Nat.Mach. Intell. | 利用归纳先验在小数据条件下预测并解析细胞类型特异性药物响应

Nat.Mach. Intell. | 利用归纳先验在小数据条件下预测并解析细胞类型特异性药物响应

DrugOne
发布于 2026-03-25 17:04:33
发布于 2026-03-25 17:04:33
DRUGONE
预测不同细胞类型对药物的反应是精准医学的重要目标,但在实际研究中,每种细胞类型通常只有少量实验数据,使得传统机器学习方法难以建立可靠模型。深度学习模型虽然具有较强表达能力,但往往依赖大规模数据,在小样本条件下容易过拟合,并且难以解释预测结果。
研究人员提出一种基于归纳先验的机器学习框架,用于在小数据条件下预测并解释细胞类型特异性的药物反应。该方法通过将生物学知识作为先验结构嵌入模型,使模型能够在有限数据下学习合理的表示,并保持良好的泛化能力。研究结果表明,该方法在多个药物反应预测任务中显著优于传统深度学习模型,并能够揭示与药物敏感性相关的基因和通路。

药物对不同细胞类型的作用差异是药物开发和精准治疗中的关键问题。例如,同一种药物在不同肿瘤细胞系中可能表现出完全不同的敏感性,因此需要建立能够预测细胞特异性药物反应的模型。
现有研究通常使用大规模细胞系数据库训练机器学习模型,但在真实应用中,研究人员往往只拥有少量样本,例如患者来源细胞或罕见细胞类型。在这种情况下,传统深度学习模型难以训练稳定,而简单模型又难以捕捉复杂的生物学关系。
一种可行的解决思路是引入归纳先验,即在模型中加入生物学知识,例如基因调控网络或信号通路结构,使模型在数据不足时仍能学习合理的关系。通过这种方式,可以减少对大规模数据的依赖,同时提高模型可解释性。
方法
研究人员构建了一种基于归纳先验的神经网络模型,将基因表达数据与生物通路信息结合,用于预测细胞对不同药物的反应。
