Nat. Commun. | 基于多表示图神经网络的基因组抗菌耐药性预测框架

Nat. Commun. | 基于多表示图神经网络的基因组抗菌耐药性预测框架

DrugOne
发布于 2026-03-25 16:22:50
发布于 2026-03-25 16:22:50
DRUGONE
全基因组测序(WGS)数据为解析抗菌药物耐药性(AMR)的分子机制提供了重要资源。然而,这类数据具有高维度特征,并且缺乏统一的基因组表示方式,这成为利用机器学习预测耐药表型的重要障碍。为充分利用这些高分辨率数据,研究人员提出AMR-GNN,一种基于图深度学习的框架,通过整合多种基因组表示并结合图神经网络,实现从基因组序列预测抗菌药物耐药表型。
研究人员以铜绿假单胞菌作为示例进行验证,该病原体是一种具有复杂耐药机制的重要临床革兰阴性菌。AMR-GNN被设计为一个概念验证框架,旨在解决当前基于数据驱动机器学习进行AMR表型预测的多个关键问题,包括通过多种基因组表示提升预测性能、减少菌株克隆关系带来的偏差,以及识别关键生物标志物以提高模型可解释性。进一步在一个包含多种革兰阴性和革兰阳性病原体的大型公开数据集上验证表明,该方法在多种病原体和药物组合中均具有良好的泛化能力。

抗菌药物耐药性是全球公共卫生的重要威胁。快速而准确地检测病原体的耐药表型对于改善患者治疗效果、减少不必要的抗生素使用以及控制医院内耐药菌传播至关重要。传统的培养和药敏试验方法通常需要数天时间才能得到结果,这种延迟限制了临床及时决策和感染控制措施的实施。
