面向更深预测编码神经网络的训练

面向更深预测编码神经网络的训练

CreateAMind
发布于 2026-03-11 17:11:49
发布于 2026-03-11 17:11:49
Towards the Training of Deeper Predictive Coding Neural Network
面向更深预测编码神经网络的训练
shttps://arxiv.org/pdf/2506.23800#page=1.00&gsr=0

摘要
通过平衡传播训练的预测编码网络是一种通过迭代能量最小化过程进行推断的神经模型。先前的研究表明,这类模型在浅层架构中表现出色,但当网络深度超过五到七层时,性能会显著下降。在本研究中,我们发现这种性能下降的原因是:在权重更新过程中,各层之间的误差呈指数级失衡,且前一层的预测对更深层的更新指导效果不佳。为解决第一个问题,我们引入了两种新的优化潜在变量的方法,利用精度加权在“松弛阶段”重新平衡各层之间的能量分布;针对第二个问题,我们提出了一种新的权重更新机制,以减少深层中的误差累积。经实证测试,我们在大量图像分类任务上验证了这些方法,结果表明,对于超过七层的网络,测试准确率大幅提升,其性能与类似模型的反向传播相当。这些发现表明,更好地理解松弛阶段对于大规模使用平衡传播训练模型至关重要,并为这类模型在复杂任务中的应用开辟了新的可能性。
引言
在GPU上训练大规模模型在能耗方面极为昂贵。为解决这一问题,近期的研究方向之一是研究利用物理系统特性进行计算的替代加速器 [Wright et al., 2022, Momeni et al., 2024]。一个典型的例子是利用忆阻器交叉阵列进行存内计算的硬件 [Tsai et al., 2018, Haensch et al., 2018]。然而,在不改变主要算法——误差反向传播 [Rumelhart et al., 1986] 的情况下,转向新型硬件已被证明具有挑战性,原因在于两个核心问题:需要顺序执行前向和反向传播过程,以及需要解析地计算全局代价函数的梯度。这些要求需要数字硬件架构精确匹配前向计算及其对应的梯度计算,且必须在低噪声环境中进行,因为即使是微小的波动也可能传播数值误差,从而改变模型的最终性能。 为解决上述问题,一个研究方向是研究仅依赖局部计算的深度神经网络学习算法 [Bengio, 2014, Hinton, 2022]。其中一种方法是通过平衡传播来训练模型,这是一种框架,允许通过模拟达到平衡状态的物理系统来学习神经网络的参数 [Scellier and Bengio, 2017]。这种物理系统通常通过能量函数定义,该函数用神经网络的权重和神经元描述其状态,不同的函数描述不同的系统 [Hopfield, 1982, Krotov and Hopfield, 2016]。
近年来,研究人员投入了大量精力来扩大基于能量模型的部署规模。最近的两项工作还通过使用霍普菲尔德能量函数 [Scellier et al., 2024] 和预测编码能量 [Pinchetti et al., 2024],仔细基准测试了常用学习算法的多种变体,结果表明,这类模型在训练浅层模型(最多五层或七层)时,能够达到与通过反向传播训练的标准深度学习模型相当的性能。然而,这一结果并未转化为深层模型的情况,在深层模型中,我们观察到性能显著下降。由于现代深度学习的大部分成功都依赖于非常深的架构,因此,如果我们的目标是训练大规模的预测编码网络,那么理解和解决这种性能下降的原因至关重要。
