Nat. Commun. | 用 AlphaFold-Multimer 发现 GPCR 纳米抗体

Nat. Commun. | 用 AlphaFold-Multimer 发现 GPCR 纳米抗体

DrugIntel
发布于 2026-05-08 19:21:40
发布于 2026-05-08 19:21:40

文献来源:Harvey EP*, Smith JS*, Hurley JD* et al. In silico discovery of nanobody binders to a G-protein coupled receptor using AlphaFold-Multimer.Nature Communications, 2026. DOI: 10.1038/s41467-026-72093-5 通讯作者:Andrew C. Kruse & Katherine J. Susa(哈佛医学院 / UCSF)
目录
- 1. 研究背景与动机
- 2. 核心科学问题
- 3. 研究策略与方法体系
- 4. 关键结果
- 5. 方法学细节与实验验证
- 6. 讨论与局限性
- 7. 与同期相关工作的比较
- 8. 意义与展望
- 9. 值得关注的细节
一、研究背景与动机
1.1 抗体药物的现状与挑战
抗体是最重要的生物药物类别之一。截至2020年,全球已有超过100种单克隆抗体获批上市,超过800种处于临床试验阶段,构成增速最快的药物类群。其核心优势在于对靶蛋白的高度特异性识别、可工程化的慢解离速率(低 ),以及有利的药代动力学特性(长半衰期)。
然而,传统抗体发现流程面临系统性瓶颈:
方法 | 原理 | 主要局限 |
|---|---|---|
免疫动物 | 体内 B 细胞免疫筛选 | 哺乳动物靶点高度保守 → 免疫耐受失败;周期 6–18 个月 |
噬菌体展示 | 体外文库筛选 | 需专业设备;常产生多反应性(polyreactive)抗体 |
酵母展示 | 体外文库筛选 + FACS | 类似噬菌体展示;缺乏体内免疫滤过 |
尤其是 G 蛋白偶联受体(GPCR)这一最重要的药物靶点家族,约占 FDA 批准药物的 35%,但 GPCR 靶向抗体极度匮乏:截至2021年,在所有临床开发中的 GPCR 靶向药物里,抗体类型不足1%,获批 GPCR 单克隆抗体仅3种。根本原因在于 GPCR 构象动态性强、重组蛋白产量低,难以满足传统抗体发现流程所需的高质量样本要求。
1.2 纳米抗体(Nanobody / VHH)的独特价值
纳米抗体是来自骆驼科动物(骆驼、单峰驼、羊驼等)的单域重链抗体可变区片段(VHH),分子量约 12–15 kDa,约为传统抗体(150 kDa)的十分之一。其结构特点赋予其独特优势:
- • 单链结构:无轻链,便于计算建模与虚拟筛选
- • 长突出的 CDR3 环:可深入 GPCR 跨膜束,靶向传统抗体难以触及的正位结合口袋(orthosteric site)
- • 理化稳定性好:热稳定性高,可在多种条件下维持活性
- • PDB 结构丰富:2015年至2023年,PDB 中纳米抗体-GPCR 复合物结构从寥寥数个迅速增长至逾150个,为计算预测提供了丰富训练数据
目前已有1个纳米抗体(caplacizumab,靶向 vWF,用于血栓性血小板减少性紫癜)获 FDA 批准,多个处于临床开发阶段。
1.3 AlphaFold-Multimer 的崛起与局限
自2021年 AlphaFold2 发布以来,蛋白质结构预测发生了根本性变革。AlphaFold-Multimer(AF-M) 是其专门针对蛋白质复合物预测优化的版本,通过以下信息源进行结构推断:
- 1. 多序列比对(MSA):利用同源蛋白序列中的共进化信号推断接触残基
- 2. 蛋白质数据库(PDB)结构模板:利用已知三维结构进行同源建模
- 3. 深度神经网络:端到端学习序列到结构的映射关系
然而,抗体-抗原之间不存在共进化关系(抗体序列由 V(D)J 重组产生,与抗原无共进化历史),这使得 MSA 的共进化信号对抗体预测几乎无贡献。AF-M 对抗体-抗原复合物的预测完全依赖 PDB 结构模板。这一限制长期以来被视为 AF-M 用于抗体发现的根本性障碍。
二、核心科学问题
本研究围绕三个递进的核心科学问题展开:
Q1:AF-M 能否准确预测纳米抗体-GPCR 复合物的结构,包括训练截止后发表的新型构象?
