Nat. Commun. | 一种用于精确刻画蛋白质互作的新型语言模型

Nat. Commun. | 一种用于精确刻画蛋白质互作的新型语言模型

DrugOne
发布于 2026-03-25 16:33:49
发布于 2026-03-25 16:33:49
蛋白质是名副其实的生命发动机。但这台发动机并非单打独斗,细胞内的绝大多数工作,都需要蛋白质们“携手合作”才能完成。从免疫系统精准识别敌人,到细胞内部传递生长信号,背后都离不开蛋白质之间精准而动态的“握手”与“对话”。因此,如何利用人工智能,仅从蛋白质的序列信息,就判断出它们是否会“握手”(互作)、握得有多紧(结合强度),以及在哪里“握手”(互作界面),就成了解码生命奥秘的关键一环。
近日,新加坡国立大学张阳教授团队在《Nature Communications》发表研究,提出了一种蛋白质对语言模型(Protein Pair Language Model, PPLM),能够直接从蛋白质序列对中学习蛋白质之间的互作关系,而不再局限于传统蛋白语言模型对单条蛋白链的表征学习。在此基础上,研究团队进一步开发了PPLM-PPI、PPLM-Affinity和PPLM-Contact三个下游方法,分别用于蛋白质互作预测、蛋白质结合亲和力预测以及界面接触预测。实验结果表明,PPLM在这三类核心任务上均显著优于现有方法,展示了蛋白质对基础语言模型在互作建模中的巨大潜力。

研究背景
近年来,大规模蛋白语言模型(protein language models, PLMs)快速发展。以ESM、ProtBERT等为代表的模型,已经在蛋白质结构预测、功能注释、突变效应分析和蛋白设计等方向发挥了重要作用。它们的成功说明:通过大规模序列预训练,AI能够学到大量与蛋白质生物学相关的规律。