OpenFold3-preview2: 开源版AlphaFold3 再升级,实现跨分子类型的高精度结构预测

OpenFold3-preview2: 开源版AlphaFold3 再升级,实现跨分子类型的高精度结构预测

DrugOne
发布于 2026-03-25 16:35:45
发布于 2026-03-25 16:35:45
DRUGONE
研究人员介绍了 OpenFold3-preview2(OF3p2),这是 OpenFold3 通用生物分子结构预测系统的第二个预发布版本。与上一版本 OF3p 相比,OF3p2 在模型性能、训练流程和数据集构建方面均实现了显著改进,目前是学术界对 AlphaFold3 的最接近复现之一。该版本发布了更新的模型权重、推理与训练代码,以及完整的数据集,使得该系统成为目前唯一可以从零开始训练并达到接近 AlphaFold3 性能的开源实现。研究人员在本报告中给出了新的基准测试结果,并总结了相对于前一版本的改进。OpenFold3 项目的长期目标是构建一个在所有分子类型上都能够达到 AlphaFold3 性能水平的开源结构预测系统。
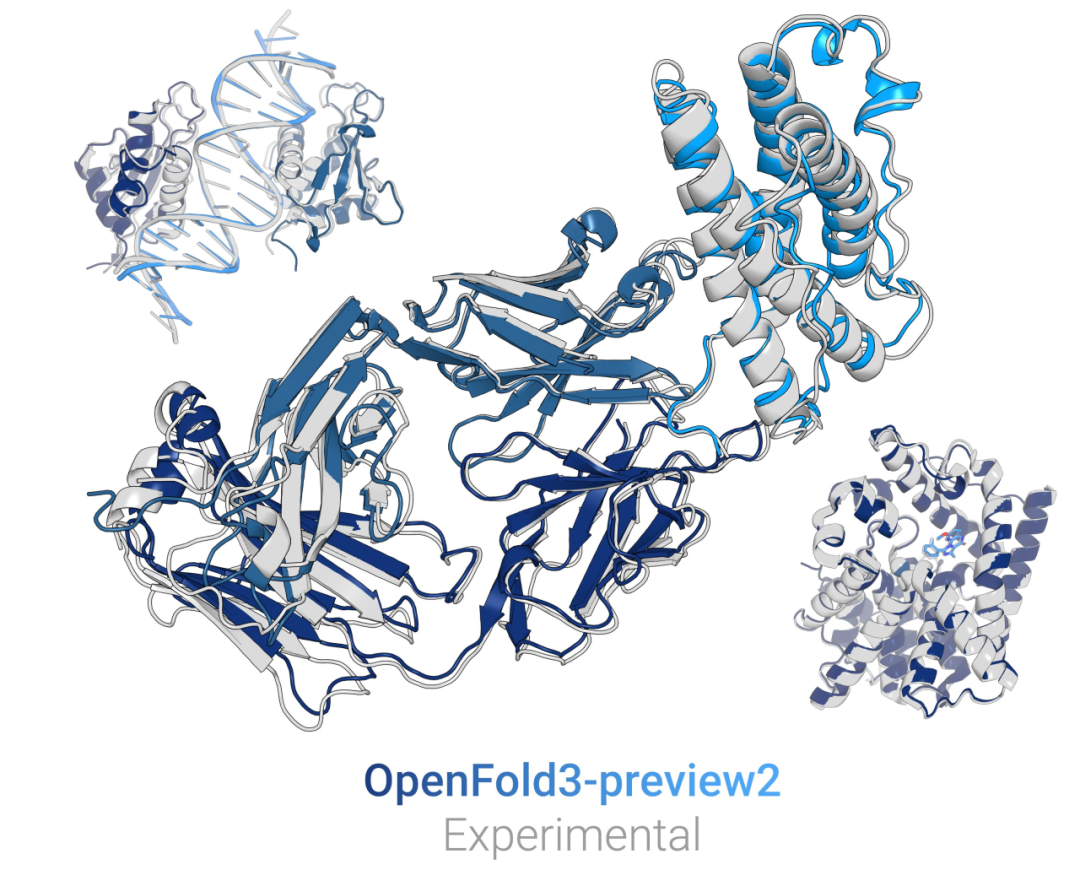
