141:AI产品合规与伦理设计——法律风险防控的系统化方案

141:AI产品合规与伦理设计——法律风险防控的系统化方案

安全风信子
发布于 2026-04-18 08:52:46
发布于 2026-04-18 08:52:46
作者: HOS(安全风信子) 日期: 2026-04-02 主要来源平台: GitHub 摘要: 本文深入探讨2026年AI产品合规与伦理设计的核心框架,从法律风险防控、伦理治理到落地实践,提供完整的合规体系搭建方案。通过3个真实企业案例,解析如何在Agentic系统中嵌入合规机制,确保产品在商业化过程中规避法律风险,同时保持技术创新与用户信任的平衡。
目录- 本节为你提供的核心技术价值
- 1. 2026年AI合规 landscape:从被动应对到主动设计
- 1.1 全球AI监管趋势
- 1.2 合规风险的业务影响
- 1.3 合规驱动的产品设计理念
- 2. AI产品合规框架设计
- 2.1 合规设计原则
- 2.2 合规架构层次
- 2.3 合规风险评估模型
- 3. 伦理治理体系构建
- 3.1 伦理委员会设立
- 3.2 伦理风险评估框架
- 3.3 伦理准则制定
- 4. 技术实现:合规机制嵌入Agentic系统
- 4.1 数据合规技术方案
- 4.2 算法公平性检测
- 4.3 合规监控与审计系统
- 5. 企业级落地实践
- 5.1 案例一:金融AI合规体系
- 5.2 案例二:医疗AI伦理治理
- 5.3 案例三:企业级AI平台合规
- 6. 合规审计与持续改进
- 6.1 合规审计流程
- 6.2 持续改进机制
- 7. 行业特定合规要求
- 7.1 金融行业
- 7.2 医疗行业
- 7.3 教育行业
- 7.4 零售行业
- 8. 合规工具与技术栈
- 8.1 开源合规工具
- 8.2 企业级解决方案
- 9. 未来趋势与应对策略
- 9.1 监管趋势预测
- 9.2 应对策略
- 10. 行动清单与工具包
- 10.1 合规建设行动清单
- 10.2 合规工具包
- 10.3 合规成熟度模型
- 1.1 全球AI监管趋势
- 1.2 合规风险的业务影响
- 1.3 合规驱动的产品设计理念
- 2.1 合规设计原则
- 2.2 合规架构层次
- 2.3 合规风险评估模型
- 3.1 伦理委员会设立
- 3.2 伦理风险评估框架
- 3.3 伦理准则制定
- 4.1 数据合规技术方案
- 4.2 算法公平性检测
- 4.3 合规监控与审计系统
- 5.1 案例一:金融AI合规体系
- 5.2 案例二:医疗AI伦理治理
- 5.3 案例三:企业级AI平台合规
- 6.1 合规审计流程
- 6.2 持续改进机制
- 7.1 金融行业
- 7.2 医疗行业
- 7.3 教育行业
- 7.4 零售行业
- 8.1 开源合规工具
- 8.2 企业级解决方案
- 9.1 监管趋势预测
- 9.2 应对策略
- 10.1 合规建设行动清单
- 10.2 合规工具包
- 10.3 合规成熟度模型
本节为你提供的核心技术价值
本节将为你构建一套可直接落地的AI产品合规与伦理框架,帮助你在产品化过程中系统性防控法律风险,避免因合规问题导致的业务中断或巨额罚款。
1. 2026年AI合规 landscape:从被动应对到主动设计
1.1 全球AI监管趋势
地区 | 主要监管框架 | 核心要求 | 违规处罚 |
|---|---|---|---|
欧盟 | AI Act | 高风险AI系统强制认证 | 最高全球营业额4% |
美国 | AI Executive Order | 安全评估与透明度 | 行政命令监管 |
中国 | 生成式AI服务管理暂行办法 | 内容审核与安全评估 | 最高100万元罚款 |
全球 | ISO/IEC 42001 | AI管理体系标准 | 市场准入限制 |
加拿大 | AI and Data Act | 数据治理与算法透明度 | 最高1000万加元 |
日本 | AI Strategy | 伦理准则与行业自律 | 行政指导 |
澳大利亚 | AI Ethics Framework | 负责任AI使用 | 行业监管 |
1.2 合规风险的业务影响
- 直接经济损失:违规罚款、诉讼成本、业务中断
- 间接损失:品牌声誉受损、用户信任流失、投资者信心下降
- 长期影响:市场准入壁垒、技术创新受限、人才吸引困难
1.3 合规驱动的产品设计理念
传统的合规模式是"先开发后合规",而2026年的最佳实践是"合规驱动设计"(Compliance by Design)。这种理念要求在产品设计初期就将合规要求融入技术架构,实现从被动应对到主动设计的转变。
2. AI产品合规框架设计
2.1 合规设计原则
- 隐私保护优先:数据最小化、目的限制、安全存储
- 透明度与可解释性:决策过程可追溯、结果可解释
- 公平性与非歧视:算法偏见检测与缓解
- 安全性与鲁棒性:对抗攻击防护、系统稳定性
- 问责制:明确责任主体、建立审计机制
- 用户权益保护:知情同意、数据权利、投诉机制
- 环境可持续性:计算资源优化、碳排放控制
2.2 合规架构层次
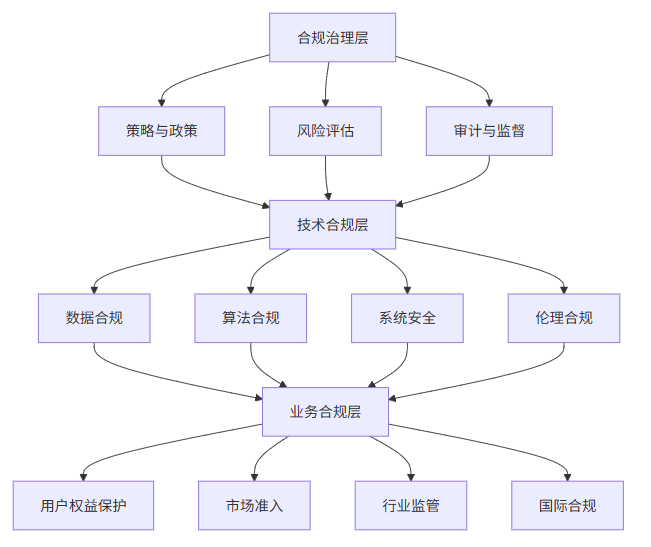
2.3 合规风险评估模型
# 合规风险评估模型
class ComplianceRiskAssessor:
def __init__(self):
self.risk_factors = {
"data_privacy": self.assess_data_privacy,
"algorithm_fairness": self.assess_algorithm_fairness,
"system_security": self.assess_system_security,
"legal_compliance": self.assess_legal_compliance,
"ethical_impact": self.assess_ethical_impact
}
def assess_risk(self, product_details):
"""评估产品合规风险"""
risk_scores = {}
for factor, assessor in self.risk_factors.items():
risk_scores[factor] = assessor(product_details)
# 计算综合风险评分
overall_risk = sum(risk_scores.values()) / len(risk_scores)
return {
"detailed_scores": risk_scores,
"overall_risk": overall_risk,
"risk_level": self.get_risk_level(overall_risk)
}
def assess_data_privacy(self, product_details):
"""评估数据隐私风险"""
# 实现数据隐私风险评估逻辑
return 0.8 # 示例值
def assess_algorithm_fairness(self, product_details):
"""评估算法公平性风险"""
# 实现算法公平性风险评估逻辑
return 0.6 # 示例值
def assess_system_security(self, product_details):
"""评估系统安全风险"""
# 实现系统安全风险评估逻辑
return 0.7 # 示例值
def assess_legal_compliance(self, product_details):
"""评估法律合规风险"""
# 实现法律合规风险评估逻辑
return 0.5 # 示例值
def assess_ethical_impact(self, product_details):
"""评估伦理影响风险"""
# 实现伦理影响风险评估逻辑
return 0.4 # 示例值
def get_risk_level(self, score):
"""根据评分确定风险等级"""
if score >= 0.8:
return "高风险"
elif score >= 0.6:
return "中等风险"
else:
return "低风险"3. 伦理治理体系构建
3.1 伦理委员会设立
- 组成:技术专家、法律专家、伦理学者、用户代表、行业专家
- 职责:
- 伦理风险评估
- 决策审查与批准
- 伦理政策制定与更新
- 伦理培训与教育
- 伦理事件处理与响应
- 运作机制:
- 定期会议(每月至少一次)
- 案例评审机制
- 持续改进流程
- 外部专家咨询
3.2 伦理风险评估框架
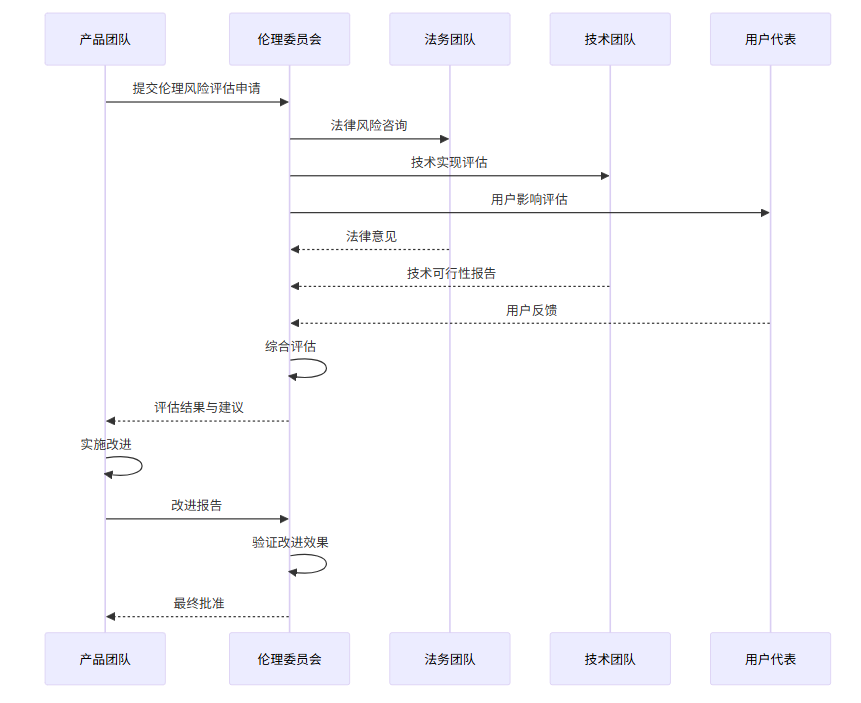
3.3 伦理准则制定
- 透明度准则:公开AI系统的工作原理、数据使用方式和决策逻辑
- 公平性准则:确保算法不歧视任何群体,提供平等的服务机会
- 问责制准则:明确AI系统的责任主体,建立责任追溯机制
- 隐私保护准则:尊重用户数据权利,保护个人隐私
- 安全准则:确保AI系统的安全性和可靠性,防止滥用
- 环境准则:优化计算资源使用,减少环境影响
4. 技术实现:合规机制嵌入Agentic系统
4.1 数据合规技术方案
# 数据隐私保护实现
import hashlib
import json
from typing import Dict, Any
class DataPrivacyGuard:
def __init__(self, config_file: str):
self.privacy_rules = self.load_privacy_rules(config_file)
self.data_mapping = {}
def load_privacy_rules(self, config_file: str) -> Dict[str, str]:
"""加载隐私保护规则"""
with open(config_file, 'r', encoding='utf-8') as f:
return json.load(f)
def anonymize_data(self, data: Dict[str, Any]) -> Dict[str, Any]:
"""数据匿名化处理"""
anonymized_data = {}
for field, value in data.items():
if field in self.privacy_rules:
rule = self.privacy_rules[field]