然而,这些模型几乎都有一个共同前提:预训练对象是单条蛋白序列。也就是说,它们更擅长回答“一个蛋白是什么”、“这个蛋白可能折叠成什么样”、“这个蛋白可能具有什么功能”,却并不擅长直接回答“两个蛋白之间会发生什么”。
这一区别看似细微,实际上非常关键。因为蛋白质互作问题天然是“关系型”的:研究对象不再是一个单体,而是一对蛋白及其之间的耦合关系。两个蛋白是否能结合、结合强度如何、界面位点在哪里,这些问题都依赖于跨链信息,而不是单条链内部的信息。传统PLMs也常被用于PPI(protein-protein interaction, 蛋白质相互作用)任务,但通常采用两种策略:一是分别编码两个蛋白序列后再拼接;二是直接将两条序列拼成一条“长链”输入模型。这两种做法虽然有一定效果,但本质上都是在“单链语言”的框架下处理“关系型问题”——模型在预训练阶段从未真正学习过蛋白质对的互作模式。
方法简介
为解决这一问题,张阳团队提出了蛋白质对语言模型PPLM。与传统单体蛋白语言模型不同,PPLM的输入不再是一条蛋白序列,而是蛋白序列对。PPLM的核心创新,在于引入了专门面向蛋白对的混合型注意力机制——含“链内注意力”和“链间注意力”两个通道。其中,链内注意力用于建模单个蛋白内部残基之间的关系,并保留序列顺序信息;链间注意力则专门用于建模两个蛋白之间的跨链联系,避免将蛋白对简单视为一条更长的单链来处理。与此同时,模型还引入了可学习的链间注意力权重和显式链间残基对掩码,进一步增强对跨链互作信号的捕捉能力。这一设计的关键思想在于,蛋白质内部相互作用和蛋白质之间相互作用并不是同一种关系。PPLM不是把“蛋白对”当作“更长的单链”处理,而是通过结构化注意力机制,让模型在预训练阶段就学会区分并协调这两类关系,从而形成真正的“互作感知表示”。
