Nat. Commun. | 多到单模态知识转移预训练用于分子表示学习

Nat. Commun. | 多到单模态知识转移预训练用于分子表示学习

DrugOne
发布于 2026-03-02 19:06:46
发布于 2026-03-02 19:06:46
编辑 |熊展坤
今天给大家分享一篇华中农业大学章文教授团队联合俄亥俄州立大学张平教授团队近期在Nature Communications上发表的论文,题目为“Multi-to-uni modal knowledge transfer pre-training for molecular representation learning”。论文提出了 M2UMol,一种多到单模态知识转移预训练方法,用于分子表示学习。该工作面向真实世界中“多模态不全”的分子数据场景,提出多模态到单模态的知识迁移预训练框架:在仅使用1万多条模态不完整的多模态分子数据进行建模的情况下,学习到更鲁棒的分子表示,使得下游任务性能优于百万级单模态数据训练的模型,同时由于数据规模更小、训练路径更高效,整体训练时间显著缩短。

华中农业大学信息学院章文教授和俄亥俄州立大学计算机科学与工程系张平教授为共同通讯作者。华中农业大学信息学院博士研究生熊展坤、王紫嫣、黄锋为文章共同第一作者。课题组博士研究生邱闽瑶、方舒言、杨柳青、华中农业大学信息学院周雄辉副教授和刘世超副教授也参与了该工作。
背景
人工智能药物分子发现是通过人工智能算法发现具有治疗潜力的分子,而如何从多模态数据中学习高质量分子表示是其核心计算问题之一。然而在现实应用中,分子多模态数据存在模态残缺、分布不均等挑战,导致现有多模态预训练模型难以充分利用大规模不完整数据,也无法在下游任务中稳定应用。 该问题成为制约多模态分子预训练走向实际应用的核心瓶颈。作者围绕该问题展开研究,旨在让模型在“模态不完整”的条件下依然能够有效学习多模态分子知识。 作者提出了M2UMol,一种多到单模态知识迁移(Multi-to-uni Modal Knowledge Transfer)预训练框架,实现了从多模态数据向单模态表示的高效知识转移。
该研究的主要创新在于:
1.提出能够同时处理不完整模态预训练与单模态下游预测的表示学习框架;
2.构建用于从2D模态生成3D、文本、生化等伪多模态表示的模态特定适配器(modal-specific adapters),从而在信息缺失时自动补全多模态特征;
3.设计了生成–真实多模态对比学习与模态分类预训练策略,能够有效引导多模态知识向2D编码器迁移,使生成的多模态特征既可靠又具有模态区分性。
4.M2UMol在广泛的分子任务中表现出优越性能。作者还开发了一个用户友好的软件包,集成了分子表示学习、关键官能团分析、分子多模态检索等功能,可方便地应用于药物发现各个领域,有望促进药物开发进程。
M2UMol代码、预训练权重和软件包可在https://github.com/Zhankun-Xiong/M2UMol上获得。
方法
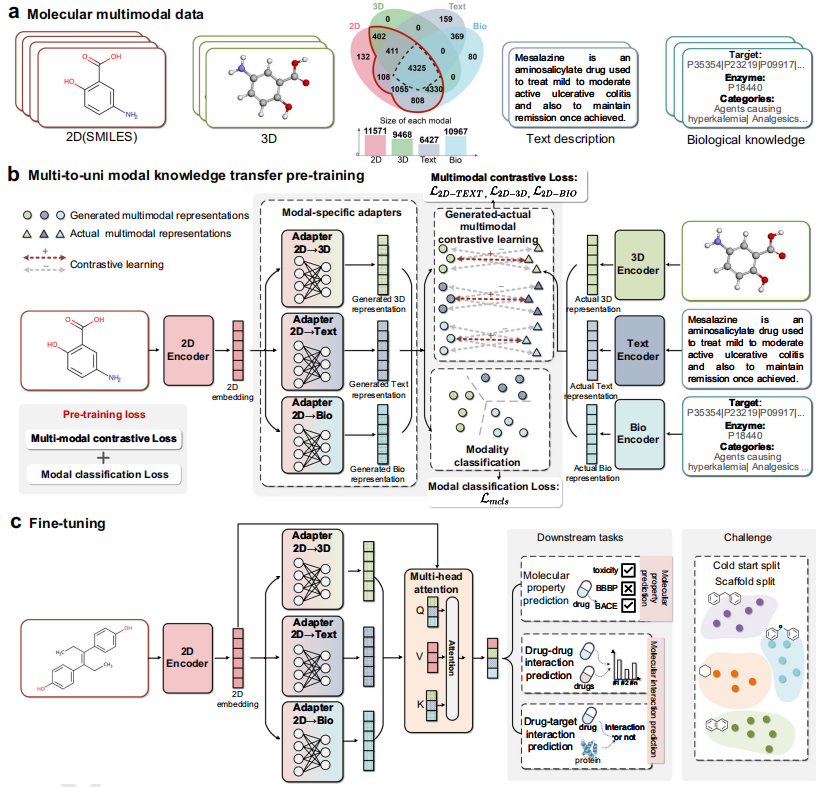
上图是M2UMol框架概述图。 a图:展示了所使用的四种类型的分子多模态数据,以及表示作者所构建的预训练数据集中多模态数据的分布Venn图。在Venn图中,红线包围的区域表示具有不完整模态的分子,黑色虚线包围的区域表示具有完整模态的分子。