Q2:AF-M 的置信度指标是否能有效区分真实结合与非结合的纳米抗体-GPCR 对?其判别性能是否具有 GPCR 特异性?
Q3:能否基于 AF-M 构建完全计算驱动的前瞻性筛选流程,从随机虚拟文库中发现具有真实结合活性和功能活性的 GPCR 纳米抗体?
三、研究策略与方法体系
3.1 总体技术路线
虚拟纳米抗体文库设计(10,000 条)
│
▼
AF-M 大规模结构预测(无模板模式)
│
▼
多维度置信度指标提取与 LCF 综合评分
│
▼
候选命中分子排名与过滤(LCF > 阈值,去除生化缺陷序列)
│
▼
重组表达纯化(Fc 融合体 / 单体)→ 细胞结合实验 → 功能验证
│
▼
结合位点验证(定点突变 + AF-M 预测位点比对)3.2 基准测试集的构建
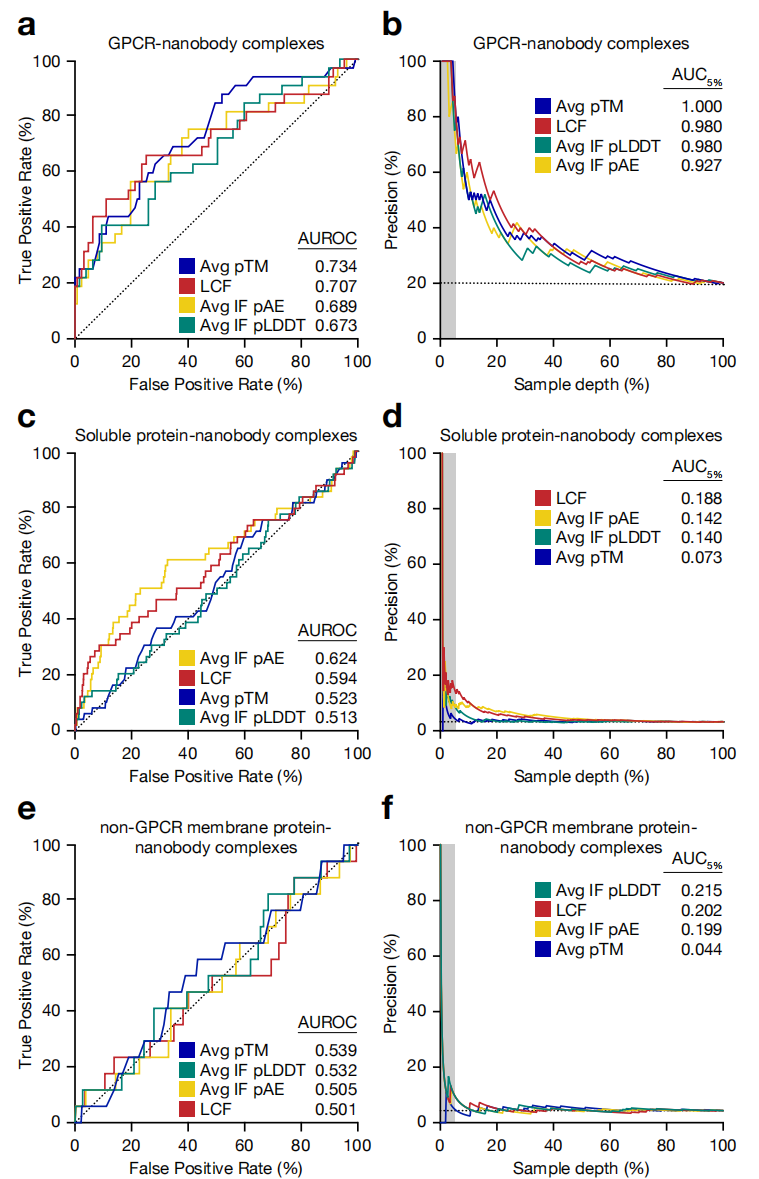
在进行前瞻性筛选之前,研究团队首先系统评估 AF-M 的判别能力,构建了三类基准测试集:
靶点类型 | 真实结合对 | 非结合对照 | AUROC(最优指标) |
|---|---|---|---|
GPCR | 32 对 | 127 对 | 0.73(avg pTM) |
可溶性蛋白 | 49 对 | 1,469 对 | ~0.50(近随机) |
非GPCR膜蛋白 | 17 对 | 376 对 | ~0.50(近随机) |
非结合对照通过置换配对(permutation)生成:将纳米抗体与其非同源抗原随机配对,并通过 BLAST 同源性搜索确认各抗原之间无过近的序列相似性,以避免数据泄露。
关键发现:AF-M 对 GPCR 纳米抗体的判别能力显著优于其他靶点类型,提示 PDB 中大量 GPCR-纳米抗体结构(>150个)在训练中发挥了关键作用,形成了特异性的"GPCR-nanobody识别能力"。
3.3 置信度指标体系与线性组合特征(LCF)
研究团队系统提取并评估了以下 AF-M 输出指标:
全局指标:
- •
avg_pTM:五个模型的平均预测模板建模得分(AUROC = 0.73) - •
best_pTM:最高置信度模型的 pTM(AUROC = 0.71)
界面特异性指标(界面定义:链间 Cα–Cα 距离 ≤ 10 Å 的残基对):
- •
avg_iPAE:平均界面预测对齐误差(AUROC = 0.69;数值越低越好) - •