最近的研究表明,在一个三层模型中,一层中聚集的能量可能比前一层中聚集的能量高出一个数量级 [Pinchetti et al., 2024]。尽管这种浅层模型仍然可以实现良好的测试准确率,但我们推测,这种“能量失衡”在更深层的架构中成为了一个关键瓶颈,导致性能下降的方式在概念上类似于消失梯度问题 [Hochreiter, 1998]。更具体地说,这种失衡阻碍了能量的有效传播——以及关键的误差信息——从输出层向早期层的反向传播,从而产生了两个问题:首先,它阻止了模型充分利用其深度,因为早期层接收到的误差信号不足以进行有效训练;其次,由于后层中能量过多,潜在状态可能与前向传播值大幅偏离,从而导致次优的权重更新。
解决这种能量失衡需要能够随着能量在网络中传播而自适应调节不同层能量的机制——这一挑战与生物神经系统通过基于精度的调节解决的问题惊人地相似 [Clark, 2013, Mumford, 1992]。在大脑中,信息流实际上被认为受到精度加权的强烈影响,这是一种动态重新调整误差项的机制,有效地平衡了不同大脑区域之间的自上而下和自下而上的信号 [Rao and Ballard, 1999, Friston, 2005, Friston and Kiebel, 2009, Clark, 2013]。尽管精度加权在生物系统中扮演着核心角色,但在机器学习应用中却一直被忽视,而且在实验设置中,当在算法描述中被考虑时,通常被设置为 1 [Whittington and Bogacz, 2017, Salvatori et al., 2023, Song et al., 2020]。受这一神经科学原理的启发,我们提出利用精度来调节预测编码网络中的能量传播,旨在通过解决识别到的能量失衡问题,提高其在图像分类任务中的性能。我们通过首先分析深度卷积架构的能量传播,然后提出时间依赖的精度来解决这些问题。结果表明,这大大提高了测试准确率,从而证实了我们关于能量传播与实证结果之间因果关系的假设。我们的贡献简要如下:
- 我们实证研究了模型不同层的能量传播,表明靠近标签的层的能量比其他层大几个数量级,而第一层的能量几乎不存在。这有力地支持了深层模型的能量无法到达第一层的假设。我们还表明,在通过反向传播训练的高性能模型中,并未观察到类似现象。
- 为解决这种失衡,并测试其是否影响模型的最终测试准确率,我们提出了两种依赖于时间和层数的精度加权组合。第一种提议,称为脉冲精度,在能量到达特定层时利用非常大的精度将其推向下一层。第二种提议,我们称之为衰减精度,引入了对后层进行重罚的指数衰减精度。结果表明,这两种方法都调节了能量失衡,其中脉冲精度在深层模型的测试准确率方面提供了最大的改进。
- 此外,我们还提出了一种批量归一化 [Ioffe and Szegedy, 2015] 的变体,在这种新的推理方式下,进一步提高了结果。
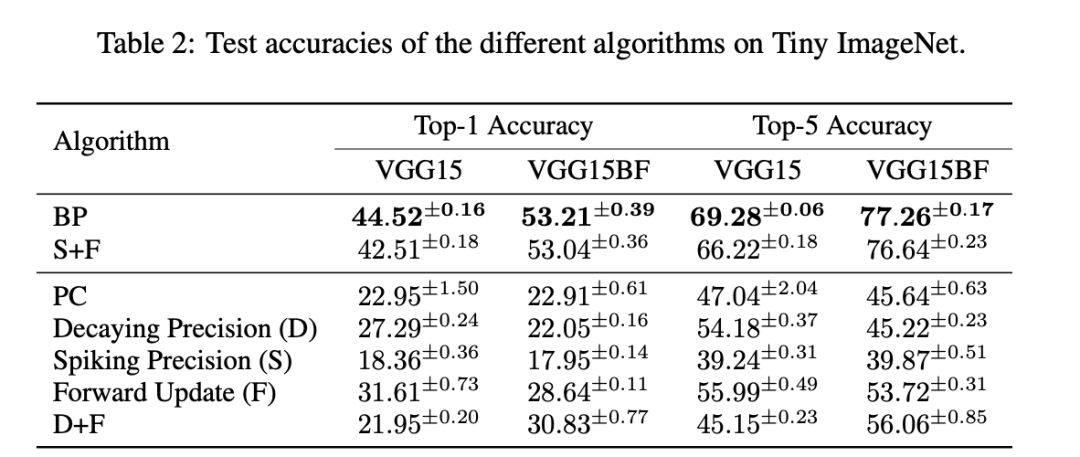
- 为了进一步提升结果,我们引入了一种新的权重更新机制,改变了权重参数的更新方式。这种方法同时使用初始化时计算的预测(从而增加了一定程度的不可行性)和收敛时的神经活动来计算更新。结果再次表明,这种方法大大提高了预测编码网络在超过十层的模型中的性能。此外,将我们新的权重更新和精度加权推理结合起来,使我们能够在生物合理性社区中具有挑战性的基准测试中达到与反向传播相当的结果,例如在 Tiny ImageNet 上训练具有 15 层的卷积模型。
2 相关工作