b图:将2D/3D/Text/Bio模态数据输入相应的编码器以获得其表示。然后将2D表示输入所设计的模态特定适配器以生成伪3D/Text/Bio表示。预训练目标是最小化生成-实际多模态对比学习和模态分类预训练任务的损失。
c图:将2D拓扑图输入到预训练的2D图编码器和特定于模态的适配器中以获得2D表示并生成3D/文本/生物表示,并使用注意力机制进行分子表示融合,以获得各种下游任务的最终分子表示。
2.1 多模态分子数据构建
作者对多模态分子数据的构建方式进行符号化表示。
2D 拓扑图(2D): 设 表示一个分子集合,其中每个分子都可以表示为一个以原子为节点、以化学键为边的二维拓扑图。对于任意分子 ,其对应的二维拓扑图记为 。
3D 构象图(3D): 形式上,一个分子的三维构象图包含其原始二维拓扑图以及所有节点的笛卡尔坐标。设 表示具有三维构象的分子集合。对于任意分子 ,其对应的三维构象图记为 。
文本描述(Text): 对于文本模态,作者从 DrugBank 中提取两类药物信息:(1)包含关键性质、作用机制和使用指南的简要摘要;(2)包含历史发展、发现过程和临床试验结果的更全面背景信息。作者将这些文本拼接以构成每个分子的统一文本描述 ,其中 , 为具有文本描述的分子集合。
生化特征(Bio): 对于生化特征模态,作者整合 DrugBank 中三类生化功能信息,包括药物类别、靶点关联和酶关联。具体来说,对于分子 ,其生化特征可表示为一个二进制向量集合:, , or 其中每个向量的元素取值 或 ,分别表示该分子是否属于某一药物类别、靶点或酶。三类特征的维度分别为 ,即 。
需要注意的是,并非 中每个分子都同时具有 3D、Text 和 Bio 模态,因此:
2.2 多到单模态知识迁移预训练(Multi-to-uni modal knowledge transfer pre-training)
2.2.1 模态编码器
M2UMol 使用四个独立的编码器处理不同模态。
二维编码器 使用 GraphGPS从 的二维拓扑图中学习分子二维表示。三维编码器 使用 ComENet从 的三维构象图中学习表示。文本编码器 首先利用 PubMedBERT的预训练 tokenizer对文本描述进行分词,再将 tokens 输入 PubMedBERT 的 pooler 层得到 768 维表示。生化编码器 将三类生化特征分别映射到 维后取平均作为表示。
形式化地,对于分子 , 它的2D表示为. 如果分子 也属于 , or , 就能得到它的 3D, Text or Bio embedding,即 , , or 。这些embeddings都为维向量。
2.2.2 模态特定适配器(Modal-specific adapters)
模态特定适配器用于从二维模态生成伪 3D、文本、Bio 表示。对于二维表示 ,三种伪模态表示的生成方式为:

其中 , 为可训练参数。
2.2.3 自监督任务
作者设计了两类自监督任务:生成–真实多模态对比学习与模态分类。