全基因组测序为检测耐药性提供了一种有前景的替代方案。细菌基因组相对较小,使得WGS技术在临床微生物学实验室中逐渐普及。随着生物信息学技术的发展,WGS数据不仅可以用于病原体鉴定,还可以用于耐药性检测。然而,目前大多数方法仍依赖规则或基因检测策略,这些方法在耐药性由单一基因决定时表现良好,但在存在复杂基因互作或遗传异质性的情况下效果有限。
近年来,机器学习方法被广泛用于耐药性预测,因为它能够捕捉复杂的遗传关系,并在模型训练完成后快速预测多种抗生素的耐药表型。然而,细菌基因组包含数百万个核苷酸序列,其表示方式多种多样,目前尚未形成统一的最佳表示方法。例如,SNP表示可以识别相对于参考基因组的变异,而泛基因组分析可以揭示群体中存在的变异基因。如何有效整合这些不同表示方式仍然是一个重要挑战。
图神经网络为解决这一问题提供了新的可能性。其结构允许通过节点特征和边特征整合不同类型的数据,并通过样本之间的相似性网络传播信息。这一特性非常适合AMR预测,因为具有相似基因组特征的菌株往往具有相似的耐药表型。基于这一思路,研究人员开发了AMR-GNN框架,将多种基因组特征整合到统一的图神经网络模型中,以提升AMR预测性能。
方法概述
研究人员构建了一个包含全基因组测序数据和药敏实验结果的大型数据集,其中包括来自研究中心及多个公开数据库的铜绿假单胞菌基因组数据。最终数据集包含2515个菌株,覆盖多种序列型和12种常见抗假单胞菌抗生素。根据EUCAST标准,将最小抑菌浓度数据转化为“敏感”或“耐药”两类标签。
在模型设计中,每个菌株被视为图中的一个节点,其节点特征由基因组特征向量表示。研究人员首先评估了多种单一基因组表示方式,包括unitig、SNP和频率混沌游戏表示(FCGR)。随后选择性能最好的表示方式作为节点特征,并利用其他表示方式构建样本之间的相似性网络,从而形成图结构。