模型首先利用已知的基因通路结构建立网络连接,使得模型参数受到生物学结构约束。随后,模型在有限样本上进行训练,并通过正则化和共享参数提高泛化能力。
为了提高可解释性,模型在预测过程中可以识别对药物反应最重要的基因和通路,从而揭示潜在的作用机制。
该方法不仅能够进行预测,还可以用于解释不同细胞类型对药物反应差异的原因。
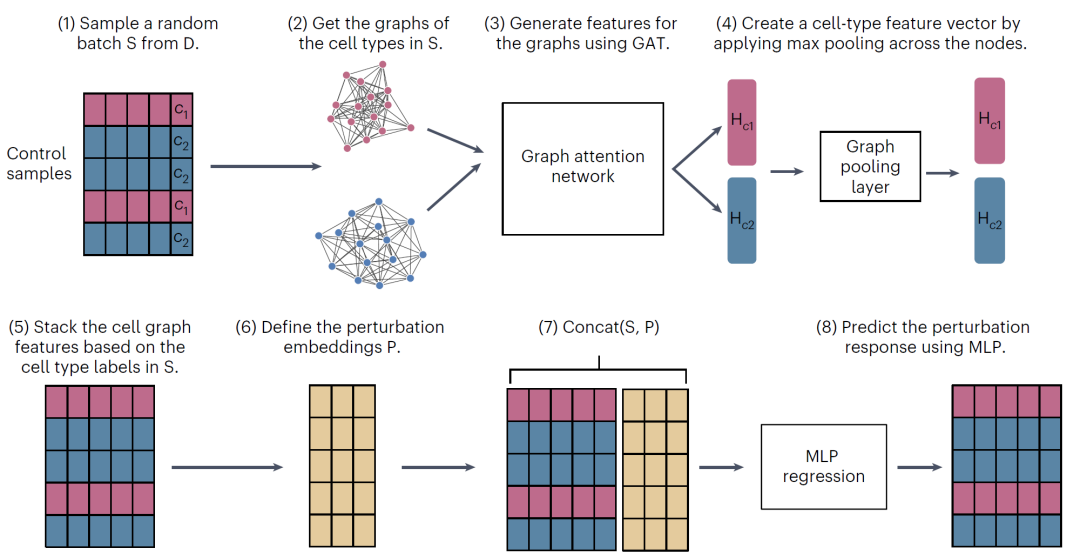
图1:PrePR-CT:一种基于图结构的深度学习方法,用于预测单细胞扰动响应。
结果
小样本条件下的预测性能
研究人员首先在少量样本条件下比较不同模型的预测性能。结果表明,引入归纳先验后,模型在数据较少时仍能保持较高精度,而传统深度学习模型性能明显下降。
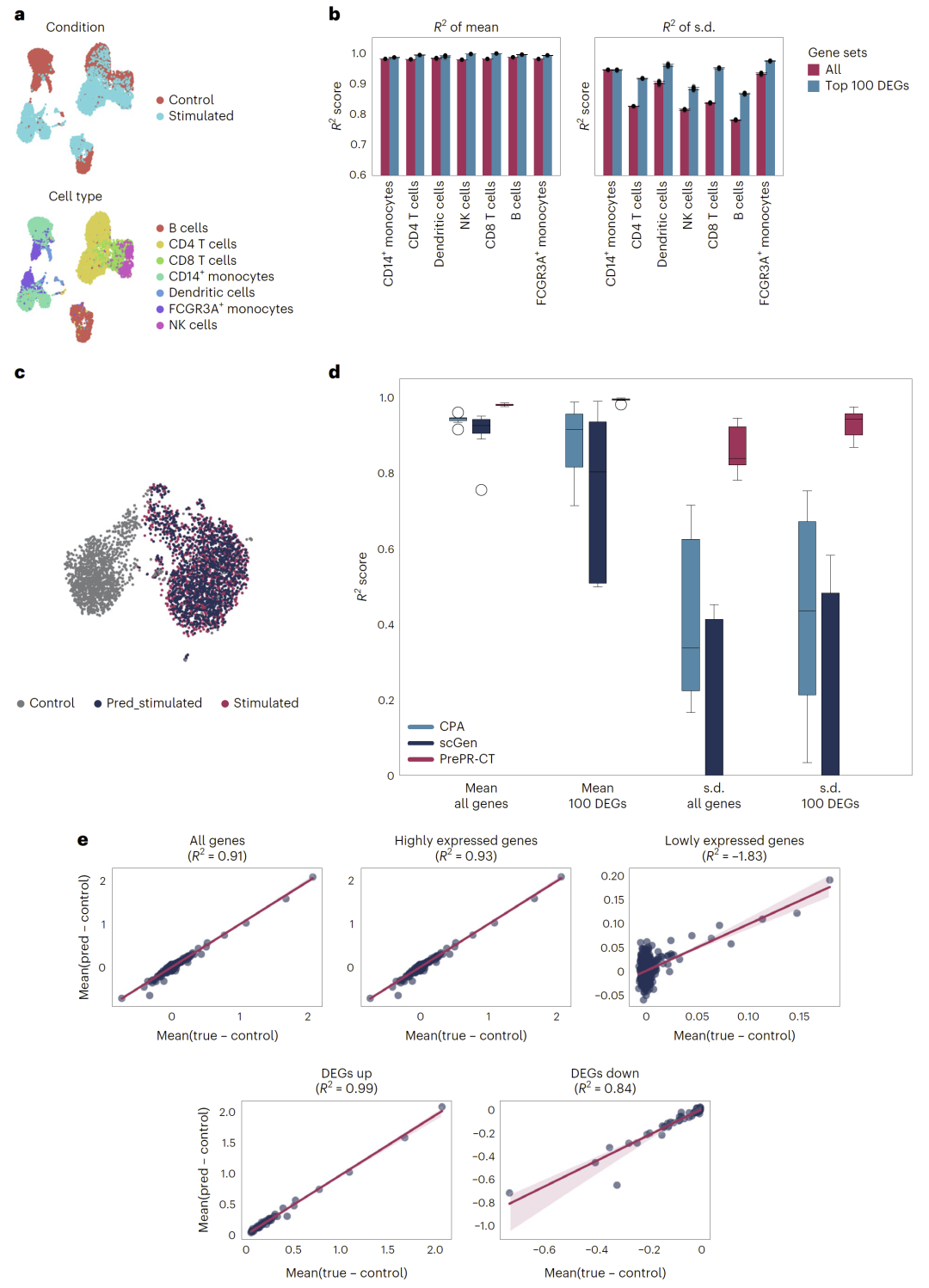