生成–真实多模态对比学习 为了使模型能够生成与实际表示尽可能相似的3D、Text和Bio模态表示,作者通过对比学习(CL)将生成的伪多模态表示与实际多模态表示对齐。令表示代表三种模态{3D,Text,Bio}。对于每个 和每个分子,作者将其生成/实际表示视为锚样本,其他分子的生成表示和实际表示作为负样本,然后最大化正对的互信息(每个正对包含一个锚样本和一个对应的正样本),同时最小化负对的互信息(每个负对包含一个锚样本和一个负样本)。作者对每个模态采用独立的CL目标,总损失表示为:
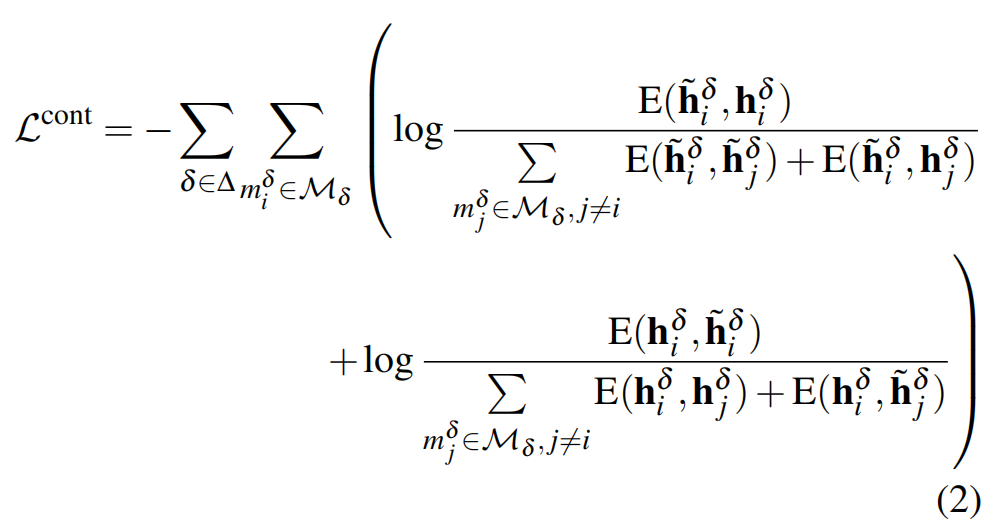
其中,和分别表示分子在中的生成表示和实际表示;,这里表示余弦相似度;并且是温度系数。
模态分类 作者设计了一个模态分类器,以进一步增强生成的多模态表示中包含的模态特异性和可扩展性。模态分类器将生成的表示, 和 作为输入,并识别生成的表示属于哪个模态。为了优化模态分类器,最小化交叉熵损失:
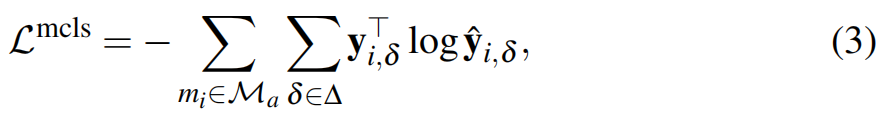
其中 是独热模态标签,模态的索引处为1,在其他地方为0,并且是模态分类器对于的预测值,在具体实现中,是一个带有softmax函数的单层线性投影层。
预训练目标 作者优化总预训练损失,其组合公式(2)和公式(3)用于预训练模型M2UMol:
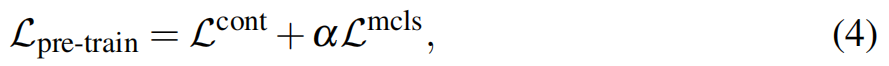
其中是平衡模态分类器贡献的超参数。
2.3 基于注意力知识融合的微调
在预训练之后,M2UMol中的2D模态编码器 以及包括投影头, 和 的模态特定适配器通过下游任务上的基于注意力的知识融合策略进行进一步微调,仅用分子2D拓扑图输入来模拟多模态融合。
基于注意力的知识融合 对于分子,首先获得拓扑图,并利用预先训练的2D图形编码器来学习2D表示。然后,特定于模态的投影头, 和 分别生成3D、Text和Bio表示, 和 ,随后通过多头注意机制将其融合为最终表示:
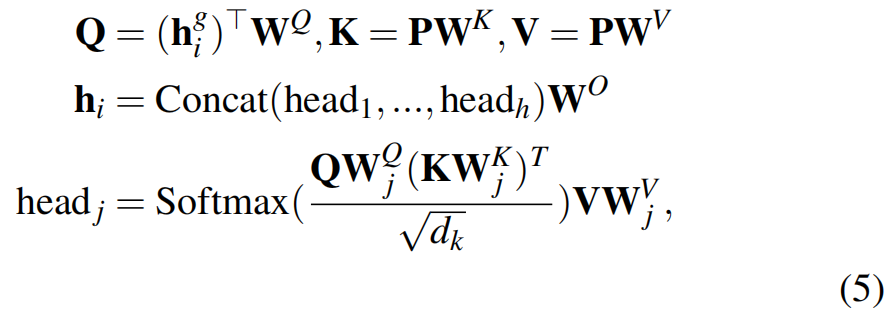
其中,; ; 是可训练参数,是隐向量维数;投影是参数矩阵, , 和 ,表示注意力头的数量, 。最后,表示分子的最终表示,其可被用于各种下游任务的不同预测器中。
结果
3.1 M2UMol在分子性质预测和分子相互作用预测任务上优于基线方法
在本节中,作者通过将提出的方法M2UMol与两种类型的分子下游任务:分子性质预测(MPP)和分子相互作用预测(MIP)的基线方法进行比较来评估其有效性。
分子性质预测(MPP): 分子性质预测是药物发现中的一项重要任务,有利于科学家筛选出具有所需性质的分子。作者遵循大多数现有方法所使用的骨架划分来评估M2UMol的效果-基于分裂。骨架划分是一种具有挑战性和现实性的评估设置,通常用于评估MRL方法的OOD泛化能力。在这里,作者将M2UMol与最近的优秀预训练MRL方法进行比较。结果如下表所示。
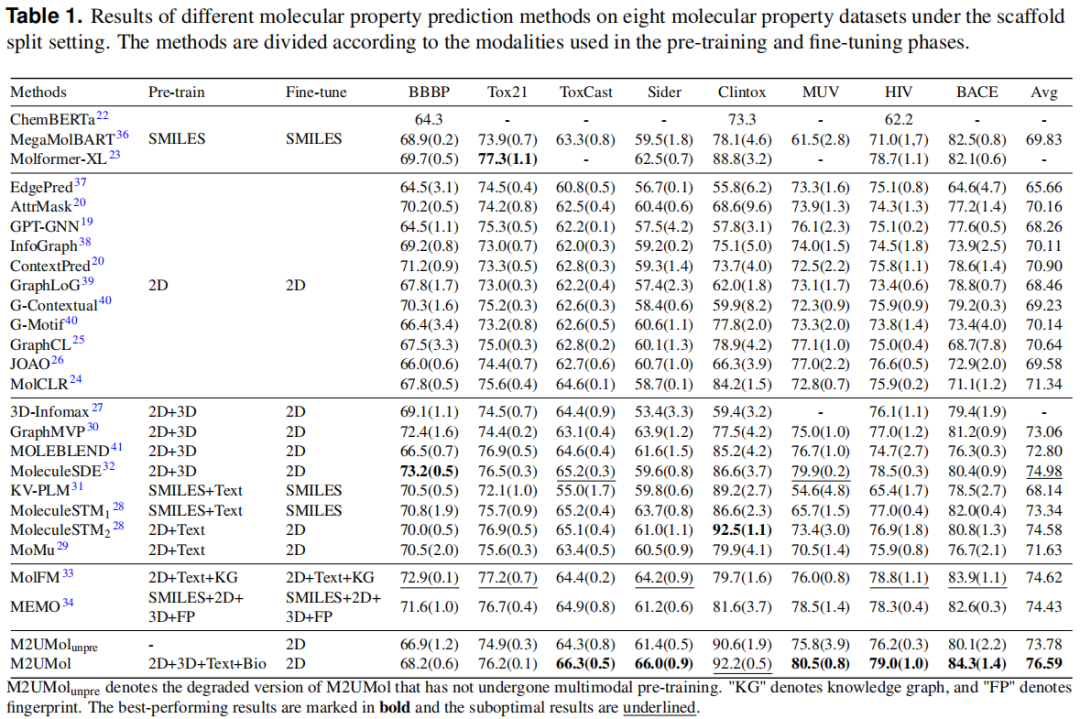