平衡传播(EP)。 平衡传播是一种受连续霍普菲尔德网络对比学习启发的监督学习算法 [Movellan, 1991]。在这里,神经活动在两个阶段进行更新:第一阶段是为了最小化定义在神经网络参数上的能量函数;第二阶段则是在添加定义在标签上的损失函数后最小化相同能量 [Scellier and Bengio, 2017]。有趣的是,这两个阶段使我们能够使用有限差分系数以任意精度近似损失函数的梯度 [Zucchet and Sacramento, 2022]。其结果是,平衡传播可以被视为一种允许使用任意物理系统(这些系统能够达到平衡)来最小化损失函数的技术,因此它已在众多领域得到了研究 [Scellier, 2024, Kendall et al., 2020]。在旨在扩大机器学习实验规模的模拟方面,大多数工作使用霍普菲尔德能量进行实验 [Hopfield, 1982],主要是在使用卷积网络的图像分类任务上 [Laborieux et al., 2021, Laborieux and Zenke, 2022]。目前的最新研究进展表明,EP 模型能够在具有 5 层和 7 层隐藏层的模型上达到与 BPTT(通过时间的反向传播)相当的性能 [Scellier et al., 2024],混合模型是例外,它们通过交替使用 BP 和 EP 训练的层块,在具有 15 层的模型上实现了良好性能 [Nest and Ernoult, 2024]。
预测编码(PC)。 我们这里使用的预测编码最初是为了模拟大脑中的层次化信息处理而开发的 [Rao and Ballard, 1999, Friston, 2005]。直观地说,这一理论认为,层次结构中某一层次的神经元和突触会更新,以更好地预测下层神经元的活动,从而最小化预测误差。有趣的是,同样的算法也可以用作深度神经网络的训练算法 [Whittington and Bogacz, 2017],并且观察到其与反向传播有许多相似之处 [Song et al., 2020, Salvatori et al., 2022a]。为此,它已在众多机器学习任务中得到应用,包括图像生成和分类、自然语言处理以及联想记忆等 [Sennesh et al., 2024, Salvatori et al., 2023, Pinchetti et al., 2022, Ororbia and Kifer, 2020, Salvatori et al., 2021]。同样,目前的最新研究进展是通过训练具有 5 层隐藏层的卷积模型实现的,一旦使用 7 层深的模型,性能就开始变差 [Pinchetti et al., 2024]。PC 与 EP 之间的联系可以通过双层优化的概念很好地加以解释 [Zucchet and Sacramento, 2022],其中用于学习的神经活动是物理系统的平衡态。关于描述在这种设置中进行学习的更一般框架(但与所使用的物理系统和能量函数无关),我们参考了两篇最近的研究 [Ernoult et al., Scellier et al., 2022]。
3 背景

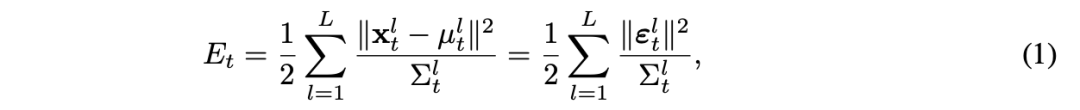
我们假设协方差是与网络层相关的:同一层中的所有神经元具有相同的协方差。为此,当协方差 Σₗₜ 是一个标量值,或是一个其对角线元素均等于该标量的对角矩阵时,我们使用相同的记号。关于预测编码网络的详细结构,我们参考图1(a)。
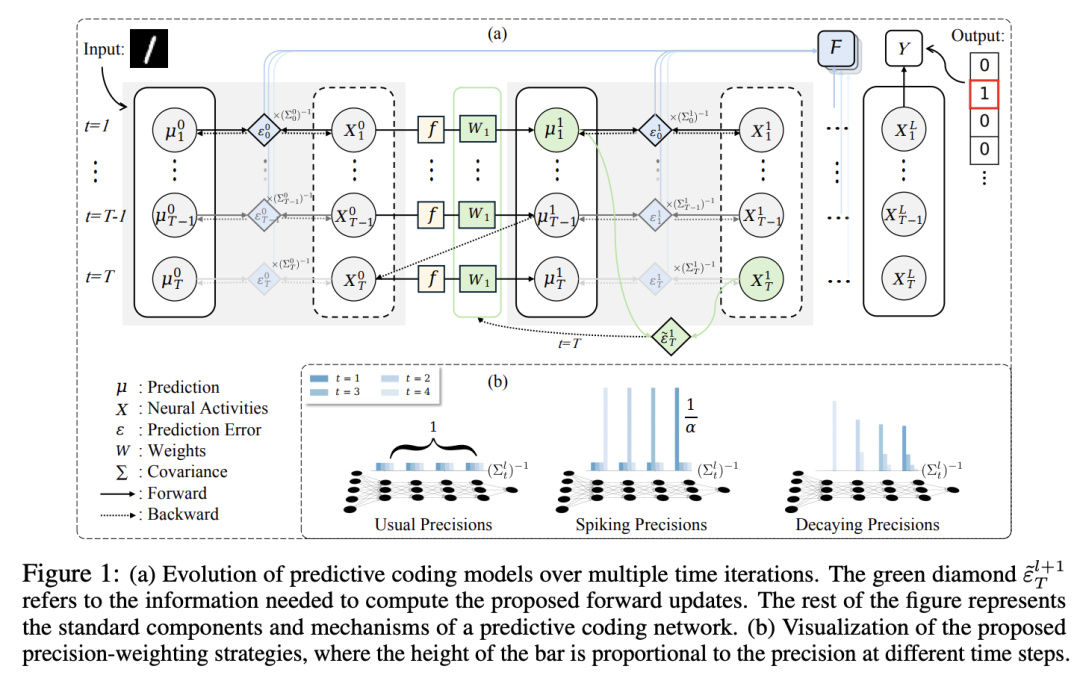

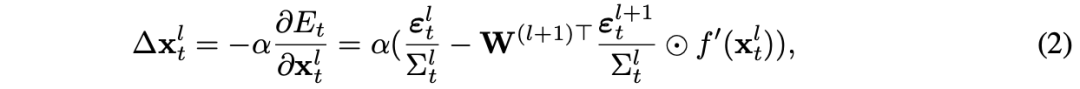

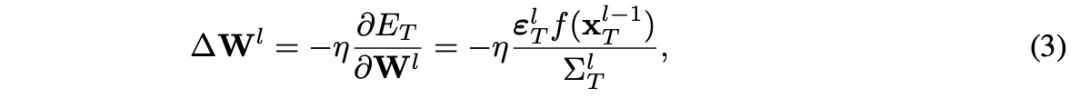

4 方法
在本节中,我们首先研究了不同网络层之间能量不平衡的现象,然后利用由此得出的见解,提出了几种时间依赖协方差的不同表达形式,以解决这一问题。具体来说,我们介绍了两种方法,分别称为脉冲精度(spiking precisions)和衰减精度 (decaying precisions),每种方法都提供了不同的策略,通过动态更新精度来更好地在整个模型中分配能量。此外,我们还引入了一种学习阶段的变体,该变体利用初始化时的神经活动来更好地更新参数,从而提升模型的整体性能。
