从LLM到Agent OS:AI智能体的完整进化线复盘(需求驱动视角)

从LLM到Agent OS:AI智能体的完整进化线复盘(需求驱动视角)

烟雨平生
发布于 2026-04-21 14:17:49
发布于 2026-04-21 14:17:49
为什么AI从"只会聊天"进化到"能自主干活"?
这不是技术的偶然突破,而是真实需求倒逼的必然结果。
本文以"实际需求驱动"为主线,带你走完这3年半的技术进化之路:
- LLM Chat → Reasoning → Function Call → MCP → Skills → Agent → MAS → Agent OS
- 从CoT到ToT,从Prompt Engineering到Harness Engineering
- 从单一模型到多模型协作,从零散工具到完整生态
阅读本文后,你将带走:
- 🧠 一张完整的进化路线图:每个阶段"为什么会出现"、"解决了什么问题"、"留下了什么新问题"
- 💡 深入理解每个技术概念:不只是名词解释,而是明白它在进化链中的位置和价值
- 🔮 对未来的判断:Agent OS之后,下一个战场在哪里?
引言:从聊天到智能体,为什么必须进化?
2022年底,ChatGPT横空出世。那一刻,所有人都以为AI的终极形态就是"超级聊天机器人"——你问什么,它答什么,知识渊博,对话流畅。
但现实很快给了我们一记耳光:
企业场景的第一个问题:信息时效性
用户:今天北京天气怎么样?
LLM(基于2021年数据训练):抱歉,我的训练数据只到2021年,无法回答。
企业场景的第二个问题:私有数据无法访问
用户:我们公司的组织结构是什么样的?
LLM:我无法访问你们公司的私有数据。
企业场景的第三个问题:无法真正"干活"
用户:帮我订一张明天从北京到上海的机票。
LLM:我可以帮你查询航班信息、订票流程...但我无法真正执行订票操作。
上面的问题很痛。
于是,进化开始了。
第一阶段:LLM Chat时代(2022-2023):从GPT-3到ChatGPT
▪ 需求驱动:让AI能聊起来
2022年之前,LLM的应用场景主要是文本补全、翻译、摘要等"单次交互"场景。GPT-3展现了惊人的文本生成能力,但它更像一个"超级文本补全器",而不是"对话伙伴"。
2022年11月,ChatGPT发布,彻底改变了这一局面。它不只是"补全文本",而是能:
- 理解对话上下文(多轮对话)
- 扮演特定角色(角色扮演)
- 遵循指令(Instruction Following)
- 执行推理任务(逻辑推理、数学推理)
▪ 技术突破:RLHF(人类反馈强化学习)
ChatGPT 的核心突破不是模型架构,而是在预训练大模型基础上,采用了 RLHF(Reinforcement Learning from Human Feedback)训练范式。
简单来说,RLHF 整体分为三步:
- 有监督微调(SFT)在人工标注的高质量对话数据上微调,让模型先学会 “按照人类期望的方式回答”。
- 奖励模型训练(Reward Model)用人类对回答的偏好数据训练一个打分模型,让模型学会 “判断回答好坏”。
- 强化学习(PPO)使用 PPO(Proximal Policy Optimization,近端策略优化) 算法,以奖励模型的分数为目标,用近端策略优化算法继续优化,让模型输出更让人类满意的结果。
说明:基座模型的预训练(Pre-training)属于前期基础训练,并不属于 RLHF 流程本身。
▪ 这个阶段的局限
问题一:知识截止
模型的"知识"全来自训练数据,训练数据截止后发生的事情,模型一无所知。
问题二:幻觉(Hallucination)
模型会一本正经地胡说八道。比如问它"某本书的第10章内容",它能编出一整章看起来很有道理,但完全是虚构的内容。
问题三:无法访问外部世界
模型无法联网、无法查数据库、无法执行代码、无法调用API。
问题四:无法真正"干活"
模型只能"说",不能"做"。它能告诉你怎么订票,但无法真正订票。
第二阶段:推理能力突破(2022-2023):从CoT到ToT
▪ 需求驱动:让 AI 能 “想清楚”
人们很快发现,ChatGPT 虽然能流畅对话,但在数学计算、逻辑推理等复杂任务上表现不稳定,经常直接给出错误答案。
数学题:
用户:鸡兔同笼,有35个头,94只脚,鸡兔各几只?
ChatGPT(未优化):它可能直接瞎猜:鸡20只,兔15只(不对)。
逻辑题:
用户:小明比小红高,小红比小刚高,谁最高?
ChatGPT(未优化):可能回答小刚最高(错)。
这些问题的本质是是:模型缺少分步思考的能力,更倾向于直接 “猜” 出结果,而不是严谨推导。
▪ 技术突破 1:Chain of Thought(CoT,思维链)
2022 年,Google 发表论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》,正式提出思维链(CoT)。
核心思想:
在 Prompt 中显式要求模型一步一步思考并展示推导过程,把复杂问题拆解成简单步骤,大幅提升推理准确率。
示例:
用户:鸡兔同笼,有35个头,94只脚,鸡兔各几只?
Prompt:请一步一步思考,最后给出答案。
模型:
1. 假设全是鸡,那么应该有35×2=70只脚
2. 实际有94只脚,比假设多了94-70=24只脚
3. 每只兔比鸡多2只脚,所以兔的数量是24÷2=12只
4. 鸡的数量是35-12=23只5. 验证:23×2 + 12×4 = 46+48 = 94只脚 ✅
6. 答案:鸡23只,兔12只
效果:
CoT 让 GPT-3 等模型在各类数学与逻辑推理任务上的准确率获得显著提升,成为当时提升模型推理能力最有效的方式之一。
▪ 技术突破 2:Tree of Thoughts(ToT,思维树)
CoT 只能沿一条路径线性思考,一旦某一步出错,整体结果就会跑偏。
2023 年,研究人员进一步提出Tree of Thoughts(ToT,思维树)。
核心思想:
模型不再只走一条推理线,而是生成多条可能的推理路径,通过评估、剪枝、投票、反思等机制筛选最优路径,从而更接近人类的多角度思考方式。
示例:
任务:写一个吸引人的文章标题
CoT(思维链):
1. 想一个标题:"AI如何改变世界"(就这样)
2. 完成
ToT(思维树):
路径1:"AI如何改变世界" → 评估:太普通,打分3分
路径2:"AI时代:你的工作会被替代吗?" → 评估:有痛点,打分7分
路径3:"从ChatGPT到Agent OS:AI的3年进化史" → 评估:有技术深度+有时间维度,打分9分
路径4:"别慌,AI不会取代你,但会用AI的人会" → 评估:有情绪价值,打分8分
最终选择:路径3或路径4
▪ Prompt Engineering(提示词工程)的兴起
随着 CoT、ToT 等技术普及,人们意识到 Prompt 质量直接决定模型效果,Prompt Engineering 迅速成为独立技术方向,包括:
- 设计系统提示(System Prompt)
- 少样本学习(Few-shot Learning)
- 思维链模板设计
- 角色扮演与指令增强
经典Prompt模板:
你现在是一个专业的[角色],请[任务描述]。
要求:
1. [要求1]
2. [要求2]
3. [要求3]
示例:
[示例1]
[示例2]
请一步一步思考:
[CoT模板]
后续还出现了 PoT(Program-of-Thought)、GoT(Graph-of-Thought)等进阶推理范式,进一步丰富了模型的思考方式。
▪ 这个阶段的局限
问题一:推理能力依赖模型基座本身
CoT、ToT 只是激发模型潜力,无法创造模型原本不具备的推理能力。
问题二:上下文长度限制
复杂推理步骤容易超出模型上下文窗口,导致思考中断。
问题三:仍然无法访问外部世界
模型可以 “想”,但不能 “查、算、做”,无法借助外部工具纠正错误或获取实时信息。
第三阶段:工具调用(2023):Function Calling
▪ 需求驱动:让AI能"干活"
CoT和ToT解决了"想清楚"的问题,但模型仍然无法真正"干活":
用户:今天北京天气怎么样?