best_iPAE:最优模型的界面 PAE(AUROC = 0.68) - •
avg_ipLDDT:平均界面预测局部距离差异检验(AUROC = 0.67) - •
best_ipLDDT:最优模型的界面 pLDDT(AUROC = 0.65) - •
avg_model_support:界面接触在五个模型中的平均出现频率(AUROC ≈ 0.65) - •
best_pDockQ:最优模型的预测对接质量评分(AUROC = 0.66;与 pLDDT 高度相关)
线性组合特征(Linear Combination Feature, LCF):
将上述六个独立指标(去除冗余的 best_pDockQ)各自归一化至 [0, 1] 区间后,计算乘积:
LCF 的整体 AUROC 为 0.71,略低于单指标最佳值(0.73),但精准率曲线下面积(AUC5%)表现突出——在排名最高的5%纳米抗体中,LCF 和各组成指标的精准率均达到 0.93–1.0,意味着前5%候选物中几乎全为真阳性结合物。
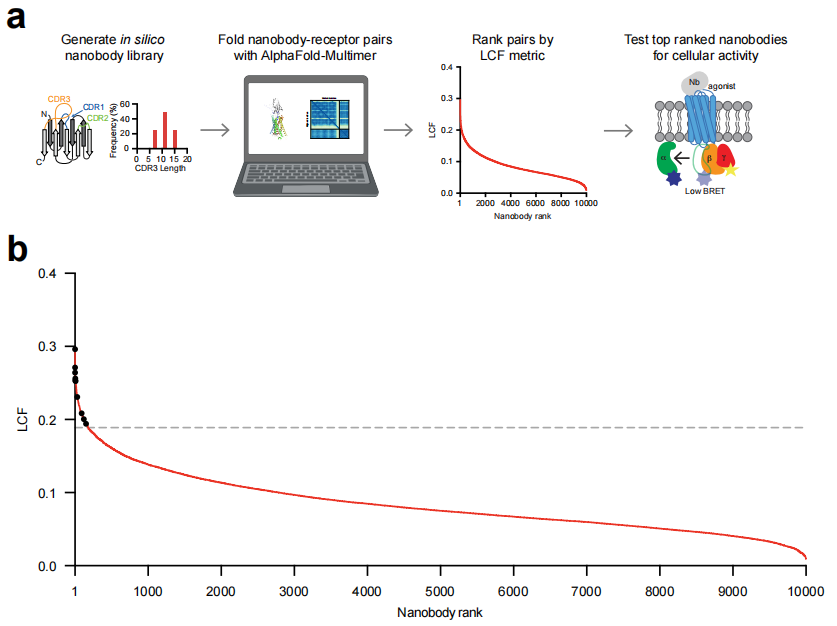
3.4 虚拟纳米抗体文库设计
文库设计遵循 McMahon et al. (2018) 已发表的酵母展示文库规范,关键参数如下:
- • 文库规模:10,000 条序列
- • CDR3 长度分布:7 / 11 / 15 个残基(三类等比例)
- • 氨基酸采样:各 CDR 位置的氨基酸按已发表文库的氨基酸频率分布独立采样;绝大多数位置排除半胱氨酸和甲硫氨酸(避免氧化和二硫键问题);部分位置使用受限氨基酸集合(与原文库设计一致)
- • 框架区(FR):沿用已验证的 VHH 骨架序列,仅 CDR 区随机化
重要说明:此文库为完全随机设计,不含任何已知 GPCR 结合序列,也未针对 MRGPRX2 做特异性富集。这是验证计算方法有效性的关键控制条件。
3.5 AF-M 运行参数
使用修改版本的 ColabFold 本地脚本,运行于配备 NVIDIA A100 GPU 的 Lambda Labs 服务器:
- • 版本:AF-M Multimer v2 / v3
- • 循环次数(recycles):3
- • 模板:关闭(
no_templates,防止特定结构偏倚) - • Amber 后处理:关闭
- • 每对预测:5个模型
四、关键结果
4.1 AF-M 准确预测训练截止后的新型 GPCR-纳米抗体结构