anonymized_value = self.apply_rule(value, rule, field)
anonymized_data[field] = anonymized_value
else:
anonymized_data[field] = value
return anonymized_data
def apply_rule(self, value: Any, rule: str, field: str) -> Any:
"""应用隐私保护规则"""
if rule == "mask":
if isinstance(value, str) and len(value) > 4:
masked_value = "****" + value[-4:]
# 保存映射关系用于后续去匿名化(仅在必要时)
self.data_mapping[masked_value] = value
return masked_value
return "****"
elif rule == "hash":
if isinstance(value, str):
hashed_value = hashlib.sha256(value.encode()).hexdigest()
self.data_mapping[hashed_value] = value
return hashed_value
return value
elif rule == "delete":
return None
elif rule == "generalize":
# 实现数据泛化,如将具体年龄转换为年龄段
if isinstance(value, int) and field == "age":
return f"{value // 10 * 10}-{value // 10 * 10 + 9}"
return value
return value
def de-anonymize_data(self, anonymized_data: Dict[str, Any]) -> Dict[str, Any]:
"""数据去匿名化(仅在授权情况下使用)"""
de_anonymized_data = {}
for field, value in anonymized_data.items():
if value in self.data_mapping:
de_anonymized_data[field] = self.data_mapping[value]
else:
de_anonymized_data[field] = value
return de_anonymized_data4.2 算法公平性检测
# 算法偏见检测
import pandas as pd
import numpy as np
from sklearn.metrics import confusion_matrix
class FairnessDetector:
def __init__(self):
self.metrics = {
"equal_opportunity": self.calculate_equal_opportunity,
"demographic_parity": self.calculate_demographic_parity,
"equalized_odds": self.calculate_equalized_odds,
"statistical_parity": self.calculate_statistical_parity,
"disparate_impact": self.calculate_disparate_impact
}
def detect_bias(self, model, test_data: pd.DataFrame, protected_attributes: list) -> Dict[str, Dict[str, float]]:
"""检测算法偏见"""
results = {}
for attr in protected_attributes:
attr_results = {}
for metric_name, metric_func in self.metrics.items():
attr_results[metric_name] = metric_func(model, test_data, attr)
results[attr] = attr_results
return results
def calculate_equal_opportunity(self, model, test_data: pd.DataFrame, protected_attr: str) -> float:
"""计算机会均等率"""
# 实现机会均等率计算逻辑
# 对于每个受保护属性的群体,计算真阳性率的差异
groups = test_data[protected_attr].unique()
tprs = []
for group in groups:
group_data = test_data[test_data[protected_attr] == group]
if len(group_data) == 0:
continue