从表中可以看出,多模态预训练MRL方法往往比单模态方法产生更好的性能。当在预训练阶段引入更多模态时,性能增强十分明显。这种趋势表明,使用更多的模态进行预训练可能对下游分子性质预测任务具有更多的潜在益处。在基线中,M2UMol在8个数据集中的5个数据集上产生最佳性能,AUC平均改善5.21%、10.00%、10.69%、5.57%和8.79%,作者将M2UMol在单模态分子性质预测任务上的有利结果归因于模型在预训练中将多模态知识转移到了2D分子表示学习中,并在微调阶段模拟了多模态信息融合,以学习到更高质量的分子表示。此外,M2UMol在11小时内使用单个GPU(RTX 3090)仅在11 k分子上进行了预训练,但仍然实现了优秀的预测性能。这证明了模型的高度可扩展性和效率。
分子间相互作用预测(MIP): 分子间相互作用可以为复杂的生物系统分析提供重要的信息,是药物发现的有力资源,本文选择了两个具有代表性的分子间相互作用预测任务:DDI预测任务和DTI预测任务,进一步评估M2UMol的性能。当同时服用多种药物时,可能会出现意外的药物-药物不良反应,称为DDI事件(DDIEs)。预测DDIEs通常被认为是DDI预测中的多分类任务,对于公共卫生安全和药品安全监测至关重要,在深度学习和生物信息学领域备受关注。对于这项任务,作者主要关注具有挑战性的场景:冷启动划分和骨架划分。对于前一种情况,用于测试的药物不包括在DDI数据中,M2UMol在DDI数据上进行微调,而对于后一种情况,不仅测试药物,而且它们的骨架在DDI数据中也是不可见的。第二种情况比第一种情况更棘手,但在以前的工作中很少关注。作者选择最近先进的DDIE预测方法作为比较基线。
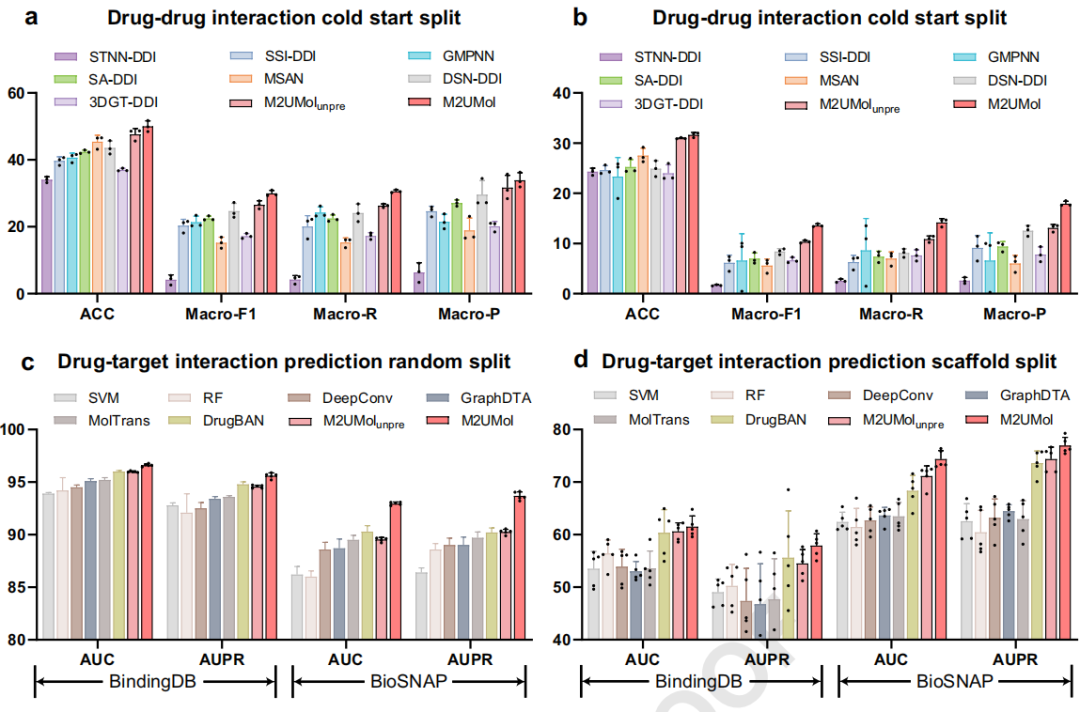
结果上图a-b所示。总体而言,M2UMol在两种情况下都明显优于所有基线。具体而言,与基线相比,M2UMol在ACC中实现了9.66%和6.84%的平均性能增益,在Macro-F1中实现了11.92%和7.74%的平均性能增益,在Macro-R中实现了12.03%和7.47%的平均性能增益,在Macro-P中实现了12.27%和10.43%的平均性能增益。DTI预测是药物发现中不可或缺的一步,有助于缩小候选化合物的搜索范围。作者将DrugBAN(预测DTI的里程碑方法)中的药物表示学习模块替换为M2UMol的微调架构,以使M2UMol适应DTI预测。然后,作者遵循DrugBAN中的两个评估场景,即随机划分和骨架划分,以展示M2UMol在改善DTI预测方面的能力。图c-d显示了不同方法在DTI预测中的结果。可以观察到,与DrugBAN相比,M2UMol_unpre的结果没有显著改善,而M2UMol的改善尤为明显。更具体地说,M2UMol的表现优于DrugBAN,在两个评估场景的两个数据集上,AUC平均改善2.60%,AUPR平均改善2.48%。总之,M2UMol在两个分子相互作用预测任务上都实现了优秀性能,展示了其可靠性、灵活性和鲁棒性,这归因于其能够提供高质量的药物分子表示。其在预测分子相互作用方面的优越性也突显了其在促进人工智能辅助药物发现方面的非凡潜力。
3.2 M2UMol在预训练中从多模态数据中获取多种知识
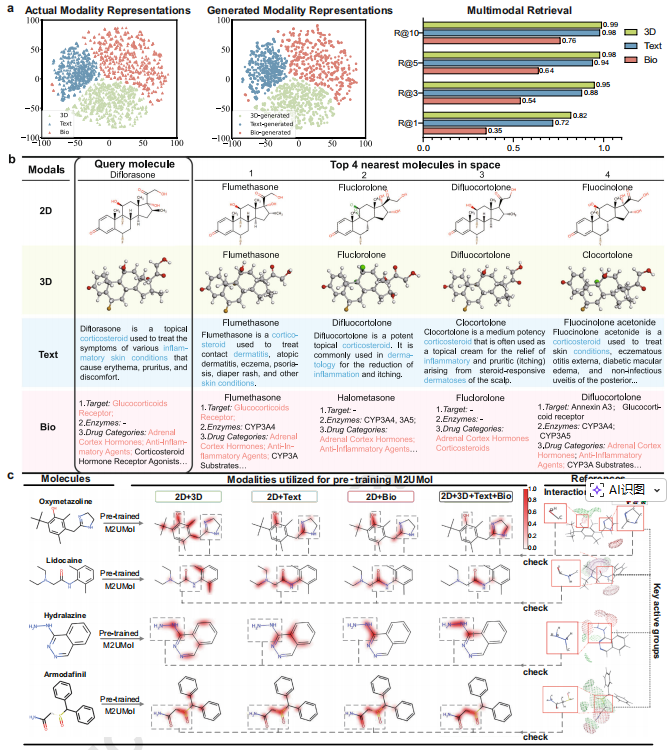