测试案例:GPCR AT1R(血管紧张素II I型受体)与合成纳米抗体 AT118-H 的复合物(PDB: 8TH3,2024年发表,晚于AF-M训练截止日期2021年9月30日)。
AF-M 预测结果与实验冷冻电镜结构高度吻合:
结构层级 | RMSD(Å) |
|---|---|
整体复合物 | 2.9 |
AT1R 受体单独 | 2.9 |
AT118-H 纳米抗体单独 | 1.8 |
CDR1 环 | 1.52 |
CDR2 环 | 2.65 |
CDR3 环 | 1.54 |
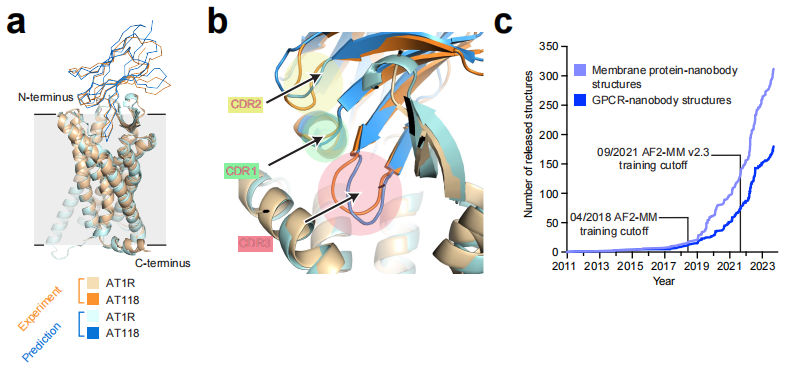


值得注意的是,AT118-H 诱导 AT1R 采取一种前所未见的混合构象——胞外侧呈激活态,胞内侧呈非激活态。AF-M 不仅预测了结合,还正确推断出这一罕见构象,说明其并非简单复现已知模板,而是学会了推断微妙的结构特征。
4.2 对 MRGPRX2 的虚拟筛选及命中率
筛选漏斗统计:
10,000 条虚拟纳米抗体
└─ 去除含潜在生化缺陷序列(糖基化位点、预测多反应性)→ 去除 25%(2,500条)
└─ LCF > 阴性对照最高 LCF 阈值 → 179 条(1.79%)
└─ 预测结合于胞外区 → 177 条(177/179,99%)
└─ 去除额外缺陷 → 选取 Top 6 + 4 条低排名对照 = 10 条
└─ 表达纯化后细胞结合实验 → 4 条阳性
└─ 生化行为良好 → 3 条进入完整验证命中率:10条实验候选物中,3条(30%)获得高亲和力结合并有功能活性,且均排名靠前(rank 1, 5, 7),体现了 LCF 排名的预测价值。



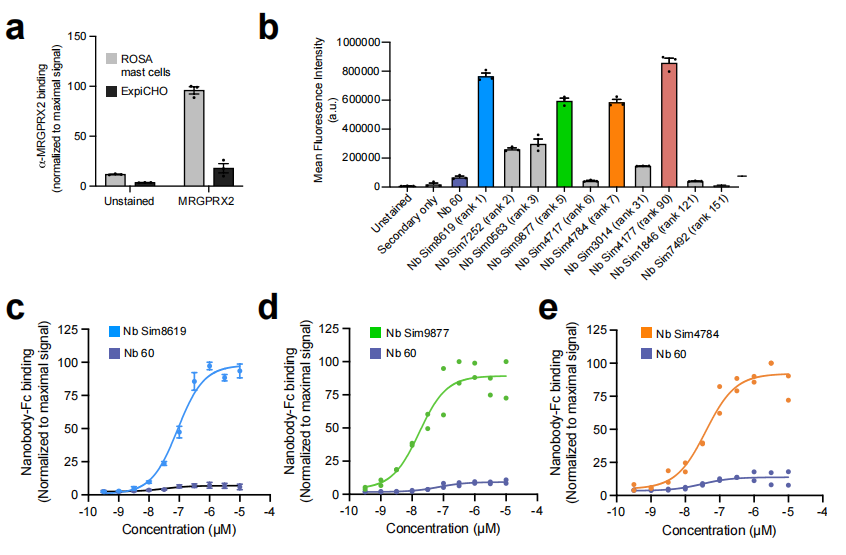
4.3 三条命中纳米抗体的结合特性
纳米抗体 | AF-M 排名 | HEK293T Kd (nM) | HEK293T Bmax | ROSA 细胞 Kd (nM) | MC4R/CXCR3 特异性 |
|---|---|---|---|---|---|
Sim8619 | 1 | 200 ± 20 | 97% ± 3% | 100 ± 10 | 高特异性 |
Sim9877 | 5 | 160 ± 30 | 100% ± 6% | 20 ± 4 | 高特异性 |