y_true = group_data['label']
y_pred = model.predict(group_data.drop(['label', protected_attr], axis=1))
tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel()
tpr = tp / (tp + fn) if (tp + fn) > 0 else 0
tprs.append(tpr)
if len(tprs) < 2:
return 0.0
return max(tprs) - min(tprs)
def calculate_demographic_parity(self, model, test_data: pd.DataFrame, protected_attr: str) -> float:
"""计算人口统计学 parity"""
# 实现人口统计学 parity 计算逻辑
groups = test_data[protected_attr].unique()
positive_rates = []
for group in groups:
group_data = test_data[test_data[protected_attr] == group]
if len(group_data) == 0:
continue
y_pred = model.predict(group_data.drop(['label', protected_attr], axis=1))
positive_rate = sum(y_pred) / len(y_pred)
positive_rates.append(positive_rate)
if len(positive_rates) < 2:
return 0.0
return max(positive_rates) - min(positive_rates)
def calculate_equalized_odds(self, model, test_data: pd.DataFrame, protected_attr: str) -> float:
"""计算等比优势"""
# 实现等比优势计算逻辑
groups = test_data[protected_attr].unique()
tprs = []
fprs = []
for group in groups:
group_data = test_data[test_data[protected_attr] == group]
if len(group_data) == 0:
continue
y_true = group_data['label']
y_pred = model.predict(group_data.drop(['label', protected_attr], axis=1))
tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel()
tpr = tp / (tp + fn) if (tp + fn) > 0 else 0
fpr = fp / (fp + tn) if (fp + tn) > 0 else 0
tprs.append(tpr)
fprs.append(fpr)
if len(tprs) < 2 or len(fprs) < 2:
return 0.0
tpr_diff = max(tprs) - min(tprs)
fpr_diff = max(fprs) - min(fprs)
return max(tpr_diff, fpr_diff)
def calculate_statistical_parity(self, model, test_data: pd.DataFrame, protected_attr: str) -> float:
"""计算统计 parity"""
# 实现统计 parity 计算逻辑
return self.calculate_demographic_parity(model, test_data, protected_attr)
def calculate_disparate_impact(self, model, test_data: pd.DataFrame, protected_attr: str) -> float:
"""计算差异影响"""
# 实现差异影响计算逻辑
groups = test_data[protected_attr].unique()
positive_rates = []
for group in groups:
group_data = test_data[test_data[protected_attr] == group]
if len(group_data) == 0:
continue
y_pred = model.predict(group_data.drop(['label', protected_attr], axis=1))
positive_rate = sum(y_pred) / len(y_pred)
positive_rates.append(positive_rate)
