GDDR7技术突破:边缘AI内存解决方案

GDDR7技术突破:边缘AI内存解决方案

数据存储前沿技术
发布于 2026-03-09 18:11:30
发布于 2026-03-09 18:11:30
阅读收获
- 技术选型决策依据:理解HBM、GDDR、LPDDR在不同AI场景下的技术定位,为边缘AI硬件设计提供了科学的内存技术选型框架。
- 先进封装经济性分析:掌握2.5D/3D封装技术的成本效益模型,明确标准封装方案在成本敏感场景下的巨大优势。
- 产业生态布局洞察:认识Cadence与Rambus等IP厂商的生态合作模式,理解从技术标准到量产落地的完整产业链协作机制。
全文概览
随着AI模型复杂度指数级增长,传统通用硬件正面临"内存墙"瓶颈。你是否注意到,从云端大规模训练到边缘智能推理,不同场景对内存带宽、功耗和成本的要求截然不同?
最新发布的GDDR7标准通过PAM3调制技术,将单引脚带宽提升至36-48 Gbps,总带宽达到1.15 Tbps,为AI推理提供了前所未有的性能表现。更关键的是,它在标准PCB工艺下实现了HBM级别的性能,成本却仅为后者的四分之一。
当Google TPU、AWS Trainium等定制ASIC正在重塑数据中心格局,边缘侧的ASIC化程度将达到70%。在这种背景下,GDDR7凭借"高带宽、低成本、标准封装"的三角平衡优势,正在成为500GB/s带宽需求下无可替代的最优解。这不仅是技术的突破,更预示着AI基础设施即将迎来从通用到专用、从云端到边缘的深刻变革。
👉 划线高亮 观点批注
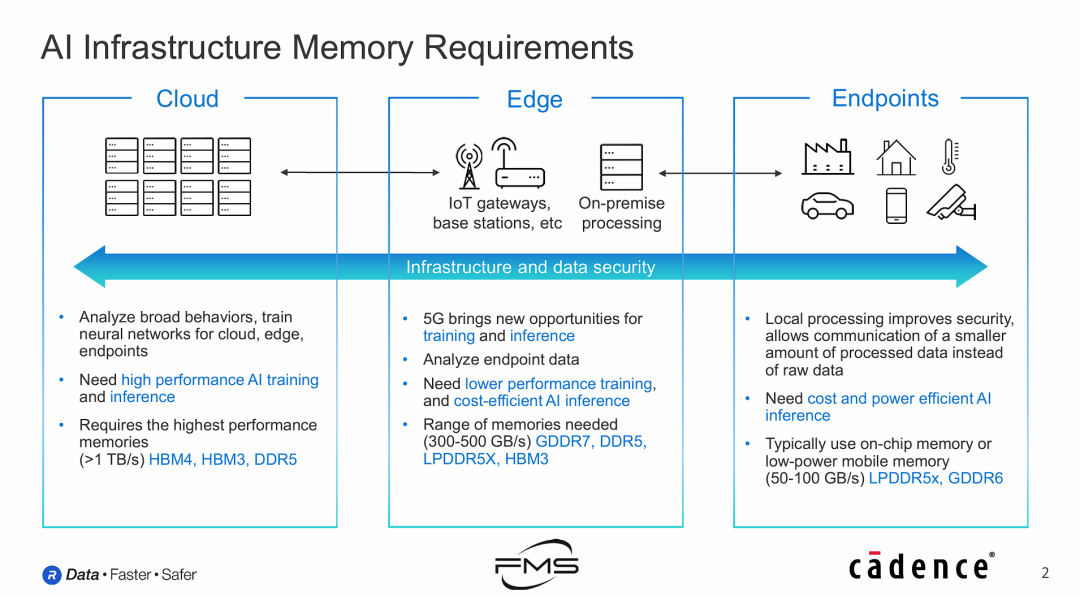
AI基础设施内存需求
AI基础设施内存需求
AI基础设施的不同层级(从云到端)对内存带宽、功耗、成本及技术标准有着截然不同的分级需求。
