谷歌发布第七代TPU震撼发布,引领AI推理进入新时代


摘要
2025年4月,Google 发布第七代TPU Ironwood,震撼算力市场。

当全球芯片设计者,都在对标英伟达H100 GPU的性能参数时,谷歌公司悄然发布了一款足以震惊业界的第七代TPU。
2025年4月Google Cloud Next 25大会,谷歌正式发布了第七代TPU Ironwood,该卡以42.5EFLOPS的算力刷新了业界纪录,而且具备更低的训练成本。
01、性能怪兽:性能暴增30倍的硬核参数
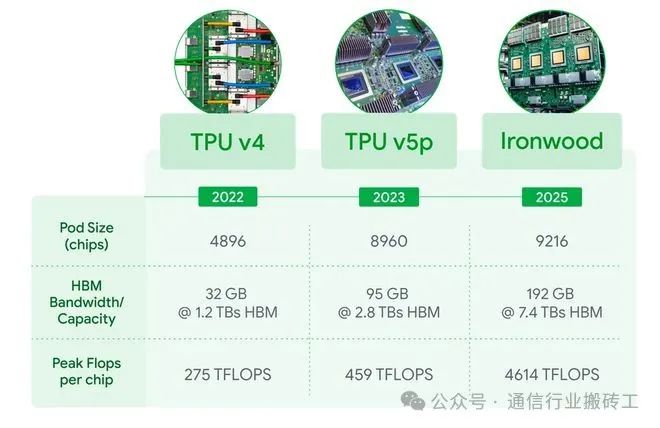
在谷歌公布的参数表中,Ironwood TPU 展现出令人震惊的硬件指标:
- 192GB HBM3E显存:较前代暴增6倍,轻松运行万亿参数级别的大模型
- 7.2TB/s内存带宽:相当于每秒传输230部4K电影
- 10兆瓦液冷系统:用数据中心级散热支撑9216芯片集群
- FP8混合精度:训练速度较BF16提升10倍
这组数据背后,藏着谷歌工程师通过3D堆叠封装技术,将两个计算核心、8组HBM内存与互连芯片集成在单一封装内,配合自研的Jupiter光交换网络,构建出堪比超算级别的AI加速单元。
更惊人的是其能效迭代速度:相比2018年发布的初代云TPU,第七代Ironwood TPU卡的每瓦性能飙升了29.3倍。打个夸张一点的比方:这个效能提升,相当于用现在一部智能手机的功耗的算力水平,就能驱动十年前学校电教室机房计算机的算力。
02、推理迭代:从计算单元到“推理引擎”的提升
Ironwood的颠覆性创新,在于其针对推理任务进行全栈优化:
- 动态电压调节:根据负载实时调整供电,将闲置功耗降低80%
- 第三代SparseCore引擎:金融等高频交易加速性能提升5倍
- 3D环面互连拓扑:将芯片间延迟压缩至纳秒级
这种新架构的优势直接反映在应用场景中:当传统TPU还在为训练千亿模型焦头烂额时,Ironwood已能实时处理混合专家模型(MoE)的万亿级推理请求。据说谷歌内部测试显示,搭载该TPU的环境,运行Gemini 2.5的推理延迟降低67%,而成本仅为前代方案的1/4。
更值得大家关注的是"弹性推理"能力:通过Pathways软件栈,开发者可将数万块TPU动态组合为"虚拟超级计算机"。通过支持云原生架构,Ironwood TPU 能够让AI推理首次具备分钟级弹性伸缩能力。
03、从实验室到生活:即将改变的现实场景
在AI芯片的战场上,谷歌正通过其雄厚的技术积累,构建起技术竞争的护城河:
- 液冷架构突破:通过浸没式冷却技术,实现功率密度较风冷提升200%
- 软硬协同生态:从Axion ARM CPU到Pathways系统级的优化,打造端到端技术栈
- 推理经济模型:按token计费模式,或将改写云计算商业模式
这种组合拳直击大模型推理行业的痛点:当前大模型推理成本中,显存带宽制约占60%以上,然而 Ironwood 通过 HBM3E+FP8 的组合,能够有效的将token成本压缩到0.0003美元/千次,这或将推动大模型行业降本增效的浪潮。
04、技术密码:谷歌技术的“三重创新”
伴随着Ironwood TPU的登场,这或许预示着AI基础设施正经历着跨时代的转折:
- 从训练主导到推理优先:据说谷歌云80%的AI工作负载已转向推理
- 从静态计算到动态思维:强大的算力支撑,让实时知识检索的"思考型AI"成为可能。
- 从单任务处理到群体智能:通过部署万卡集群,强大的算力矩阵可以支撑多智能体协同的推理模型
这种转变在技术路线图上表现的尤为明显,据说第三代SparseCore不仅加速推荐系统,更在内部集成了强大的模拟仿真引擎,这或许意味着AI开始跨界进入传统HPC领域。据谷歌透露,已有科研机构在Ironwood TPU测试版本上实现分子动力学模拟速度提升40倍的实验。
05、展望未来:AI芯片的新赛道
当Ironwood TPU以 Exaflops 量级算力冲击算力市场时,我们更需要冷静思考:
- 液冷系统的运维成本是否会导致算力集中化部署?
- Pathways生态能否打破CUDA的护城河?
- 推理优化的架构是否会影响训练效率?
这些问题,都将在谷歌10月公布的详细技术白皮书中找到答案。但可以确定的是,AI算力的竞争已进入"专业定制芯片"时代。以英伟达等为代表的通用GPU的应用场景,正在被TPU、NPU、IPU等专用架构所替代。或许谷歌本次举办的Google Cloud next 25发布的一系列新技术新产品,或将正在加速算力市场的变革。
如果本文对你有所启发,请不吝点赞、转发、小心心。也欢迎评论区一起讨论交流。
排版: Mr.李自成 / 审核:Mr.李自成
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号