M2UMol可以从2D分子图生成可靠的多模态表示。 M2UMol能够仅从相应分子的2D表示就能生成多模态伪表示。为了评估生成多模态表示的质量,作者通过t-SNE可视化实际和生成的多模态表示。如上图a可以观察到,实际的模态表示和生成的模态表示都根据模态类型分别分布到三个聚类中。观察表明,M2UMol可以捕获不同模态的差异化知识,并将其传输到adapter中,以便它能够仅基于2D表示生成可区分的表示。此外,作者进行了多模态检索任务来评估生成的多模态表示的质量。由于所有实际和生成的表示都具有相同的维度,因此作者考虑在一个共同的欧几里得空间中的所有匹配的生成-实际表示对,检查每一对中的实际表示是否在top-k个距离最近的表示之内,作者利用广泛使用的度量Recall@K,k在{1,3,5,10}中可选,来评估多模态检索任务中生成的多模态表示的质量。如图a中的条形图所示,可以观察到:(1)所生成的3D表示比所生成的其他模态的表示质量更高,这可能是由于3D和2D之间较小的模态gap,因为3D和2D都描绘分子结构信息;(2)尽管文本和2D之间存在很大的模态gap,并且文本的数据规模小于3D和Bio,生成的文本表示仍然很好地近似于它们匹配的实际表示(Recall@1=0.72,Recall@10=0.98),表明M2UMol能够有效地弥合模态差距;(3)生成的Bio表示的质量相对较差,但可以接受(Recall@1=0.35,Recall@10=0.76),这可能是由于二进制生化特征向量的稀疏性。这证明了M2UMol在仅使用2D分子图生成可靠的多模态表示方面的鲁棒能力。此外,受先前研究的启发,作者进行了案例研究,以表明M2UMol有效地捕获语义信息,从而为共享相似特征的分子产生相似的表示。(ID:DB 00223)作为查询分子,并在2D表示空间或生成的3D/Text/Bio中检索其前4个最接近的分子,并将检索到的分子的模态数据在图b中可视化。每个模态表示空间中的前4个最接近的分子表现出类似于二氟拉松的特征。具体而言,在2D模态中,二氟拉松和最近的氟米松是一对构象异构体,它们与其他三种分子的区别仅在于少数基团,例如F被CL取代和CH3被OH取代。在3D模态中,二氟拉松及其邻近分子具有高度相似的原子组成和结构。在文本模态中,所有列出的分子都是具有抗炎作用的皮质类固醇。在Bio模态中,所示分子靶向糖皮质激素受体,也可以被CYP3家族中的酶代谢。这说明了M2UMol捕捉分子之间内在关系的能力。此外,最相似的分子在不同的模态空间中会有所不同,这突出了M2UMol能够从多模态角度进行分析,并为每种模态生成不同的表示。这种能力确保为每种分子提供互补和全面的信息。
M2UMol可精确聚焦于分子的关键结构。由于M2UMol使用的模态分子数据比大多数现有的预训练MRL模型(通常包括两种模态)更多,因此自然会出现一个问题,即在多模态到单模态知识转移预训练中使用更多模态是否对M2UMol从更全面的角度理解关键分子知识有更多好处。作者从预训练数据集中选择几个分子,并将预训练的M2UMol学习的分子原子和键的注意力权重可视化(2D+3D+Text+Bio)及其三种变体,使用部分模态进行预训练(2D+3D、2D+Text或2D+Bio)。此外,作者展示了从分子操作环境计算生成的相互作用势图。其提供了化学探针(在这种情况下为Na+、N1+和O)与分子表面具有有利相互作用的区域的图形表示。基于相互作用势图,M2UMol还可以确定示例分子的关键活性基团,作为与注意力可视化进行比较分析的参考。如图c所示,随着在预训练阶段逐步纳入模态(从左到右),M2UMol逐渐将注意力分配到与相互作用势图中识别的关键活性基团高度一致的特定分子片段。在这里以肾上腺素能激动剂羟甲唑啉为例:M2UMol非常关注羟基和咪唑啉环,它们在羟甲唑啉与肾上腺素能受体结合期间参与氢键相互作用和离子相互作用,结果表明,M2UMol具有仅基于多模态分子数据本身来理解分子结构-活性关系和鉴定分子的关键结构的潜力,并且它包含的模态越多,有关分子关键结构的解析越精准。
