重磅 | 模型自己写的 Skill 没用?SkillsBench 揭秘 Agent Skill 增强真相

重磅 | 模型自己写的 Skill 没用?SkillsBench 揭秘 Agent Skill 增强真相

mixlab
发布于 2026-03-25 09:39:25
发布于 2026-03-25 09:39:25
Shadow:Skill把Prompt和脚本、Tool整合在一起,想要设计好用的skill,需要深刻理解原理,把适合的任务放入到Prompt、脚本和Tool。良好架构的Skill,可以提升执行效率和准确性。
这篇论文研究得出:模型自己写的Skill没用。推荐阅读⬇️
导读:Agent Skills 正在成为 LLM 智能体的标配,但它们真的有效吗?最新发布的 SkillsBench 基准测试给出了令人意外的答案: curated Skills 平均提升 16.2%,但模型自生成的 Skills 不仅无用甚至有害。本文深度解读 SkillsBench 核心发现与设计原则。
随着 Claude Code、Gemini CLI 等 agent-centric 工具的爆发,Agent Skills(智能体技能)已成为增强 LLM 代理能力的热门方案。然而,社区中存在着一个 fundamental tension(根本张力):
虽然 Skills 生态系统迅速增长,但缺乏标准方法来衡量它们是否真的有效。
- Skills 到底能带来多少提升?
- 模型能否自己生成所需的技能?
- 怎样的 Skills 设计才是最高效的?
近日,一项名为 SkillsBench 的研究填补了这一空白。作为首个将 Skills 作为一级评估对象的基准测试,它通过 7,308 条轨迹的大规模实证评估,揭示了 Agent Skills 效能的真相。
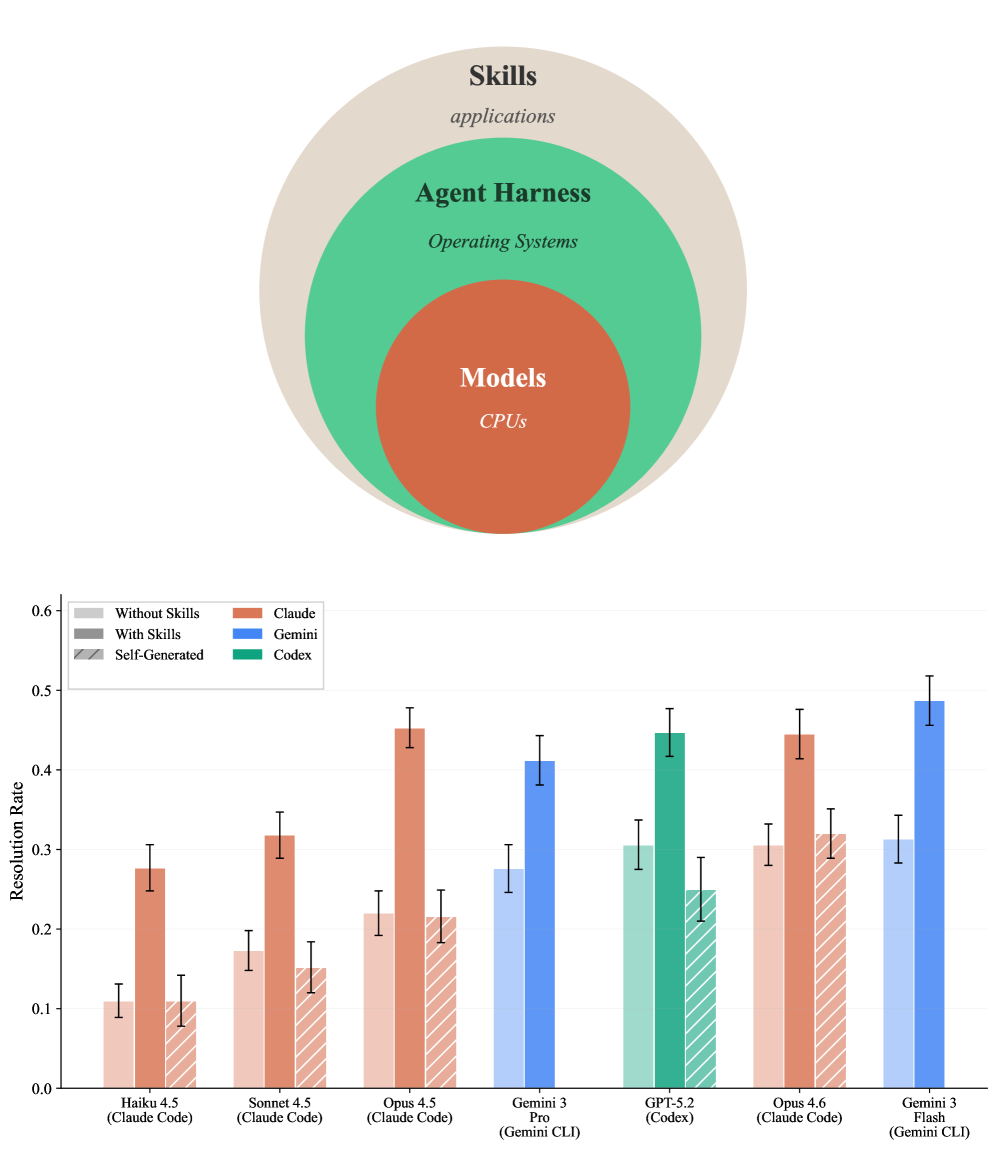
图 1: Agent 架构栈与不同配置下的解决率
01 SkillsBench:首个技能增强基准测试
SkillsBench 不仅仅是一个任务集,它是一个以 Skills 为中心的评估框架。