我们还提出了一种新型的批量归一化 (batch normalization)公式,更适合用于预测编码网络(PCNs)的训练。我们将展示,这种新公式在与标准预测编码(PC)方法结合使用时,对性能不会产生显著影响。然而,在与我们新提出的方法结合使用时,它将带来显著的性能提升。
为了更好地理解我们所提出的方法,图1(a)展示了一个流程图,直观地说明了后续各节中讨论的模块。此外,图1(b)展示了协方差矩阵的可视化结果。
为了研究网络不同层级之间的能量不平衡现象,我们在训练过程中跟踪了每一层的总能量,以及测试和训练损失,并将其与反向传播(BP)的结果进行了对比。我们进行了广泛的研究,测试了多种模型、数据集和设置,其中大部分结果我们主要在补充材料中报告,而在图2中仅展示了表现最佳模型的图表。
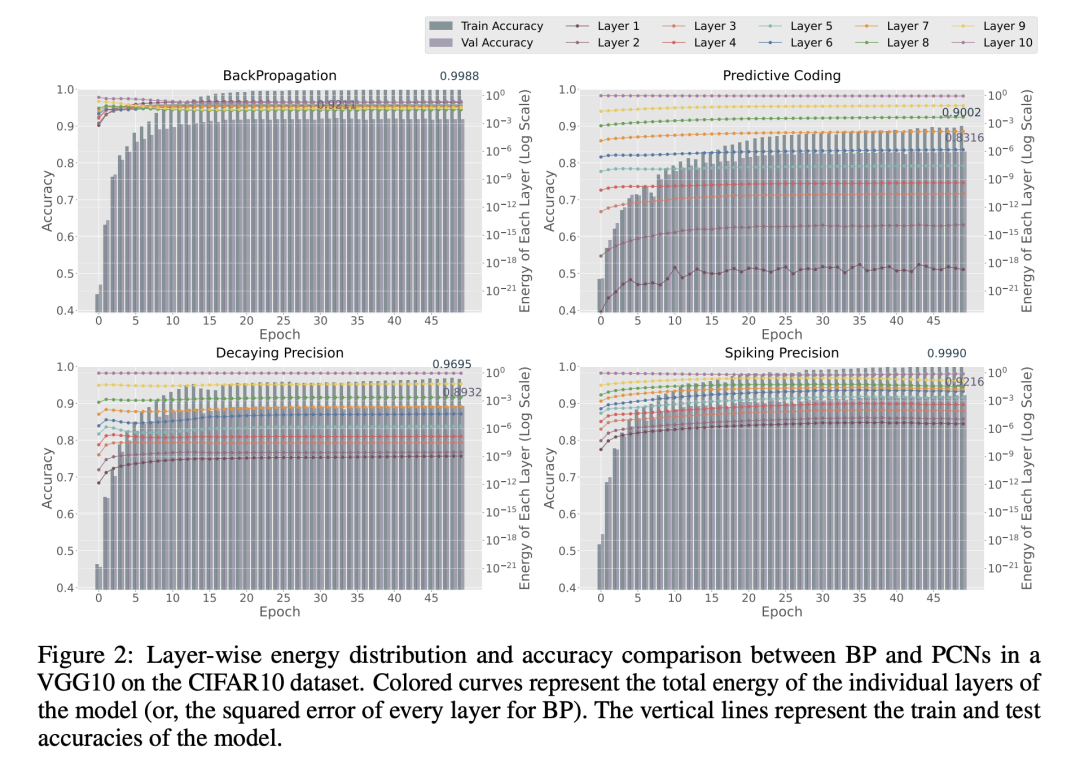
由于BP并没有明确的能量定义,因此我们使用了反向传播过程中每一层计算出的平方误差,这在权重参数更新方面等同于PC方法中的误差。可以观察到,在PCN中存在显著的能量不平衡现象,其中早期层的能量比后期层低多个数量级。这在BP训练的模型中并未出现,BP模型表现出更均匀的能量分布,甚至能量最低的层也高于10⁻²。
这一组实验揭示了深度PC模型表现不佳的潜在原因。我们所提出的方法(第二行)似乎略微缓解了这种能量不平衡,尽管这种不平衡仍然非常显著。然而,这种部分缓解已经足以让模型拟合训练集。在本节的其余部分,我们将详细描述用于解决这一主要瓶颈的方法。
脉冲精度(Spiking Precision) 。训练预测编码模型涉及在稳定性与误差信号的有效传播之间进行关键的权衡。一方面,神经活动的学习率 α 过大可能导致不稳定:目前领域内大多数最佳结果都是使用较小的学习率获得的,例如 α = 0.05 [Pinchetti 等, 2024]。另一方面,这样小的学习率又会指数级地减缓误差信号在模型各层之间的传播速度,正如 [Song 等, 2020] 补充材料中所指出的那样。
为此,我们提出一种方法:当能量——最初集中在输出神经元中——首次传播到某一层时,使该层的精度产生一个与学习率成比例的脉冲(spike)。从时间调度的角度来看,这种情况发生在 l = L − t 时。对于一个具有 L 层和 T 个推断步的网络,所提出的脉冲精度形式如下:
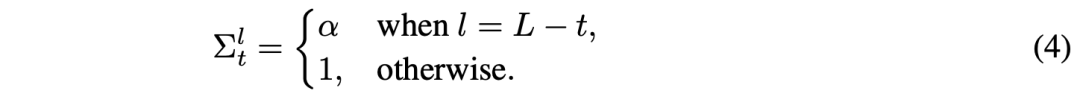
直观上,在前 L 次迭代过程中,这种脉冲使得能量能够从最后一层有效地传播到第一层,而其余的更新则照常进行。虽然这种方法还有一个额外的优势,即不会引入任何新的超参数,但它未能解决我们之前指出的第二个问题:即由于较大的能量和持续的更新,导致神经活动与前向传播的结果偏离过大。
衰减精度(Decaying Precision) 。在平衡稳定性与误差信号高效传播这一思路的基础上,我们提出了一种衰减精度策略。在此方法中,不同层的精度随时间呈指数衰减,其定义如下:
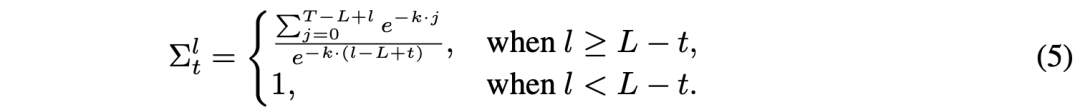
在这里,分子的求和项作为一个归一化项,确保在时间上各层精度的总和等于 1,即满足:
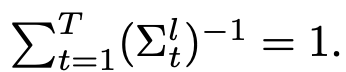