- 性能与带宽的递减趋势:
- 云端是算力中心,聚焦大规模训练,对带宽要求极高(>1 TB/s),必须采用HBM等昂贵的顶级显存技术。
- 边缘侧起承上启下作用,带宽需求中等(300-500 GB/s),技术选择最为多样化(混合了GDDR、DDR、LPDDR甚至部分HBM)。
- 终端聚焦应用和推理,带宽需求最低(50-100 GB/s),但对功耗和成本极其敏感。
- 技术标准的特定适用场景:
- HBM系列 (HBM3/4):主要统治云端高性能计算领域。
- GDDR/DDR系列:在边缘侧和部分高性能终端作为主力。
- LPDDR系列:凭借低功耗特性,主导终端设备及部分边缘设备。
- 计算重心的转移:
- 云端侧重于“训练”(Training)。
- 边缘与终端逐渐侧重于“推理”(Inference)以及数据的本地化预处理,强调数据安全性和传输效率(只传结果不传原始数据)。
- 未来技术演进:图中提及了 HBM4 和 GDDR7,暗示了行业对下一代更高带宽存储标准的迫切需求,以支持日益复杂的AI模型。
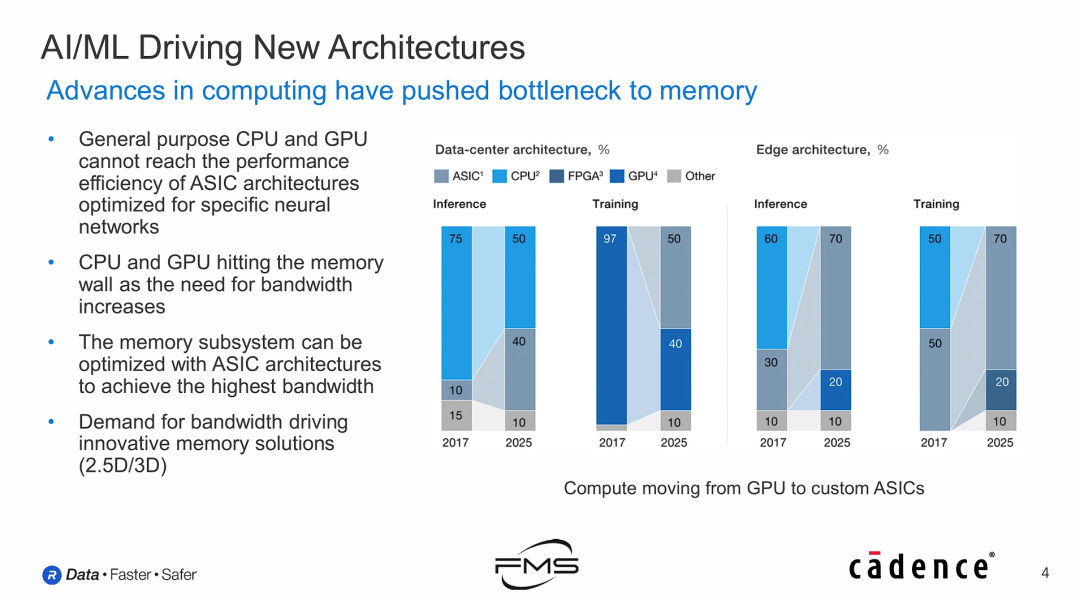
AI/ML正在驱动新的架构
AI/ML正在驱动新的架构
为了突破“内存墙”并提升AI计算效率,计算架构正经历从通用硬件(CPU/GPU)向定制化专用硬件(ASIC)的巨大转型,这直接推动了先进封装(2.5D/3D)和新型内存技术的发展。
- “内存墙”是核心驱动力:明确指出计算性能的瓶颈已不再是算力本身,而是内存带宽。传统的CPU/GPU架构在应对海量AI数据吞吐时,受限于内存带宽,效率不如定制化芯片。
- ASIC的崛起(数据中心侧):