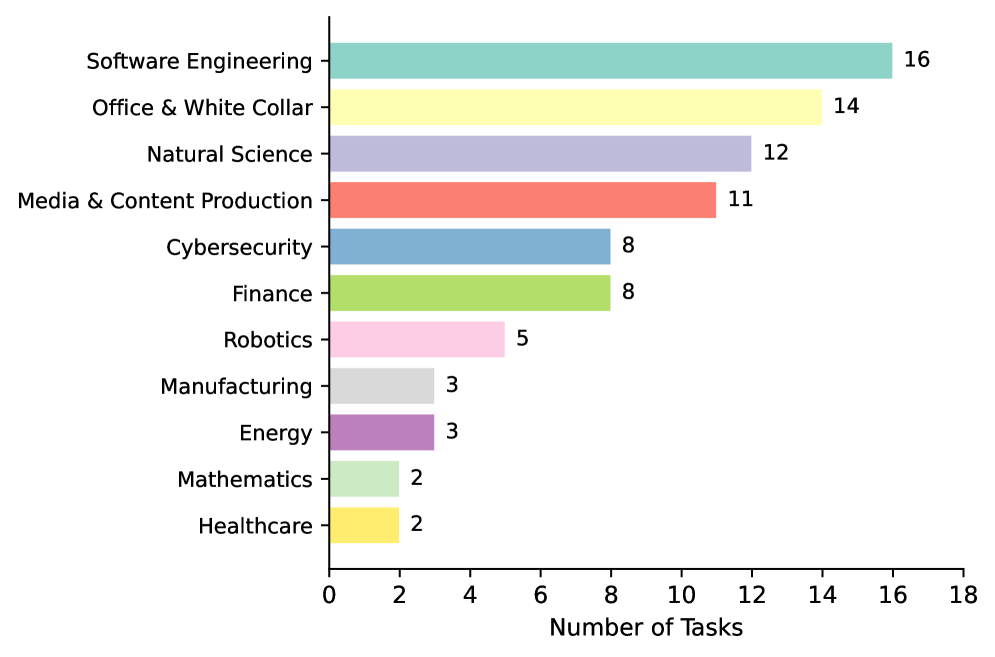
- 任务规模:涵盖 11 个领域的 84 个任务(从 322 个候选任务中精选)。
- 评估条件:每个任务均在三种条件下执行——无 Skills、 curated Skills(人工策划)、自生成 Skills。
- 测试配置:7 种 agent-model 配置(包括 Claude Code, Gemini CLI, Codex CLI 等主流商业代理)。
- 验证方式:采用确定性验证器(Deterministic Verifiers),避免 LLM-as-a-judge 的方差。
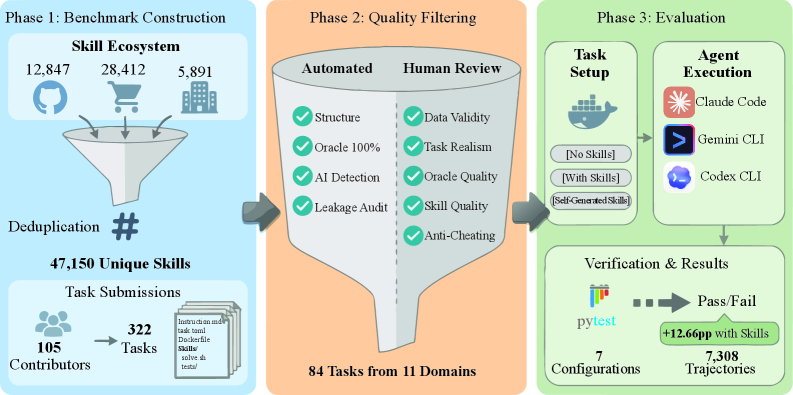
图 2: SkillsBench pipeline overview
研究团队采用了社区驱动的开源贡献模式,105 位来自学术界和工业界的贡献者提交了任务,并经过严格的自动化验证与人工审查,确保任务具有真实世界复杂性且防止作弊。
02 核心发现:四大真相
经过大规模实验,SkillsBench 得出了四个关键发现,其中一些结果可能颠覆你的认知。
📌 核心发现:人工策划技能(Curated Skills)对 Agent 提升显著
人工策划的 Skills 平均将通过率提高了 16.2 个百分点 (pp)。然而,这种提升在不同领域和配置间差异巨大:
- 最高提升:医疗保健领域 (+51.9pp)
- 最低提升:软件工程领域 (+4.5pp)
- 负面案例:84 个任务中有 16 个显示负增益,说明 Skills 有时会带来冲突指导或 unnecessary complexity。
洞察:Skills 的有效性高度依赖于特定领域知识在模型预训练中的稀缺程度。领域越 specialized(如临床数据协调),Skills 带来的提升越大。
📌 发现 2:模型无法可靠地自生成 Skills
这是本研究最令人震惊的发现之一。当被提示在解决问题前先生成 procedural knowledge 时:
- 平均表现:自生成 Skills 相比无 Skills 基线 下降 1.3pp。
- 失败模式:模型能识别需要领域知识,但生成的程序性知识不精确或不完整(例如只说“用 pandas 处理数据”,却没有具体的 API 模式)。
- 结论:有效的 Skills 需要人类策划的领域专业知识,模型目前无法可靠地自我增强。
📌 发现 3:Less is More(少即是多)
Skills 的设计复杂度直接影响效能:
- 最佳数量:每个任务提供 2-3 个 Skills 模块时效果最佳 (+18.6pp)。
- 边际递减:提供 4 个以上 Skills 时,收益降至 +5.9pp。
- 文档长度:聚焦的、中等长度的 Skills (+18.8pp) 优于全面的综合文档 (-2.9pp)。
建议:过于详尽的文档会增加 context burden,agent 难以从中提取 actionable guidance。 concise, stepwise guidance(简洁的逐步指导)配合 working example 往往更有效。
📌 发现 4:小模型 + Skills 可媲美大模型
Skills 可以部分补偿模型容量的限制:
- 案例:Claude Haiku 4.5 + Skills (27.7%) 的表现优于 无 Skills 的 Claude Opus 4.5 (22.0%)。
- 意义:在程序性任务上,合理的 Skills 增强可以让 smaller models 匹配 larger models 的性能,同时降低成本。
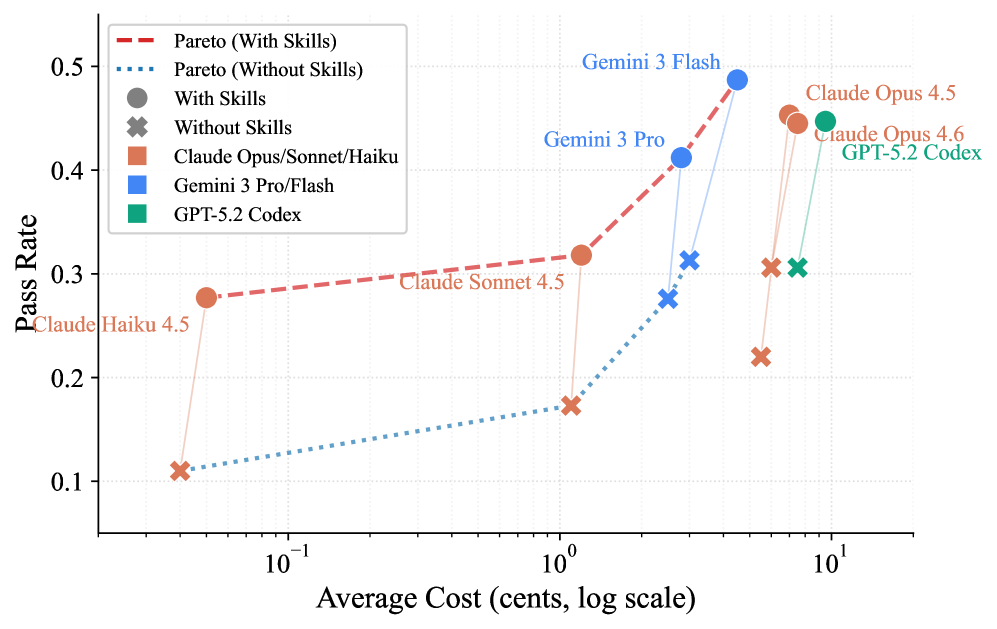
03 领域差异:谁最需要 Skills?
SkillsBench 涵盖了 11 个领域,数据显示 Skills 的效益存在显著的异质性:
领域 | 提升幅度 (Δ) | 原因分析 |
|---|---|---|
Healthcare | +51.9pp | specialized procedural knowledge,预训练覆盖少 |
Manufacturing | +41.9pp | 特定工作流知识稀缺 |