Sim4784 | 7 | 80 ± 30 | 43% ± 5% | 50 ± 10 | 部分靶向 MC4R |
三条纳米抗体均在内源性表达 MRGPRX2 的 ROSA 肥大细胞系和异源转染 MRGPRX2 的 HEK293T 细胞上表现出一致的特异性、剂量依赖性结合,而在转染空载体的 HEK293T 细胞上无结合信号。

4.4 功能性拮抗活性验证
β-氨基己糖苷酶释放实验(肥大细胞脱颗粒):
- • MRGPRX2 小分子激动剂 Compound 48/80 诱导约 70% 的脱颗粒释放
- • Sim8619、Sim9877、Sim4784 单独处理均不引发脱颗粒(非激动剂)
- • 三条纳米抗体均能显著抑制 48/80 诱导的脱颗粒(功能性拮抗剂)
Gi TRUPATH BRET 信号转导实验(G蛋白活化):
- • Sim8619 单独处理仅在高浓度(相对于48/80的EC50)时引起微弱 Gi 活化
- • Sim8619 预处理后显著降低 48/80 激活 Gi 的最大效应(Emax 下降)并右移 EC50
- • 类似效果在另一结构不同的 MRGPRX2 肽类激动剂 Substance P 处理中也能观察到
这两项实验共同证明三条纳米抗体为功能性竞争性(或部分竞争性)正位拮抗剂。
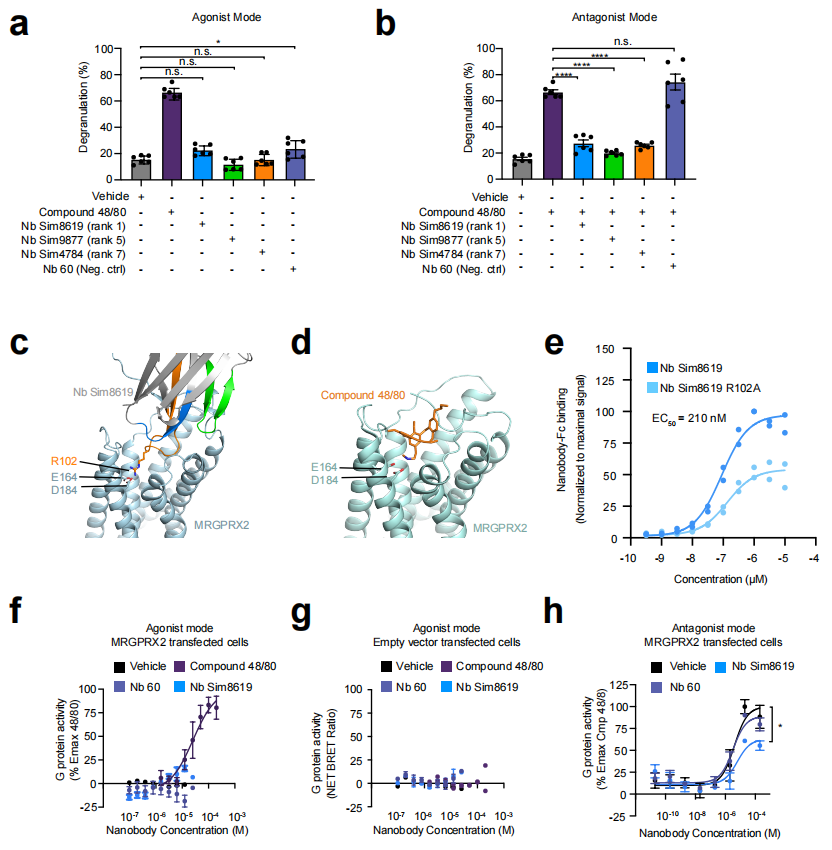



4.5 AF-M 预测结合位点的实验验证
AF-M 预测三条纳米抗体均结合于 MRGPRX2 的正位结合口袋(orthosteric binding pocket),与 48/80 的结合位点重叠,具体接触残基包括受体上的两个酸性残基 E164 和 D184。
验证策略包含多个正交实验:
(1)纳米抗体 CDR 区定点突变
突变 | 纳米抗体 | 预期效果 | 实验结果 |
|---|---|---|---|
R102A | Sim8619(rank 1) | 破坏与 E164/D184 的盐桥 | 亲和力下降约2倍,Bmax 降低 |
其他 CDR 突变 | Sim8619, Sim9877, Sim4784 | 破坏界面接触 | 全部导致亲和力显著降低 |
(2)受体 MRGPRX2 定点突变(E164A/D184A)
效果 | Sim8619 | Sim9877 | Sim4784 |
|---|---|---|---|
AF-M 预测 CDR3 与 E164/D184 直接接触 | ✓ | ✗ | ✓ |