我们的方法确保了权重的调整仍然与初始的前馈预测保持联系,同时又融合了通过迭代推断获得的更精细的表示。这种方法的优势在于能够在学习过程中保持稳定性,并防止误差在深层中累积,这对于扩展预测编码(PC)网络至关重要。但其缺点是需要在内存中存储额外的信息,这些信息仅用于权重更新,因此相比原始方法,生物合理性略差一些。此前有研究以不同的方式使用过类似形式的能量函数,但那些工作中该函数是用来指导神经活动的更新而非权重更新 [Whittington 和 Bogacz, 2017]。伪代码详见算法 1。

BatchNorm 冻结(BF, BatchNorm Freezing) 。BatchNorm 被证明在稳定深度神经网络训练方面起到了关键作用,因为它缓解了与梯度相关的问题,并确保了梯度的平稳传播。在训练过程中,它通过以下函数对层的激活值进行归一化处理:
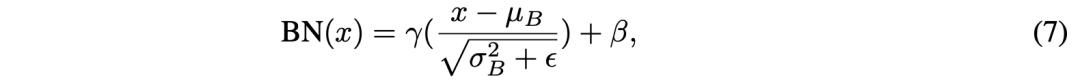

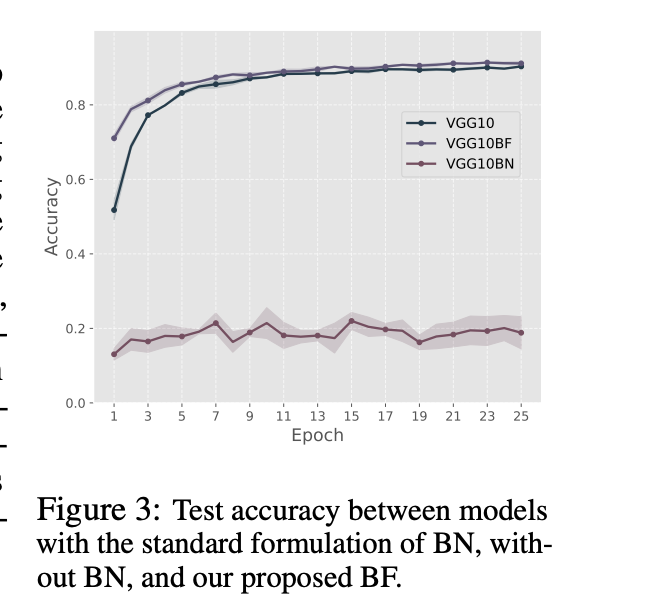
然而,当直接应用于PCNs时,批量归一化(BatchNorm)未能取得类似的改进效果。我们推测这种失败是由于迭代推理阶段导致的,其中对同一批数据进行多次处理可能会导致层统计量的过拟合。为了解决这一问题,我们提出了批量归一化冻结(BatchNorm Freezing,BF),这是一种修改方法,它在推理阶段冻结批量归一化的状态,并且仅在学习阶段更新运行统计量,同时在推理迭代过程中仍然使用批量统计量进行归一化。我们的实验结果表明,这种修改不仅保留了网络的收敛性,还提升了性能,这表明其稳定激活分布的能力有效地支持了PC架构中的基于能量的优化。
5 实验
在本节中,我们在超过7层的架构上测试了我们提出的方法组合,并展示了在训练与BP在相同复杂度模型上时,我们能够达到与BP相当的性能。为了提供全面的评估,我们在CIFAR10/100 [Krizhevsky等,2009]上测试了它们。我们考虑了以下三个基线:标准的PC(在第3节中描述)、带有中心调整的PC(PC-CN)、根据先前研究[Pinchetti等,2024;Scellier等,2024]表现最佳的算法,以及标准的BP。作为架构,我们使用了VGG类模型[Simonyan和Zisserman,2014],这些是深度卷积模型,后接前馈层。与上述研究的设置类似,我们在本研究中仅考虑在卷积层之后有一个单一前馈层的模型。这使我们能够检查当模型深度增加时,我们提出的方法是否仍然存在性能下降的问题。在所有情况下,我们都进行了大量的超参数搜索,报告了通过早停法获得的最佳测试准确率,并取5次运行的平均值。所有用于复现结果的详细信息都可以在补充材料中找到。
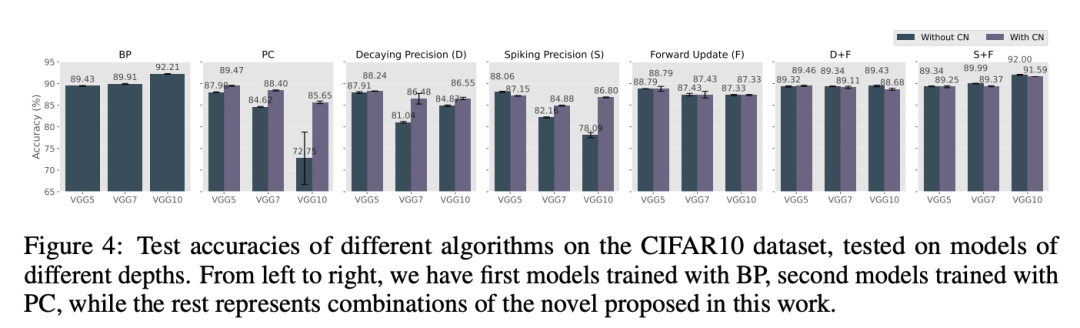
性能退化。在第一个实验中,我们在不同深度的VGG模型上测试了一些提出的算法,并在图4中报告了它们的测试准确率随层数变化的条形图。这些图表表明,当模型深度增加时,PC的原始公式以及使用中心调整的公式在测试准确率上都显著下降。相比之下,我们提出的方法组合(精度和前向更新,即D+F和S+F)表现出色,尤其是在模型深度增加时,显著避免了准确率的大幅下降。特别是,带有前向更新的尖峰精度是唯一一种在VGG5/7/10模型中表现出与BP相当性能的方法组合。我们稍后会看到,这一结果与更复杂的实验结果一致,即该方法仍然是总体上表现最佳的方法。在没有前向更新的模型中,与先前的研究结果一致,使用中心调整可以提高算法的准确率,尤其是在大多数情况下,随着模型层数的增加,这种效果更加明显。然而,我们发现一旦添加了前向更新,中心调整就不再带来性能上的好处。因此,从现在开始,我们将只报告使用PC标准公式(没有任何调整)的实验。
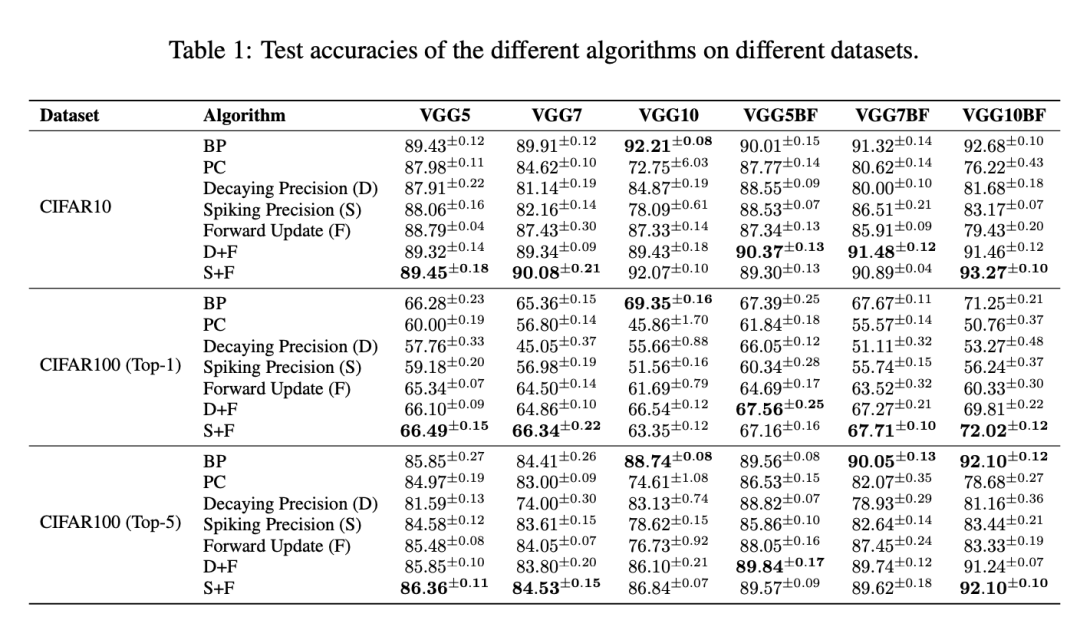