- 在AI训练领域,GPU不再一家独大,Google TPU、AWS Trainium等定制ASIC将在2025年占据半壁江山。
- 在AI推理领域,ASIC也在逐步蚕食CPU的市场份额。
- 边缘侧的ASIC化更为彻底:边缘计算对功耗和效率更敏感,因此预测到2025年,边缘侧的训练和推理将由ASIC占据绝对主导地位(约70%),通用CPU将退居次席。
- 硬件形态的演进:为了配合ASIC实现高带宽,单纯的芯片设计不够,必须结合 2.5D/3D 等先进封装技术,通过缩短内存与计算单元的物理距离来提升带宽密度。
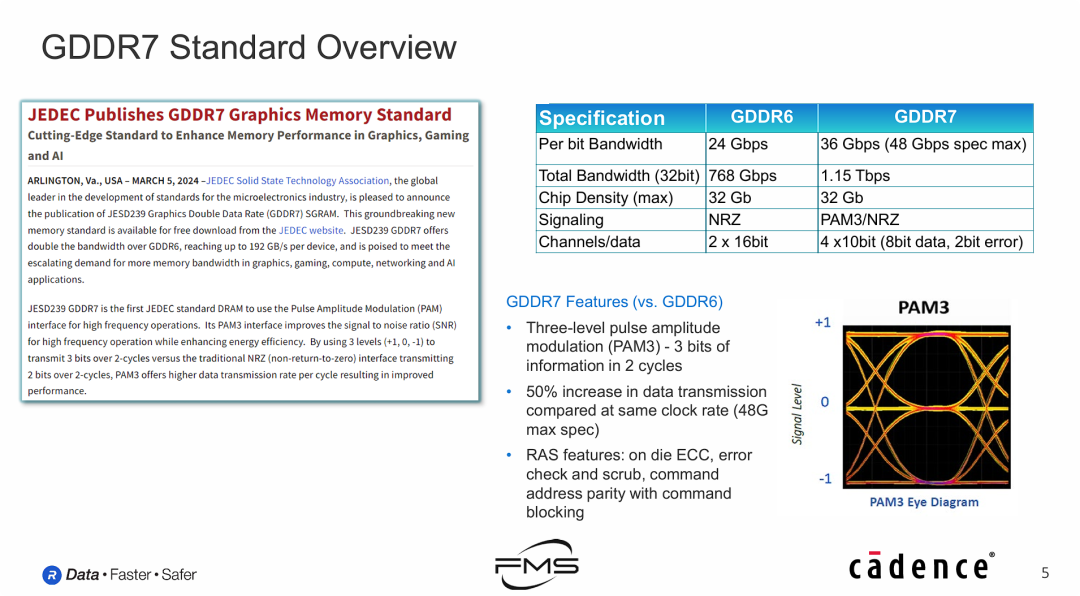
GDDR7 技术参数全览
GDDR7 技术参数全览
- 左侧新闻摘要
- 展示了JEDEC发布GDDR7显存标准的公告(2024年3月5日)。
- 核心亮点:首个使用PAM3(脉冲幅度调制)接口的JEDEC标准DRAM,旨在提升高频操作下的信噪比,提升能效。
- 右上表格:GDDR6 vs GDDR7 规格对比
- Per bit Bandwidth(单引脚带宽):GDDR6为24 Gbps;GDDR7提升至 36 Gbps(最高规格可达 48 Gbps)。
- Total Bandwidth(总带宽):在32bit位宽下,GDDR6为768 Gbps;GDDR7提升至 1.15 Tbps。
- Chip Density(最大容量密度):两者目前单颗最大均为 32 Gb。
- Signaling(信号编码):GDDR6使用传统的NRZ(不归零码);GDDR7引入了 PAM3/NRZ。
- Channels(通道数):GDDR6是 2 x 16bit;GDDR7变为 4 x 10bit(括号注明:8bit数据 + 2bit错误校验/ECC),通道更加细分以提升并发效率。