模型:我可以告诉你,北京属于温带季风气候,四季分明...(只能科普气候常识,但它无法告诉你今天的真实天气)
用户:帮我计算一下123456 × 789012
模型:让我一步一步算...(它可能会算错,因为它并非专用计算器。)
用户:帮我查询一下MySQL数据库中有多少用户
模型:抱歉,我无法访问数据库(无法直接访问数据库与外部系统)
核心需求非常明确:模型需要能够安全、规范地使用外部"工具"——天气API、计算器、数据库、搜索引擎、文件系统...
在 Function Calling 正式普及之前,学界已出现Toolformer、APIFormer等先驱工作,探索了模型调用工具的可行性,为后续标准化能力落地奠定了基础。
▪ 技术突破:Function Calling
2023年6月,OpenAI在ChatGPT中正式推出了Function Calling(函数调用)能力。
核心思想:
- 开发者定义一组函数(tools,工具),并清晰描述每个工具的功能与入参格式
- 模型根据用户意图,判断"是否需要调用函数"、"调用哪个函数"、"传什么参数"
- 应用程序执行函数,返回结果给模型
- 模型将工具返回结果整合,形成最终回答
完整流程:
1. 定义工具 tools = [ { "type": "function", "function": { "name": "get_weather", "description": "获取指定城市的实时天气", "parameters": { "type": "object", "properties": { "city": { "type": "string", "description": "城市名称,例如:北京、上海" } }, "required": ["city"] } } } ] 2. 用户提问 用户:今天北京天气怎么样? 3. 模型判断需要调用工具 模型分析用户意图: - 问题涉及"天气" - 提到"北京" - 需要获取实时数据 → 调用 get_weather 工具 4. 模型返回工具调用请求 { "tool_calls": [ { "id": "call_123", "type": "function", "function": { "name": "get_weather", "arguments": "{\"city\": \"北京\"}" } } ] } 5. 应用程序执行工具 result = call_weather_api(city="北京") # result: {"temperature": 25, "weather": "晴", "humidity": 40} 6. 将工具结果返回给模型 messages = [ {"role": "user", "content": "今天北京天气怎么样?"}, {"role": "assistant", "tool_calls": [...]}, {"role": "tool", "content": json.dumps(result)} ] 7. 模型整合信息生成最终回答 模型:今天北京天气晴朗,气温25℃,湿度40%,适合外出活动。
▪ Function Calling的本质
Function Calling 并不是模型直接远程调用函数,而是模型以结构化格式告诉应用程序:需要调用哪个工具、参数是什么,再由应用程序完成实际调用。
这听起来像是"多此一举",但它的价值在于:
- 模型的决策能力: 模型判断"是否需要调用工具"、"调用哪个工具"、"用什么参数"
- 模型的推理能力: 模型根据工具的"描述",理解工具的功能
- 模型的整合能力: 模型将多个工具的结果整合成连贯的回答
这样一来,模型具备了工具决策能力、参数理解能力与多结果整合能力,第一次真正具备了 “落地做事” 的可能。
▪ 这个阶段的突破
突破一:模型能真正"干活"
模型可以查天气、查数据库、调用API、执行代码,完成真实业务动作。
突破二:模型的"知识边界"被打破
模型不再依赖训练数据,而是可以通过工具获取实时数据、私有数据。
突破三:Agent的雏形出现
虽然还很简单,但模型已经具备了"自主决策+调用工具+整合结果"的能力,这正是智能体(Agent)的基础。
▪ 这个阶段的局限
问题一:工具爆炸
随着Agent应用的增加,需要的工具越来越多:
- 天气工具
- 数据库工具
- 搜索引擎工具
- 邮件工具
- 日历工具
- 文件系统工具
- ...
同时,每个 Agent 单独适配成本极高。如果每个Agent都为每个工具编写专用适配代码,维护成本会爆炸。
问题二:模型选择错误
模型可能会"选错工具"或"传错参数",导致任务失败。
问题三:跨模型兼容性
不同模型的Function Calling接口不同: ...
- OpenAI: tools参数
- Anthropic Claude: tools参数
- Google Gemini: tools参数
- DeepSeek: tools参数
虽然格式类似,但细节差异导致迁移成本高。
问题四:工具描述依赖描述
模型选择工具的准确性,严重依赖工具的"描述"(description)。描述写得好,模型就能选对;描述写得差,模型就会选错。
第四阶段:连接器标准化(2024-2025):MCP
▪ 需求驱动:解决工具爆炸
随着Agent应用的普及,"工具爆炸"的问题变得日益严重:
场景:一个企业有10个Agent,需要接入20个数据源/工具
- Agent 1: 销售助手(需要CRM、订单系统、客户数据库)
- Agent 2: 客服助手(需要知识库、工单系统、CRM)
- Agent 3: 技术助手(需要Git仓库、Jira、Wiki、Slack)
- Agent 4: 财务助手(需要ERP、财务系统、报表系统)
- ...
