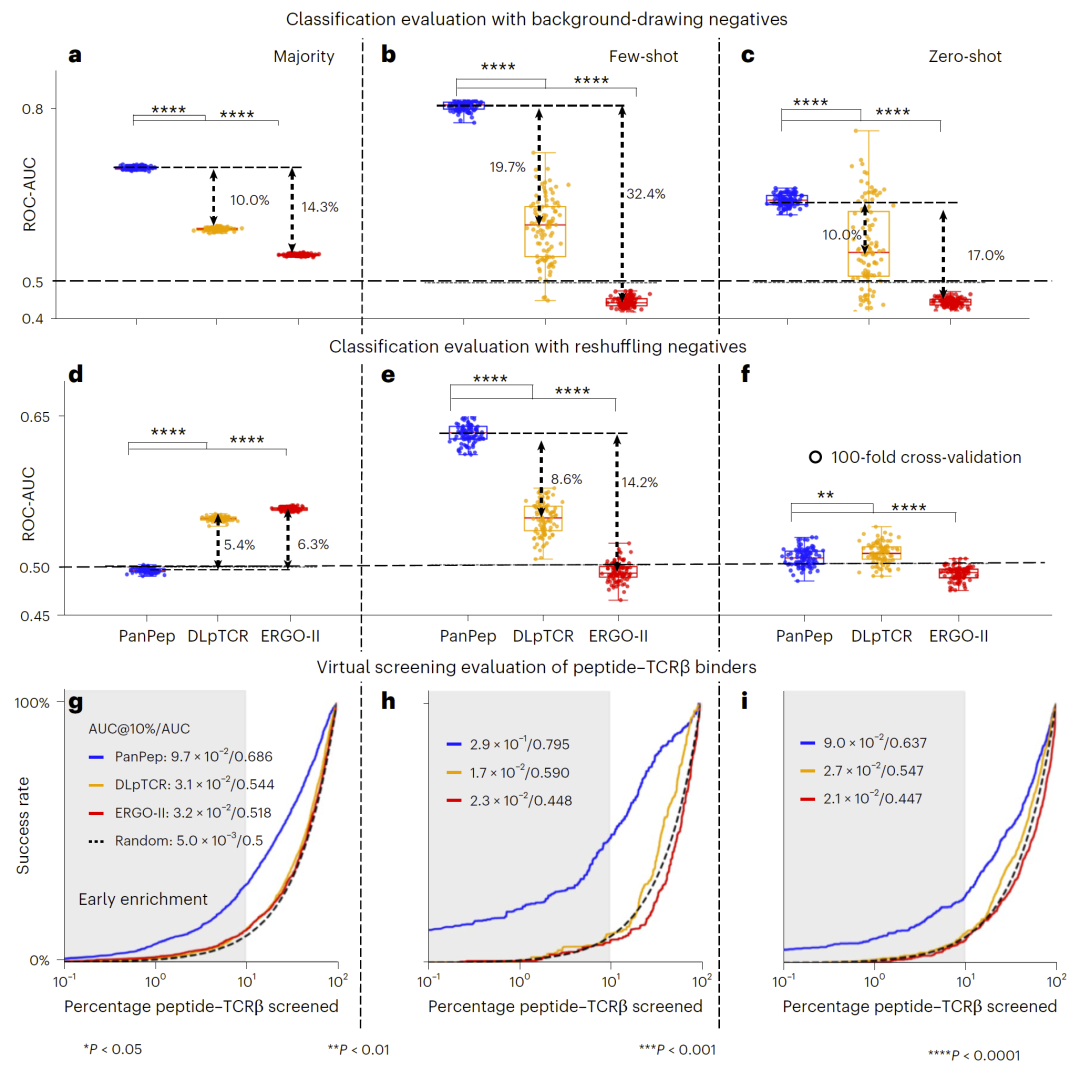
图2:PanPep与DLpTCR、ERGO-II在原始数据集上的性能比较。
独立测试集上的泛化能力
随后,研究人员构建了一个完全独立的新测试集,其中的抗原和TCR均未出现在PanPep训练数据中。
在这一更加严格的测试中,PanPep在majority和few-shot场景中仍保持领先,在ROC-AUC、PR-AUC以及虚拟筛选指标上均优于DLpTCR、ERGO-II和UnifyImmun等模型。
特别是在background-drawing负样本策略下,PanPep在zero-shot场景中依旧表现出较强能力,说明其确实能够对未知抗原进行一定程度的泛化预测。
然而,在“未知抗原–未知TCR”这一最严格场景中,PanPep性能显著下降,几乎接近随机水平。
研究人员认为,这表明PanPep的泛化仍然严重依赖于训练中见过的TCR模式,而真正意义上的“全新组合泛化”仍然是一个开放问题。