在此基础上,作者进一步开发了三个任务模型。首先,在PPI预测中,PPLM输出的序列表示以及链内、链间注意力特征会经过并行池化和聚合,再通过多层感知机进行集成预测,从而判断两个蛋白是否发生相互作用。其次,在结合亲和力预测中,对PPLM的最后一层进行微调,并将受体与配体的全序列表示进行池化后输入线性层,以预测蛋白质之间的结合强度。最后,在界面接触预测中,PPLM生成的链间注意力矩阵会进一步与MSA特征和单体距离图结合,通过专门设计的Inter-protein Transformer网络,预测残基接触图并识别界面残基。
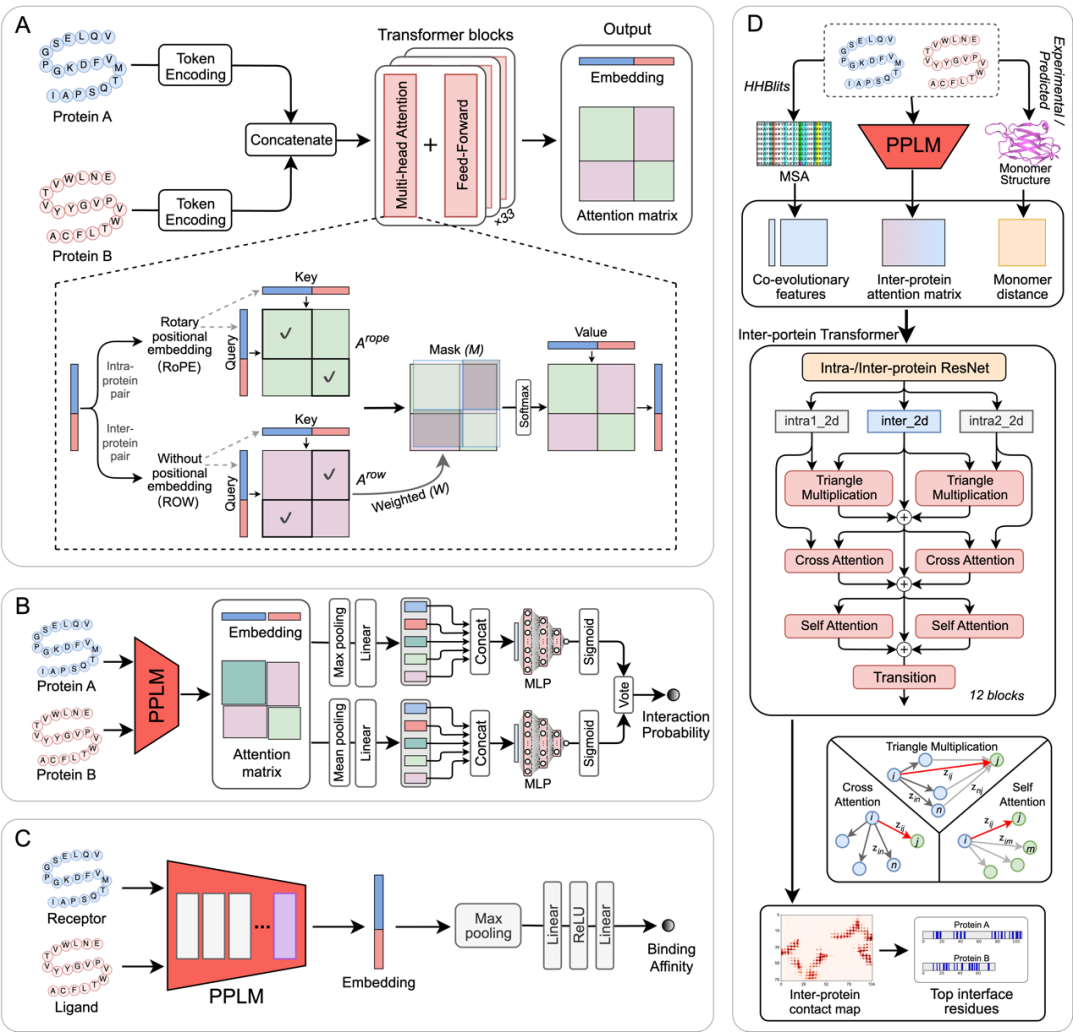
图1. PPLM的整体框架及其下游应用。
结果分析
PPLM在语言建模层面展现出对蛋白对更强的理解能力
为了评估PPLM是否真正学到了蛋白对层面的表示,作者首先从最基础的语言建模能力出发,比较了PPLM与单序列语言模型ESM2在蛋白序列对上的表现。结果显示,在同源二聚体、异源二聚体以及STRING来源的蛋白对数据上,PPLM的perplexity均显著低于ESM2,说明其对蛋白对序列中氨基酸分布规律的建模更加准确。更重要的是,当作者对真实界面残基进行masking时,PPLM相比ESM2仍然表现出明显优势,表明PPLM对蛋白质界面区域的残基依赖关系更敏感,也更擅长捕捉与相互作用直接相关的局部上下文信息。进一步的案例分析还显示,PPLM最后一层的链间注意力已经能够在无监督条件下自然聚焦到真实接触区域。这说明,PPLM在预训练阶段学到的并不仅仅是一般性的序列统计规律,而是包含了与蛋白互作相关的生物学信息。
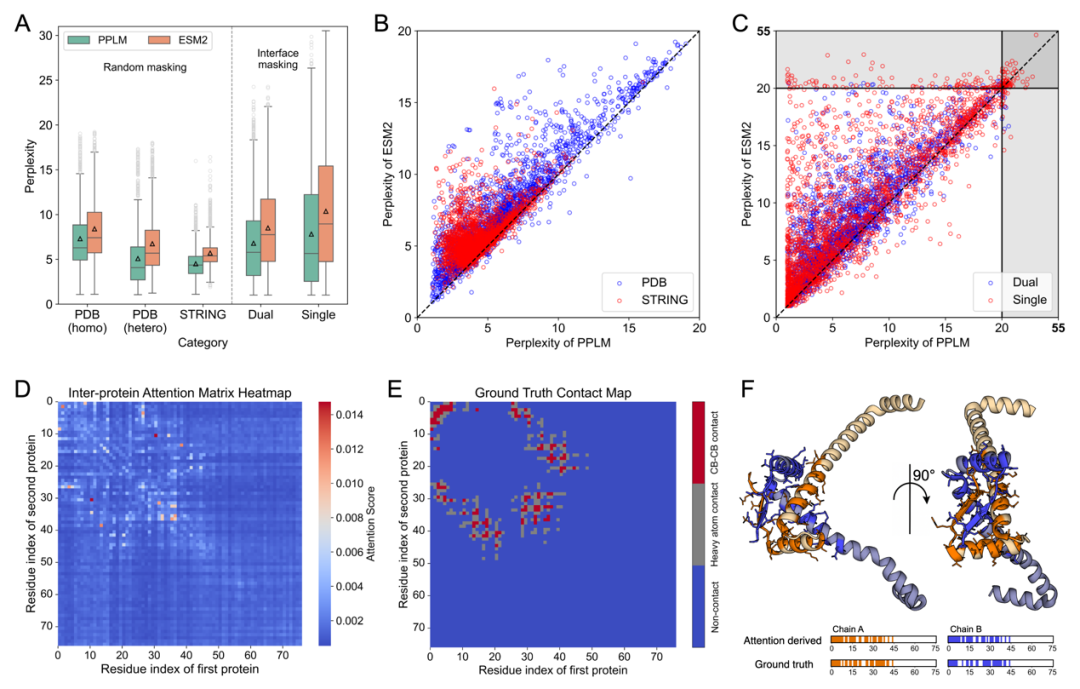