模型采用双分支图卷积网络结构,每个分支利用不同的邻接矩阵学习菌株之间的关系,并通过低秩多模态融合方法整合两个分支的表示向量,从而生成统一的嵌入表示用于预测耐药表型。此外,研究人员还通过移除同一MLST克隆群体之间的连接来减少群体结构带来的偏差。
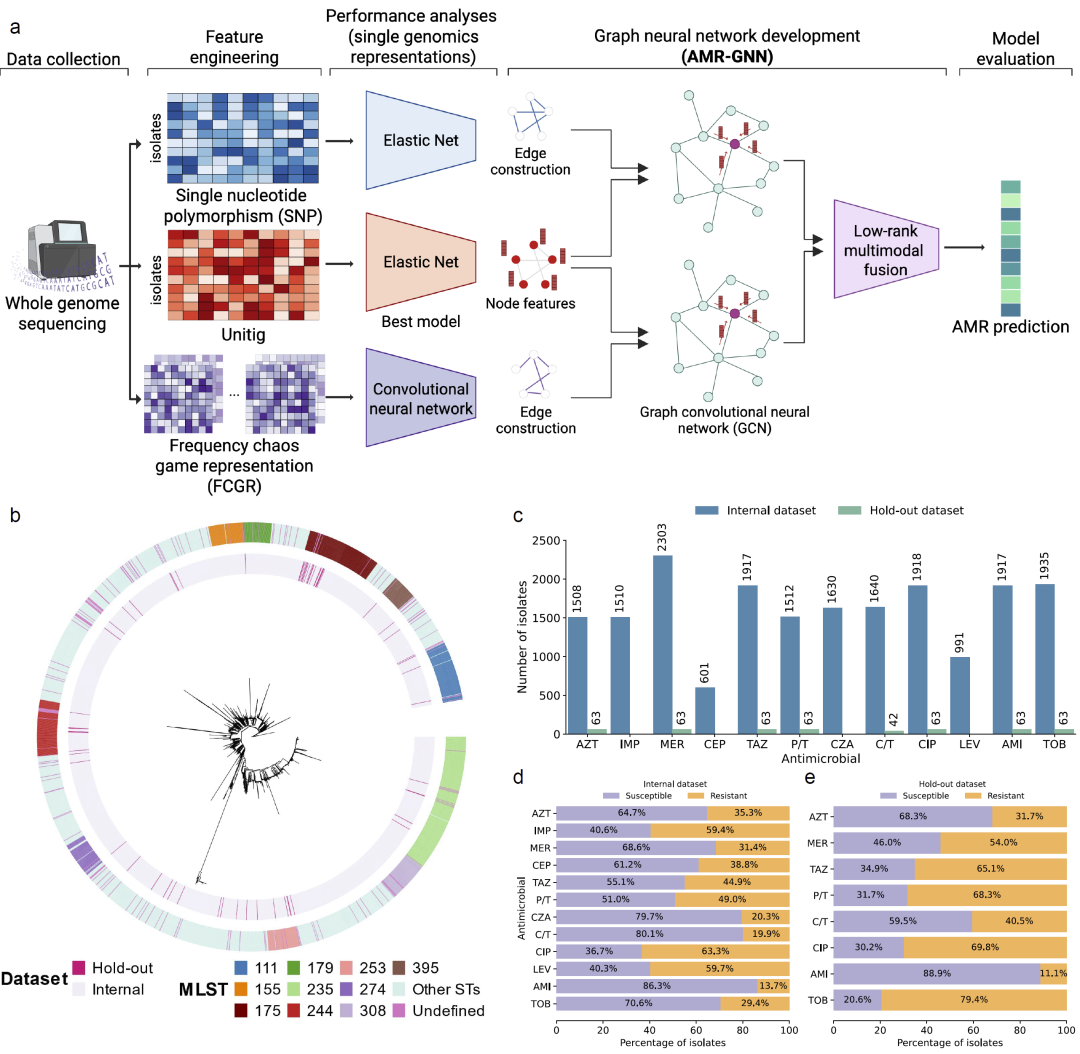
图1|AMR-GNN工作流程及用于训练与测试的铜绿假单胞菌数据集概览。
结果
数据集与模型设计
研究人员整合了来自多个数据源的WGS数据和药敏实验结果,构建了包含2515个铜绿假单胞菌菌株的数据集。该数据集具有丰富的群体结构,涵盖500多个序列型。研究人员将其中大部分数据用于模型训练和内部验证,并保留两个较小数据集作为独立外部验证集。
在模型结构上,AMR-GNN将每个菌株作为图中的节点,并通过基因组相似性构建节点之间的连接关系。节点特征来自基因组序列表示,而边则反映菌株之间的遗传相似性。通过这种方式,模型能够同时利用个体菌株信息和群体结构信息进行学习。
单一基因组表示模型表现
研究人员首先评估了不同单一基因组表示方式在耐药性预测中的表现。结果表明,基于unitig特征的模型在绝大多数抗生素上获得了最高的预测性能。该模型在氟喹诺酮类和氨基糖苷类抗生素上的预测准确度尤其高,而在部分β-内酰胺类抗生素上的表现则相对较低。
相比之下,FCGR表示在部分抗生素上明显优于SNP表示,但整体性能仍略低于unitig表示。因此,研究人员选择unitig特征作为图神经网络的节点特征,并利用SNP和FCGR信息构建图结构。
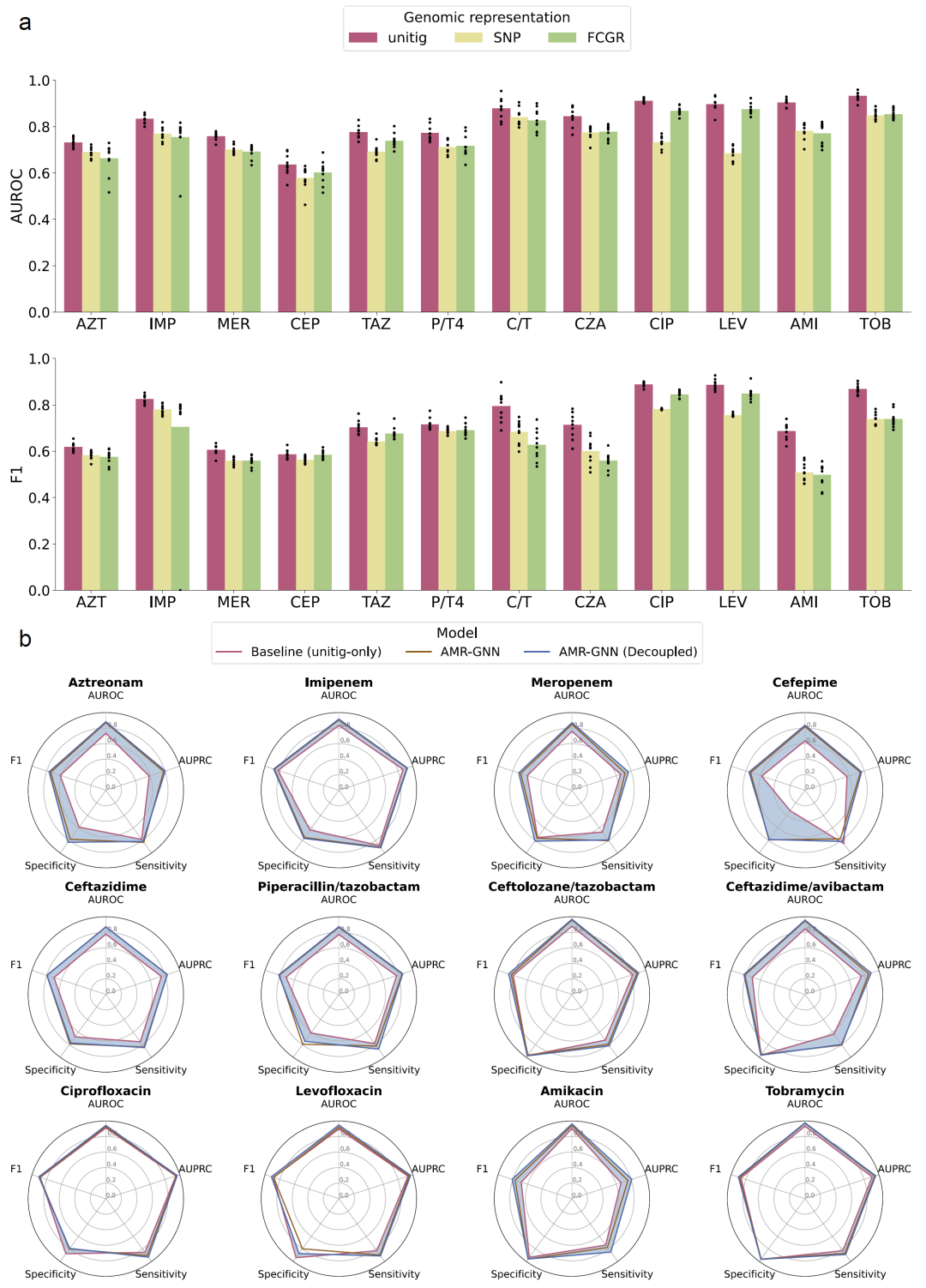
