
dask.submit:调度程序中不足的内存/负载分配
运行一个优秀的dask服务器:
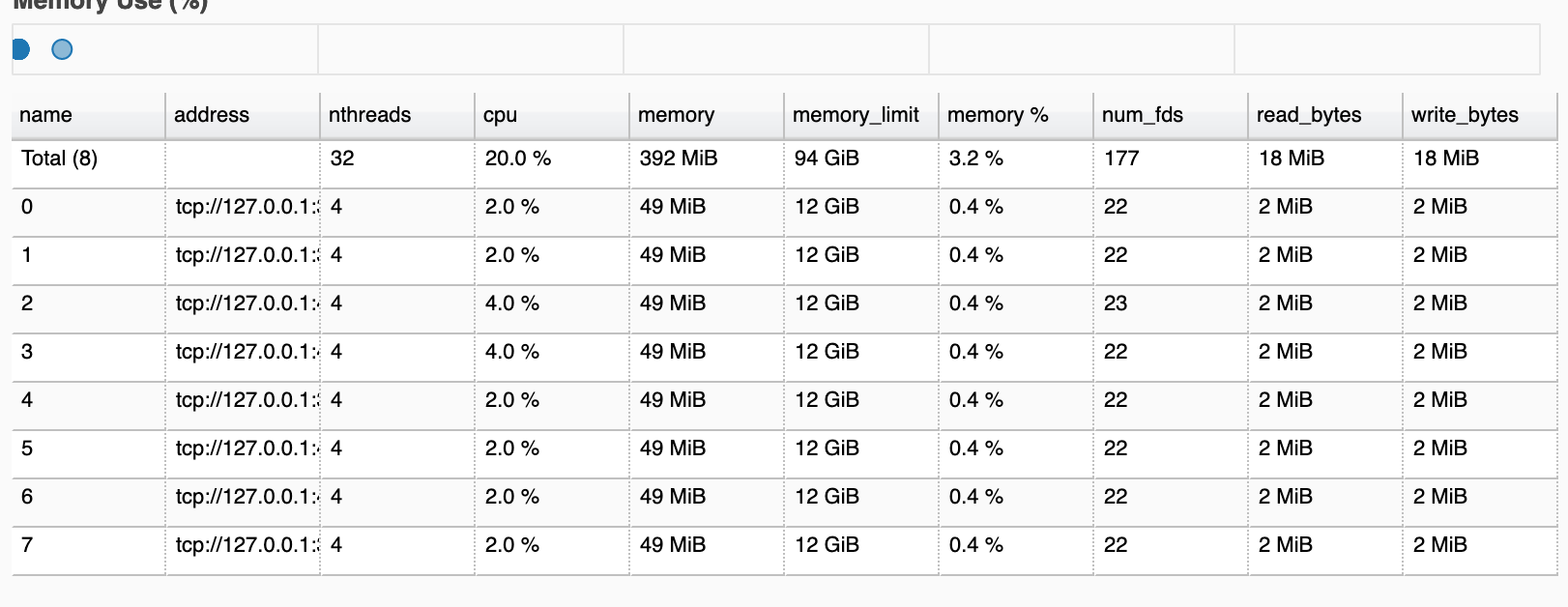
在我开始使用publish_dataset预填一些关于工作人员的数据时,内存似乎分配得很好:
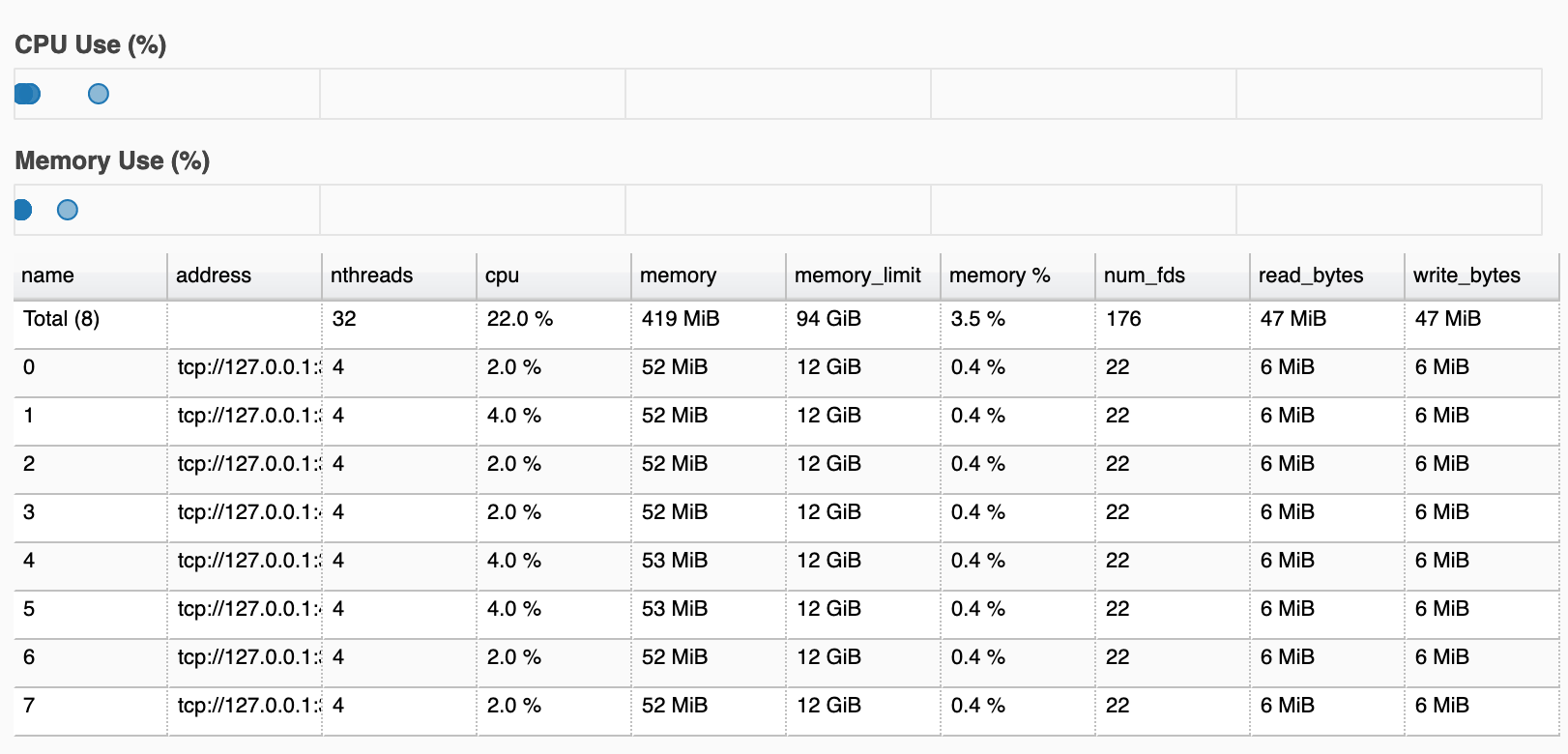
接下来,我在循环中调用futures.append(client.submit(fn, values)),然后调用client.gather(futures) --这是可行的!但是它没有假设的那么快,因为大多数计算/内存负载都集中在两个单进程 (worker4和worker 1)上:
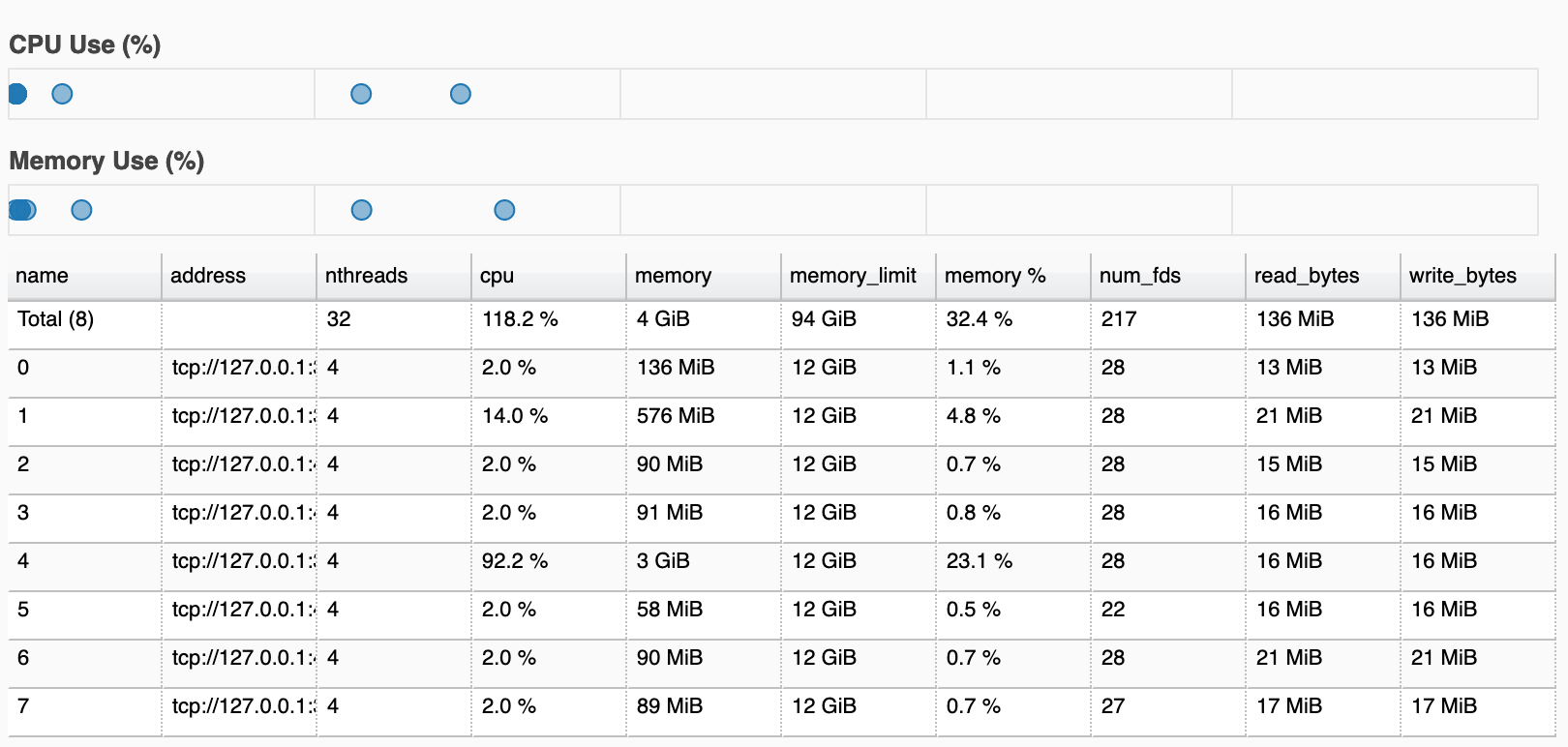
问题:
Dask为什么要这样做?submit to the specific workers
- Should
- 是否有可能预先加载特定工作的数据,而不是parallelization?
,我以某种方式在工作人员之间重新分配使用的内存,以实现更好的parallelization?。
相关:Dask Worker Stealing Register Worker callbacks和Dask Actors per worker
回答 1
Stack Overflow用户
发布于 2020-05-23 17:46:25
为什么达斯克要这样做?
不幸的是,我对你的问题还不太了解,不知道达斯克为什么选择做它正在做的事情。
是否可以预先加载特定工程的数据,而不是提交给特定的工人?
是。参见workers=关键字scatter和submit
是否应该在工作人员之间重新分配使用的内存,以实现更好的并行化?
达斯克应该帮你处理这事。我建议使用分散,而不是publish_dataset,因为它不像您认为的那样(我建议查看每个方法的docstring )。
https://stackoverflow.com/questions/61856435
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号