Nature | 发现式学习: 基于极少实验快速预测电池循环寿命

Nature | 发现式学习: 基于极少实验快速预测电池循环寿命

DrugOne
发布于 2026-03-02 19:19:51
发布于 2026-03-02 19:19:51
电池新设计的寿命评估通常需要长时间实验与高能耗测试,严重制约技术创新进程。现有寿命预测方法依赖大量目标设计的寿命标注数据,且往往必须在原型制造完成后才能给出可靠预测。
研究人员提出了一种名为发现式学习(Discovery Learning)的科学机器学习框架,将主动学习、物理引导学习与零样本学习整合进类似人类推理的闭环流程中。该方法能够利用历史电池数据,在极少实验条件下预测新型电池设计的循环寿命。在包含123个工业级大容量锂离子软包电池的数据集上,发现式学习仅利用部分电池前50个循环的信息,即可实现约7.2%的寿命预测误差,同时在时间与能耗成本上分别节省约98%与95%。该方法为高效电池寿命评估提供了新路径,也为AI加速科学发现展示了重要潜力。

开发高寿命电池对于电动车和储能系统至关重要,但传统寿命测试往往需要数年时间,并消耗大量能源,成为电池技术进步的重要瓶颈。基于物理模型的方法虽然试图通过退化机理建模进行预测,但由于相关机制仍存在不确定性,难以达到稳定可靠的精度。近年来,数据驱动方法借助机器学习取得了一定进展,但仍高度依赖目标体系的大规模寿命标注数据,并且在面对材料体系或结构设计发生变化时容易受到分布偏移影响,从而导致泛化性能显著下降。在科学机器学习领域,这种“数据难以获取”和“分布偏移”问题尤为突出,使得AI模型难以在真实工程场景中高效应用。
发现式学习的核心思想
