Nat. Mach. Intell. | 蛋白质–蛋白质相互作用推断模型中使用预训练蛋白质语言模型的一个缺陷

Nat. Mach. Intell. | 蛋白质–蛋白质相互作用推断模型中使用预训练蛋白质语言模型的一个缺陷

DrugAI
发布于 2026-03-03 17:29:08
发布于 2026-03-03 17:29:08
DRUGONE
随着预训练蛋白质语言模型(protein language models, pLMs)的广泛应用,越来越多基于 pLM 的方法被用于蛋白质–蛋白质相互作用(PPI)推断任务。本文系统识别并验证了一个关键问题:现有预训练 pLM 可能成为下游 PPI 任务中的数据泄漏来源。研究人员通过构建“严格(strict)”与“非严格(non-strict)”两种预训练数据集,对小型高效 pLM 进行训练和比较,从而量化数据泄漏对模型性能的影响。结果表明,若预训练阶段包含下游 PPI 测试蛋白,模型测试性能会显著虚高。然而,这种泄漏现象并不会同样程度地影响非配对任务,如蛋白关键词注释。此外,研究人员未发现 pLM 的上下文长度与长蛋白 PPI 预测性能之间存在显著关联。进一步实验表明,无论基于 pLM 还是传统方法的模型,在人类–SARS-CoV-2 跨物种 PPI 推断以及点突变对结合亲和力影响预测等任务上均无法有效泛化。该研究强调了在评估 pLM-based PPI 模型时建立更严格数据协议的重要性,并揭示了当前模型的关键局限。