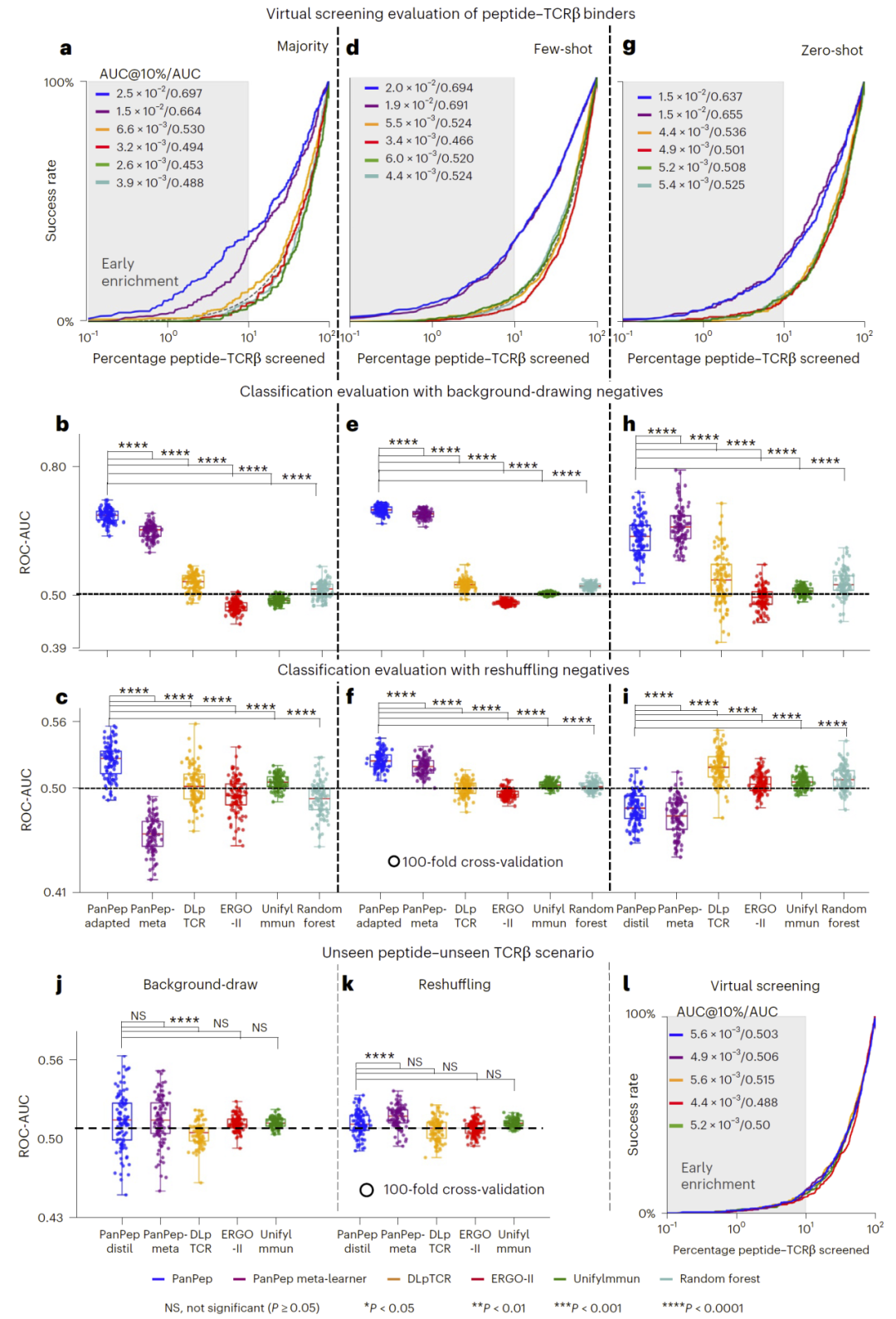
图3:PanPep在独立测试集与未知抗原–未知TCR场景中的泛化表现。
训练层面的可复现性
为了测试PanPep是否稳定可训练,研究人员进一步进行了十次独立重新训练实验。
结果显示,重新训练后的PanPep模型整体趋势与原始模型一致,并持续优于DLpTCR和ERGO-II。尤其在虚拟筛选指标上,PanPep在不同重复实验中均表现稳定。
不过,研究人员同时观察到明显性能波动。这意味着PanPep虽然具有可复现性,但其性能对训练数据划分较为敏感。
此外,研究人员发现,PanPep中的distillation模块反而经常弱于meta-learner本身。这提示当前知识蒸馏过程可能导致部分预训练知识丢失。
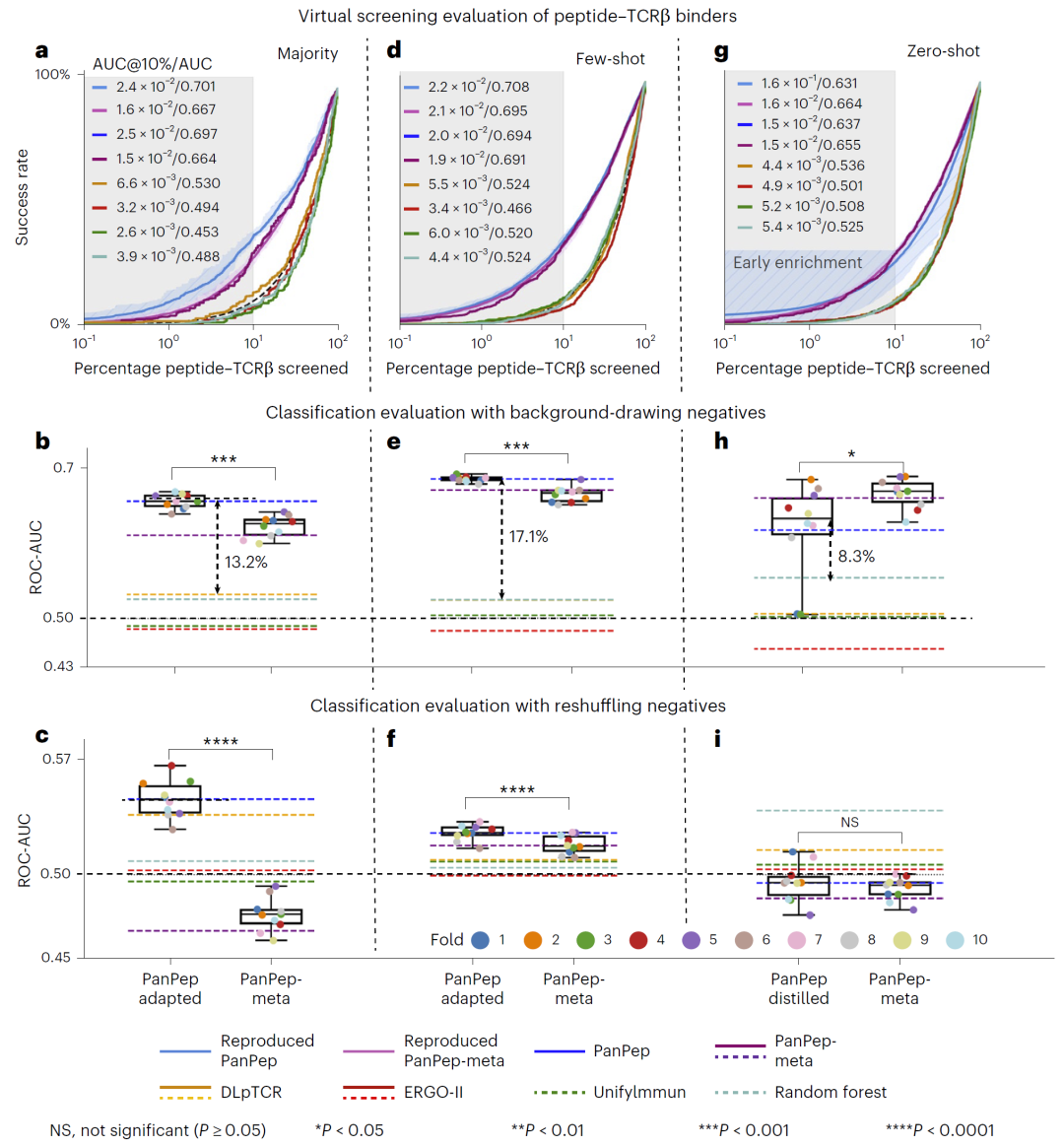