- Agent 10: 管理助手(需要以上所有系统)
问题: 如果每个Agent都为每个工具编写专用适配代码,需要10×20=200个集成点。
更严重的问题:
- 工具API变更 → 需要更新所有集成点
- 新增一个工具 → 需要为所有Agent编写适配代码
- 更换模型 → 需要重写所有工具调用代码
▪ 技术突破:MCP(Model Context Protocol)
2024 年,以 Anthropic 为代表的机构开始推动 MCP(Model Context Protocol,模型上下文协议) 标准化,试图解决 “工具爆炸” 的问题。
核心思想:
- 工具提供者实现"MCP服务器"(标准接口)
- Agent应用实现"MCP客户端"(标准接口)
- 一次对接,到处使用
架构对比:
【传统方式】 Agent 1 ──┐ ├── Tool A API 1 Agent 2 ──┤ ├── Tool A API 2 Agent 3 ──┘ └── ...(每个Agent都有自己的Tool A适配代码) 【MCP方式】 Agent 1 ──┐ ├── MCP Client ── MCP Server A ── Tool A Agent 2 ──┤ ├── MCP Client ── MCP Server B ── Tool B Agent 3 ──┘ └── ...(工具只需要实现一次MCP Server)
MCP的价值:
- 集成点从 N×M 降到 N+M
- N个Agent + M个工具
- 传统方式:N×M个集成点
- MCP方式:N个MCP Client + M个MCP Server
- 工具可复用
- 一个MCP Server可以被所有Agent使用
- 社区可以共享MCP Server
- 跨模型兼容
- MCP协议独立于具体模型
- 换模型不需要重写工具代码
- 标准化接口
- 工具提供者只需要实现一次MCP Server
- Agent应用只需要实现一次MCP Client
▪ MCP的本质:USB-C接口
如果用一句话形容MCP:
MCP = USB-C接口(标准化连接器)
- 以前:每个设备都有自己的接口(iPhone的Lightning、Android的Micro-USB、各种专用接口)
- 现在:统一用USB-C,一次适配,到处使用
同理:
- 以前:每个工具都有自己的API格式
- 现在:统一用MCP协议,一次对接,到处使用
▪ MCP与Function Calling的关系
不是替代关系,而是互补关系:
- Function Calling:解决"单个模型如何按定义的JSON协议调用自己的API"
- MCP:解决"如何标准化工具的接口,让多个Agent共享多个工具"
完整流程:
1. MCP Client注册工具(从MCP Server获取工具定义) 2. MCP Client将工具定义转换为模型的tools参数 3. 模型通过Function Calling选择工具 4. MCP Client执行工具(通过MCP Server) 5. MCP Client将工具结果返回给模型
▪ 这个阶段的突破
突破一:工具可复用
社区开始涌现大量MCP Server:
- MCP Server for GitHub
- MCP Server for Google Drive
- MCP Server for PostgreSQL
- MCP Server for Slack
- ...
突破二:开发成本降低
开发者不再需要为每个Agent编写工具适配代码,直接使用社区的MCP Server即可。
突破三:生态开始形成
工具提供者有动力实现MCP Server,因为可以被所有Agent使用。
▪ 这个阶段的局限
问题一:模型仍然会"选错工具"
MCP解决了"工具的接口标准化"问题,但没有解决"模型如何正确选择工具"的问题。
问题二:工具描述仍然是手工编写
MCP Server需要提供工具的"description",这个描述仍然是手工编写的,质量参差不齐。
问题三:工具组合逻辑仍然需要显式编码
模型可以调用单个工具,但如何组合多个工具完成复杂任务?这仍然需要开发者显式编写逻辑。
第五阶段:能力封装(2025-2026):Skills
▪ 需求驱动:让模型会用对工具
MCP解决了"工具的接口标准化"问题,但新问题出现了:
问题一:模型不知道"什么时候该用什么工具"
用户:帮我写一篇关于AI的文章
模型:我需要调用哪个工具?
- 搜索引擎工具?查资料
- 文件系统工具?保存文章
- 邮件工具?发送给谁?
- 还是...都不用?直接用模型的知识写?
问题二:模型不知道"怎么用工具"
用户:帮我查询一下MySQL数据库中有多少用户
模型:我需要调用数据库工具,但是:
- 用什么SQL语句?
- 查询哪个表?
- 用什么条件过滤?
- 结果怎么处理?
问题三:工具组合逻辑复杂
很多任务需要组合多个工具:
用户:帮我策划一次北京旅行
模型需要:
1. 搜索景点(搜索引擎工具)
2. 查询天气(天气工具)
3. 筛选酒店(酒店工具)
4. 规划路线(地图工具)
5. 生成行程(用模型的知识)
6. 保存行程(文件系统工具)
7. 发送给用户(邮件工具)
模型需要知道:
- 调用哪些工具?
- 按什么顺序调用?
- 每个工具的参数是什么?
- 如何组合工具的结果?
▪ 技术突破:Skills
MCP也有工具爆炸、决策混乱、上下文过载。Skills 正是为了解决这些问题而出现。2024-2025年,随着Agent应用的深化,行业内逐步形成了“能力封装”的技术方向,行业常用叫法包括Tool Skill、Capability、Agent Skill、Task Pack等,本文统一称为Skills(技能包)。
核心思想:
Skills = 封装好的Prompt + 工具调用序列 + 任务流程(Workflow) + 质量与容错规则,核心是告诉模型"什么时候用工具"、"怎么用工具"、"如何组合工具",同时实现工具懒加载、缓解工具爆炸、降低决策干扰,可复用迭代并自动进化,相当于给模型提供可直接复用的“操作手册”和“经验包”。
Skills与MCP的区别:
MCP = USB-C接口(标准化连接器) - 解决"能不能连"的问题 - 给模型"工具" Skills = 专业手册(经验包) - 解决"会不会用"的问题 - 给模型"经验"
Skills的本质:
如果用一句话形容Skills:
Skills = Prompt + Tool Definition + Task Logic
示例:小红书发布Skill
name: xiaohongshu_publisher description: 自动发布内容到小红书 steps: 1. 登录小红书 - 调用:mcp://xiaohongshu/login - 参数:username, password 2. 查找发布入口 - 调用:mcp://xiaohongshu/find_publish_page - 参数:无 3. 生成内容 - 调用:llm.generate - Prompt: "根据以下主题生成小红书内容:{topic}" - 参数:topic 4. 发布内容 - 调用:mcp://xiaohongshu/publish - 参数:title, content, tags 5. 查看发布结果 - 调用:mcp://xiaohongshu/check_publish_status - 参数:post_id quality_rules: - 标题要有吸引力(包含数字、问题、利益点) - 内容要有情绪价值或知识价值 - 标签要符合平台调性 - 发布时间选择流量高峰期 fallback_rules: - 登录失败 → 重试3次,仍失败则通知用户 - 发布失败 → 检查内容是否违规,修改后重试 - 账号被封 → 通知用户,停止发布
Skills的价值:
- 告诉模型"什么时候用什么工具"
- 不是所有工具都是"可选的"
- 有些工具是"必须的"
- 有些工具是"条件触发的"
- 告诉模型"怎么用工具"
- 工具的参数应该怎么填?
- 工具的返回值应该怎么处理?
- 工具失败后应该怎么处理?
- 告诉模型"如何组合工具"
- 工具的调用顺序是什么?
- 如何组合工具的结果?
- 什么时候需要循环调用?