3.3 M2UMol通过高质量的表示提高下游任务的性能
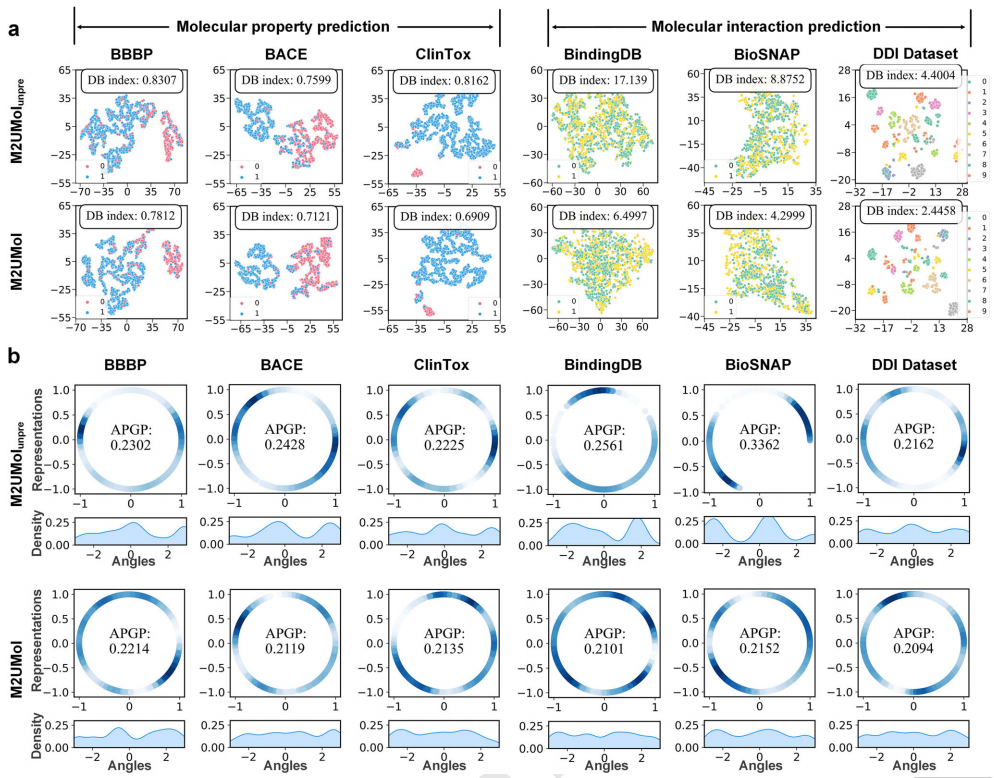
在本节中,作者讨论M2UMol提供的分子表示如何有益于各种下游任务。作者通过t-SNE可视化从M2UMol和M2UMol_unpre获得的下游任务分子表示。“M2UMol”表示经过微调的预训练的M2UMol,而“M2UMol_unpre”表示未经过预训练的M2UMol,该架构直接随机初始化模型并在下游任务上进行训练。如图a所示,M2UMol针对两个MPP数据集BBBP和BACE中的正样本和负样本学习的表示,比来自M2UMol_unpre的那些更清楚地分为两部分。对于两个DTI数据集BindingDB和BioSNAP,M2UMol实现了比M2UMolunpre更低的Davies-Bouldin(DB)指数(7.1770和3.8673)。对于DDI数据集,作者选择测试集内的最稀疏的10 个DDI事件的DDI用于t-SNE可视化,可以观察到M2UMol学习的表示与M2UMol_unpre相比更紧密清晰地聚集。受之前研究的启发,分子的高质量表示应该大致均匀地分布在单位超球体上,保留尽可能多的数据信息。在此,作者将上述M2UMol和M2UMol_unpret测试集中的分子表示通过t-SNE进行降维,然后进行L2归一化,投影到单位圆上。然后,通过在圆上使用非参数高斯核密度估计(KDE)来可视化表示的密度分布。此外,作者计算平均成对高斯势分数,简称为APGP分数,用于量化表示的均匀性。此外,作者示出了每个点的角度的密度估计,以更清楚地呈现分布。如图b所示,对于M2UMol_unpre,表示的分布一致地表现出相对高的聚类程度,并且角度密度估计曲线有明显的峰,这可能是由于在没有来自预训练的知识的情况下,M2UMol_unpre学习到的表示仅包含有限的单模态信息,这可能使得当分子结构相似时难以学习独特的特征。至于预训练的M2UMol,分子表示的分布具有较低的APGP分数,相比于前者更加均匀,并且角度密度估计曲线也明显更平滑。这是因为在经过作者设计的多对单知识迁移预训练之后,模型能够仅基于分子的2D拓扑图来生成不同模态的表示,这提供了更多样化的信息,增强了对分子独特特征的学习,并使表示在空间中分布得更均匀。
3.4 M2UMol能够揭示与下游任务相关的分子的关键结构
在本节中,作者进一步进行可解释性分析,以研究M2UMol在下游任务上进行微调后捕获任务相关的关键结构或官能团的能力。为此,作者可视化了M2UMol在MMP和DDI预测任务上学习的分子的注意力权重。
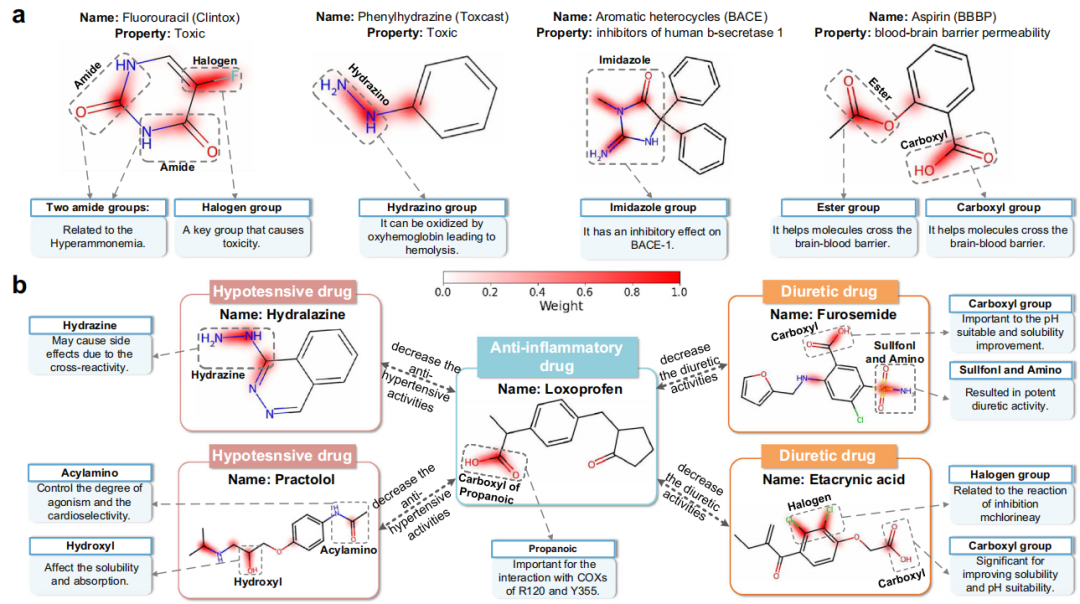