- 右下区域:GDDR7 关键技术特性
- PAM3 调制技术:这是GDDR7最大的技术变革。相比于NRZ(2个电平传1bit),PAM3使用3个电平(+1, 0, -1),能在2个时钟周期内传输3 bit信息。
- 效率提升:在相同时钟频率下,数据传输量提升 50%。
- RAS Features(可靠性特性):引入了片上ECC(On-die ECC)、错误检查与清理(Error check and scrub)、命令地址奇偶校验(Command address parity)等功能,极大增强了在高频运行下的数据可靠性。
- 眼图(Eye Diagram):右侧展示了PAM3的信号眼图,清晰可见三个电平状态。
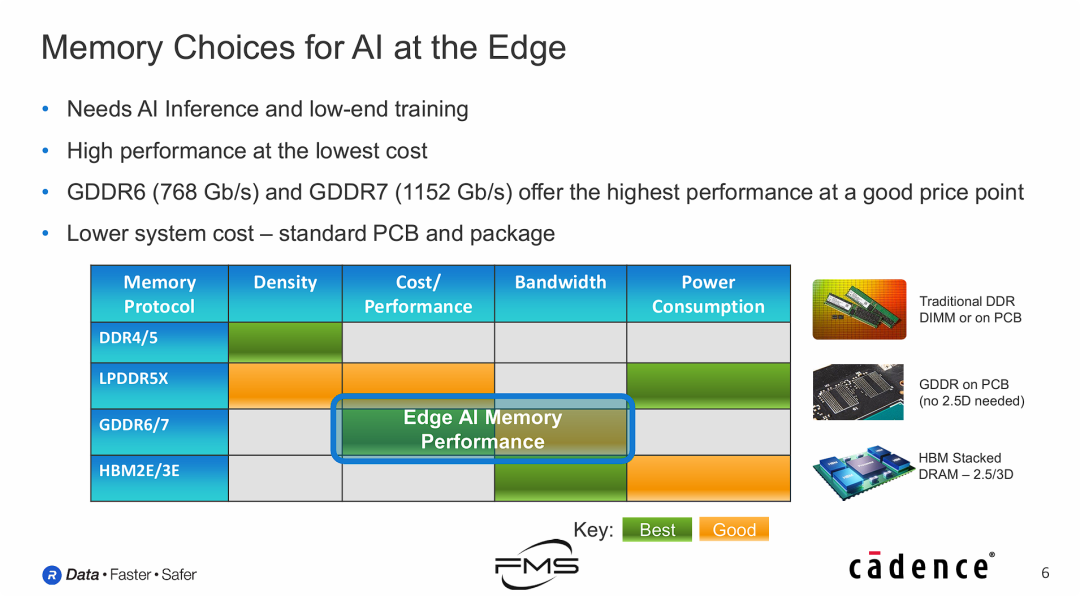
边缘AI的内存选择
边缘AI的内存选择
在边缘AI(Edge AI)市场,GDDR6/7 凭借“高带宽、低成本、标准封装”的三角平衡,优于DDR和HBM,或许是最佳选择。
- HBM的局限性:虽然HBM(如HBM3)带宽最高且能效极好,但其依赖昂贵的 2.5D/3D 封装,对于成本敏感的边缘设备(如基站、监控、网关)来说太过奢侈。
- DDR的瓶颈:传统的DDR4/5虽然容量大且便宜,但带宽不足,无法满足AI推理对数据吞吐的高要求。
- GDDR的胜利:
- 无需先进封装:GDDR可以使用标准的PCB制造工艺,大幅降低了系统级成本。
- 性能达标:GDDR7提供的 1.15 Tbps 带宽足以应付绝大多数边缘侧的推理和轻量级训练任务。
- 性价比之王:在图表的“Cost/Performance”一栏中,GDDR是唯一的“最佳”选项。
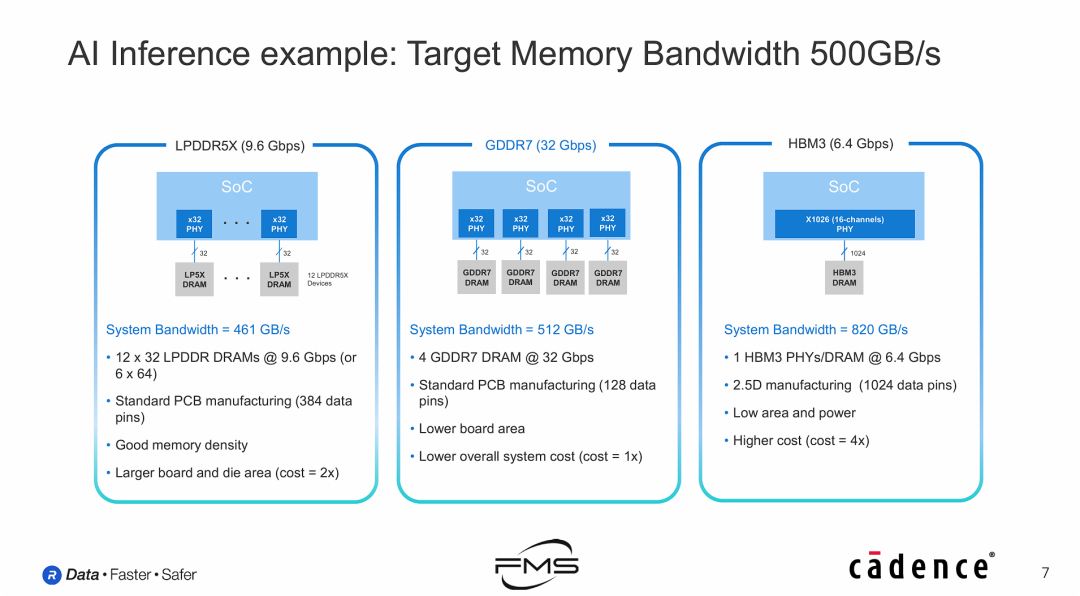