- 经验传承
- 知识领域的最佳实践
- 常见问题的解决方案
- 避坑指南
▪ Skills的层次
Level 1:单个工具的Skill
name: weather_skill description: 查询天气的工具使用指南 rules: - 用户问"天气"时,调用get_weather工具 - 如果用户没有指定城市,询问用户 - 如果天气工具失败,告知用户无法获取天气信息
Level 2:工具组合的Skill
name: travel_planner_skill description: 策划旅行的完整流程 steps: 1. 搜索景点 2. 查询天气 3. 筛选酒店 4. 规划路线 5. 生成行程 tools: - search_attractions - get_weather - search_hotels - plan_route quality_rules: - 行程要合理(每天不超过3个景点) - 酒店要靠近景点 - 考虑天气因素
Level 3:领域专家的Skill
name: sales_agent_skill description: 销售助手的完整能力 knowledge: - 销售话术库 - 客户痛点库 - 成功案例库 tools: - search_crm - create_order - send_email - generate_contract skills: - 开场话术 - 需求挖掘 - 方案呈现 - 异议处理 - 成交技巧 - 售后跟进 quality_rules: - 先了解客户需求,再推荐产品 - 用数据说话,用案例证明 - 保持专业和亲和力
▪ Context Engineering(上下文工程)的兴起
随着Skills的普及,Context Engineering(上下文工程) 成为一个新领域:
- 如何设计Skill的描述?
- 如何组织Skill的步骤?
- 如何设计Skill的质量规则?
- 如何设计Skill的降级规则?
Context Engineering vs Prompt Engineering:
Prompt Engineering: - 如何设计System Prompt? - 如何设计Few-shot Learning? - 如何设计CoT Prompt? Context Engineering: - 如何设计Skill的描述? - 如何设计Skill的步骤? - 如何设计Skill的质量规则? - 如何设计Skill的降级规则?
▪ 这个阶段的突破
突破一:模型会用对工具了
Skills告诉模型"什么时候用什么工具"、"怎么用工具"、"如何组合工具",模型的工具调用准确率大幅提升。
突破二:经验可以传承
领域的最佳实践、常见问题、避坑指南,都可以封装成Skills,让新模型"继承"这些经验。
突破三:知识领域的门槛降低
以前,做一个"销售助手"需要:
- 懂销售领域知识
- 懂技术实现
- 懂Prompt Engineering
现在,只需要:
- 使用"销售领域专家Skill"
- 配置好工具
- 就能快速上线
▪ 这个阶段的局限
问题一:Skills仍然需要人工编写
Skills的设计、编写、调优,仍然需要人工参与,成本较高。
问题二:Skills的质量参差不齐
不同开发者编写的Skills,质量差异巨大。
问题三:Skills的兼容性问题
不同平台的Skill格式不统一,导致Skills无法跨平台复用,迁移成本高。
问题四:仍然没有解决"自主规划"问题
Skills告诉模型"如何完成任务",但模型仍然无法自主拆解复杂任务、自主规划执行路径,需要依赖预设的流程。
第六阶段:智能体(2023-2025):ReAct, Workflow, AutoAgent
▪ 需求驱动:让AI能"自主规划"
Function Calling + MCP + Skills 让模型能"用对工具",但模型仍然无法"自主规划任务":
用户:帮我策划一次北京旅行
模型:我有Skills可以告诉你"如何策划旅行",但我仍然需要你告诉我:
- 你的预算是多少?
- 你想去哪些景点?
- 你喜欢什么类型的酒店?
- 你打算住几天?
- ...
模型无法"自主规划":它不知道"先做什么、后做什么"、"什么时候需要问用户"、"什么时候可以自主决策"。
▪ 技术突破1:ReAct(Reasoning + Acting)
2022年,Google发表论文《ReAct: Synergizing Reasoning and Acting in Language Models》,由姚顺雨(Shunyu Yao)担任第一作者,2022 年 10 月在 arXiv 发布预印本,由普林斯顿大学与 Google Research 合作完成,后发表于 ICLR 2023,提出了ReAct(推理+行动)框架,这是早期自主Agent的核心技术之一,为后续Agent的自主规划能力奠定了基础。
核心思想:
- 模型不只是"回答问题"
- 而是"思考(Reasoning)→ 行动(Acting)→ 观察(Observation)→ 再思考"的循环
- 模型可以"自主决定"下一步做什么
ReAct的完整流程:
用户:帮我策划一次北京旅行 Thought 1(思考1): 用户想要策划一次北京旅行,我需要: 1. 了解用户的需求(预算、天数、偏好) 2. 搜索北京的热门景点 3. 查询北京的天气 4. 根据需求和天气推荐景点和酒店 Action 1(行动1): 询问用户的需求 用户:预算5000元,3天,喜欢历史文化 Thought 2(思考2): 用户的需求明确了: - 预算:5000元 - 天数:3天 - 偏好:历史文化 现在我需要: 1. 搜索北京的历史文化景点 2. 查询北京未来3天的天气 3. 根据预算筛选酒店 4. 生成行程 Action 2(行动2): 搜索北京的历史文化景点(调用搜索引擎工具) Observation 2(观察2): 故宫、天坛、颐和园、长城、明十三陵、雍和宫、孔庙、国子监... Thought 3(思考3): 搜索到了很多景点,我需要: 1. 筛选出最适合3天旅行的景点 2. 查询天气 3. 生成初步行程 Action 3(行动3): 查询北京未来3天的天气(调用天气工具) Observation 3(观察3): 第1天:晴天,25℃ 第2天:多云,22℃ 第3天:小雨,18℃ Thought 4(思考4): 第3天有雨,不适合户外活动,我应该: - 第1天、第2天:安排户外景点(故宫、天坛、长城) - 第3天:安排室内景点(博物馆、购物中心) Action 4(行动4): 筛选酒店(调用酒店工具) Observation 4(观察4): 筛选出3家酒店: 1. 王府井酒店:500元/晚,市中心 2. 前门酒店:400元/晚,靠近天安门 3. 什刹海酒店:450元/晚,风景好 Thought 5(思考5): 用户喜欢历史文化,前门酒店靠近天安门,最合适。 Action 5(行动5): 生成行程(调用模型的知识) 最终结果: 第1天:故宫 → 天坛 → 什刹海(住宿:前门酒店) 第2天:长城 → 颐和园(住宿:前门酒店) 第3天:国家博物馆 → 购物中心(住宿:前门酒店)
▪ 技术突破2:Workflow(工作流)
ReAct的问题是:模型在"自主规划"时,可能会"想错",导致整个任务失败。Workflow(工作流)是另一种更可控的方案,与ReAct形成互补。
核心思想:
- 不是让模型"自主规划"
- 而是让开发者"显式定义工作流"
- 模型只需要"执行工作流中的每个步骤"
Workflow示例:
workflow: travel_planner description: 旅行策划工作流 steps: - name: collect_requirements type: llm prompt: "询问用户的旅行需求(预算、天数、偏好)" - name: search_attractions type: tool tool: search_attractions input: "{requirements.city}" - name: check_weather type: tool tool: get_weather input: "{requirements.city}" - name: filter_hotels type: tool tool: search_hotels input: "{requirements.city}, {requirements.budget}" - name: generate_itinerary type: llm prompt: "根据景点、天气、酒店,生成旅行行程" - name: save_itinerary type: tool tool: save_file input: "{itinerary}" retry_policy: max_retries: 3 on_failure: fallback_to_manual fallback_strategy: - 如果搜索景点失败 → 手动推荐热门景点 - 如果查询天气失败 → 假设天气良好 - 如果筛选酒店失败 → 推荐用户自行搜索
ReAct vs Workflow:
ReAct: - 优点:灵活,可以适应复杂场景 - 缺点:不可控,模型可能会"想错" Workflow: - 优点:可控,开发者显式定义流程 - 缺点:不灵活,场景变化需要重新定义流程
▪ 技术突破3:AutoAgent(自动智能体)
AutoAgent(自动智能体)是ReAct和Workflow的结合体,兼顾灵活性与可控性,2023年初,AutoGPT等早期AutoAgent产品出现,推动了自主Agent的落地应用。
核心思想:
- 用Workflow定义"框架"
- 用ReAct填充"细节"
- 模型可以"自主规划"任务,但有"框架约束"
AutoAgent示例:
workflow: auto_travel_planner description: 自动旅行策划智能体 framework: - name: planning_phase type: react description: 规划阶段:收集需求、搜索信息、生成方案 skills: - collect_requirements - search_attractions - check_weather - filter_hotels - generate_itinerary - name: execution_phase type: workflow description: 执行阶段:按步骤执行 steps: - book_hotels - book_tickets - create_itinerary_document - send_confirmation_email - name: monitoring_phase type: react description: 监控阶段:跟踪行程、处理异常 skills: - check_travel_status - handle_cancellations - send_notifications
▪ 相关增强推理技术
除了ReAct、Workflow、AutoAgent,行业内还出现了Plan-and-Solve(规划与求解)、Reflexion(反思)、Self-Consistency(自一致性)等增强推理技术,进一步提升模型的自主规划与纠错能力。
▪ Harness Engineering(组件工程)的兴起
随着Agent的普及,Harness Engineering(组件工程)成为一个新领域,核心是Agent的全链路工程化设计,包括::
- 如何设计Agent的框架(Framework)?
- 如何设计Agent的技能(Skills)?
- 如何设计Agent的工具(Tools)?
- 如何设计Agent的记忆(Memory)?
- 如何设计Agent的监控(Monitoring)?
Harness Engineering vs Context Engineering vs Prompt Engineering:
Prompt Engineering: - 如何设计System Prompt? - 如何设计Few-shot Learning? - 如何设计CoT Prompt? Context Engineering: - 如何设计Skill的描述? - 如何设计Skill的步骤? - 如何设计Skill的质量规则? Harness Engineering: - 如何设计Agent的框架(Framework)? - 如何设计Agent的技能(Skills)? - 如何设计Agent的工具(Tools)? - 如何设计Agent的记忆(Memory)? - 如何设计Agent的监控(Monitoring)?
▪ Agent的层次
Level 1:单工具Agent
功能:调用一个工具完成任务 例子:天气查询Agent、数据库查询Agent
Level 2:多工具Agent
功能:组合多个工具完成任务 例子:旅行策划Agent、销售助手Agent
Level 3:自主规划Agent
功能:自主规划任务,动态选择工具 例子:AutoGPT、Manus
Level 4:多Agent协作Agent
功能:多个Agent协作完成任务 例子:研发团队Agent(产品经理Agent + 开发Agent + 测试Agent + 运维Agent)
▪ 这个阶段的突破
突破一:模型可以"自主规划"了
ReAct让模型可以"思考→行动→观察→再思考"的循环,自主决定下一步做什么。
突破二:模型可以"组合工具"了
模型可以自主决定"调用哪些工具"、"按什么顺序调用"、"如何组合结果"。
突破三:Agent的雏形成熟了
模型具备了"自主规划 + 工具调用 + 结果整合 + 异常处理"的能力,这已经是一个完整的Agent了。
▪ 这个阶段的局限
问题一:ReAct不稳定
模模型在"自主规划"时,可能会出现推理偏差、步骤错乱,导致整个任务失败。
问题二:Workflow不灵活
Workflow虽然可控,但场景变化需要重新定义流程,维护成本高,无法适应复杂多变的需求。
问题三:Agent的记忆问题
Agent没有"长期记忆",每次对话都是"从零开始",无法积累经验、记住用户偏好。
问题四:Agent的协作问题
多个Agent之间如何协作?如何分配任务?如何共享信息?如何协调冲突?这些问题尚未形成成熟的解决方案。
第七阶段:多智能体协作(2024-2025):Multi-Agent Collaboration, Agent Memory
▪ 需求驱动:让多个Agent协同工作
单个Agent的能力有限,很多复杂任务需要多个Agent分工协作才能完成:
场景:开发一个新功能
- 产品经理Agent:需求分析、编写PRD
- 架构师Agent:架构设计、技术选型
- 开发Agent:编写代码、单元测试
- 测试Agent:集成测试、Bug修复
- 运维Agent:部署上线、监控告警
问题:多个Agent如何协作?
- 谁来分配任务?
- Agent之间如何沟通?
- 如何共享信息?
- 如何协调冲突?
- 如何保证质量?