图4:PanPep十次独立训练实验中的性能波动与稳定性分析。
扩展至TCRα链预测
目前多数TCR预测模型只使用TCRβ链,因为公开TCRα数据相对较少。
研究人员因此进一步测试:PanPep是否能够迁移到TCRα预测任务。
结果显示,在majority场景中,PanPep在虚拟筛选和分类指标上与DLpTCR相当,甚至在重排负样本设置下仍保持一定预测能力,而DLpTCR几乎失效。
不过,在few-shot和zero-shot场景中,PanPep优势明显减弱。研究人员认为,这主要是由于TCRα训练数据规模过小,并且序列多样性不足。
同时,不同训练重复之间方差较大,也说明小数据问题严重影响了模型鲁棒性。
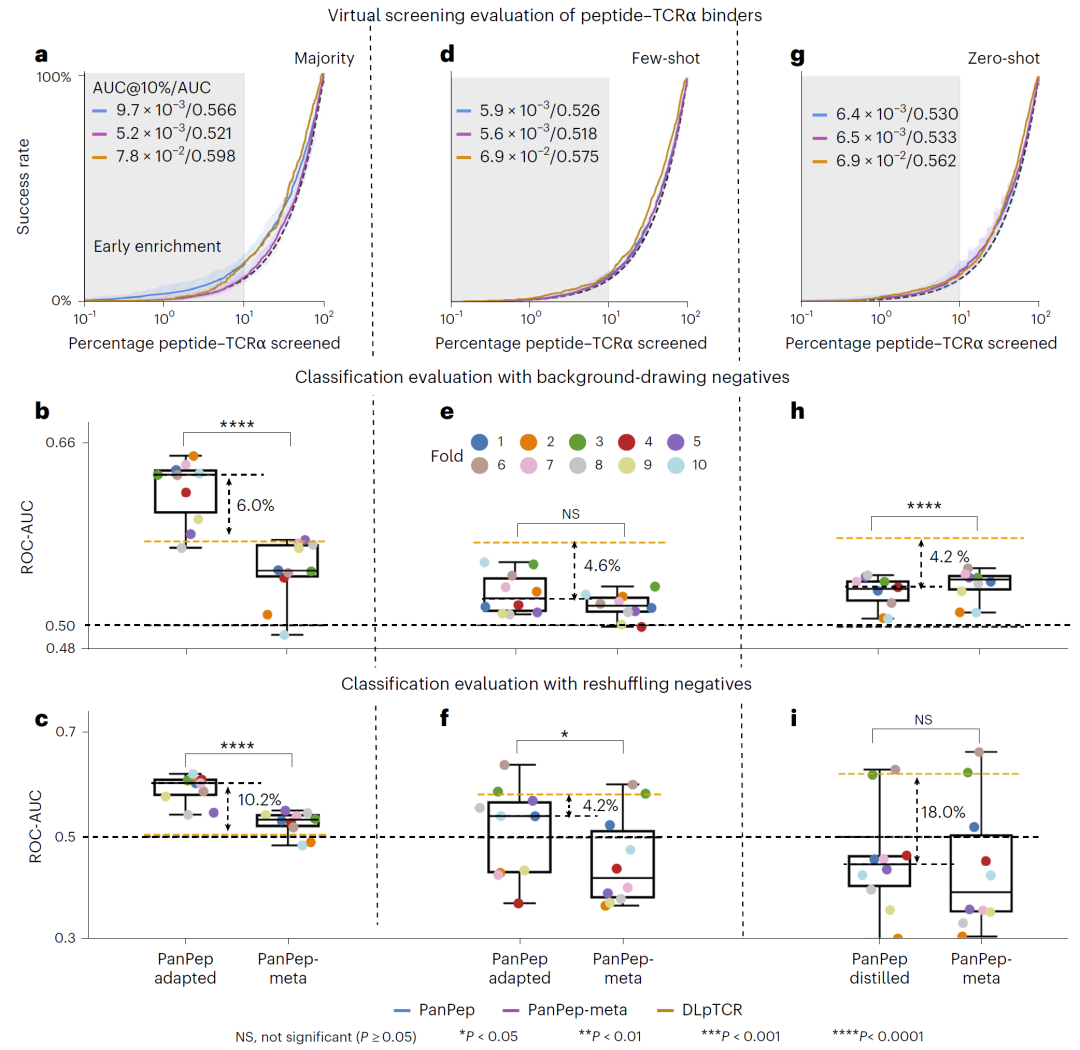
图5:PanPep在TCRα结合预测中的表现。
扩展至TCRαβ双链预测