AI推理示例:目标内存带宽 500GB/s
AI推理示例:目标内存带宽 500GB/s
在500 GB/s这一典型的边缘AI带宽需求下,GDDR7是唯一在性能、成本和工程复杂度上实现完美的“甜蜜点(Sweet Spot)”的技术。
- LPDDR5X 的“堆料”困境:虽然单颗便宜,但为了凑够带宽,必须堆砌数量巨大的芯片(12颗),导致PCB布线极其复杂(384个引脚),最终导致系统级成本反而比GDDR7贵一倍(2x),且带宽仍勉强(461 GB/s)。
- HBM3 的“杀鸡用牛刀”:虽然HBM3性能强悍(820 GB/s)且面积小,但其昂贵的2.5D封装工艺导致成本飙升至GDDR7的4倍(4x)。对于500 GB/s的需求来说,这是严重的性能过剩和成本浪费。
- GDDR7 的“精准打击”:
- 数量少:仅需4颗芯片即可达标。
- 工艺成熟:标准PCB工艺,无需先进封装。
- 成本最低:定义为1x基准成本。
- 结论:GDDR7以最少的器件数量、最简单的工艺,精准满足了带宽需求,是该场景下的最优解。
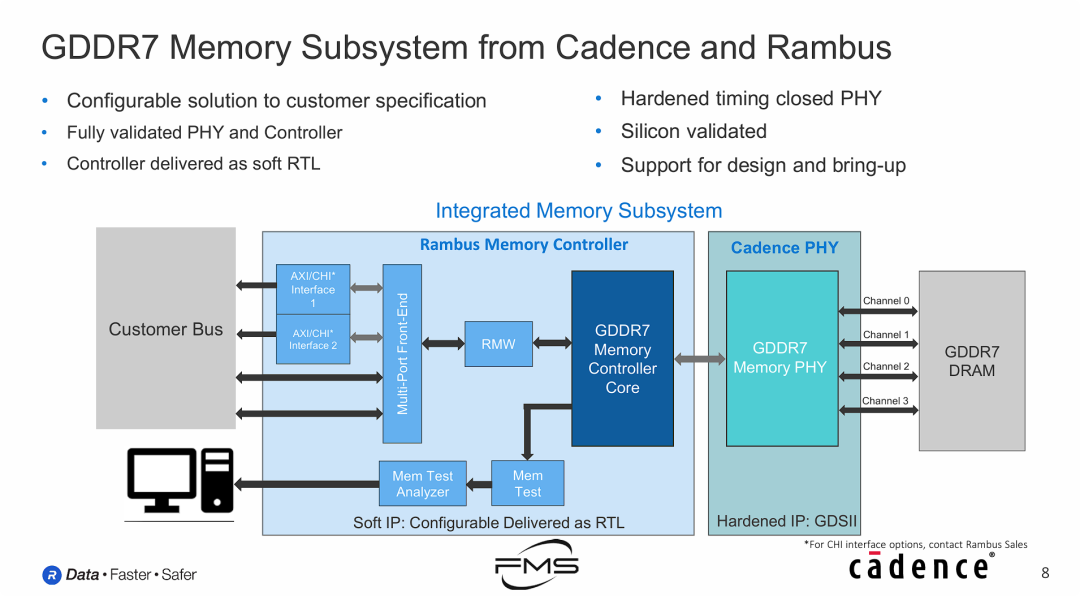
来自Cadence和Rambus的GDDR7内存子系统
来自Cadence和Rambus的GDDR7内存子系统
GDDR7不仅仅是一个标准,行业内已经有了成熟的、经过硅验证的IP解决方案,芯片设计公司(客户)可以立即着手设计集成GDDR7的ASIC芯片。
- “软硬”结合的生态分工:
- Rambus 负责逻辑层面的“软核”(控制器),处理复杂的协议和数据调度,提供灵活性。
- Cadence 负责物理层面的“硬核”(PHY),解决最困难的高速信号完整性(Signal Integrity)和时序问题,确保PAM3信号在几十Gbps的高速下稳定传输。