蛋白质语言模型近年来成为推动蛋白功能预测和相互作用推断的重要工具。其能够将蛋白序列编码为高维向量表示,成为构建 PPI 推断模型的理想特征来源。然而,PPI 推断领域长期存在数据泄漏与泛化能力不足的问题。早期研究已指出,当训练集与测试集共享蛋白或高度相似序列时,模型性能会被严重高估。
由于当前主流 pLM 多在 UniRef 等大规模数据库上预训练,而这些数据库往往包含下游 PPI 任务中的测试蛋白,因此预训练阶段可能已经暴露了测试信息。考虑到 pLM 通常占据下游模型绝大多数参数,其对数据泄漏的放大效应尤为值得关注。本研究系统评估这一问题,并探索其对不同任务的影响程度。
预训练数据泄漏对 PPI 性能的影响
研究人员首先比较多种主流 pLM 作为编码器时的 PPI 推断性能,发现 pLM-based 模型显著优于非 pLM 方法。随后,为验证数据泄漏假设,研究人员设计并训练了一种高效小型 pLM——SqueezeProt,并构建两种预训练版本:
- Strict 版本:剔除所有出现在 PPI 测试与验证集中的蛋白及其高度相似序列;
- Non-strict 版本:包含上述蛋白。
两者训练规模一致,仅在是否包含测试蛋白上存在差异。实验结果显示,在 C3 严格划分的 PPI 数据集上,非严格版本显著优于严格版本。例如 MCC 指标平均提升超过 11%。随着训练–测试序列相似性阈值降低,该差距依然存在,证明性能差异确实源于预训练阶段的数据泄漏。
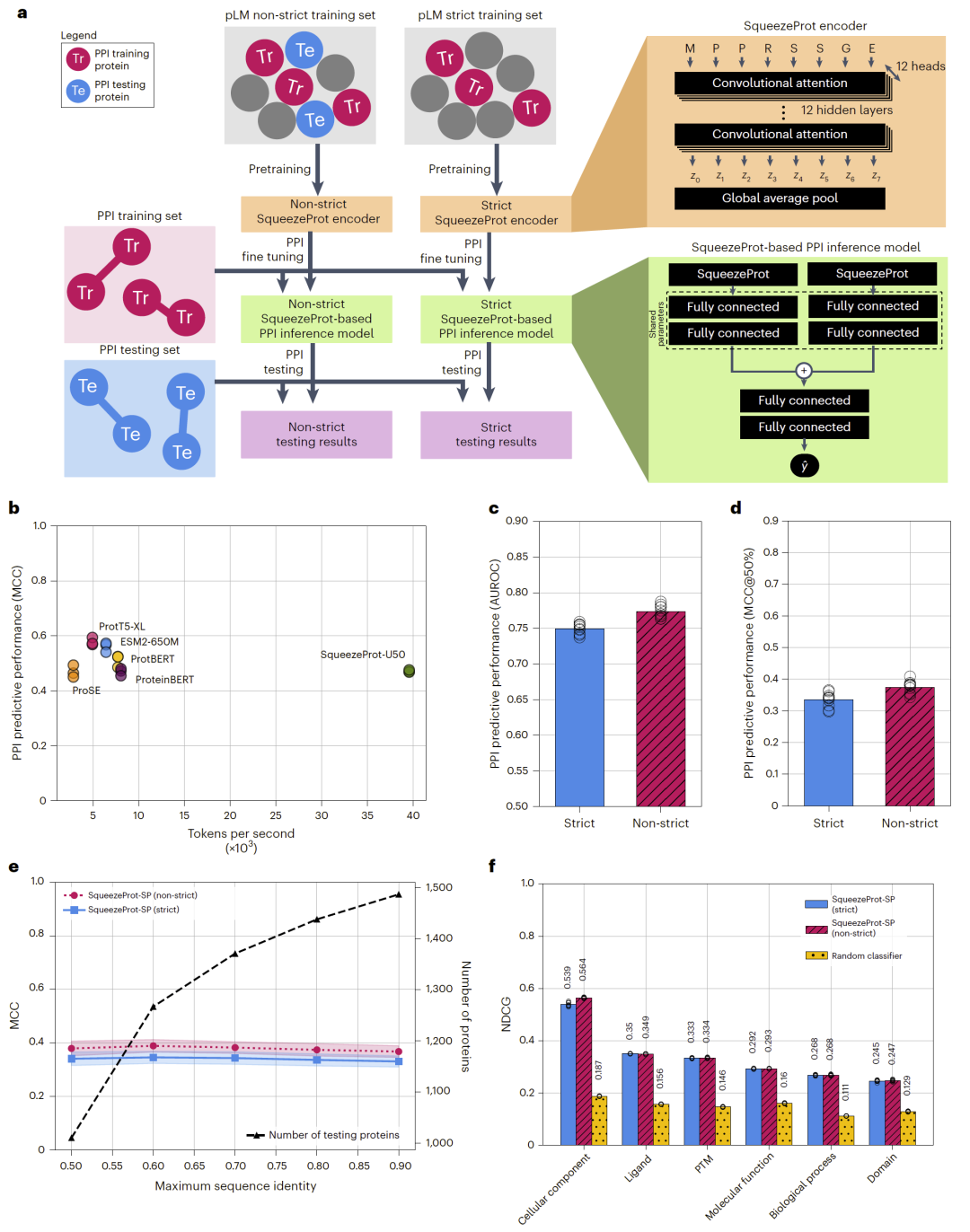
图1:严格与非严格预训练流程及性能比较。
数据泄漏是否影响其他任务?
研究人员进一步测试该泄漏现象是否影响非配对任务,例如 UniProt 关键词预测。实验结果表明,除了“细胞组分”类别外,严格与非严格版本在大多数关键词分类指标上差异不显著。这说明数据泄漏的严重程度依赖于下游任务的性质,配对任务(如 PPI)更容易受到影响。