为解决上述问题,研究人员借鉴教育心理学中的发现学习理论,提出通过类似人类推理的方式,将历史知识转化为新问题的预测能力。发现式学习由三个协同模块构成:学习者负责通过主动学习从未标注的新电池设计中选择最具信息量的样本;解释器基于物理引导学习,将早期循环数据映射到统一且可解释的物理特征空间,以缩小历史电池与新设计之间的差异;预言机则在不依赖新寿命实验的情况下,仅利用历史数据进行零样本预测,并生成寿命“伪标签”供学习者进一步优化推理过程。三者形成一个不断迭代的闭环系统,使模型能够在极低实验成本下逐步提高预测精度。
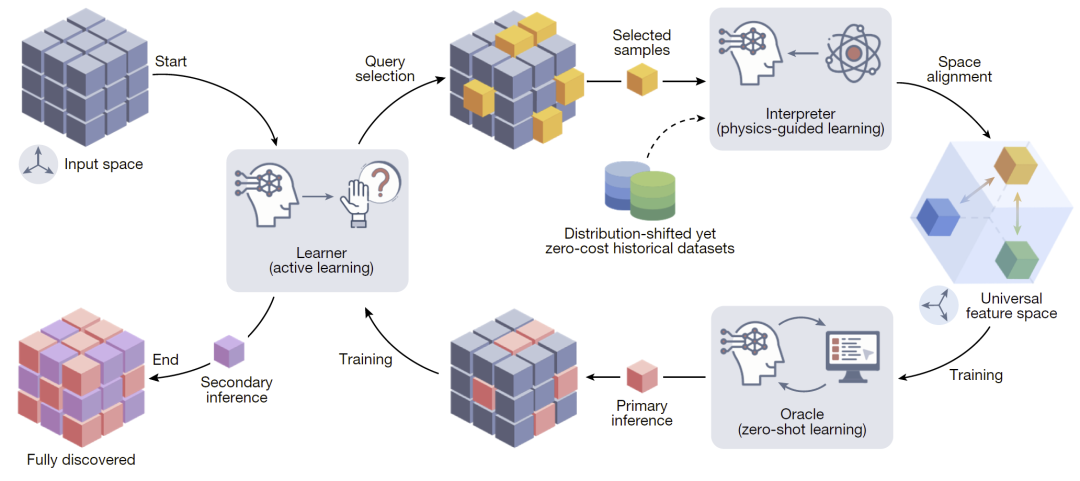
图1:发现式学习整体框架。
工业级电池数据构建
为了验证该方法的有效性,研究人员构建了一个高质量的工业级老化数据集,包含123个大容量锂离子软包电池,覆盖多种正负极材料组合与结构设计,并在不同温度与充放电协议条件下进行循环测试。电池循环寿命分布在约250至1700次之间,充分体现了真实工业场景中的复杂性。同时,模型训练阶段仅使用公开的小容量圆柱电池数据集作为历史知识来源,这些电池在材料体系、结构参数和制造工艺上与测试电池存在显著差异,从而构成一个典型的跨分布预测任务。这种设置进一步突出了问题的挑战性。
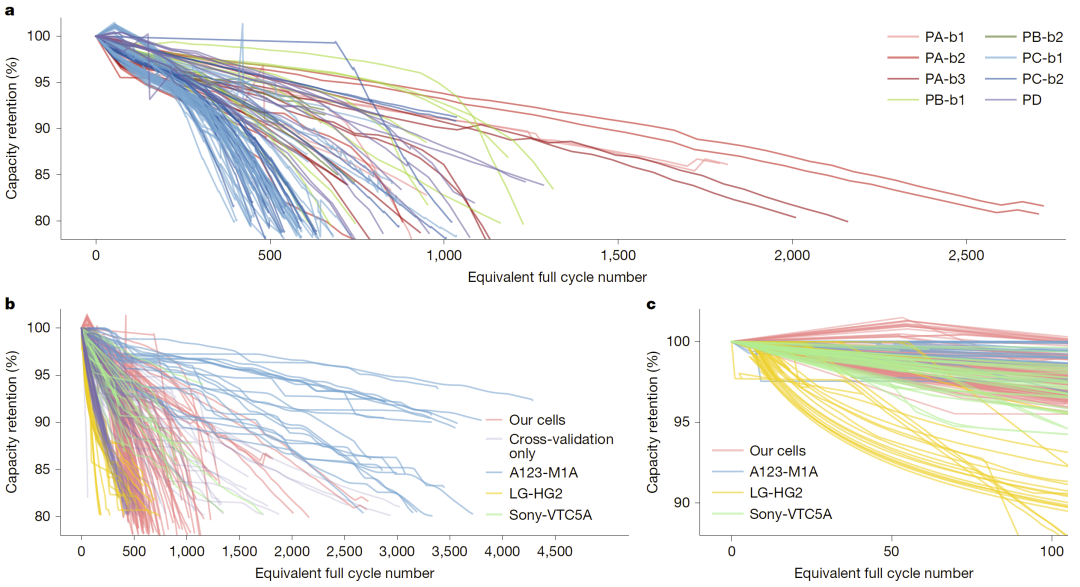
图2:工业级大容量电池与公开数据集的老化行为对比。
开放环预测性能
在不引入主动学习反馈的情况下,研究人员首先评估了解释器与预言机构成的开放环预测能力。结果显示,该模型在电池组平均寿命预测上的误差约为6.4%,在单电池层面误差约为9.1%,预测值与真实寿命之间具有极高相关性。进一步的可解释分析表明,早期循环阶段的一系列物理特征,如活性材料体积分数、锂化学计量状态变化以及界面膜阻抗演化等,对寿命预测起到了关键作用,而且这些特征的重要性会随温度和倍率条件发生变化,与已知的电池退化机理高度一致。这说明发现式学习不仅具有较高精度,也具备良好的物理合理性。