近年来,深度学习方法已经显著推动了蛋白质结构预测的发展,而 AlphaFold3 进一步扩展到多种生物分子类型,包括蛋白质、核酸、小分子和复合物。然而,由于 AlphaFold3 并未完全开源,学术界难以在其基础上进行可重复训练和方法扩展。因此,OpenFold3 项目的目标是构建一个完全开源且可训练的 AlphaFold3 级别模型,使研究人员能够在统一框架下研究不同分子模态的结构预测问题。OpenFold3-preview2 是该目标的重要阶段性成果。
方法概述
OF3p2 在数据集构建、模型训练和推理流程方面均遵循 AlphaFold3 的公开描述,并在多个关键环节进行了改进。研究人员重新构建了单体蒸馏数据集和 RNA 蒸馏数据集,并使用更大的序列数据库生成多序列比对信息,从而提高模型训练的稳定性和泛化能力。在训练过程中,模型总共进行了超过十五万步训练,并采用分阶段微调策略以提高最终性能。此外,研究人员修复了前一版本中的多个模板处理和置信度计算错误,从而显著提升预测稳定性。整个模型在大规模 GPU 集群上完成训练,并保持与 AlphaFold3 相似的超参数配置。
数据集更新
在新的单体蒸馏数据集中,研究人员使用最新版本的微生物和蛋白质数据库构建序列集合,并为每个序列生成多序列比对信息。随后使用结构预测模型生成候选结构,并根据置信度筛选高质量样本,以保证训练数据的可靠性。对于 RNA 数据集,研究人员采用新的 RNA 家族数据库并生成预测结构,然后根据结构质量进行筛选,最终得到高质量 RNA 蒸馏数据。
这些更新使得训练数据规模显著增加,同时保持了较高的结构准确度。
模型更新
OF3p2 在训练策略上进行了扩展,增加了训练步数,并在初始阶段同时训练置信度预测模块,以提高模型收敛稳定性。研究人员还修复了多个影响预测质量的实现错误,例如模板掩码错误、模板过滤缺失以及置信度计算不一致等问题。
此外,研究人员发现某些 RNA 数据在特定硬件后端上生成时会出现化学合理性下降的问题,因此重新生成了修正后的数据集并公开发布,以保证训练数据的一致性。
结果
蛋白-小分子复合物预测
研究人员在蛋白-小分子复合物基准测试上评估了 OF3p2,并与多个最新模型进行了比较。结果表明,OF3p2 在大多数相似度区间上的表现与当前最佳开源模型接近,并进一步缩小了与 AlphaFold3 的差距。分析表明,OF3p2 的生成能力已经能够产生高质量结构,但在基于置信度的排序阶段仍可能无法选择最佳结果。
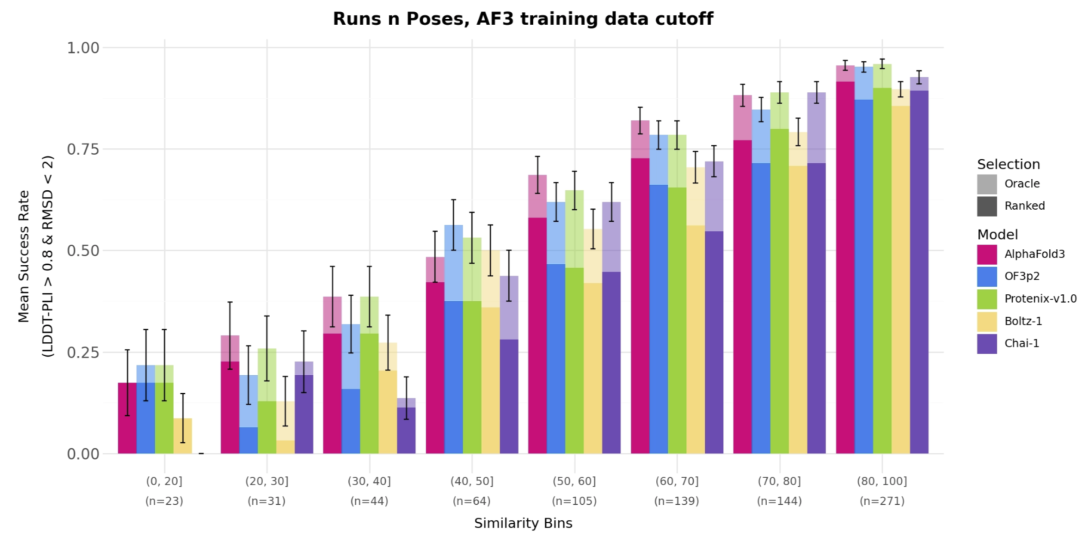