▪ 技术突破1:MAS
MAS(Multi-Agent Collaboration,多智能体协作),是多个Agent之间的协作框架,核心是解决多个Agent之间的协同问题,让多个Agent能够高效分工、信息共享、协同完成复杂任务。
核心思想:
- 定义Agent之间的"通信协议"
- 定义Agent之间的"协作模式"
- 定义Agent之间的"任务分配策略"
MAS的协作模式:
1. 协作模式1:主从模式(Master-Slave) Master Agent: - 分配任务 - 收集结果 - 协调冲突 Slave Agents: - 执行任务 - 返回结果 - 接受监督 2. 协作模式2:协作模式(Collaborative) 所有Agent平等协作: - 共享信息 - 协商决策 - 共同完成目标 3. 协作模式3:竞争模式(Competitive) 多个Agent竞争完成任务: - 谁先完成谁赢 - 比较结果质量 - 选择最优方案 4. 协作模式4:层级模式(Hierarchical) 高层Agent: - 制定战略 - 分配目标 中层Agent: - 制定计划 - 分配任务 底层Agent: - 执行任务 - 返回结果
▪ 技术突破2:Agent记忆(Agent Memory)
Agent Memory(Agent记忆)让Agent可以"记住"历史信息,解决了Agent"无记忆"的痛点,为经验积累、个性化服务提供了可能。
核心思想:
- 长期记忆:跨对话的记忆
- 短期记忆:当前对话的记忆
- 上下文记忆:任务的上下文
Agent记忆的层次:
1. 短期记忆(Short-term Memory) - 当前对话的上下文 - 存储在模型的上文窗口中 - 例子:用户说"我想要...", Agent记住这个需求 2. 长期记忆(Long-term Memory) - 跨对话的记忆 - 存储在外部数据库中 - 例子:用户的偏好、历史决策、经验教训 3. 向量记忆(Vector Memory) - 用向量数据库存储记忆 - 支持语义搜索 - 例子:搜索"类似的任务" 4. 程序化记忆(Procedural Memory) - 存储程序化的知识 - 例子:Skills、Workflows 5. 事实记忆(Fact Memory) - 存储事实性知识 - 例子:用户的信息、项目的状态
Agent记忆的实现:
class AgentMemory: def __init__(self): self.short_term = [] # 短期记忆 self.long_term = VectorDatabase() # 长期记忆(向量数据库) self.procedural = SkillStore() # 程序化记忆(Skills) self.fact = RelationalDatabase() # 事实记忆(关系数据库) def remember(self, information, memory_type): """记住信息""" if memory_type == "short_term": self.short_term.append(information) elif memory_type == "long_term": self.long_term.store(information) elif memory_type == "procedural": self.procedural.store(information) elif memory_type == "fact": self.fact.store(information) def recall(self, query, memory_type): """回忆信息""" if memory_type == "short_term": return self.short_term elif memory_type == "long_term": return self.long_term.search(query) elif memory_type == "procedural": return self.procedural.search(query) elif memory_type == "fact": return self.fact.search(query) def consolidate(self): """记忆巩固""" # 将短期记忆转移到长期记忆 for information in self.short_term: self.long_term.store(information) self.short_term.clear()
Agentic Agent
Agentic Agent(智能代理)是具备以下特征的Agent:
- 自主规划可以自主规划任务
- 工具调用可以调用各种工具
- 记忆能力可以记住历史信息
- 学习能力可以从经验中学习
- 协作能力:可以与其他Agent协作
▪ AutoAgent
AutoAgent(自动智能体)是具备以下特征的Agent:
- 自动分解任务可以将复杂任务分解为子任务
- 自动选择工具可以根据任务自动选择合适的工具
- 自动处理异常可以自动处理各种异常情况
- 自动优化策略可以从经验中学习,优化策略
▪ 这个阶段的突破
突破一:多个Agent可以协作了
A2A让多个Agent可以协作完成复杂任务。
突破二:Agent可以"记住"了
Agent Memory让Agent可以记住历史信息,跨对话积累经验。
突破三:Agent可以"学习"了
Agent可以从经验中学习,优化策略。
▪ 这个阶段的局限
问题一:MAS的协作效率低
多个Agent协作时,通信成本高,决策速度慢。
问题二:Agent记忆的管理复杂
Agent记忆的存储、检索、更新、遗忘,都是复杂问题。
问题三:Agent的"自我意识"问题
Agent是否有"自我意识"?是否有"目标"?是否有"价值观"?这些问题都没有答案。
第八阶段:智能体运行时(2024-2025):Agent Runtime(趋势推演)
▪ 需求驱动:需要一个完整的Agent平台
随着Agent的普及,开发者面临的开发、部署、运维成本越来越高,核心痛点集中在:
问题一:开发一个Agent太复杂了
开发一个Agent需要:
- 定义工具(Function Calling)
- 配置MCP Server
- 编写Skills
- 设计Workflows
- 管理Agent Memory
- 实现A2A协作
- 监控Agent运行
- 处理异常情况
- ...
问题二:每个Agent都需要重新开发
每个Agent都需要:
- 重新实现工具调用
- 重新实现MCP Client
- 重新实现Skills管理
- 重新实现Workflow引擎
- 重新实现Agent Memory
- 重新实现A2A协作
- ...
问题三:Agent的部署和运维复杂
Agent的部署和运维需要:
- 部署多个模型
- 部署多个MCP Server
- 部署多个Agent
- 监控Agent运行
- 处理异常情况
- 更新Agent配置
- ...
核心需求:需要一个完整的Agent平台
▪ 技术突破1:Agent Runtime(智能体运行时)
Agent Runtime(智能体运行时)是支撑Agent开发、运行、管理的统一平台,相当于Agent的"基础操作系统"。
核心功能:
1. 模型管理 - 支持多个模型(OpenAI, Anthropic, DeepSeek, 本地模型...) - 模型切换 - 模型路由(根据任务选择最优模型) 2. 工具管理 - MCP Server管理 - Function Calling管理 - 工具注册、发现、调用 3. Skills管理 - Skills注册、发现、调用 - Skills版本管理 - Skills质量评估 4. Workflow管理 - Workflow定义、执行、监控 - Workflow可视化 - Workflow调试 5. Agent Memory管理 - 短期记忆、长期记忆 - 记忆存储、检索、更新、遗忘 - 记忆搜索、相似度匹配 6. A2A协作管理 - Agent注册、发现 - Agent通信、协调 - 任务分配、结果收集 7. 监控和告警 - Agent运行监控 - 工具调用监控 - 异常告警 - 性能分析 8. 部署和运维 - Agent部署 - 配置管理 - 版本管理 - 滚动更新
▪ 技术突破2:OpenClaw
OpenClaw是一个开源的Agent Runtime框架。
核心特点:
- 多模型支持
- 支持OpenAI、Anthropic、DeepSeek、本地模型...
- 模型路由(根据任务选择最优模型)
- 模型切换(动态切换模型)
- 多平台支持
- 支持Web、Telegram、Slack、Discord、飞书、企业微信...