图2. PPLM与ESM2在蛋白质序列对上的Perplexity比较。
PPLM-PPI在多物种蛋白互作预测中表现优异
在蛋白质互作预测任务中,PPLM-PPI在五个物种测试集上均优于TUnA、ESMDNN-PPI、D-SCRIPT和Topsy-Turvy等现有方法,整体表现稳定且领先。在更适合不平衡数据集的AUPRC指标上,PPLM-PPI在五个物种上分别达到0.920、0.906、0.883、0.745和0.784,均为最佳结果。表明PPLM学到的蛋白对表示不仅适用于训练分布内样本,也能够较好地泛化到不同物种的蛋白互作预测任务中。对于大规模PPI网络构建、未知蛋白功能注释以及基于序列的人类蛋白互作图谱预测,这种泛化能力具有重要意义。
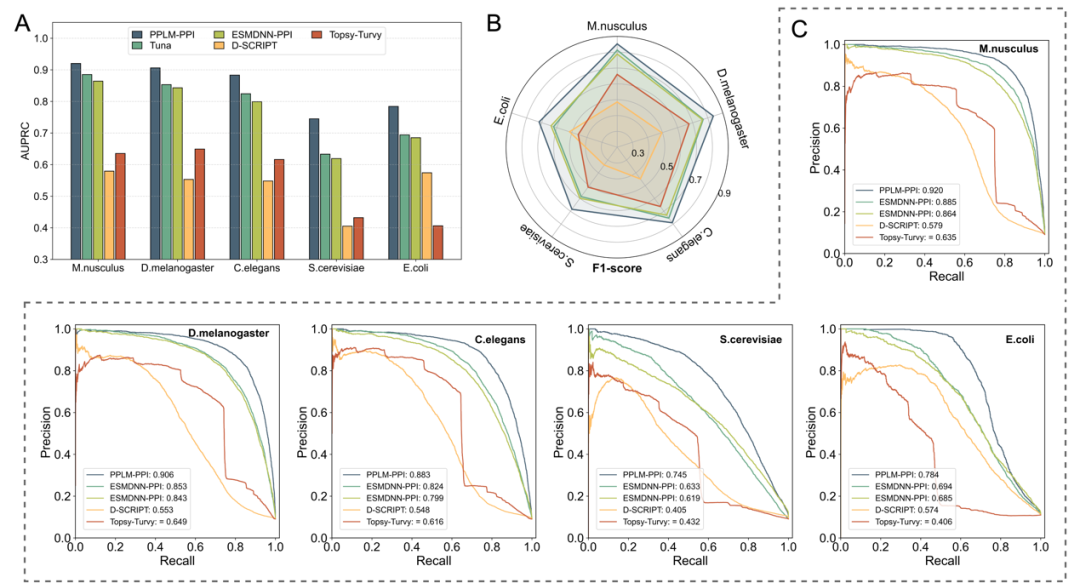
图3. PPLM-PPI在相互作用预测任务中的性能。
PPLM-Affinity能够更准确捕捉蛋白之间的结合强度
在结合亲和力预测任务中,PPLM-Affinity的整体表现优于单序列基线ESM2-Affinity,也优于结构方法PPB-Affinity。其Pearson相关系数和Spearman相关系数分别达到0.643 ± 0.058 和0.636 ± 0.082,显示出较强的连续值建模能力。尤其值得注意的是,在更具挑战性的Antibody–antigen和TCR–pMHC两类免疫相关复合物上,PPLM-Affinity依然保持明显优势。这说明,PPLM学到的蛋白对表示不仅能判断“两个蛋白是否会结合”,还能够进一步反映结合强弱这一更细粒度的性质。对于抗体工程、TCR优化以及治疗性蛋白设计等方向而言,这一点具有直接应用价值。