- 降低设计门槛:
- 对于想做边缘AI芯片(如Image 1和Image 3中提到的ASIC)的厂商来说,不需要自己从头设计复杂的GDDR7接口。只需购买这个打包的子系统方案,通过标准的AXI/CHI接口连接自己的NPU/CPU即可。
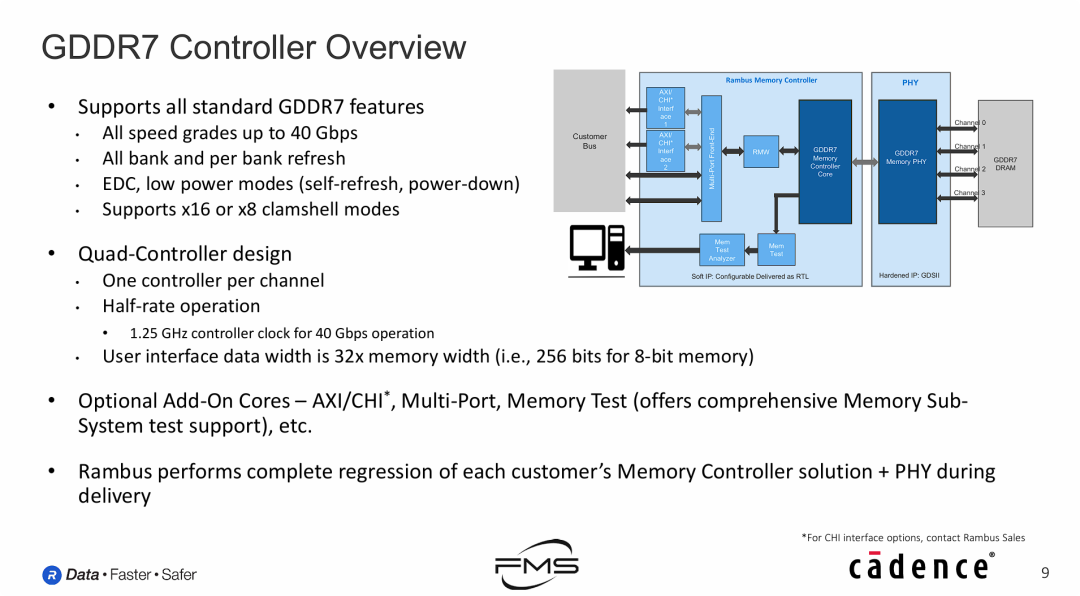
GDDR7 控制器概览
GDDR7 控制器概览
Rambus 的 GDDR7 控制器通过“四核并行”和“宽位宽低频率”的架构设计,成功解决了 40 Gbps 极高速率下的逻辑处理难题,同时支持大容量(Clamshell)和高可靠性(EDC)特性,非常适合AI芯片集成。
- 架构与标准的完美映射:
- GDDR7标准的一大变化是变成了4个独立通道(4 x 10bit)。Rambus控制器直接采用 Quad-Controller 设计,实现了1对1的精准控制,最大化了并行效率。
- 解决“速度与功耗”的矛盾:
- 外部传输高达 40 Gbps,如果内部逻辑也跑这么快,芯片会过热且无法制造。
- 该控制器通过 32倍位宽扩展(User Interface width is 32x),将内部时钟降至 1.25 GHz。这意味着它用极宽的内部总线(256 bit) 来“从容”地吞吐外部的高速数据流,保证了ASIC设计的可行性和低功耗。
- 面向AI场景的优化:
- Clamshell模式的支持是关键亮点。AI推理往往需要大显存来装载大模型,通过Clamshell模式,厂商可以在不改变接口位宽的情况下将显存容量翻倍(例如从16GB翻倍到32GB),这对边缘AI设备极具吸引力。
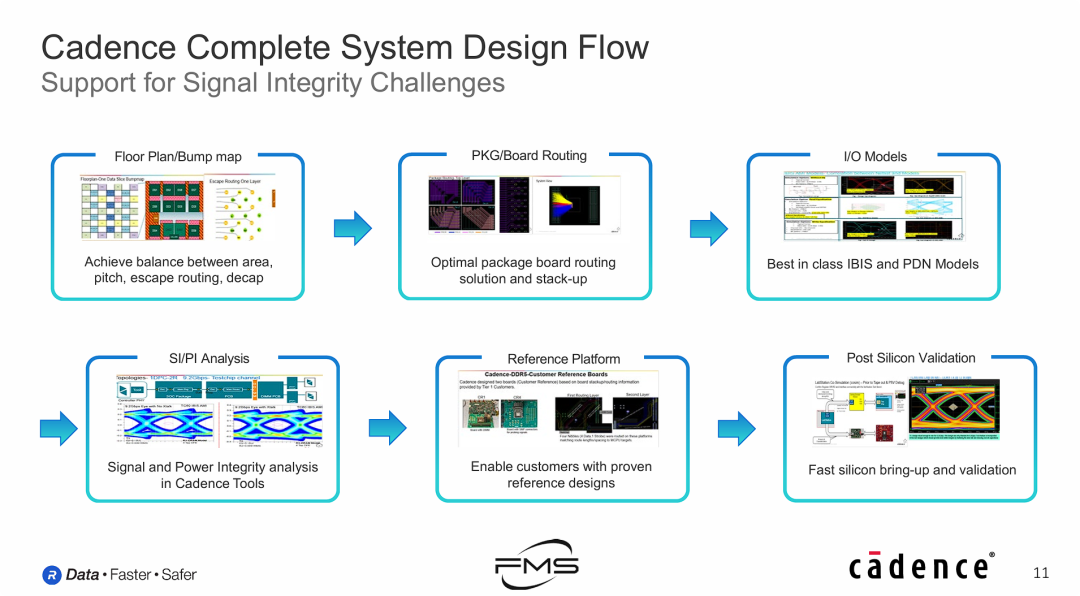