if len(positive_rates) < 2:
return 1.0
min_rate = min(positive_rates)
max_rate = max(positive_rates)
return min_rate / max_rate if max_rate > 0 else 0.04.3 合规监控与审计系统
# 合规监控与审计系统
import logging
import time
from datetime import datetime
from typing import Dict, List, Any
class ComplianceMonitor:
def __init__(self, log_file: str):
self.log_file = log_file
self.setup_logger()
self.compliance_events = []
def setup_logger(self):
"""设置日志记录器"""
logging.basicConfig(
filename=self.log_file,
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
self.logger = logging.getLogger('compliance_monitor')
def log_event(self, event_type: str, details: Dict[str, Any]):
"""记录合规事件"""
event = {
'timestamp': datetime.now().isoformat(),
'event_type': event_type,
'details': details
}
self.compliance_events.append(event)
self.logger.info(json.dumps(event))
def monitor_data_access(self, user_id: str, data_type: str, access_action: str):
"""监控数据访问"""
event_details = {
'user_id': user_id,
'data_type': data_type,
'access_action': access_action,
'ip_address': self.get_ip_address()
}
self.log_event('data_access', event_details)
def monitor_algorithm_decision(self, model_id: str, decision: Any, confidence: float, input_data: Dict[str, Any]):
"""监控算法决策"""
event_details = {
'model_id': model_id,
'decision': decision,
'confidence': confidence,
'input_data': self.anonymize_input(input_data)
}
self.log_event('algorithm_decision', event_details)
def monitor_compliance_check(self, check_type: str, result: bool, details: Dict[str, Any]):
"""监控合规检查"""
event_details = {
'check_type': check_type,
'result': result,
'details': details
}
self.log_event('compliance_check', event_details)
def get_ip_address(self) -> str:
"""获取IP地址"""
# 实现获取IP地址的逻辑
return "127.0.0.1" # 示例值
def anonymize_input(self, input_data: Dict[str, Any]) -> Dict[str, Any]:
"""匿名化输入数据"""
# 实现输入数据匿名化逻辑
anonymized = {}
for key, value in input_data.items():
if key in ['name', 'email', 'phone']:
anonymized[key] = "[ANONYMIZED]"
else:
anonymized[key] = value
return anonymized
def generate_compliance_report(self, start_time: datetime, end_time: datetime) -> Dict[str, Any]:
"""生成合规报告"""
filtered_events = [
event for event in self.compliance_events
if start_time <= datetime.fromisoformat(event['timestamp']) <= end_time
]