图2:PrePR-CT在未见过的细胞类型中准确预测单一扰动的影响。
细胞类型特异性预测
在多个细胞类型数据集上测试时,该模型能够准确区分不同细胞对同一药物的反应,说明归纳先验有助于学习细胞特异性的调控模式。
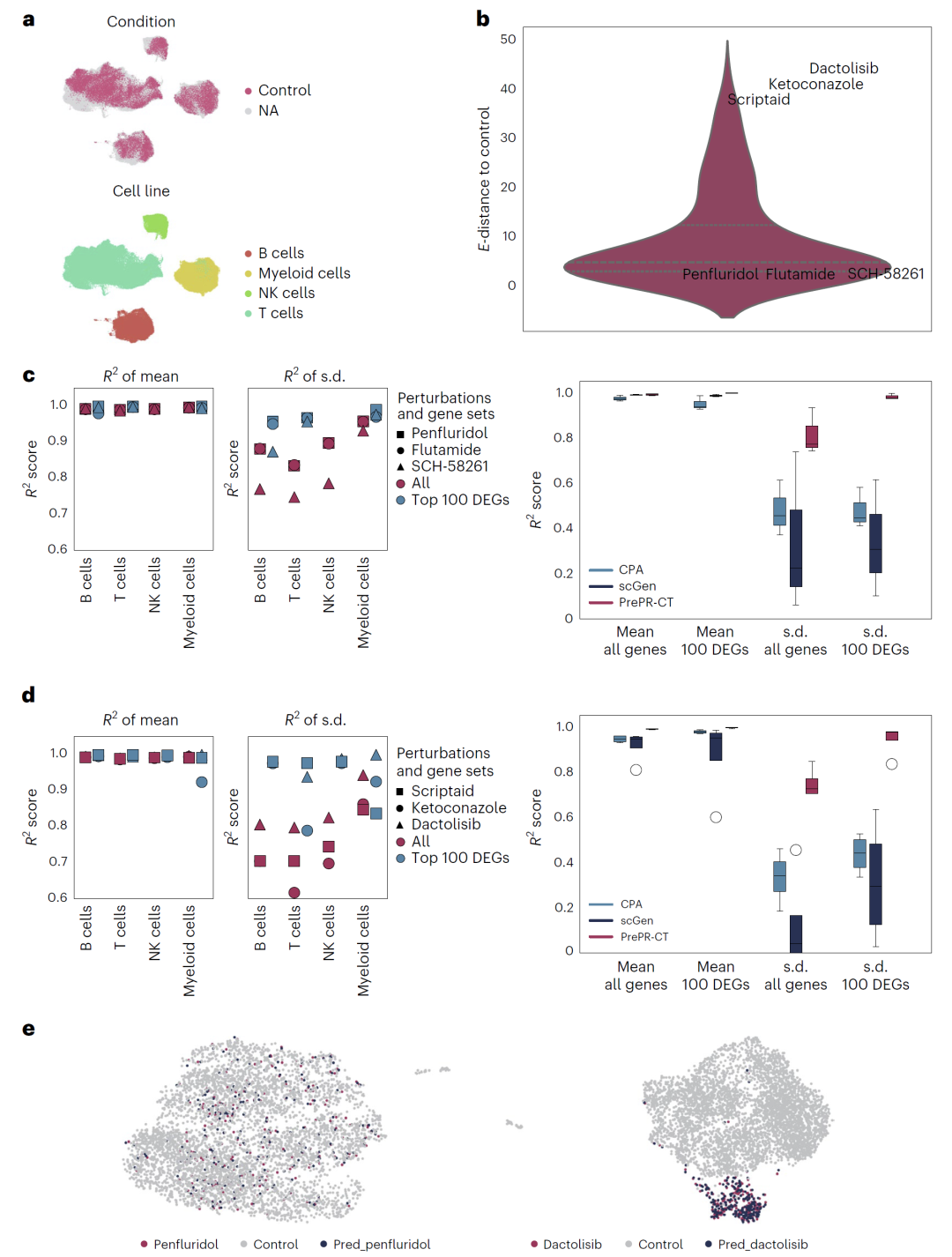
图3:PrePR-CT在未见过的细胞类型中准确预测多重扰动引起的转录响应。
模型可解释性分析
研究人员进一步分析模型的重要特征,发现模型能够识别与药物作用相关的关键基因和信号通路。这些结果与已知生物学机制一致,说明模型不仅具有预测能力,还具有解释能力。
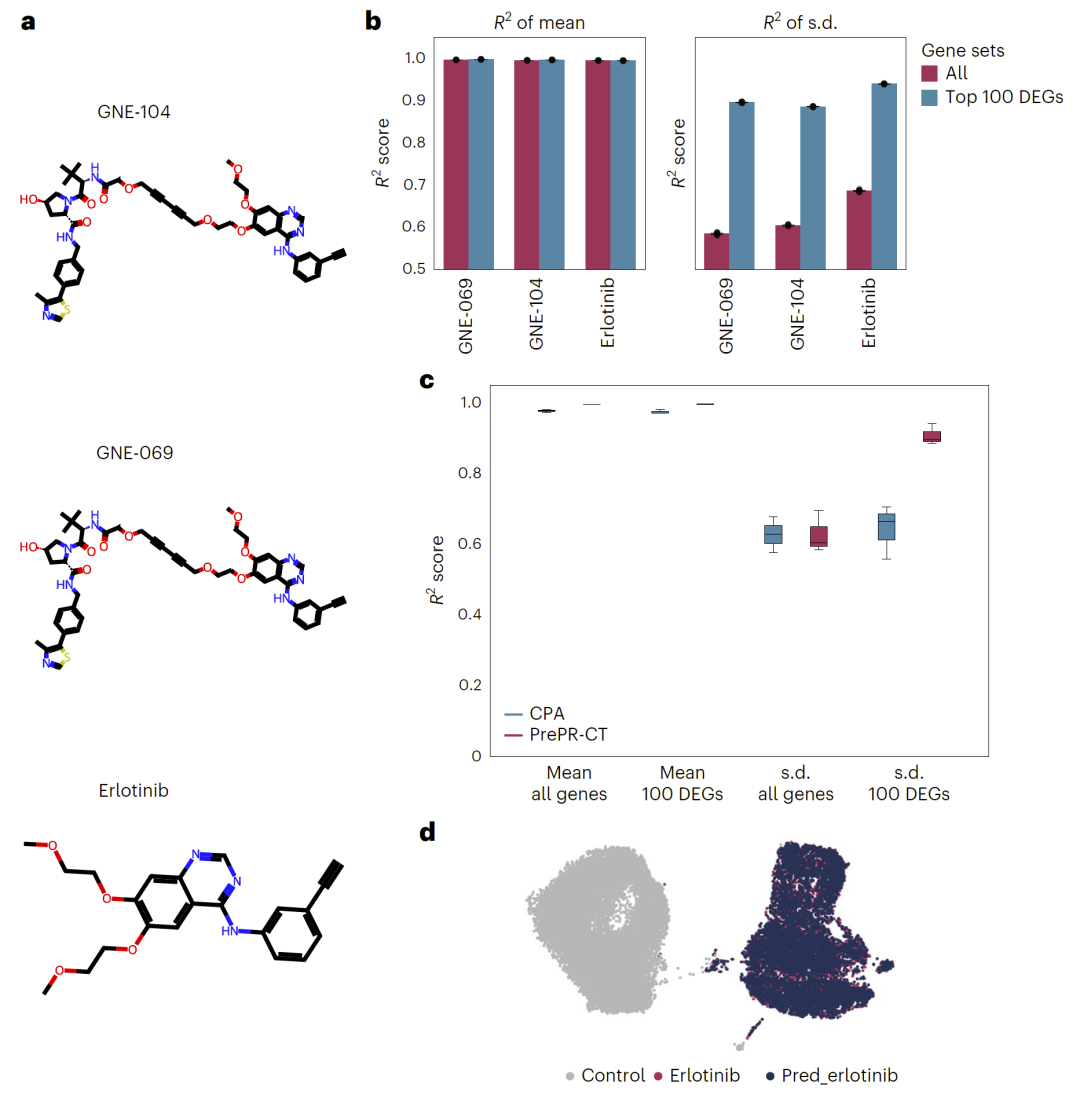
图4: PrePR-CT在相同细胞类型中准确预测未见过扰动的转录效应(Chang 数据集)。
不同数据规模下的泛化能力
随着训练数据减少,传统模型性能迅速下降,而该方法保持稳定,说明归纳先验能够有效提高样本效率。