图1. OF3p2 与其他模型在 Runs N’ Poses 蛋白-配体复合物数据集上的性能比较,结果按与训练数据的相似度(SuCOS-pocket)分组统计,评估对象为相对于 AF3 训练时间截断后保留的结构。
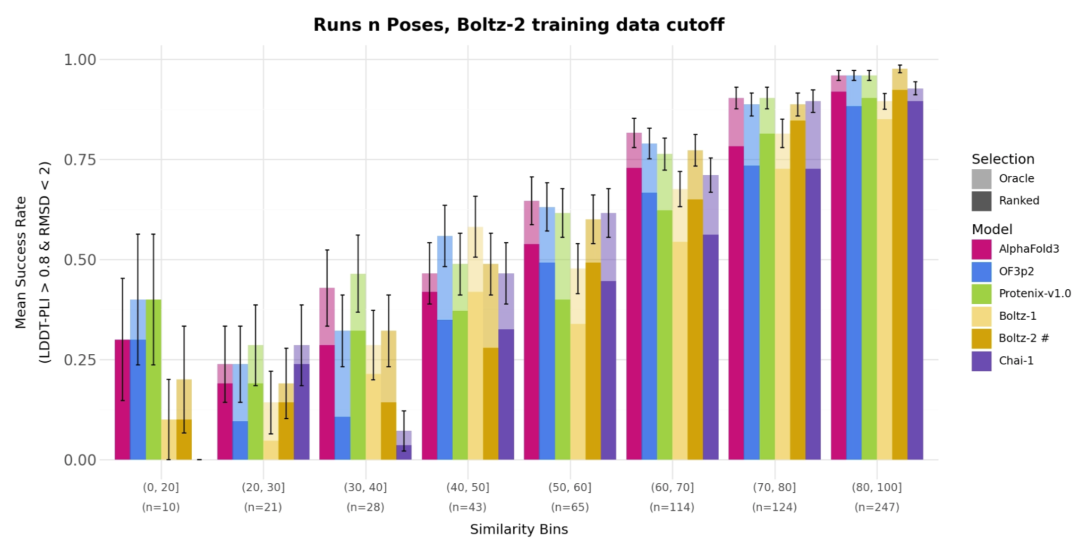
图2. OF3p2 与其他模型在 Runs N’ Poses 蛋白-配体复合物数据集上的性能比较,结果按与训练数据的相似度(SuCOS-pocket)分组统计。
生物复合物预测
在单体和多体结构预测基准中,OF3p2 在蛋白质、DNA、RNA 以及蛋白-蛋白、蛋白-核酸复合物等多种模态上进行了评估。结果显示,OF3p2 的整体性能与 AlphaFold3 和其他开源复现模型相当,在某些任务上略低,而在其他任务上则达到相同甚至更高水平,差异主要在统计波动范围内。
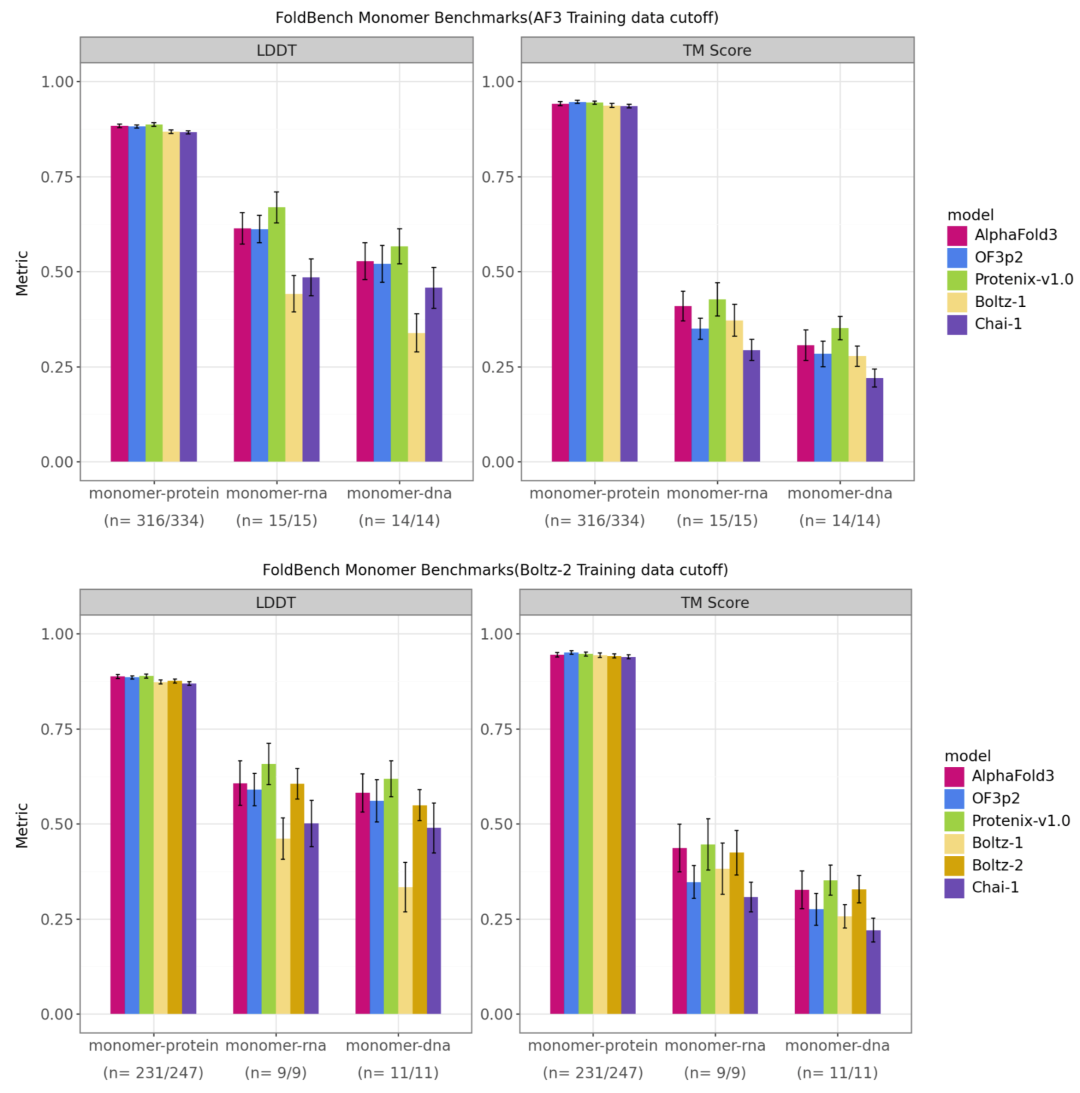
图3. FoldBench 基准测试中单体分子模态的模型性能比较。上图为相对于 AF3 训练时间截断保留的数据,下图为相对于 Boltz-2 训练时间截断保留的数据。每种模态下方标注为所有模型均成功预测的目标数量与总目标数量。