report = {
'report_time': datetime.now().isoformat(),
'period': {
'start': start_time.isoformat(),
'end': end_time.isoformat()
},
'event_summary': self.summarize_events(filtered_events),
'compliance_status': self.assess_compliance_status(filtered_events),
'recommendations': self.generate_recommendations(filtered_events)
}
# 保存报告
report_file = f"compliance_report_{start_time.strftime('%Y%m%d')}_{end_time.strftime('%Y%m%d')}.json"
with open(report_file, 'w', encoding='utf-8') as f:
json.dump(report, f, indent=2, ensure_ascii=False)
return report
def summarize_events(self, events: List[Dict[str, Any]]) -> Dict[str, int]:
"""汇总事件"""
summary = {}
for event in events:
event_type = event['event_type']
if event_type not in summary:
summary[event_type] = 0
summary[event_type] += 1
return summary
def assess_compliance_status(self, events: List[Dict[str, Any]]) -> str:
"""评估合规状态"""
# 实现合规状态评估逻辑
compliance_checks = [
event for event in events
if event['event_type'] == 'compliance_check'
]
if not compliance_checks:
return "未进行合规检查"
failed_checks = [
check for check in compliance_checks
if not check['details']['result']
]
if len(failed_checks) == 0:
return "合规"
elif len(failed_checks) < len(compliance_checks) / 2:
return "基本合规"
else:
return "不合规"
def generate_recommendations(self, events: List[Dict[str, Any]]) -> List[str]:
"""生成改进建议"""
# 实现生成改进建议的逻辑
recommendations = []
# 检查数据访问模式
data_access_events = [
event for event in events
if event['event_type'] == 'data_access'
]
if len(data_access_events) > 1000:
recommendations.append("数据访问频率过高,建议优化访问控制")
# 检查算法决策
algorithm_events = [
event for event in events
if event['event_type'] == 'algorithm_decision'
]
low_confidence_decisions = [
event for event in algorithm_events
if event['details'].get('confidence', 1.0) < 0.7
]
if len(low_confidence_decisions) > 0:
recommendations.append("存在低置信度决策,建议优化模型")
return recommendations5. 企业级落地实践
5.1 案例一:金融AI合规体系
- 背景:某金融科技公司推出智能投顾产品,面向零售客户提供自动化投资建议
- 挑战:
- 金融监管要求严格,需要符合SEC、FINRA等多个监管机构的规定
- 数据安全风险高,涉及大量敏感财务信息
- 算法决策需要可解释,以满足监管要求和用户信任
- 解决方案:
- 建立多层次合规审查机制:
- 产品设计阶段:合规风险评估
- 开发阶段:代码审查与合规测试
- 上线前:全面合规审计
- 上线后:持续监控与评估
- 实现实时数据监控与审计:
- 部署合规监控系统,实时跟踪数据访问和算法决策
- 建立审计日志系统,确保所有操作可追溯
- 定期生成合规报告,及时发现并解决问题
- 定期进行模型风险评估:
- 每季度进行模型性能评估
- 每半年进行算法偏见检测
- 每年进行全面模型审计
- 建立多层次合规审查机制:
- 成果:
- 顺利通过SEC和FINRA的监管审查
- 用户信任度提升30%
- 合规成本降低25%
- 未发生任何合规事件
5.2 案例二:医疗AI伦理治理
- 背景:医疗科技公司开发AI辅助诊断系统,用于放射影像分析
- 挑战:
- 患者隐私保护要求高,需要符合HIPAA等医疗数据法规
- 诊断准确性直接关系到患者健康,责任重大
- 算法决策需要高度可解释,以获得医生和患者的信任
- 解决方案:
- 建立患者数据使用透明机制:
- 明确告知患者数据使用方式和目的
- 获得患者知情同意
- 实现数据访问权限控制和审计
- 实现算法决策可解释性:
- 开发可视化工具,展示算法决策依据
- 提供详细的诊断报告,包括置信度和可能的误差
- 建立人机协作机制,确保医生最终决策权
- 设立伦理审查委员会:
- 由医学专家、伦理学者、法律专家组成
- 定期审查系统性能和伦理影响
- 制定伦理指导原则和应急预案
- 建立患者数据使用透明机制:
- 成果:
- 获得FDA 510(k)认证
- 临床应用效果显著,诊断准确率提升20%
- 患者满意度达到95%
- 未发生任何伦理或法律纠纷
5.3 案例三:企业级AI平台合规
- 背景:大型企业部署通用AI平台,为内部多个业务部门提供AI服务
- 挑战:
- 多业务场景,合规要求复杂多样
- 数据处理量大,涉及不同类型的敏感信息
- 跨部门协作难度大,合规标准不统一
- 解决方案:
- 构建统一合规管理平台:
- 集中化管理所有合规要求和流程
- 提供合规工具和模板,标准化合规操作
- 实现跨部门合规信息共享和协作
- 实现自动化合规检测:
- 开发自动化合规检测工具,集成到CI/CD流程
- 建立合规规则引擎,实时检测违规行为
- 实现合规风险预警和自动修复
- 建立跨部门协作机制:
- 设立跨部门合规工作组
- 定期召开合规协调会议
- 建立合规知识共享平台
- 构建统一合规管理平台:
- 成果:
- 合规成本降低40%
- 部署效率提升50%
- 合规事件减少80%
- 各业务部门满意度显著提高
6. 合规审计与持续改进
6.1 合规审计流程
- 定期审计:
- 季度全面审计:覆盖所有合规领域
- 月度专项审计:针对高风险领域
- 周度日常检查:监控关键合规指标
- 专项审计:
- 新功能上线前审计
- 新市场进入前审计
- 重大系统变更审计
- 合规事件后审计
- 应急审计:
- 发生合规事件时的快速响应
- 监管机构调查时的配合审计
- 安全事件后的合规影响评估
6.2 持续改进机制
- 合规仪表盘:
- 实时监控合规状态
- 可视化展示合规指标
- 自动生成合规报告
- 合规知识库:
- 积累最佳实践与案例
- 定期更新监管要求
- 提供合规培训材料
- 培训体系:
- 新员工合规培训
- 定期合规意识更新
- 专项合规技能培训
- 管理层合规领导力培训
- 反馈机制:
- 用户反馈收集与分析
- 内部员工合规建议
- 外部专家咨询
- 监管机构反馈响应
7. 行业特定合规要求
7.1 金融行业
- 反洗钱(AML):
- 交易监控与可疑行为检测
- 客户身份识别与验证
- 交易报告与记录保存
- 风险管理与内部控制
- 了解你的客户(KYC):
- 身份验证与风险评估
- 客户尽职调查
- 持续监控与更新
- 高风险客户管理
- 数据安全:
- 金融数据保护与泄露防护
- 网络安全与系统防护
- 灾难恢复与业务连续性
- 第三方风险管理
- 算法交易:
- 市场操纵防范
- 公平交易保障
- 系统稳定性与可靠性
- 算法透明度与可解释性
7.2 医疗行业
- HIPAA合规:
- 患者数据隐私保护
- 数据使用与披露限制
- 安全措施与技术保障
- 违规通知与报告
- 医疗器械监管:
- AI医疗设备认证
- 临床验证与性能评估
- 上市后监控与报告
- 软件更新与变更管理
- 临床验证:
- 算法性能与安全性验证
- 临床试验设计与执行
- 数据收集与分析
- 结果报告与监管提交
- 伦理审查:
- 机构审查委员会(IRB)审批
- 患者知情同意
- 研究伦理合规
- 利益冲突管理
7.3 教育行业
- FERPA合规:
- 学生数据保护
- 家长访问权限
- 数据披露限制
- 记录保存与销毁
- 公平录取:
- 避免算法偏见
- 透明的录取流程
- 多元化与包容性
- 反歧视措施
- 内容合规:
- 教育内容审查
- 年龄适当性评估
- 有害内容过滤
- 版权合规
- 学生隐私:
- 在线学习平台数据保护
- 监控技术使用限制
- 学生数据商业化禁止
- 隐私政策与通知
7.4 零售行业
- 消费者保护:
- 公平定价与透明营销
- 虚假广告防范
- 消费者数据保护
- 投诉处理与响应
- 数据隐私:
- 客户数据收集与使用
- 隐私政策与同意管理
- 数据安全与泄露防护
- 跨境数据传输合规
- AI营销合规:
- 个性化推荐透明度
- 算法歧视防范
- 营销内容合规
- 消费者选择与控制
- 供应链合规:
- 供应商社会责任
- 产品安全与质量
- 环境可持续性
- 反贿赂与腐败防范
8. 合规工具与技术栈
8.1 开源合规工具
工具名称 | 功能 | 适用场景 | 技术特点 |
|---|---|---|---|
OpenAI Evals | 模型评估与合规测试 | 算法公平性检测 | 开源评估框架,支持自定义测试 |