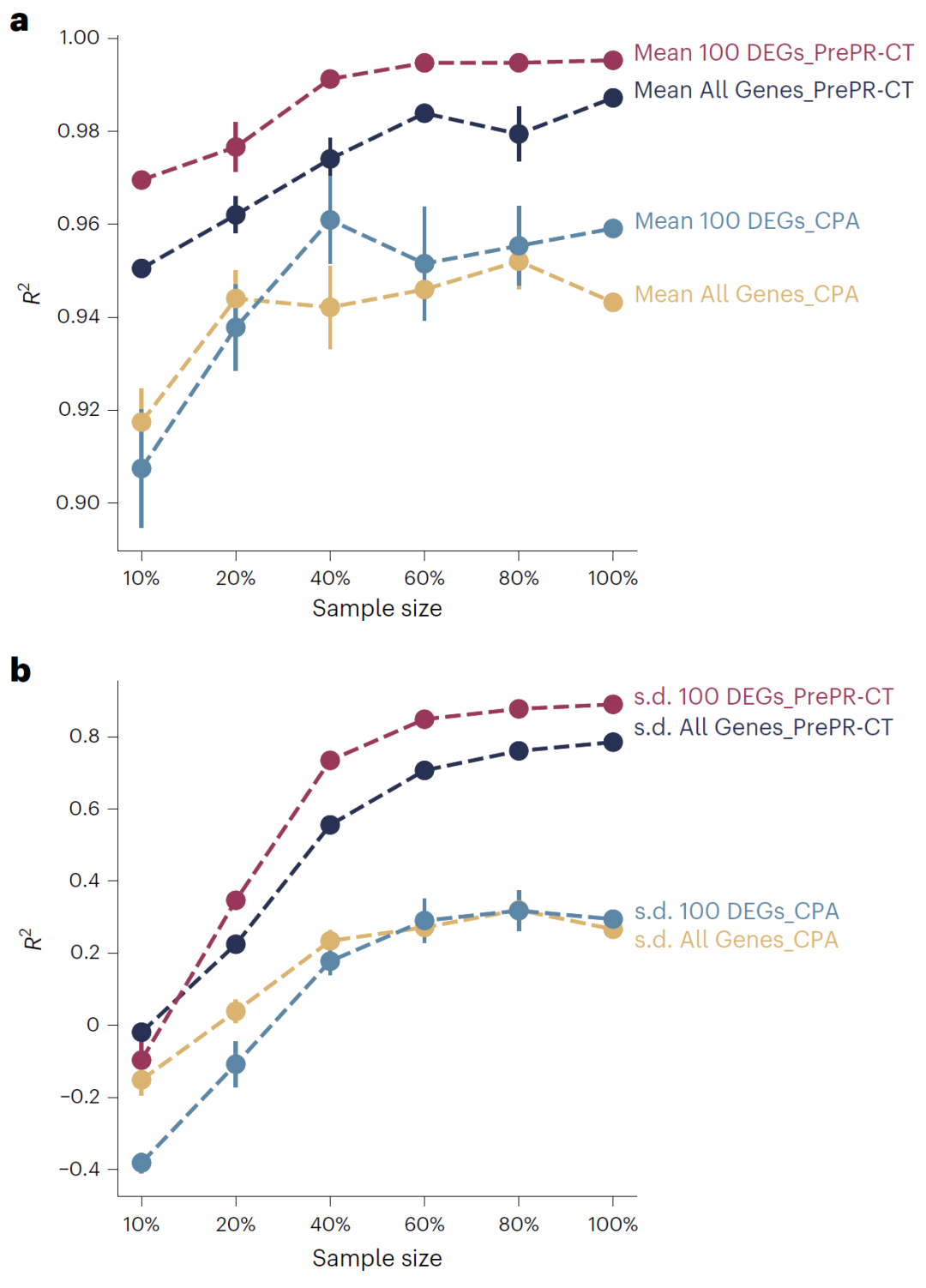
图5: PrePR-CT在小样本条件下仍能稳定工作。
跨数据集验证
在不同实验数据集之间进行训练和测试时,模型仍能保持较好表现,说明其具有较强的迁移能力。
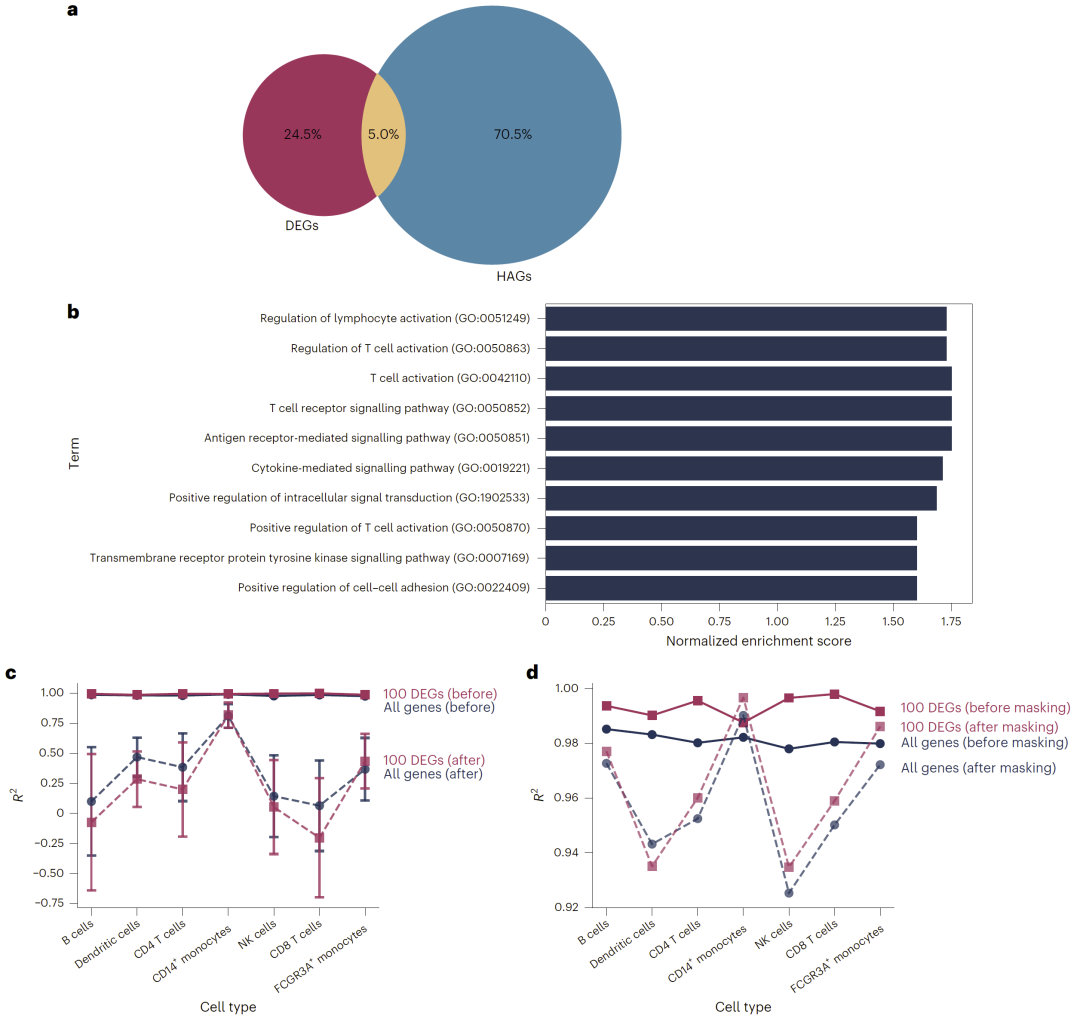
图6: HAG 分析结果。
讨论
本研究提出的归纳先验驱动模型为小样本条件下的药物反应预测提供了一种有效解决方案。通过在模型中引入生物学结构信息,研究人员能够在有限数据下训练稳定模型,并获得具有生物学意义的解释结果。
该方法特别适用于精准医学和个体化治疗,因为在这些场景中通常无法获得大量训练数据。相比纯数据驱动模型,归纳先验可以显著提高泛化能力,并减少过拟合风险。
研究人员认为,未来机器学习在生物医学中的应用将越来越依赖先验知识与数据驱动方法的结合。通过融合通路信息、基因调控网络以及多组学数据,可以进一步提高模型的预测能力和可解释性。
随着更多高质量生物学数据的积累,这类方法有望成为药物反应预测和机制解析的重要工具。
整理 | DrugOne团队
参考资料
Alsulami, R., Lehmann, R., Khan, S.A. et al. Predicting and interpreting cell-type-specific drug responses in the small-data regime using inductive priors. Nat Mach Intell (2026).
https://doi.org/10.1038/s42256-026-01202-2
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号