E164A/D184A 突变后结合下降 | ✓ | ✗(一致!) | ✓ |
Sim9877 的 CDR3 在 AF-M 模型中预测不与 E164/D184 直接接触,其结合也确实不受 E164A/D184A 突变影响——这种位点特异性的一致性强有力地支持了 AF-M 预测结合位点的准确性。
五、方法学细节与实验验证
5.1 蛋白表达与纯化
Fc 融合纳米抗体(用于细胞结合和功能实验):
- • 表达系统:Expi293F 细胞瞬时转染(哺乳动物表达)
- • 载体:pFUSE-CHIg-hG1(含 H435A 突变,避免蛋白A亲和柱干扰)
- • 纯化:蛋白A亲和层析,透析后冻存
- • 质控:SDS-PAGE + 分析性尺寸排阻色谱(SEC)
单体纳米抗体(用于结合特异性验证):
- • 表达系统:E. coli BL21(DE3)(pET26B 载体,C端 V5+6×His 标签)
- • 纯化:蛋白A亲和 + Ni-NTA 亲和双步纯化
- • 浓缩至 >100 μM(~1.6 mg/mL)
5.2 细胞结合实验(流式细胞术)
- • ROSA 肥大细胞:内源性高表达 MRGPRX2,经流式细胞术确认
- • HEK293T 细胞:瞬时转染 FLAG-MRGPRX2 或空载体
- • 检测方式:抗人 IgG Fc-AF488(Fc融合)或抗V5-APC(单体)二抗信号
- • Kd 计算:GraphPad Prism 非线性拟合,以负对照条件的 MFI 作为非特异性背景
5.3 β-氨基己糖苷酶脱颗粒实验
- • 激动剂浓度:Compound 48/80 @ 50 μM
- • 纳米抗体预处理:50 μM,15 min,37°C
- • 读出:荧光底物 4-MUG 在 360/460 nm 的荧光信号
- • 脱颗粒率计算:上清荧光 / (上清 + 裂解液荧光) × 100%
5.4 Gi TRUPATH BRET 信号转导实验
- • 系统:HEK293T 细胞瞬时转染 FLAG-MRGPRX2 + Gi TRUPATH 质粒(BRET 传感器)
- • 激动剂模式:纳米抗体 @ 20 μM,检测 ~10 min 后 BRET 变化
- • 拮抗剂模式:纳米抗体 @ 10 μM 预处理 45 min,再加变浓度激动剂
六、讨论与局限性
6.1 为何 AF-M 在 GPCR 上特别有效?