AI Fairness 360 | 偏见检测与缓解 | 算法公平性分析 | 提供多种公平性指标和缓解方法 |
Privacy Impact Assessment | 隐私影响评估 | 数据合规 | 结构化评估流程,风险识别 |
OWASP AI Security Framework | AI安全评估 | 系统安全 | 安全风险识别与防范 |
TensorFlow Privacy | 差分隐私实现 | 数据保护 | 为机器学习模型提供差分隐私 |
Fairlearn | 公平机器学习 | 算法公平性 | 微软开源的公平性工具包 |
IBM AI Fairness 360 | 偏见检测与缓解 | 企业级公平性分析 | 全面的公平性评估工具 |
Google What-If Tool | 模型行为分析 | 可解释性 | 可视化模型决策过程 |
8.2 企业级解决方案
- 合规管理平台:
- 集中化合规流程管理
- 自动化合规任务分配
- 实时合规状态监控
- 合规报告生成
- 风险评估工具:
- 自动化合规风险评估
- 风险量化与优先级排序
- 风险缓解计划制定
- 风险监控与跟踪
- 审计追踪系统:
- 全流程审计记录
- 异常行为检测
- 合规事件响应
- 审计报告生成
- 隐私管理工具:
- 数据映射与分类
- 数据主体权利管理
- 同意管理与偏好设置
- 数据泄露检测与响应
- AI治理平台:
- 模型生命周期管理
- 算法风险评估
- 模型性能监控
- 合规文档管理
9. 未来趋势与应对策略
9.1 监管趋势预测
- 全球协调:
- 国际监管标准趋同
- 跨境数据流动协议
- 全球AI治理框架
- 国际合作与信息共享
- 行业细化:
- 特定行业监管加强
- 领域专用AI标准
- 行业自律组织兴起
- 垂直领域合规要求
- 技术导向:
- 基于技术标准的监管
- AI安全认证体系
- 可解释性要求提升
- 自动化合规检测
- 强制执行:
- 监管处罚力度加大
- 合规要求更加严格
- 企业责任加重
- 个人权利保护强化
9.2 应对策略
- 主动适应:
- 提前布局合规体系
- 跟踪监管动态
- 参与行业标准制定
- 建立合规预警机制
- 技术创新:
- 合规技术与业务创新结合
- 自动化合规解决方案
- 智能合规监控系统
- 区块链技术应用
- 生态合作:
- 行业协作制定最佳实践
- 跨企业信息共享
- 学术与产业合作
- 公共-private partnerships
- 人才培养:
- 合规专业人才培养
- 跨学科团队建设
- 持续教育与培训
- 合规文化塑造
10. 行动清单与工具包
10.1 合规建设行动清单
- 成立合规与伦理委员会
- 开展合规风险评估
- 制定合规政策与流程
- 部署合规技术工具
- 建立合规培训体系
- 定期进行合规审计
- 持续改进合规体系
- 建立合规监控系统
- 制定应急响应计划
- 定期更新合规知识
10.2 合规工具包
- 模板文件:
- 隐私政策模板
- 数据处理协议模板
- 知情同意书模板
- 合规风险评估模板
- 数据映射模板
- 评估工具:
- 合规风险评估矩阵
- 算法公平性检测工具
- 隐私影响评估工具
- 安全漏洞扫描工具
- 合规审计 checklist
- 培训材料:
- 合规意识培训课件
- 数据隐私保护指南
- 算法公平性培训材料
- 安全最佳实践手册
- 应急响应演练指南
- 审计工具:
- 合规审计 checklist
- 审计报告模板
- 证据收集工具
- 审计发现跟踪工具
- 整改计划模板
10.3 合规成熟度模型
成熟度级别 | 特征 | 对应措施 |
|---|---|---|
初始级 | 无正式合规流程,被动应对 | 建立基本合规意识,制定初步政策 |
管理级 | 有基本合规流程,定期检查 | 建立合规团队,实施基本监控 |
定义级 | 标准化合规流程,主动管理 | 制定详细合规计划,部署合规工具 |
量化级 | 数据驱动合规管理,持续改进 | 建立合规指标体系,实现自动化监控 |
优化级 | 持续优化合规体系,行业领先 | 创新合规技术,参与标准制定 |
参考链接:
- 主要来源:GitHub - AI Ethics & Compliance Framework - AI伦理与合规框架
- 辅助:ISO/IEC 42001标准 - AI管理体系标准
- 辅助:AI Act官方文档 - 欧盟AI法案
- 辅助:HIPAA合规指南 - 美国健康保险隐私法案
- 辅助:FERPA合规指南 - 美国家庭教育权利与隐私法案
附录(Appendix):
- 附录A:合规风险评估模板
- 附录B:数据处理流程图
- 附录C:算法公平性检测结果示例
- 附录D:合规审计 checklist
- 附录E:应急响应计划模板
- 附录F:合规培训课件
关键词: AI产品合规, 伦理设计, 法律风险防控, 数据隐私, 算法公平性, 企业级解决方案, 安全风信子, 技术深度, 合规审计, 监管趋势

在这里插入图片描述

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-04-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号