Cadence完整系统设计流程
Cadence完整系统设计流程
针对GDDR7带来的极大信号完整性挑战,Cadence不仅仅提供IP核,还提供从“芯片规划”到“仿真分析”再到“硬件验证”的全套设计方法学工具链,确保客户能把芯片“做成”且“好用”。
- SI/PI是GDDR7设计的“拦路虎”:
- 图片通篇围绕“Signal Integrity”(信号完整性)和“Power Integrity”(电源完整性)展开。暗示了在32Gbps+的速率和PAM3调制下,信号非常脆弱,没有强大的EDA工具和流程支持,芯片很难成功。
- “工具+IP”的闭环优势:
- Cadence作为EDA巨头,将其工具优势(Simulation, Routing)与IP产品结合。客户不仅买到了Rambus/Cadence的IP,还买到了确保这些IP能正常工作的设计环境。
- 降低工程落地风险:
- 通过提供高精度的仿真模型(IBIS/PDN)和实物的参考设计(Reference Platform),Cadence帮助客户规避了高频PCB设计的深坑,缩短了产品上市时间(Time-to-market)。

总结回顾
总结回顾
- 需求驱动:高级AI应用正在通过算法的演进,对内存带宽提出远超以往的巨大需求。
- 市场增长:AI推理(Inference) 是一个正在快速增长的市场细分领域,特别是在网络边缘(Edge)和终端(Endpoints)侧。
- 最佳平衡:GDDR6 和 GDDR7 为AI推理提供了带宽、成本和密度之间的最佳权衡(Best trade-off)。这是全篇的核心论点——既不像HBM那样昂贵,也不像LPDDR那样带宽受限。
- 生态合作:Cadence和Rambus紧密合作,通过测试芯片(test chip)和系统验证,确保护航GDDR6/7系统的最佳性能。