图2|单一基因组特征模型与AMR-GNN模型的性能评估。
AMR-GNN显著提升预测性能
在引入图神经网络结构后,AMR-GNN在大多数抗生素预测任务中均优于基线模型。对于12种测试抗生素中的11种,AMR-GNN均表现出显著性能提升,尤其是在原本预测性能较低的抗生素上改进最为明显。
此外,研究人员发现细菌群体结构会对模型产生偏差,因为同一克隆群体的菌株在图中高度相连。通过移除同一MLST群体之间的连接,模型的预测性能进一步提高,并减少了对克隆信号的依赖。
在外部验证数据集中,AMR-GNN依然表现出比基线模型更好的泛化能力。虽然部分抗生素的预测性能有所下降,但整体表现仍优于传统机器学习模型。
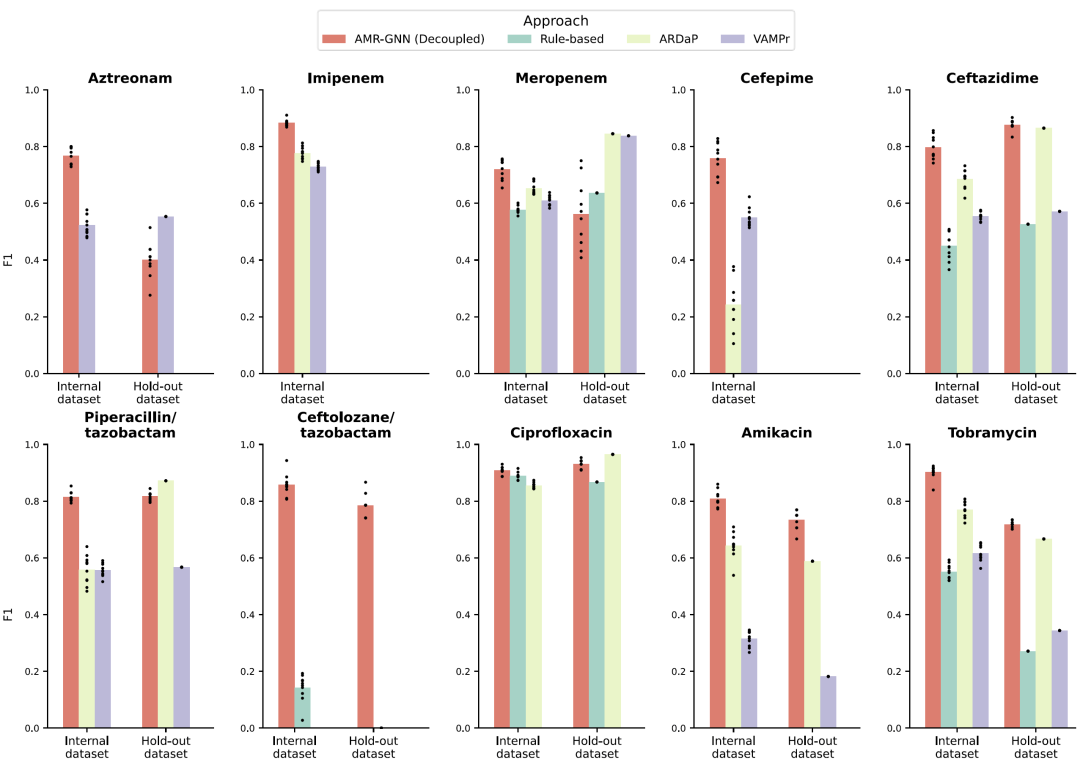
图3|AMR-GNN与规则驱动方法及现有公开AMR表型预测模型的F1-score性能比较。
在多种病原体中的泛化能力
为了评估模型的通用性,研究人员进一步在多个重要病原体的数据集中测试AMR-GNN,包括大肠杆菌、肺炎克雷伯菌、金黄色葡萄球菌和粪肠球菌。
结果显示,AMR-GNN在几乎所有物种-药物组合中都取得了较高的预测准确度,平均AUROC普遍超过0.9。这表明该模型不仅适用于铜绿假单胞菌,还能够推广到其他革兰阴性和革兰阳性病原体。
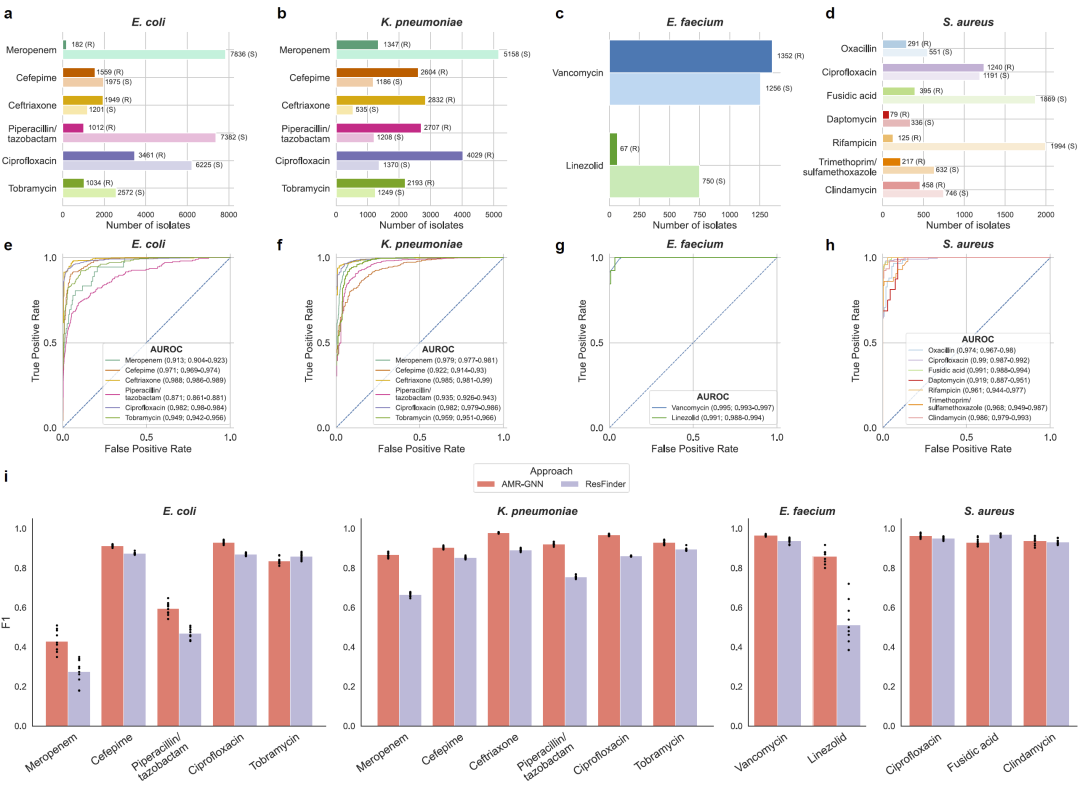
图4|AMR-GNN在BV-BRC数据库关键细菌病原体中的预测性能。
讨论
本研究表明,通过整合多种基因组表示并结合图神经网络,可以显著提升基于WGS数据的抗菌药物耐药表型预测性能。相比仅依赖单一特征表示的方法,多表示整合能够更全面地捕捉细菌基因组中的耐药信号。