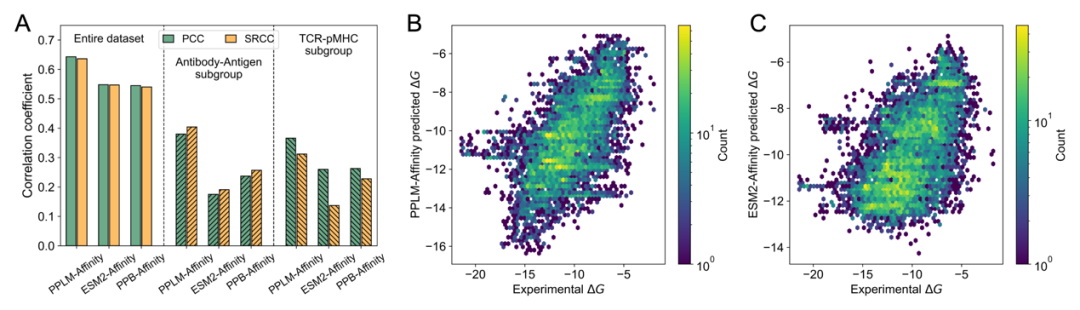
图4. PPLM-Affinity在亲和力预测任务中的性能。
PPLM-Contact在界面接触和界面识别上均表现突出
在更细粒度的界面建模任务中,PPLM-Contact在同源二聚体和异源二聚体测试集上均显著优于DeepInter、CDPred、GLINTER等现有方法,表明PPLM学到的互作表示能够有效提升界面接触预测的准确性。消融实验进一步说明,PPLM的链间注意力特征本身对接触预测具有重要贡献;当移除PPLM特征、MSA特征或单体距离图时,模型性能都会明显下降。以人类 RASEF 蛋白的 EF-hand 结构域为例,如果只依赖MSA和单体结构而不使用PPLM 特征,模型预测效果很差;而仅使用PPLM特征时,已经能够恢复大部分真实接触,显示出PPLM在界面几何模式和跨链空间关系建模上的独特价值。这些结果表明,即使在已经结合MSA和单体结构信息的场景下,PPLM仍然能够提供额外增益,说明它捕捉到的不是对已有特征的简单重复,而是更直接面向蛋白互作的补充信息。
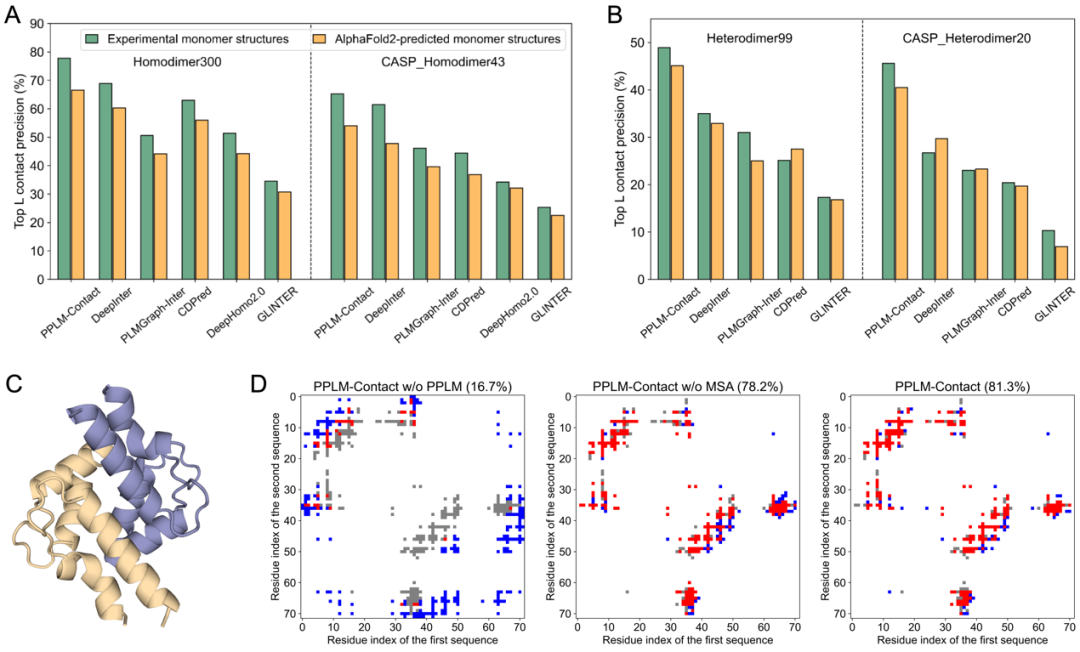
图5. PPLM-Contact在界面接触预测任务中的性能。
在此基础上,作者进一步提出了增强版PPLM-Contact2,在PPLM-Contact基础上进一步引入了从预测复合物结构中提取的链间距离图。结果显示,在引入复合物结构预测得到的链间距离图后,模型性能进一步显著提升:在同源二聚体和异源二聚体上的Top-L接触预测精度分别从65.0%提升到85.1%,以及从44.3%提升到88.0%。更重要的是,PPLM-Contact2的整体表现还超过了AlphaFold2.3、AlphaFold3和DMFold等先进复合物结构预测方法。