测试准确率。为了更好地测试我们方法的性能,以及所有组合和消融研究的性能,我们在表1中进行了全面的比较。结果显示,对于浅层网络,我们可以通过所有方法匹配或近似BP的性能。在深层模型中,情况并非如此,因为标准PC表现不佳,衰减精度和尖峰精度稍好一些,而前向更新则很好地缓解了性能下降。然而,是推理方法和更新方法的组合表现最佳,带有尖峰精度和前向更新的模型总是略微匹配使用BP训练的模型的性能。总之,我们注意到批量冻结进一步改善了结果,清楚地表明最佳的方法组合是批量冻结、前向更新和尖峰精度,这些方法在测试VGG10时在所有基准测试中都取得了最佳结果。在这种情况下,我们在测试BP时使用了带有正常BN的模型。
扩展规模。为了看看我们的方法在更大规模的数据集和更深的网络上能扩展到什么程度,我们还在Tiny ImageNet [Le和Yang,2015]上测试了VGG15,Tiny ImageNet是ImageNet的一个缩小版,包含200个类别。我们使用的模型与混合平衡传播工作中提出的模型完全相同 [Nest和Ernoult,2024]。表2中报告的结果更加强有力地显示了我们的方法相对于PC原始公式的效果。具体来说,我们观察到大多数单独的推理方法,即使是使用精度加权的方法,在这项具有挑战性的任务上也无法达到BP的性能。然而,当我们使用本工作中提出的所有新方法组合时,结果得到了匹配:前向更新、尖峰精度和批量归一化冻结。
6 结论
在本工作中,我们致力于解决将预测编码扩展到图像分类任务的问题。具体来说,我们研究了以下研究问题:为什么使用预测编码能量训练的深度模型无法达到使用反向传播训练的对应模型的准确率?我们通过提出两种新的正则化技术来解决这一问题,并展示了我们方法的组合能够训练出接近基于反向传播模型性能的深度预测编码模型。更具体地说,我们在 Tiny Imagenet 上训练了一个包含 15 个隐藏层的模型,这一结果此前只有通过使用同时包含 BP 和 EP 训练层的混合模型才能实现。我们相信这些结果将激励未来的研究工作,朝着使这类模型在更大规模上发挥作用的方向发展,这些研究将涉及我们尚未考虑的更复杂的数据集和模态,例如在 ImageNet 上训练基于平衡传播的 ResNets [He 等,2016],或者小型 Transformer 模型。
尽管这是朝着提升预测编码和平衡传播模型性能的一个良好起点,但本工作仍有一些局限性,这些将在未来的研究中得到解决和更深入的探讨。第一个问题是关于对能量不平衡现象的更好理解,这一现象尚未得到充分研究:它的成因是什么,以及它与模型在测试和训练准确率上的表现之间的相关性。这将使我们能够扩展到更大规模的数据集和基准测试。本工作的第二个局限性是,在前向更新过程中存在预测值的初始化值,这意味着算法需要在内存中存储这一值,从而增加了生物学上的不可行性。这也揭示了这类模型的另一个问题,该问题同样由能量不平衡引起:在网络的后层,收敛时的预测值往往会与初始化时的预测值偏离过大,导致随后的权重更新次优。未来的研究将探索所有这些问题,并利用所获得的知识进一步提升这类模型的性能,一个很好的起点是 Innocenti 等 [2025] 进行的同时期研究,该研究从理论上表明有可能训练非常深的前馈模型。另一项同时期的研究通过引入值节点的顺序更新来解决与我们相同的问题,这类似于之前提出的 PC 的一个变体,该变体研究了 PC 与反向传播之间的等价性 [Song 等,2020;Salvatori 等,2022b]。
附录 在这里,我们提供了所进行实验的说明,以及复制论文结果所需的所有参数的详细描述。我们还提供了一个消融研究,展示了各个方法单独的性能。
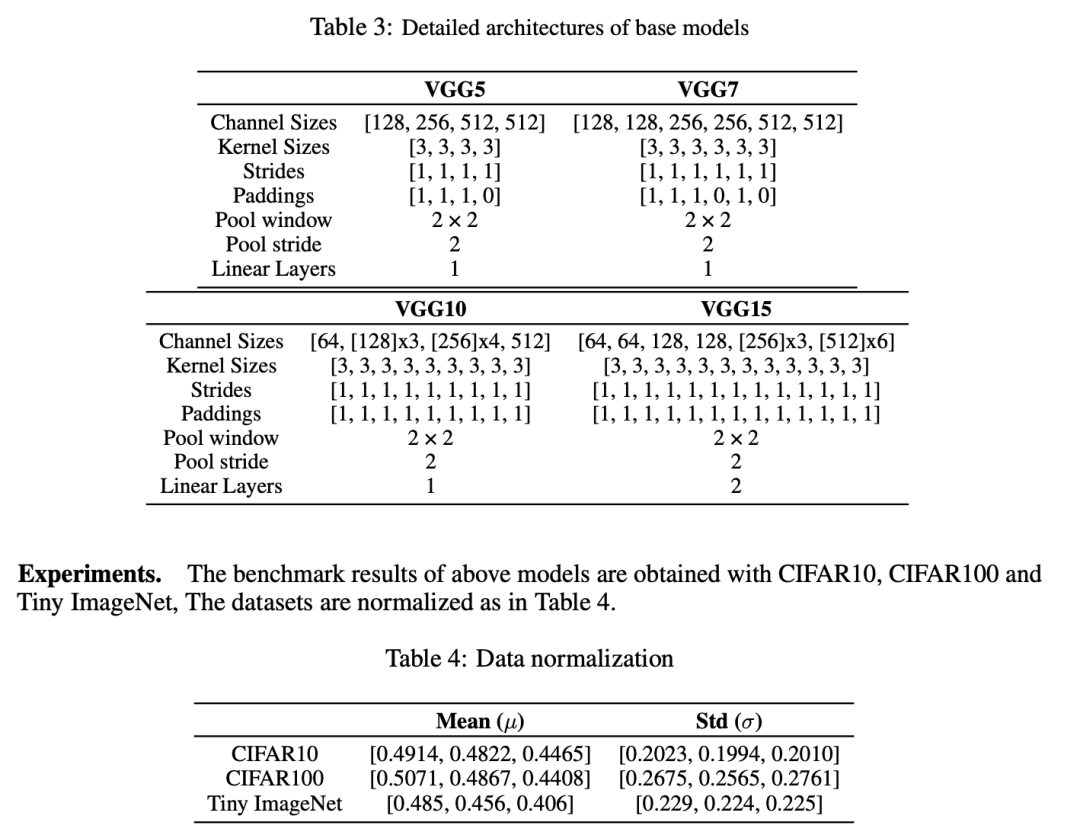
A 实验设置 模型。我们在四种模型上进行了实验:VGG5、VGG7、VGG10和VGG15。这些模型的详细架构在表3中呈现。