AMR-GNN利用图神经网络的两个关键优势:一方面能够在学习分类任务的同时构建有意义的样本网络结构,另一方面能够灵活整合多种数据类型。这使得模型不仅能够生成有效的耐药预测结果,还能够揭示菌株之间共享的遗传信息。
研究结果还表明,通过减少菌群结构带来的偏差可以进一步提升模型性能。此外,模型在多个病原体数据集上的表现证明了其良好的跨物种泛化能力。
尽管如此,该研究仍存在一些局限。例如,模型需要预先进行特征选择,随着新菌株的加入可能需要更新特征集合;部分新发现的候选耐药基因仍需要实验验证;此外,模型在不同地区的数据上可能存在泛化差异,因此需要持续整合新的基因组数据进行训练。
总体而言,AMR-GNN展示了一种整合多种基因组信息进行耐药预测的有效策略,并为未来结合转录组、蛋白组等多组学数据提供了潜在框架。这种可扩展的图神经网络模型有望在临床耐药监测和精准抗生素治疗中发挥重要作用。
整理 | DrugOne团队
参考资料
Nguyen, HA., Peleg, A.Y., Wisniewski, J.A. et al. AMR-GNN: a multi-representation graph neural network framework to enable genomic antimicrobial resistance prediction. Nat Commun (2026).
https://doi.org/10.1038/s41467-026-69934-8
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号