PPLM-Contact2的成功表明,语言模型与结构模型不是替代关系,而是互补关系:前者擅长从大规模序列对中学习互作统计规律,后者擅长提供几何和空间约束,二者结合后能够得到更高质量的界面信息。
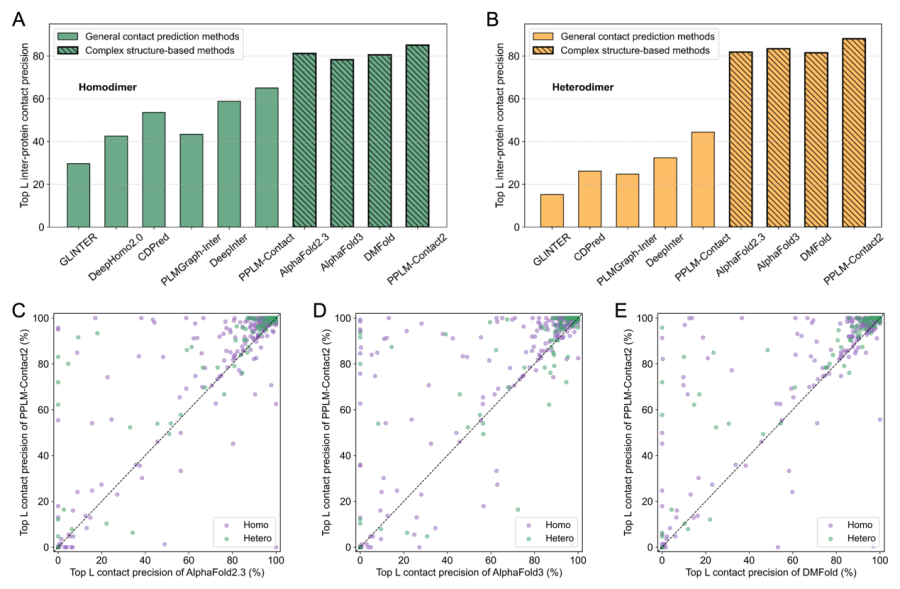
图6. PPLM-Contact2在界面接触预测任务中的性能。
除了接触图预测,作者还系统评估了不同方法在界面残基识别上的能力。结果显示,PPLM-Contact在常规接触预测方法中取得最高识别精度,而结合复合物结构特征后的PPLM-Contact2则在同源和异源二聚体上进一步达到最佳表现。在DNMT3A–DNMT3L复合物上的案例分析显示,PPLM-Contact能够更准确识别出真实界面残基。
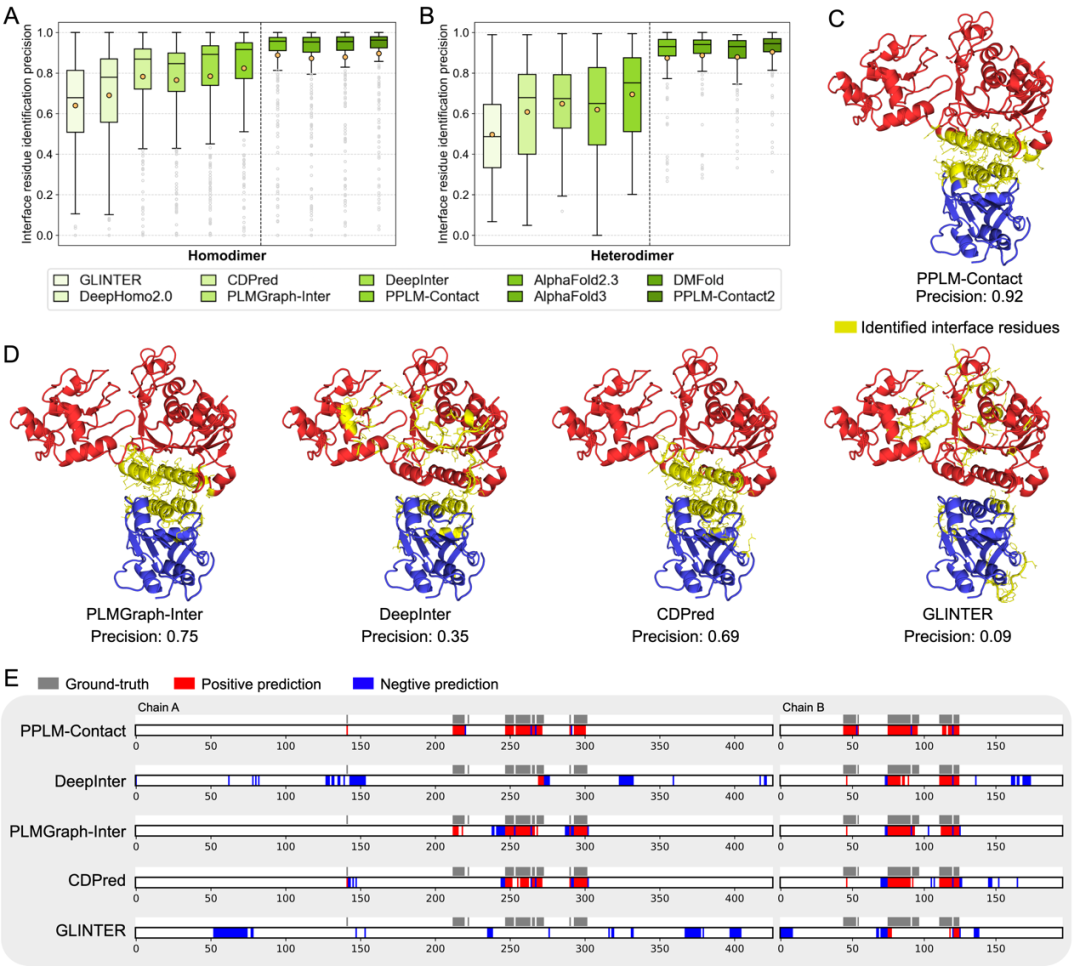
图7. PPLM-Contact在界面残基识别上的性能。
这些结果共同说明,PPLM不仅能够判断两个蛋白“会不会结合”,还能够更准确地定位“具体哪里在结合”。同时,PPLM-Contact2的成功也表明,语言模型与结构模型并不是替代关系,而是互补关系:前者擅长从大规模序列对中学习互作规律,后者提供几何和空间约束,二者结合后能够得到更高质量的界面信息。
研究意义
这项工作最值得关注的地方,并不仅仅是它在若干蛋白质相互作用任务上超过了现有方法,而是它提出了一种新的基础模型范式:推动蛋白语言模型从“单体蛋白建模”走向“蛋白互作建模”,从而迈向蛋白互作基础模型。过去的蛋白语言模型,本质上是在学习“单体蛋白语言”;而PPLM则更进一步,尝试学习“蛋白互作语言”。在这个框架中,模型在预训练阶段就开始理解:哪些跨链关系更可能对应真实界面、哪些残基耦合模式更可能支持稳定结合、哪些蛋白对关系可能对应不同的生物学功能。这样得到的表示天然适合用于互作、亲和力和界面预测,而不必完全依赖下游任务再去补学这些信息。