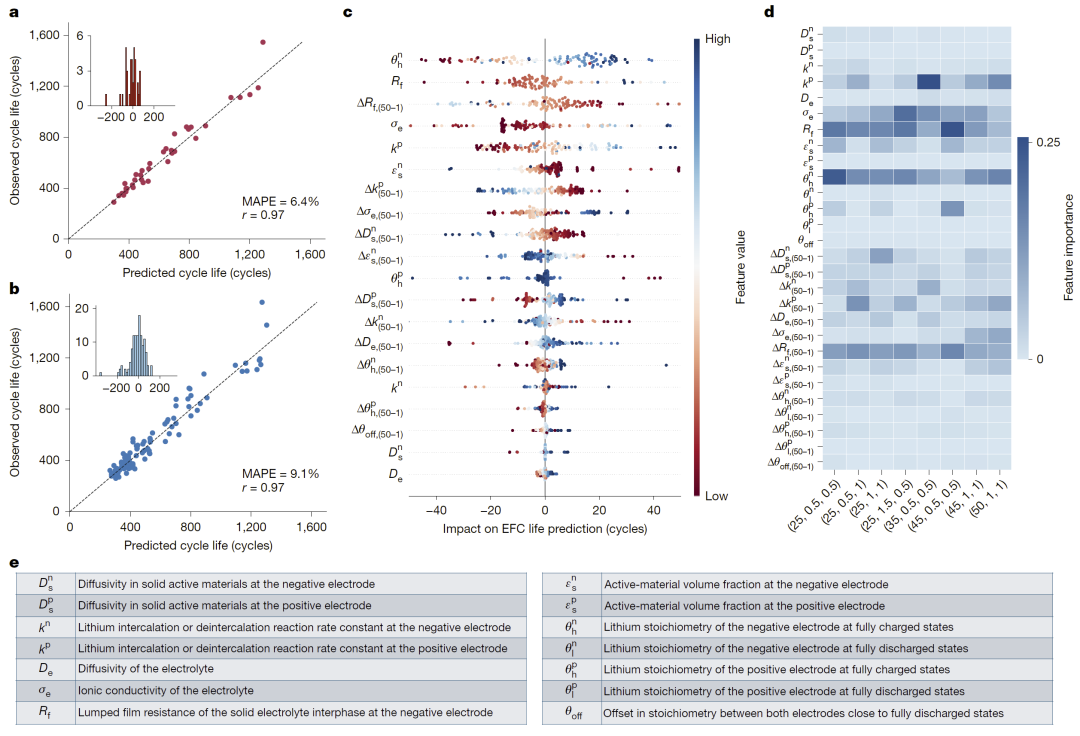
图3:开放环预测结果与关键物理特征贡献分析。
闭环学习与实验成本降低
在引入学习者进行主动样本选择后,发现式学习进一步进入闭环推理模式。模型仅对约一半的电池组进行早期循环实验,其余样本完全依赖模型推断预测寿命。最终整体预测误差约为7.2%,与开放环结果接近,但实验需求却大幅减少。通过这种以“伪标签推理”替代真实寿命标注的方式,发现式学习成功突破了传统主动学习对高成本实验数据的依赖,实现了在高精度与高效率之间的平衡。
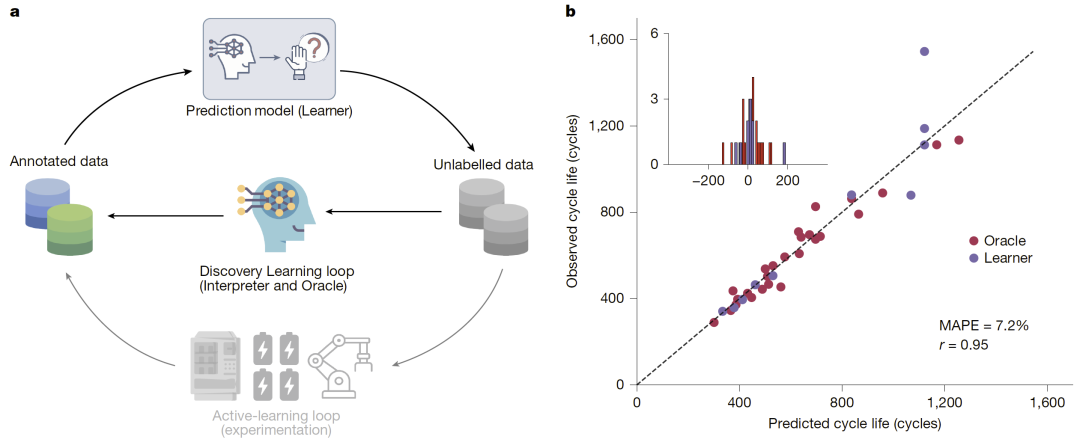
图4:闭环发现式学习流程与预测表现。
讨论与前景
研究人员系统展示了发现式学习在极少实验条件下实现高精度电池寿命预测的可行性,并证明其在时间和能耗成本上的显著优势。该框架不仅可用于寿命评估,还具备拓展到电池安全性、快充性能以及电池管理系统优化等领域的潜力。从更广泛的视角来看,发现式学习为AI在科学研究中的应用提供了一种新范式,有望缓解长期困扰科学机器学习领域的数据昂贵与泛化能力不足问题,为材料设计与复杂工程系统的快速创新开辟新路径。
整理 | 王建民
参考资料
Zhang, J., Zhang, Y., Yi, B. et al. Discovery Learning predicts battery cycle life from minimal experiments. Nature 650, 110–115 (2026).
https://doi.org/10.1038/s41586-025-09951-7
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号