pLM-based PPI 模型预测趋同现象
尽管不同 pLM 在架构与训练数据上差异较大,但研究人员发现,各 pLM-based PPI 模型在测试集上的预测结果高度一致。通过 Cohen’s κ 系数与技能归一化一致性指标分析,模型之间存在显著预测趋同性。网络拓扑分析进一步表明,推断得到的蛋白度分布与真实 PPI 网络高度相关。这意味着当前多种 pLM-based 模型在 PPI 推断任务上可能学习到类似的模式。
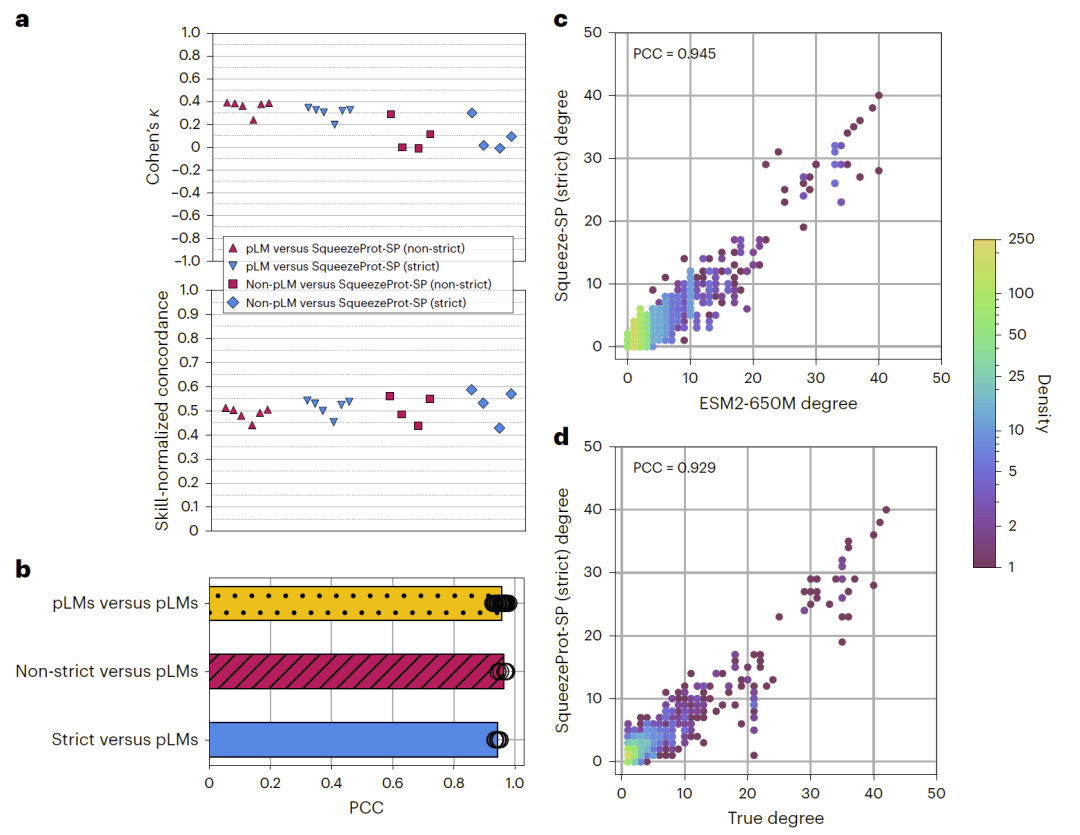
图2:不同 pLM 模型预测一致性分析。
上下文长度对长蛋白预测的影响
由于 Transformer 架构的计算复杂度限制,pLM 通常设置固定上下文长度(例如 512)。然而,许多蛋白序列长度远超该限制。研究人员将测试蛋白对按序列长度分组分析,结果显示模型性能并未随蛋白长度显著变化。即便对超出上下文长度的序列采用截断或随机窗口策略,性能变化仍然有限。这表明当前 pLM 可能已从局部序列中提取足够信息用于 PPI 推断。
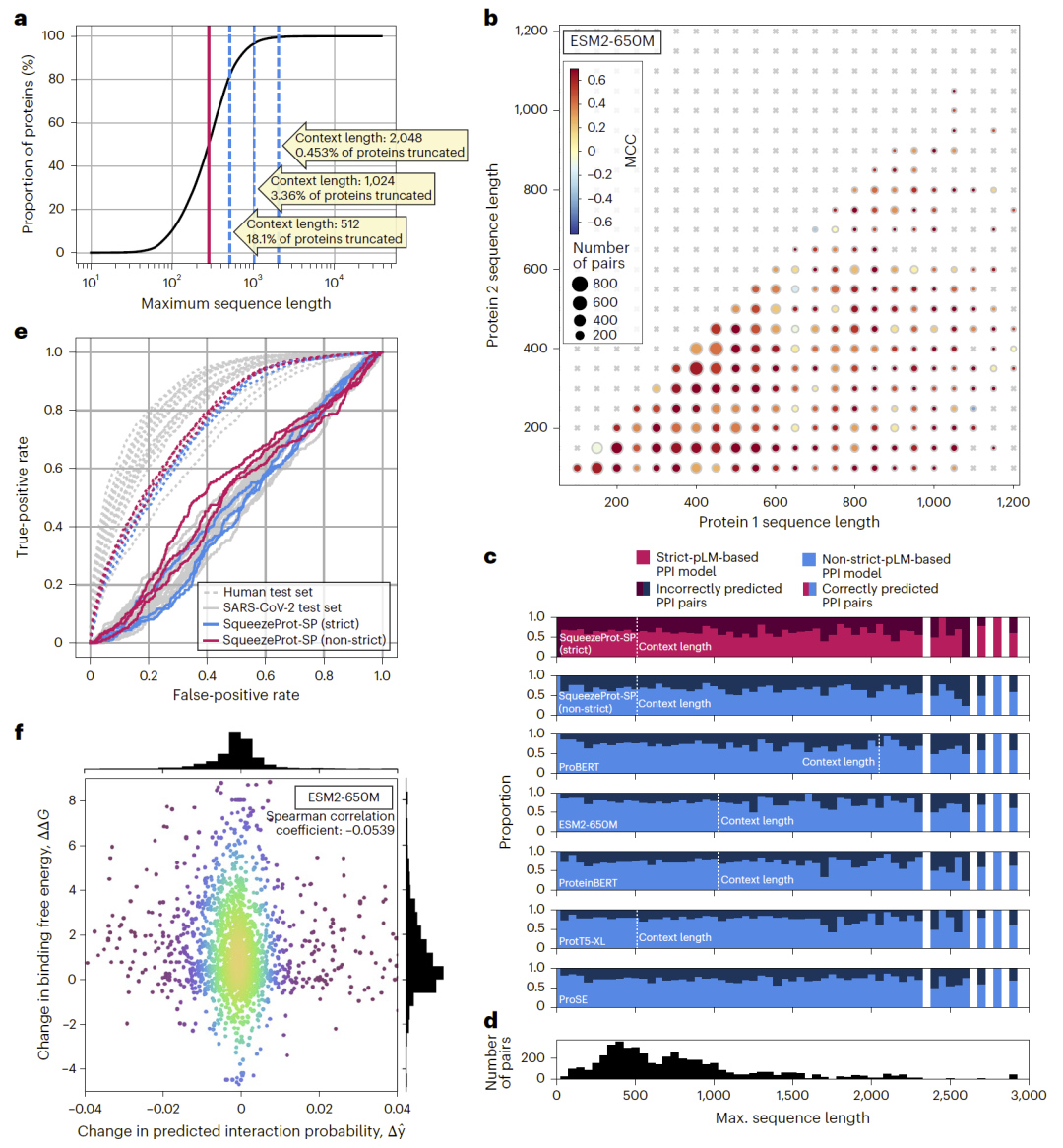
图3:蛋白长度与预测性能关系。
跨物种泛化能力:人类–SARS-CoV-2 PPI
研究人员测试模型在人类–SARS-CoV-2 跨物种 PPI 任务上的表现。结果显示,无论是六种主流 pLM-based 方法,还是传统基线方法 RAPPPID,其性能均接近随机水平。这说明当前模型在远离训练分布的场景下缺乏泛化能力。