局限与展望
尽管PPLM已使用大规模复合训练集进行训练,但仍可能无法完全覆盖不同物种、不同细胞状态和不同生物学条件下复杂多样的蛋白互作,尤其是瞬时的、弱结合的、条件依赖的相互作用。正因为如此,PPLM框架仍具有很大的扩展空间。未来可以考虑:(1)融合更大规模、更高质量的蛋白对训练集;(2)与AlphaFold3等复合物结构预测工具更深层结合;(3)将更多功能标签引入预训练或多任务微调中;(4)拓展到抗体-抗原识别、TCR识别、界面设计和治疗性蛋白优化等任务。尤其是PPLM-Affinity在antibody–antigen和TCR–pMHC 体系上的结果,提示这一框架在抗体工程、TCR优化、CDR建模等方向可能具有重要潜力。
-----------------------------------------------------
本论文的第一作者为新加坡国立大学癌症科学研究所刘俊博士,通讯作者为新加坡国立大学张阳教授。论文同时提供了PPLM在线服务器和源代码,可用于蛋白互作预测、结合亲和力预测和界面接触预测等任务。
论文链接:https://www.nature.com/articles/s41467-026-70457-5
在线服务器:https://zhanggroup.org/PPLM/
源代码链接:https://github.com/junliu621/PPLM
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号