- 统一的消息格式
- 平台适配器
- 完整的Agent生态
- Skills系统(5700+技能包)
- MCP协议支持
- Workflow引擎
- Agent Memory
- A2A协作
- 开发友好
- 声明式配置
- 可视化调试
- 实时监控
- 丰富的API
OpenClaw的架构:
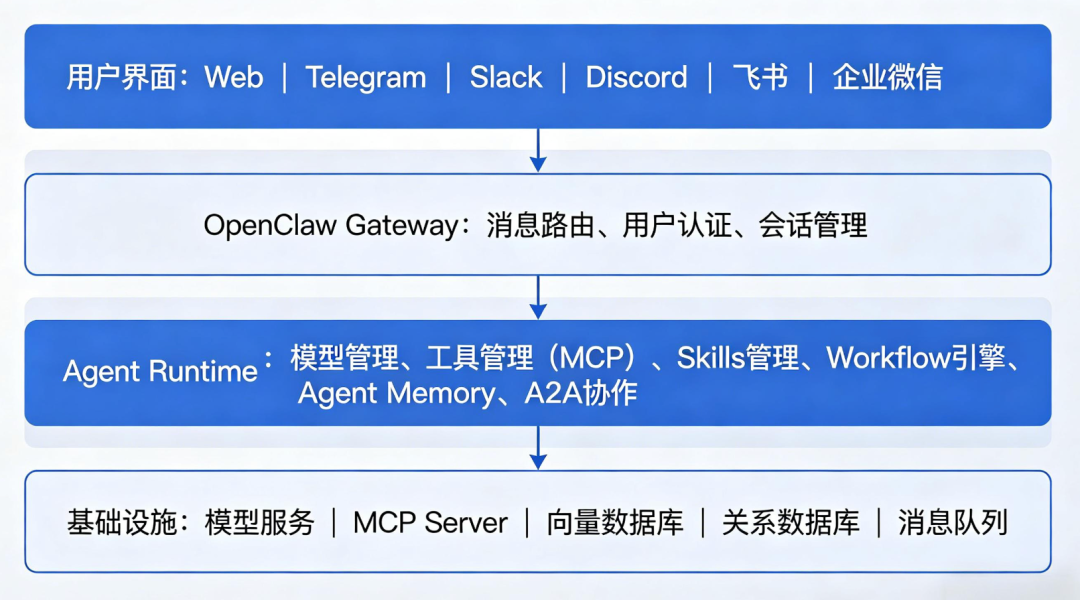
OpenClaw的Skills系统:
截至 2026 年 4 月 15 日,OpenClaw Skills(ClawHub 社区技能)最新精确数据为5700+,是 OpenClaw AI Agent 的模块化功能扩展生态,含 53 个官方内置技能与 5,652 个社区贡献技能,覆盖办公、开发、运维、生活等全场景。
OpenClaw Skills = 5700+ 技能包 技能分类: - 办公技能:Excel、PPT、Word、邮件、日历... - 编程技能:代码生成、代码审查、单元测试、调试... - 数据分析技能:数据清洗、数据分析、数据可视化... - 设计技能:Logo设计、海报设计、UI设计... - 营销技能:文案撰写、社交媒体营销、SEO... - 生活技能:旅行规划、菜谱推荐、健身计划... 技能来源: - 社区贡献 - 官方维护 - 企业定制
▪ 技术突破3:Hermes
Hermes是另一个Agent Runtime平台。
核心特点:
- 强大的Workflow引擎
- 可视化Workflow设计
- Workflow调试
- Workflow性能分析
- 强大的A2A协作
- Agent编排
- Agent通信
- 任务分配
- 强大的监控和分析
- 实时监控
- 性能分析
- 异常检测
▪ 这个阶段的突破
突破一:Agent开发变简单了
Agent Runtime提供了完整的Agent开发平台,开发者不需要从零开始。
突破二:Agent部署变简单了
Agent Runtime提供了一键部署、滚动更新、监控告警等功能。
突破三:Agent生态开始繁荣
OpenClaw的Skills系统有5700+技能包,社区贡献了大量Skills。
▪ 这个阶段的局限
问题一:Agent Runtime之间不兼容
不同厂商的Agent Runtime平台之间缺乏统一标准,Skills、工具、Agent无法跨平台复用,迁移成本高。
问题二:Agent Runtime的学习成本高
Agent Runtime功能丰富,涉及模型、工具、Skills、Workflow等多个模块,开发者需要掌握大量技术概念,学习成本较高。
问题三:Agent Runtime的性能瓶颈
Agent Runtime需要同时管理多个模型、多个工具、多个Agent,高并发场景下容易出现性能瓶颈,影响任务执行效率。
第九阶段:智能体操作系统(2025-2026):LLMOps + Agent Builder 平台(现状)与 Agent OS(未来趋势)
Agent Runtime解决了Agent开发、部署、运维的“工具化”问题,但随着Agent应用规模扩大,新的核心需求出现:
问题一:Agent生态碎片化
不同Agent Runtime平台、不同Agent之间缺乏统一的连接标准,Agent无法跨平台协同、资源无法共享,形成“信息孤岛”,难以支撑大规模、跨场景的Agent应用。
问题二:开发与运营的全链路协同不足
开发者需要在多个平台切换,完成Agent开发、测试、部署、监控、优化等环节,全链路协同效率低,难以实现Agent的快速迭代与规模化落地。
问题三:缺乏统一的生态入口
企业与开发者难以快速找到适配自身需求的Agent、Skills、工具,Agent的分发、复用、商业化路径不清晰,制约了Agent生态的进一步繁荣。
核心需求:需要一个更高层次的“生态级平台”,整合Agent开发、运营、分
发全链路能力,打破生态碎片化,实现Agent的规模化、生态化发展——这正是Agent OS(智能体操作系统)的核心定位,但目前该定位仍处于未来趋势阶段,尚未有成熟产品落地。
▪ 现状:LLMOps + Agent Builder 平台主导市场
目前行业内尚无真正意义上的“Agent OS”,市场主流产品以LLMOps(大模型运维平台)+ Agent Builder(智能体构建平台)为主,其中Dify、Coze均属于此类平台,而非Agent OS,二者的核心定位与功能如下:
1. 核心产品定位修正
- Coze(字节跳动旗下):定位为「Agent开发与分发平台」,核心功能是为开发者提供低代码/无代码工具,快速构建、调试、发布Agent,并支持Agent的分发与共享,并非“智能体操作系统”。其核心价值是降低Agent开发门槛,推动Agent的规模化创作与分发。
- Dify:定位为「LLMOps + Agent开发平台」,核心功能涵盖大模型管理、Prompt工程、Agent构建、工作流编排、监控运维等,聚焦于Agent开发与运营的全链路效率提升,同样不属于真正意义上的Agent OS。
2. 现状产品的核心功能(以Coze、Dify为代表)
- 低代码Agent构建:提供可视化编辑器,支持拖拽式配置工具、Skills、工作流,无需复杂编码即可快速构建Agent。
- 大模型适配与管理:兼容主流大模型(OpenAI、Anthropic、字节跳动火山大模型等),支持模型切换、参数调优、成本控制。
- 全链路运维监控:实时监控Agent运行状态、调用频率、错误率,提供性能分析、日志查询、异常告警功能,保障Agent稳定运行。
- 资源共享与分发:搭建Agent、Skills、工具市场,支持开发者上传、共享、复用资源,降低开发成本;提供Agent分发渠道,助力开发者实现Agent的商业化。
- 多场景适配:支持将构建好的Agent部署到Web、App、企业微信、飞书等多渠道,满足不同场景的应用需求。
▪ 未来趋势:Agent OS的核心特征(尚未落地)
你之前描述的“智能调度、自动学习、跨平台生态”,是Agent OS的核心趋势,但目前仍处于概念推演阶段,其完整定位应具备以下特征,区别于当前的LLMOps + Agent Builder平台:
1. 统一的生态入口:作为所有Agent、Skills、工具的“总入口”,支持跨平台Agent协同、资源共享,打破生态碎片化,实现“一次开发、多端复用”。
2. 智能全局调度:具备全局资源调度能力,可根据任务类型、优先级、资源占用情况,自动分配模型、工具、Agent资源,优化执行效率,降低运行成本。
3. 自主进化能力:能够基于全平台Agent的运行数据、用户反馈,自动优化S
kills、工作流、模型参数,实现生态级的自主学习与进化。
4. 跨平台生态兼容:制定统一的Agent、Skills、工具标准,支持不同厂商的Agent、Runtime平台接入,形成开放的生态体系。