研究者提出了两个互补假说:
- 1. PDB 训练数据质量与数量效应:PDB 中 GPCR-纳米抗体结构从2015年的极少数增至2023年的150余个,且快速增长。丰富的高质量训练样本使 AF-M 能学习到 GPCR 与纳米抗体之间特异性的结构互补模式。
- 2. 结合姿态的刻板性(stereotyped binding poses):相比可溶性蛋白,纳米抗体结合 GPCR 的方式具有相对保守的位置偏好(主要从胞外区进入跨膜束),这种刻板性有助于模型形成规律性认识。
对比实验中,ESMFold(蛋白质语言模型)无法区分 GPCR 纳米抗体真假结合对(AUROC ≈ 0.5),AlphaFold3 对 GPCR 的表现(ipTM AUROC = 0.74)与 AF-M 相当,但在非GPCR膜蛋白上同样失效。
6.2 目标靶点选择的合理性与局限性
选择 MRGPRX2 的依据:
- • 浅表结合口袋(shallow binding pocket)→ 对结合配体的宽容度更高,适合首次验证
- • 灵长类特有受体,序列与 MRGPRX1/3/4 同源性低,减少其他 GPCR 训练数据的混淆
- • 临床价值明确:目前无 FDA 批准药物靶向此受体
局限性:
- • 是否能推广至其他(尤其是结合口袋更深、结构更严苛的)GPCR 靶点,尚待验证
- • MRGPRX2 的"宽容"结合特性可能使其比典型 GPCR 更容易筛选
6.3 技术局限性
- 1. 合成文库纳米抗体的生化行为:免疫后来源的纳米抗体经过体内亲和力成熟,通常生化行为更佳;本研究中所有候选抗体均有部分聚集体(SEC空隙峰),这是合成文库纳米抗体的普遍问题。
- 2. 结构验证缺失:由于 MRGPRX2 重组蛋白纯化量不足,未能获得纳米抗体-MRGPRX2 复合物的实验结构(冷冻电镜或晶体学),精确结合姿态仅由突变实验间接支持。
- 3. LCF 指标的内在局限:AUROC = 0.71–0.73 意味着仍有相当比例的假阳性和假阴性;当筛选更有挑战性的 GPCR 靶点时,可能需要更大的虚拟文库,计算成本显著上升。
- 4. 拮抗机制的不确定性:竞争实验支持正位拮抗,但 Emax 下降而非完全阻断(特别是在浓度依赖性曲线中)提示可能涉及不完全竞争或变构成分,需进一步机制研究。
七、与同期相关工作的比较
方法 | 代表工作 | 策略 | 优势 | 局限 |
|---|---|---|---|---|
本文(AF-M 虚拟筛选) | Harvey et al., 2026 | 随机文库 + AF-M 置信度排名 | 无需指定表位;无需实验先验 | 目前仅在GPCR靶点有效;精度有限 |
RFdiffusion | Watson et al., 2023; Bennett et al., 2024 | 扩散模型从头设计 | 原子级精度;可指定表位 | 需要已知复合物结构或结合位点先验信息 |
Chai-2 | 近期报道 | 多模态生成模型 | 据报道可识别多个GPCR纳米抗体,含功能性激动剂 | 细节有待同行评审 |
JAM | Novo Nordisk, 2025 | 从头设计 VHH | 已应用于多跨膜膜蛋白含GPCR | 公开细节有限 |
BoltzGen / Germinal / mBER | 2025年预印本 | 扩散/语言模型设计 | 多靶点类型 | 多数尚未同行评审 |
de novo 小蛋白设计 | Muratspahic et al., 2025 | 高通量文库 + 细胞筛选 | 已获 MRGPRX1 激动剂/拮抗剂 | 仍需大规模实验筛选(非纯计算) |