对于MMP,作者从不同的数据集中选择骨架划分场景中的测试分子进行可视化分析,结果如图a所示。(PubChem ID:3385)是一种设计用于治疗肿瘤的分子,但未经FDA批准,在Clintox数据集中被标记为有毒。M2UMol注意到氟尿嘧啶的卤素基团和两个酰胺基团。前者是导致氟尿嘧啶毒性的关键基团。氟尿嘧啶,对于后者,一项研究表明,使用氟尿嘧啶可能会导致高氨血症,这可能与两个酰胺基团有关。苯肼(PubChem ID:7516)是Toxcast数据集中标记为有毒的分子。可以看到,肼基被M2UMol赋予了很高的关注权重,它被证明是可以被氧合血红蛋白氧化,导致溶血的关键官能团。芳香杂环在BACE数据集中被标记为人类b-分泌酶1的抑制剂,M2UMol关注咪唑基团,其属于芳香杂环家族,在一项研究中显示出对人β-分泌酶1的抑制作用。阿司匹林,来自BBBP数据集的分子,具有穿过血脑屏障的能力。M2UMol关注羧基和酯基,它们分别是酸性和亲脂性官能团,并已被证明有助于分子穿过血脑屏障。
对于DDI预测,作者选择临床上常用的镇痛药和抗炎药,即洛索洛芬,一种非甾体抗炎药,如图b所示,M2UMol精确地聚焦于洛索洛芬的丙酸基团中的羧基,这是高效率的关键活性组并有助于抑制参与促进利尿作用和抗高血压作用的甘草素的合成。在这里,我们随机选择两种利尿药物(呋塞米和依他尼酸)和两种利尿药物(肼屈嗪和心得洛尔),它们分别被M2UMol预测为与洛索洛芬发生“利尿活性降低”和“降压活性降低”DDI事件,用于可视化。如图5b所示,对于呋塞米,M2UMol关注磺酰基和氨基,这是产生强效利尿活性的关键基团。此外,M2UMol还关注呋塞米的羧基,这已被证明是一个重要的活性基团,具有相当大的分子间相互作用潜力。对于依他尼酸,M2UMol侧重于卤素基团和羧基,前者可与有关利尿活性的靶点相互作用,后者对pH适宜性和溶解度改善很重要,可影响药物的吸收和效果。对于肼苯哒嗪,集中的肼基是分子中最具反应性的部分,也是最有可能自发结合蛋白质的部分。对于普萘洛尔,集中的是酰氨基,这被证明控制激动作用的程度和心脏选择性,这与抗高血压作用直接相关,而集中的羟基会影响溶解度和吸收,从而影响药物的有效性。
总体而言,M2UMol能够从多模态的角度理解分子结构,从而能够全面捕捉分子的关键结构或功能基团,可视化结果与人类对药物分子结构特性的理解一致,证实了M2UMol具有良好的可解释性,能够提供多样化、丰富的分子相关知识来辅助药物发现过程。
讨论
在这项研究中,作者提出了M2UMol,一种多到单模态知识转移预训练MRL方法,它可以有效地从不完整的多模态数据中学习多模态知识,并能够基于2D拓扑图生成多模态表示,大量实验表明,M2UMol可以学习高分辨率的数据,高质量的分子表示,并在各种下游任务上实现上级性能,特别是在OOD场景中。此外,结果验证了M2UMol可以从2D拓扑图生成可靠的多模态表示,并带来包含全面知识的分子表示,这使其成为帮助药物发现的有效工具。
得益于精心设计的多到单模式知识转移预训练框架,M2UMol可以学习高质量的分子表示,并在重要的分子任务上实现上级性能,例如分子性质预测和分子相互作用预测。近年来,分子生成由于其加速从头药物设计和探索新的化学空间的潜力而获得了极大的关注,并且已经成为计算化学和药物发现的关键前沿。考虑到学习高质量的分子表示也是分子生成的基本基础,作者未来的工作将集中于将模型在分子表示学习中的上级能力扩展到分子生成。本发明的目的是研究分子生成中的表示学习,并设计一种多模态分子生成模型,该模型能够生成由多种多模态输入引导的新型分子,例如目标口袋的3D结构和关于所需分子性质的文本描述。