在对CIFAR10、CIFAR100和Tiny ImageNet训练集进行数据增强时,我们使用了50%的随机水平翻转。我们还应用了随机裁剪,但设置有所不同。对于CIFAR10和CIFAR100,图像被随机裁剪为32×32分辨率,并带有4像素的填充。而对于Tiny ImageNet,图像则被随机裁剪为64×64分辨率,并带有8像素的填充。在这些数据集上的测试阶段,我们仅应用了标准的数据归一化处理,未使用任何额外的数据增强技术。
在优化器和学习率调度器方面,在松弛阶段更新x时,我们采用带动量的随机梯度下降(SGD)。在“脉冲衰减”(Spiking Decaying)方法中,最后一个隐藏节点x的学习率随着迭代次数t呈指数衰减,按照公式 lr = lrt_x 进行调整。尽管我们在其他方法中也评估了这种指数衰减策略,但并未带来性能提升,因此在最终实现中未包含该策略。
在学习阶段,我们使用AdamW优化器并结合权重衰减来优化权重W。学习率调度采用预热-余弦退火策略(不重启)。该调度器在预热阶段以较低的学习率开始训练,然后平滑过渡到余弦形状的衰减曲线,避免性能的突然下降。调度参数设置如下:最大学习率达到初始学习率的1.1倍,最终学习率下降至初始学习率的0.1倍,预热阶段持续总迭代步数的10%。

我们基于表5中指定的搜索空间进行超参数选择。所有实验均使用基于JAX的PCX库Pinchetti等人[2024]实现,该框架专为预测编码网络设计,并提供了全面的基准测试能力。所有实验均在NVIDIA A100/H100 GPU上进行,每次试验都使用Tree-Structured Parzen Estimator(TPE)算法Watanabe [2023]进行500次迭代的超参数搜索。表1和图4中展示的结果是使用5个不同的随机种子(从0到4中选取)并采用最优超参数配置所得。训练过程最多进行50个训练轮次(epochs),并设置了早停机制:如果连续10个epoch没有准确率的提升,则提前终止训练。为了与超参数搜索设置保持一致,我们采用了一个两阶段的学习率调度策略:在前25个epoch中,权重学习率遵循之前描述的预热-余弦退火调度;之后,学习率保持在调度器的最终学习率不变。对于图2和图5中展示的结果,我们使用单个随机种子和最优超参数配置,将最大训练轮次数设置为50,并未启用早停机制。权重学习率调度方式与前述方法保持一致。
A.1 计算复杂度
在表6中,我们展示了在单个H100 GPU上使用反向传播(BP)、预测编码(PC)以及“脉冲精度+前向更新”(S + F)方法在各种任务中训练一个epoch所需的平均时间。为了消除数据集加载到内存中的开销,我们从第5个epoch开始计时,并计算连续五个epoch的平均持续时间。我们重复该测量过程五次,并报告这五次实验运行的平均值和标准差。值得注意的是,预测编码方法的运行时间受到一个实现瓶颈的影响:尽管理论上可以并行更新所有的神经活动,但我们的库目前不支持这一功能。这在训练深层架构时显著拖慢了我们的模型。
结果。从表中可以看出,PC和我们提出的S + F方法具有相当的训练时间,但两者都比BP慢,并且随着模型层数的增加,这种差距进一步扩大,主要归因于上述的实现瓶颈。在前向传播阶段,BP和PCNs(PC、S + F)执行相同的计算操作,因此计算复杂度相同。然而,在反向传播阶段,PCNs需要先更新神经元激活x,再更新权重W,其中x需要进行T次迭代更新。由于T的最优值总是等于或略大于网络层数,这进一步解释了为什么在模型深度增加时,PCNs相比BP会更慢,尽管这一问题不像操作完全并行化那样成为主要瓶颈。
B 模型中的能量传播
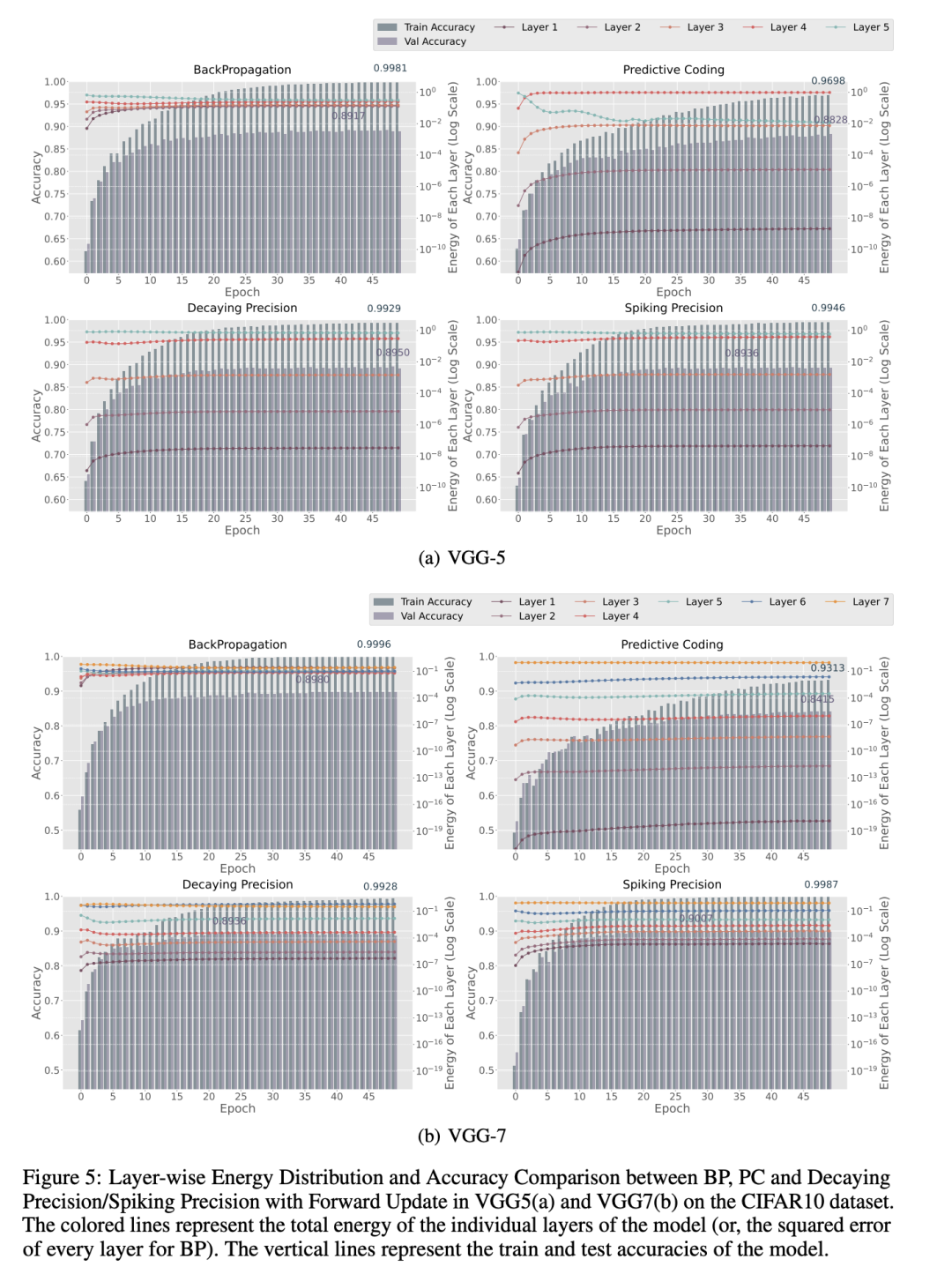