由于真正决定抗原识别的是TCRα和TCRβ共同形成的识别界面,因此研究人员进一步将PanPep扩展至双链预测任务。
研究人员通过融合分别训练的TCRα与TCRβ模型,构建了新的TCRαβ预测框架。
结果显示,在few-shot与zero-shot场景中,PanPep相比DLpTCR和ERGO-II均表现更优,特别是在早期富集指标上提升明显。
不过,即使在最佳情况下,其ROC-AUC通常也仅在0.65左右,说明真实TCRαβ预测仍然极具挑战。
研究人员指出,原因之一在于:仅凭TCR序列本身可能不足以完全决定结合特异性,还需要考虑HLA类型、抗原呈递环境以及交叉反应性等复杂因素。
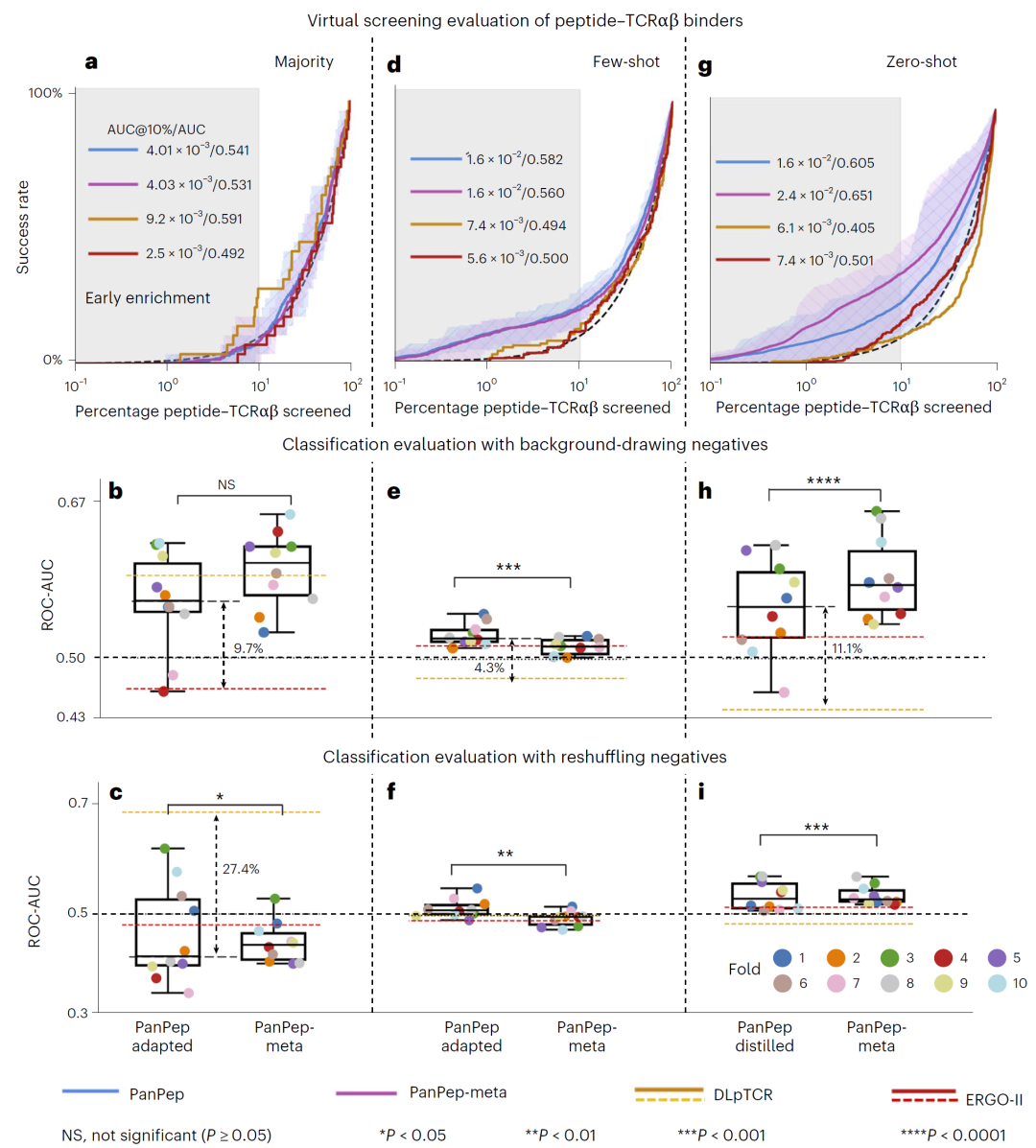
图6:PanPep在TCRαβ双链识别任务中的性能比较。
讨论
研究人员认为,本研究首次系统验证了PanPep在真实场景中的可复用性与局限性。