5. 轻量化接入:为企业、开发者提供简单易用的接入方式,无需复杂配置,即可快速调用平台内的Agent、Skills、工具,降低生态参与门槛。
▪ Agent OS 与 Agent Runtime 的区别
Agent Runtime:聚焦于“单个/多个Agent的运行管理”,是Agent的“基础运行工具”,解决的是Agent“能跑起来”的问题;
Agent OS(未来):聚焦于“整个Agent生态的管理与协同”,是Agent生态的“核心操作系统”,解决的是Agent“能规模化、生态化发展”的问题。
▪ 这个阶段的突破(现状)
突破一:Agent开发门槛进一步降低
LLMOps + Agent Builder平台的普及,让非技术人员也能通过低代码/无代码方式构建Agent,大幅扩大了Agent的开发者群体,推动Agent的规模化应用。
突破二:Agent开发运营全链路闭环形成
平台整合了开发、测试、部署、监控、优化、分发全链路功能,实现了Agent全生命周期的高效管理,提升了Agent的迭代效率与落地速度。
突破三:Agent生态初步规模化
资源市场的出现,让Skills、工具、Agent实现了共享复用,形成了“开发-共享-复用-优化”的生态闭环,推动Agent生态从“分散开发”向“规模化协同”发展。
▪ 这个阶段的局限(现状与趋势差距)
问题一:缺乏统一的生态标准
不同平台的Agent、Skills、工具格式不统一,无法跨平台复用与协同,生态碎片化问题依然突出,距离Agent OS的“统一生态”目标还有较大差距。
问题二:全局调度与自主进化能力缺失
当前平台的调度能力局限于单个Agent或单个平台内部,无法实现跨平台、全局化的资源调度;且缺乏生态级的自主学习与进化能力,无法自动优化整个生态的运行效率。
问题三:商业化路径仍不清晰
Agent的分发、变现模式还处于探索阶段,开发者难以通过Agent实现稳定盈利,制约了生态的进一步繁荣与创新。
问题四:性能与安全挑战突出
随着Agent数量与应用场景的增加,平台面临高并发、数据安全、隐私保护等挑战,如何平衡性能、安全与用户体验,成为当前平台发展的核心难题。
▪ 总结:第九阶段的核心特征
当前处于“LLMOps + Agent Builder平台主导”的现状阶段,核心价值是降低Agent开发运营成本、推动Agent规模化应用;而Agent OS作为未来趋势,其“统一生态、智能调度、自主进化”的核心定位,将成为下一阶段AI进化的核心方向,推动Agent从“工具化”走向“生态化”。
总结:进化的本质和未来趋势
▪ 进化的本质
回顾这3年半的进化,我们可以发现一个清晰的规律:
进化的本质 = 需求倒逼技术突破
- LLM Chat → 需求:让AI能聊起来
- CoT/ToT → 需求:让AI能想清楚
- Function Calling → 需求:让AI能干活
- MCP → 需求:解决工具爆炸
- Skills → 需求:让AI会用对工具
- ReAct/Workflow → 需求:让AI能自主规划,又能可靠按流程执行
- MAS/Agent Memory → 需求:让多个Agent协同工作,并具备持续记忆与经验积累
- Agent Runtime → 需求:需要完整的Agent平台
- Agent OS → 需求:Agent的"操作系统"
进化的规律:
- 每次突破都解决了上一个阶段的瓶颈
- 每次突破都带来了新的能力
- 每次突破都留下了新的问题
- 进化从未停止,问题永远存在
▪ 技术栈的演进
从LLM Chat到Agent OS,技术栈发生了巨大的变化:
2022年:LLM Chat - Prompt Engineering - RLHF 2023年:CoT/ToT + Function Calling - Prompt Engineering - CoT/ToT - Function Calling 2024年:MCP + Skills + ReAct/Workflow - Prompt Engineering - CoT/ToT - Function Calling - MCP - Skills - Context Engineering - ReAct/Workflow 2025年:A2A + Agent Memory + Agent Runtime - Prompt Engineering - CoT/ToT - Function Calling - MCP - Skills - Context Engineering - ReAct/Workflow - A2A - Agent Memory - Harness Engineering - Agent Runtime 2026年:Agent OS - Prompt Engineering - CoT/ToT - Function Calling - MCP - Skills - Context Engineering - ReAct/Workflow - A2A - Agent Memory - Harness Engineering - Agent Runtime - Agent OS
▪ 未来的趋势
趋势1:Agent OS会更"智能"
Agent OS的"智能调度"、"智能学习"、"智能决策"会更成熟:
- 自动选择最优模型
- 自动选择最优工具
- 自动选择最优Skill
- 自动优化策略
趋势2:Agent OS会更"开放"
Agent OS的生态会更开放:
- Skills、工具、Agent可以跨平台使用
- 标准化的协议
- 统一的市场
趋势3:Agent OS会更"易用"
Agent OS会更易用:
- 自然语言配置
- 低代码/无代码
- 可视化界面
- 智能推荐
趋势4:Agent会更"个性化"
Agent会更"个性化":
- 记住用户的偏好
- 适应用户的习惯
- 预测用户的需求
- 主动提供服务
趋势5:Agent会更"社交化"
Agent会更"社交化":
- Agent之间的社交
- Agent与人类的社交
- Agent的"个性"
- Agent的"情感"
趋势6:Agent会更"专业化"
Agent会更"专业化":
- 医疗Agent
- 法律Agent
- 教育Agent
- 金融Agent
- ...
▪ 最后的话
从LLM Chat到Agent OS,这是一段波澜壮阔的进化之路。
3年半前,AI只是"会聊天的机器人"; 3年半后,AI已经能"自主干活、协同工作、学习优化"。
但这只是开始。
未来,Agent OS会更加智能、更加开放、更加易用; 未来,每个企业都会有自己的Agent团队; 未来,每个人都会有一个或多个"个人Agent"; 未来,Agent会成为"数字员工"的标配。
Agent OS的未来,就是AI的未来。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号