- 完整子系统:双方联合提供完整的、经过验证的 GDDR6/7 PHY(物理层)和 Controller(控制器)内存子系统 IP。
- 设计服务:Cadence不仅仅卖IP,还提供PCB和封装设计支持(PCB and package design support),帮助客户解决“最后一公里”的工程落地问题。
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- 在AI计算从"算力为王"转向"内存带宽为王"的变革中,你认为传统CPU/GPU厂商应该如何调整产品策略,以应对ASIC的全面崛起?
- 考虑到边缘AI对成本、功耗和性能的三角平衡要求,你预测除了GDDR7之外,还会有哪些新兴内存技术在这个细分市场中获得突破性发展?
- 从产业链协同的角度来看,你觉得IP供应商、系统集成商和最终设备厂商之间应该建立怎样的合作模式,才能加速GDDR7等先进内存技术在AI推理市场的大规模落地应用?
原文标题:GDDR Memory for High-Performance AI Inference[1]
Notice:Human's prompt, Datasets by Gemini-3-Pro
#FMS25 #端侧推理
---【本文完】---
👇阅读原文,搜索🔍更多历史文章。

丰子恺-护生画集-杨枝净水
- https://files.futurememorystorage.com/proceedings/2025/20250807_DRAM-303-1_Kamath.pdf ↩
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号