本研究的核心区分点在于:无需实验筛选步骤的纯计算前瞻性筛选——从序列设计到结合位点验证,理论上全程可在计算环境中完成,实验仅用于最终验证。这一特点使其在降低初期筛选成本方面具有独特优势。
八、意义与展望
8.1 对药物发现的直接意义
- • MRGPRX2 相关疾病:发现的三条拮抗纳米抗体(Sim8619, Sim9877, Sim4784)具有先导化合物价值,有望用于慢性自发性荨麻疹(chronic spontaneous urticaria)、药物诱导的假过敏反应(如造影剂、肌松药所致的 IgE 非依赖性肥大细胞激活)等适应症。
- • 值得注意的是,Harvey等人及其合作者已就 MRGPRX2 拮抗纳米抗体提交专利申请。
- • GPCR 抗体治疗空白:目前 GPCR 抗体在 FDA 批准药物中严重欠代表(<1%),本方法体系有望系统性加速 GPCR 靶向抗体药物的早期发现阶段。
8.2 方法学发展方向
提升精度的可能路径:
- • 持续增长的 PDB GPCR-纳米抗体结构数据将自动改善 AF-M 表现
- • AlphaFold3 及后续版本有望进一步提升预测精度(当前 AF3 GPCR AUROC = 0.74,与 AF-M 相当)
- • 针对 GPCR 特异性的微调(fine-tuning)模型
扩展至其他靶点类型:
- • 对于当前 AF-M 表现不佳的靶点(可溶性蛋白、非GPCR膜蛋白),可结合 RFdiffusion、Chai-2 等生成模型进行互补
- • 引入贝叶斯优化(Bayesian optimization)/ 主动学习(active learning):以小批量实验反馈指导下一轮虚拟文库设计,更高效探索抗体化学空间
计算成本优化:
- • 更大规模的虚拟文库(>100,000条)对于挑战性靶点可能必要,需发展更高效的计算流程
8.3 更广泛的科学意义
本研究是AI 工具直接产生经实验证实的科学发现的一个完整、严格的范例,具体体现在:
- 1. 严格的训练/测试集分离(使用训练截止后的结构作为测试案例)
- 2. 多正交实验验证(细胞结合、功能实验、定点突变)
- 3. 透明的方法学报告(代码开源于 GitHub)
随着 AI 蛋白质结构预测模型的持续迭代和 PDB 数据的不断积累,类似的"计算驱动 → 少量实验验证"范式有望成为生物药物早期发现的主流路径之一。
值得关注的细节
关于 LCF 设计哲学: 研究者选择将六个指标的归一化值相乘(而非相加或取均值),这意味着任何一个指标极低都会导致 LCF 趋近于零——相当于一个"严格与"(AND gate)逻辑,只有各方面置信度均高的预测才能获得高 LCF。这一设计有效提升了前5%筛选的精准率(AUC5% = 0.93–1.0),代价是整体 AUROC 略低于单个最优指标。
关于 Sim4177(rank 90)的经验教训: Sim4177 在细胞结合实验中显示阳性信号,但生化行为不佳(SEC 分析显示严重聚集),最终被排除。这提示即使是计算预测的"命中",仍需通过生化质控把关,合成文库纳米抗体的生化行为问题不容忽视。
关于 MRGPRX2 与训练数据的关系: MRGPRX2 的结构(PDB)发表于 2021年底,晚于 AF-M 训练截止日期(2021年9月30日),因此 AF-M 在预测时并未包含 MRGPRX2 自身结构的直接信息。这一设计排除了"数据泄露"的可能,使筛选结果更具说服力。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号