对点突变敏感性分析
在现实生物系统中,单个氨基酸突变即可显著改变结合亲和力。研究人员利用 SKEMPI 数据库分析预测概率变化与真实结合自由能变化之间的相关性。结果显示几乎不存在显著相关性,Spearman 系数接近零。这说明当前 PPI 模型对细微但重要的序列变化不敏感。
讨论
本研究揭示了预训练 pLM 在 PPI 推断中的一个关键缺陷:预训练阶段包含测试蛋白会导致评估性能虚高。研究人员建议未来应:
- 在严格排除测试蛋白的前提下进行预训练;
- 开发更高效、可重复训练的 pLM 架构;
- 探索“机器遗忘”等技术以消除污染数据影响;
- 融合结构信息提升泛化能力。
此外,当前 PPI 数据库本身存在偏向稳定、常见相互作用的问题,对组织特异性或瞬时相互作用的建模仍有待提升。
总体而言,尽管 pLM-based 模型在标准数据集上表现优越,但在跨物种预测与突变敏感性等关键场景下仍存在系统性局限。研究人员强调,在大规模基础模型时代,更严格的数据划分与评估协议应成为标准实践。
整理 | DrugOne团队
参考资料
Szymborski, J., Emad, A. A flaw in using pretrained protein language models in protein–protein interaction inference models. Nat Mach Intell (2026).
https://doi.org/10.1038/s42256-025-01176-7

内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号