在本节中,我们特意从实验框架中选取了VGG5和VGG7架构,用于进行模型间能量分布的对比可视化。图5和图2展示了在CIFAR10数据集上,反向传播(BP)、预测编码(PC)、我们提出的“衰减精度+前向更新”(D + F)以及我们提出的“脉冲精度+前向更新”(S + F)这四种方法在VGG5(图5(a))、VGG7(图5(b))和VGG10(图2)架构下的各层能量分布和分类准确率。
在VGG5中,尽管四种方法表现出相当的准确率,但我们提出的方法在网络各层之间实现了比PC更优的能量平衡,从而证明了它们在提升模型逐层能量均衡方面的有效性。有趣的是,尽管PCNs的能量分布不如BP均匀,其表现依然良好。与VGG5中的能量传播相比,图5(b)和图2显示,当在VGG7/10架构中实现标准PC时,出现了显著的能量不平衡现象,这与测试准确率的下降密切相关。相比之下,我们提出的方法在深层网络中相较于标准PC保持了更优的能量平衡,同时实现了与BP相当甚至更优的测试准确率。
C 消融研究
在本节中,我们进行了消融研究,以评估每个所提出组件的有效性。这些实验使我们能够量化每个组件的独立贡献,以及它们组合使用时的协同效应。结果如表1所示。
首先,我们观察到,移除前向更新(使用带有衰减/脉冲精度的标准PC模型)会导致显著的准确率下降,且这种下降随着网络深度的增加而更加明显。同时,当移除前向更新时,中心 nudging(center nudging)的有效性重新显现出来,其影响在更深的网络中也更加显著,如图4所示。这一现象证实了我们之前的假设:基于xₗᵗ 的突触权重更新可能会引入跨层累积的误差,从而导致深层架构中的性能下降。
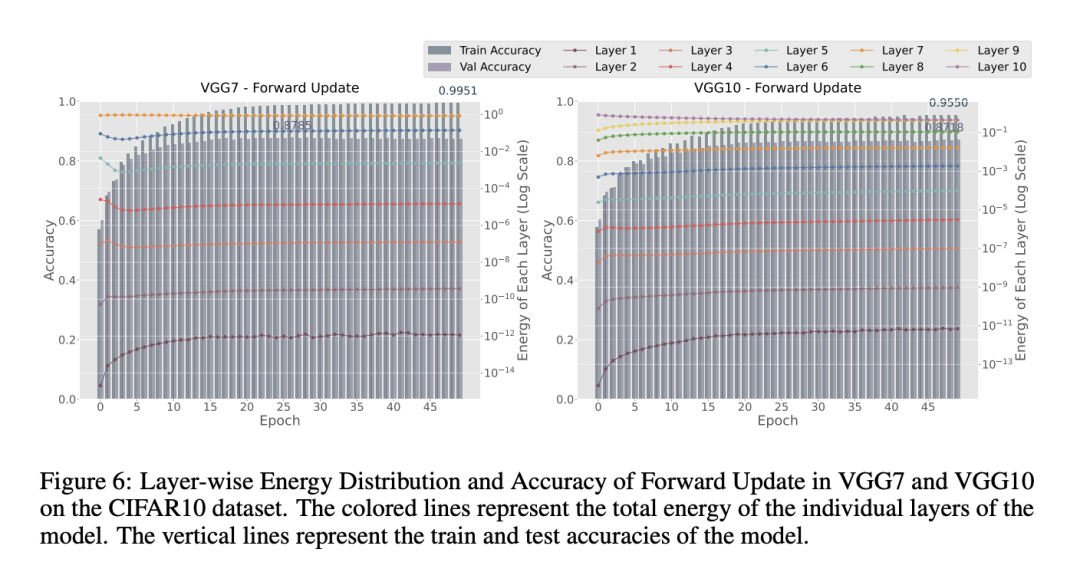
其次,我们观察到,在大多数情况下,移除衰减/脉冲精度模块会导致性能下降。这一效应在VGG7/10等深层模型中尤为明显,没有精度项时,各层之间的能量分布变得显著不平衡。如图6和图5所示,在VGG7架构中使用脉冲精度和前向更新的情况下,第一层的能量占比约为10⁻⁶,而在没有脉冲精度的模型中,该比例骤降至10⁻¹²。对使用衰减/脉冲精度+前向更新与仅使用前向更新之间的逐层能量分布可视化表明,我们提出的方法成功地平衡了各层之间的能量分布,从而提升了模型性能。
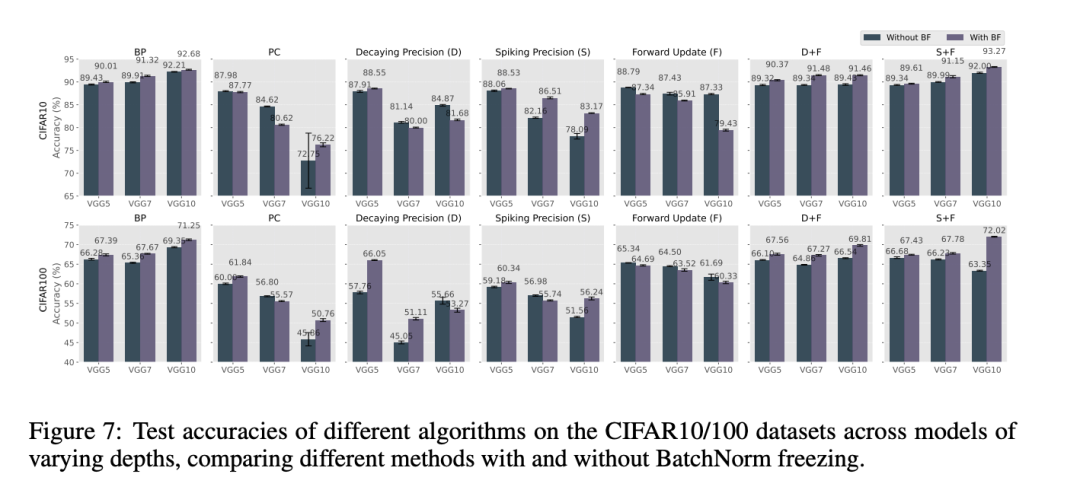
第三,我们发现,将BatchNorm冻结(BF)与我们的精度模块和前向更新机制结合使用时,能够显著提升模型性能。如图7所示,将BF与我们提出的方法(D + F 和 S + F)结合后,在所有网络深度以及CIFAR10和CIFAR100数据集上都一致提升了准确率。具体而言,在VGG10架构下,S + F 配置结合BF在CIFAR10上达到了93.27%的准确率,在CIFAR100上达到了72.02%,甚至超过了BP基线。相比之下,当将BF应用于标准PC或仅与前向更新结合时,大多数情况下我们观察到的是性能下降而非提升。对于仅使用衰减精度或脉冲精度但没有前向更新的模型,BF在不同网络深度下的效果不一致且难以预测。这些结果表明,我们所提出组件之间的协同作用至关重要——BF似乎只有在与我们的能量平衡机制(无论是衰减精度还是脉冲精度)以及前向更新机制共同使用时,才能稳定训练动态。这种协同作用使得深层网络在整个训练过程中保持稳定的梯度,从而实现更稳健的优化,最终获得更高的分类准确率。
shttps://arxiv.org/pdf/2506.23800#page=1.00&gsr=0
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号