Mathematics | +6.0pp | 模型预训练覆盖较好 |
Software Eng. | +4.5pp | 模型已有强 prior,Skills 可能引入冲突 |
在任务层面,提升最大的任务包括 mario-coin-counting (+85.7pp) 和 sales-pivot-analysis (+85.7pp),这些任务涉及预训练中罕见的具体程序性知识。
Refer to caption
04 对开发者与研究者的启示
基于 SkillsBench 的分析,我们在构建 Agent Skills 时应遵循以下原则:
- 人类设计不可替代:不要依赖模型自动生成 Skills,核心 procedural knowledge 仍需人类专家输入。
- 模块化设计:保持 Skills 精简,2-3 个模块为佳,避免信息过载。
- 针对性增强:在模型预训练知识薄弱的领域(如医疗、制造)部署 Skills 收益最高。
- Harness 兼容性:Skills 的有效性也取决于 Agent Harness 的实现。某些 harness 会可靠地检索 Skills,而另一些可能会忽略它们。
05 结语与展望
SkillsBench 的建立标志着 Agent 评估进入了一个新阶段:从评估“模型能做什么”转向评估“增强能让模型多做多少”。
虽然当前结果基于 terminal-based 任务,但它为 principled Skills design(原则性技能设计)提供了实证基础。未来,随着多模态技能和 GUI 环境代理的发展,这一基准框架有望进一步扩展。
对于从业者而言,核心启示很明确:Skills 是强大的杠杆,但杠杆的支点必须是高质量的人类知识。
📚 论文信息
- Title: SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
- Link: arXiv:2602.12670
(本文基于学术论文内容整理,旨在传播前沿技术资讯)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号