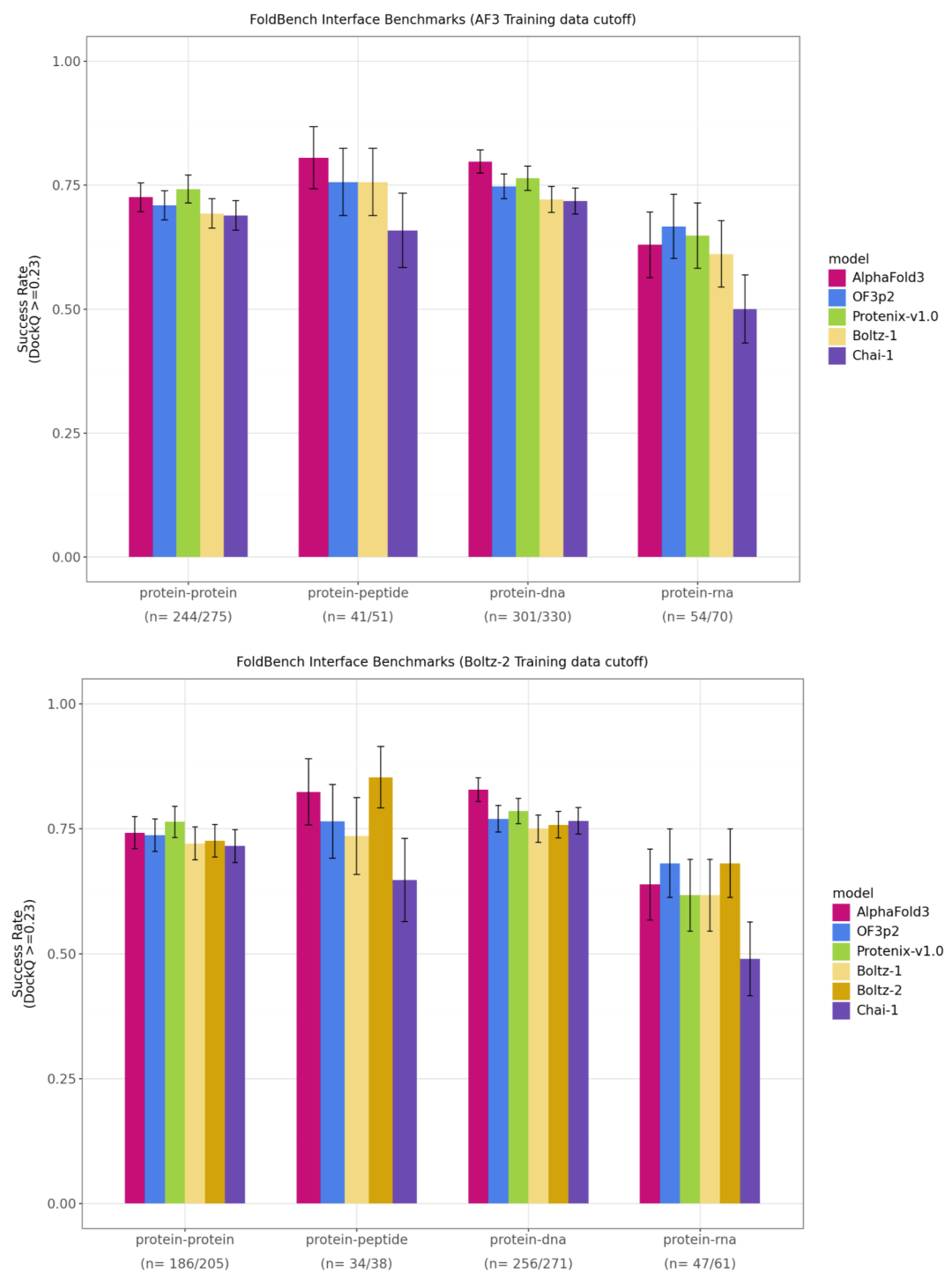
图4. FoldBench 基准测试中多体分子模态的模型性能比较。上图为 AF3 训练时间截断之后的保留子集,下图为 Boltz-2 训练时间截断之后的保留子集。每种模态下方标注为所有模型均成功预测的目标数量与总目标数量。由于作者未提供结果,Protenix-v1 的蛋白-肽复合物性能未显示。
抗体-抗原复合物预测
研究人员使用 AlphaFold3 论文中的测试集评估抗体-抗原复合物预测性能。通过增加多序列比对采样数量,可以观察到模型性能随采样数增加而提升。OF3p2 的性能随采样数增长呈现明显提升趋势,但增长速度仍略低于 AlphaFold3。结果表明,OF3p2 已显著缩小与官方模型之间的差距,但在高采样情况下仍存在性能差异。
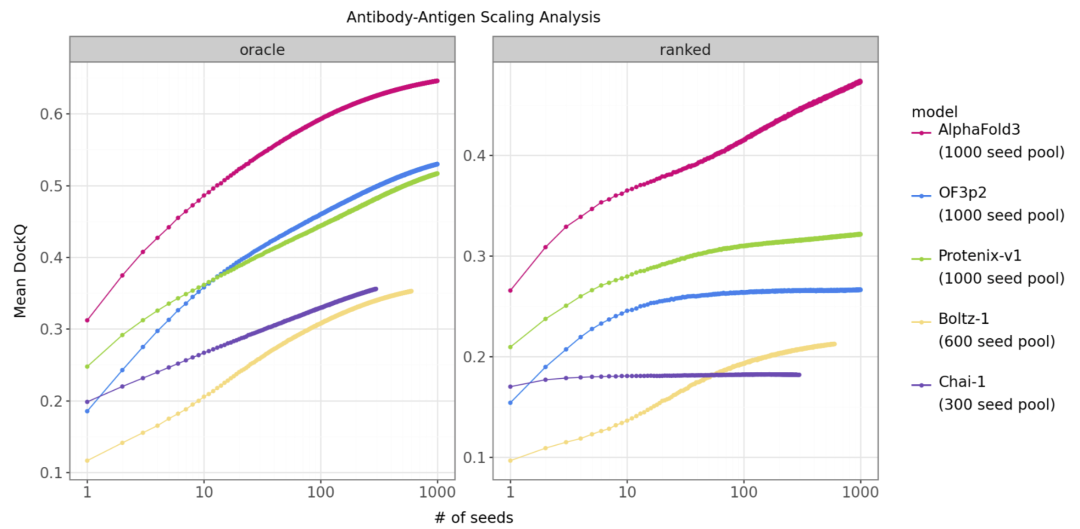
图5. 在 Google DeepMind 抗体-抗原测试集上,DockQ 平均值随 MSA 种子数量变化的关系。
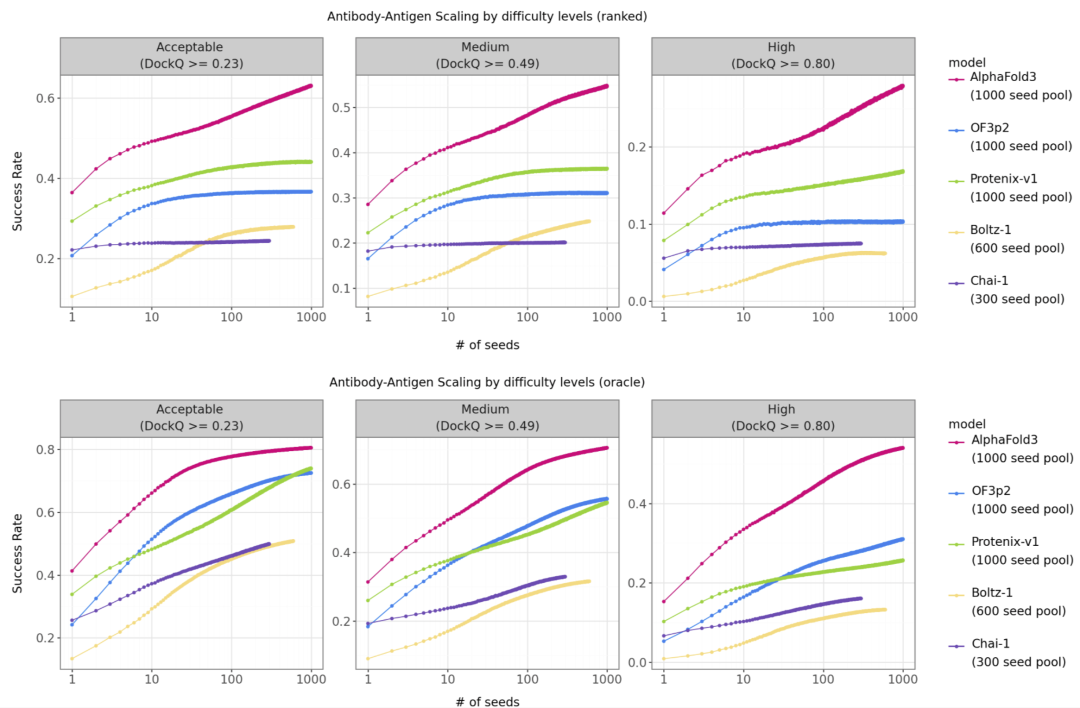
图6. 在 Google DeepMind 抗体-抗原测试集上,不同 DockQ 分类下成功率随 MSA 种子数量变化的关系。成功率按照 AF3 的定义计算,即 DockQ 值高于或等于对应分类阈值的界面比例。
讨论
总体而言,OF3p2 相比前一版本取得了显著进步,并在多个基准测试中超过大多数 AlphaFold3 复现模型,仅次于最新发布的部分高性能实现。研究人员发现,即使某些模型使用更新的数据集,OF3p2 仍能保持竞争力,说明模型架构和训练策略同样重要。当前仍没有任何开源复现能够在所有分子模态上完全达到 AlphaFold3 的性能水平,而 OF3p2 被认为是实现这一目标的重要一步。通过公开模型权重、训练代码和完整数据集,研究人员希望推动社区进一步改进结构预测模型,并最终实现全面超越 AlphaFold3 的开源系统。
整理 | DrugOne团队
参考资料
- https://portal.openfold.omsf.io/reports/of3p2_technical_report.pdf
- https://github.com/aqlaboratory/openfold-3
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号