M2UMol软件包使用
M2UMol能够有效地学习高质量的分子表示,具有很强的泛化能力,能够在广泛的分子任务中实现上级性能。此外,通过利用精心设计的多对单知识转移预训练框架,M2UMol弥合了2D和其他模态之间的模态差距,仅使用2D输入就可以方便地检索多模态信息。此外,通过在预训练期间使用四种不同的模态,M2UMol具有精确识别关键分子结构的强大能力。利用这些全面的功能,作者开发了一个基于M2UMol的软件包,用于AI辅助药物发现。 M2UMol软件包的功能如下:
分子表示学习: M2UMol软件包可以直接以SMILES为输入,学习具有多模态知识的固定表示,然后将表示作为分子的特征或指纹。M2UMol软件包还提供了一个API,用户可以轻松地将M2UMol作为分子编码器嵌入到他们自己的模型中,并且M2UMol可以在特定领域的任务上进行进一步微调,以适应各种分子任务。这种双重功能设计既为需要即时分子描述符的实验研究人员服务,也为开发人员建立专门的预测模型提供服务。
多模态检索: 基于用户给出的SMILES,M2UMol软件包可以检索五个最相似的3D构象、文本描述和生化特征(包括药物类别、反应靶点和酶)。一方面,对于只有SMILES的分子,M2Umol软件包的跨模态检索功能可以为研究人员提供全面的见解:检索到的3D构象能够分析构象空间特征;检索到的文本描述可以帮助揭示潜在的物理化学性质;和检索的生化特征可以帮助识别可能的药物类别沿着相互作用的靶标和酶。另一方面,该功能可以作为AI生成分子的验证工具,基于M2Umol包提供的检索到的多模态数据,研究人员可以分析分子的分子构象合理性,它是否具有所需的特性,或者它是否能与某种靶标或酶反应,从而可以初步有效地筛选所产生的分子。
关键结构识别: M2UMol软件包可以直接从给定的SMILES中识别出关键分子结构,并支持根据给定的重要性阈值可视化分子结构的重要性。该功能可以增强研究人员对分子的理解,从而使他们能够根据给定的关键结构设计实验。此外,该功能可能有助于分子优化。在使用工具识别分子的关键活性基团后,它可以防止在分子优化过程中对影响分子性质的关键结构的破坏,因此,可以优化分子结构的其它部分以提高诸如溶解性的性能。
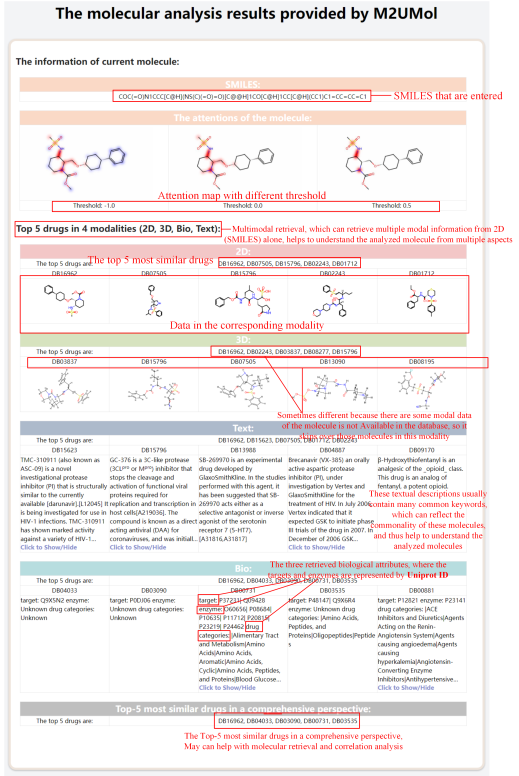
在这里,作者给出了M2UMol包用于多模态检索和关键结构识别的例子如下,结果的不同部分的描述附在图中。
论文与代码
Xiong, Z., Wang, Z., Huang, F. et al. Multi-to-uni modal knowledge transfer pre-training for molecular representation learning. Nat Commun (2026).
https://doi.org/10.1038/s41467-026-69302-6
代码:https://github.com/Zhankun-Xiong/M2UMol
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号