总体而言,PanPep最大的优势在于:它是目前少数能够处理few-shot与zero-shot TCR识别问题的模型之一。相比传统监督学习方法,元学习框架确实能够提高对未知抗原的泛化能力。
然而,研究人员也发现,目前的TCR预测模型仍然远未达到真实应用要求。
首先,PanPep在“早期富集”能力上仍然有限,这意味着在真实大规模TCR筛选中,模型无法足够高效地把真实binder排到最前列。
其次,模型对负样本构造方式极其敏感。研究人员指出,当前大量工作使用的background-drawing负样本过于容易,从而高估了模型性能。而更加困难的reshuffling负样本则更接近真实场景。
第三,当抗原和TCR同时为未知时,所有模型几乎都接近随机水平。这意味着当前AI实际上尚未真正理解TCR识别机制,而更多是在利用数据分布模式。
研究人员进一步提出,未来方向可能包括:
使用更大规模免疫基础模型(foundation models)、引入自监督学习、采用更深层架构、改善负样本构造策略,以及结合HLA、抗原呈递环境和交叉反应信息。
研究人员最后强调,TCR结合预测不仅是一个机器学习问题,更是一个高度复杂的生物学问题。
真正实现泛化免疫识别,可能需要类似“免疫基础模型(immune foundation model)”的新一代AI系统。
整理 | DrugOne团队
参考资料
He, F., Wang, X. & Xu, D. Reusability report: Meta-learning for antigen-specific T cell receptor binder identification. Nat Mach Intell (2026).
https://doi.org/10.1038/s42256-026-01236-6

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号