
keras多层LSTM模型的股价预测收敛于一个常数
keras多层LSTM模型的股价预测收敛于一个常数
提问于 2018-07-31 16:40:59
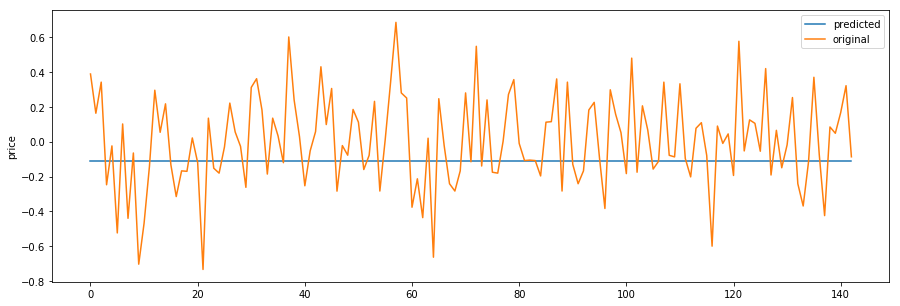
我建立了一个多层LSTM模型,它使用回归来预测数据的下一个帧的值。该模型在20年代后完成。然后,我得到一些预测,并将它们与我的实际真值进行比较。正如您在上面的图片中所看到的,预测会聚合到一个恒定的值。我不知道为什么会这样。到目前为止,我的模型如下:
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Dropout
from keras.layers import LSTM, BatchNormalization
from tensorflow.python.keras.initializers import RandomUniform
init = RandomUniform(minval=-0.05, maxval= 0.05)
model = Sequential()
model.add(LSTM(kernel_initializer=init, activation='relu', return_sequences=True, units=800, dropout=0.5, recurrent_dropout=0.2, input_shape=(x_train.shape[1], x_train.shape[2]) ))
model.add(LSTM(kernel_initializer=init, activation='relu', return_sequences=False, units=500, dropout=0.5, recurrent_dropout=0.2 ))
model.add(Dense(1024, activation='linear', kernel_initializer=init))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(1, activation='linear', kernel_initializer= 'normal'))
model.compile(loss='mean_squared_error', optimizer='rmsprop' )
model.summary()EDIT1: I将历元从20减少到3。结果如下:
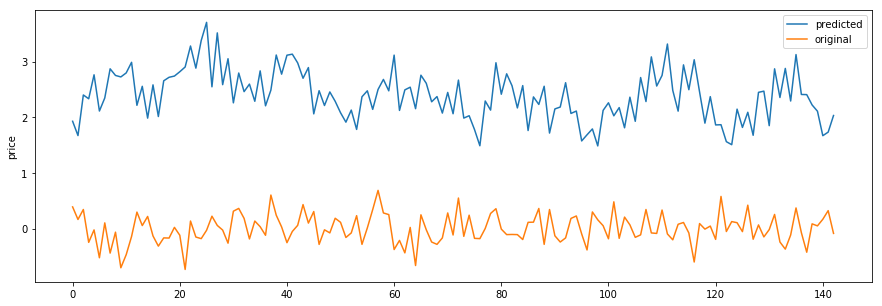
通过对两幅图片的比较,我可以得出结论,当年代数增加时,预测更有可能收敛到某个特定值,即-0.1左右。
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-08-07 09:10:49
所以,在尝试了不同数量的LSTM单元和不同类型的体系结构之后,我意识到当前的LSTM单元数会导致模型学习得太慢,而对于如此庞大的model.For每层都有20个时代是不够的,我将LSTM单元的数量更改为64,并删除了Dense(1024)层,并将时间从20个增加到400个,结果非常接近于地面真值。--我应该提到,在新模型中使用的数据集不同于前一个模型,因为我遇到了该数据集的一些问题。以下是新的模式:
from keras.optimizers import RMSprop
from keras.initializers import glorot_uniform, glorot_normal, RandomUniform
init = glorot_normal(seed=None)
init1 = RandomUniform(minval=-0.05, maxval=0.05)
optimizer = RMSprop(lr=0.001, rho=0.9, epsilon=None, decay=0.0)
model = Sequential()
model.add(LSTM(units=64, dropout=0.2, recurrent_dropout=0.2,
input_shape=(x_train.shape[1], x_train.shape[2]),
return_sequences=True, kernel_initializer=init))
model.add(LSTM(units=64, dropout=0.2, recurrent_dropout=0.2,
return_sequences=False, kernel_initializer=init))
model.add(Dense(1, activation='linear', kernel_initializer= init1))
model.compile(loss='mean_squared_error', optimizer=optimizer )
model.summary()你可以在这里看到预测:
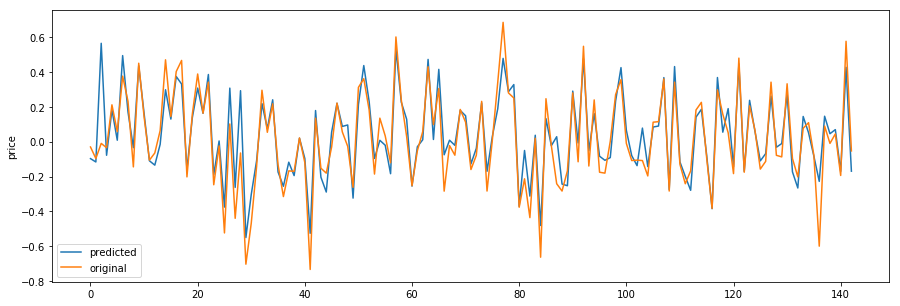
这仍然不是最好的模式,但至少表现优于前一个。如果你对如何改进它有任何进一步的建议,它将是非常感谢的。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/51618251
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号