
过采样会产生新的数据点。
过采样会产生新的数据点。
提问于 2020-03-17 11:29:36
我试图解决一个不平衡的分类问题,所有的输入功能都是分类的。以下是每个功能的值计数:
for i in X_train.columns:
print(i+':',X_train[i].value_counts().shape[0])
Pclass: 3
Sex: 2
IsAlone: 2
Title: 5
IsCabin: 2
AgeBin: 4
FareBin: 4在train_test_split后,在训练数据上应用SMOTE。创建了一些新值,这些值在X_train数据集中不存在。
from imblearn.over_sampling import SMOTE
from collections import Counter
#removing the random_state dosent help
sm = SMOTE(random_state=0)
X_res, y_res = sm.fit_resample(X_train, y_train)
print('Resampled dataset shape %s' % Counter(y_res))
Resampled dataset shape Counter({1: 381, 0: 381})重放数据集的值计数:
Pclass: 16
Sex: 7
IsAlone: 2
Title: 12
IsCabin: 2
AgeBin: 4
FareBin: 4有一些新的值是通过使用SMOTE创建的,under_sampling的新值也是这样创建的。这些新值不存在于测试数据集中。
示例:
X_train-Pclass 1-20,2-15,3-40
X_res-Pclass 1-20,0.999999-3,2-11,1.9999999-4,3-34,2.9999999-6我的问题是:
- 为什么这些价值观是被创造出来的,它们是否具有一些重要意义?
- 怎么对付他们?我应该把它们围起来还是把它们移走?
- 是否有办法在不创造这些新的价值的情况下反复进行抽样?
回答 1
Stack Overflow用户
发布于 2020-03-17 12:20:27
如果数据集的类分布不均匀,这可能会在培训和分类的后期阶段造成麻烦,因为分类器用于学习特定类的特征的数据将非常少。
与普通的上采样不同,SMOTE利用最近邻算法生成新的合成数据,可以用来训练模型。
正如在这张原始的打孔纸中所说的,“通过抽取每个少数民族类样本,并在连接任意/所有k个少数类最近邻居的线段上引入合成示例,少数群体类被过度抽样。”
因此,是的,,这些新生成的合成数据点很重要,您不必太担心它们。SMOTE是执行此任务的最佳技术之一,因此我建议使用此方法。
例如,考虑以下图像:
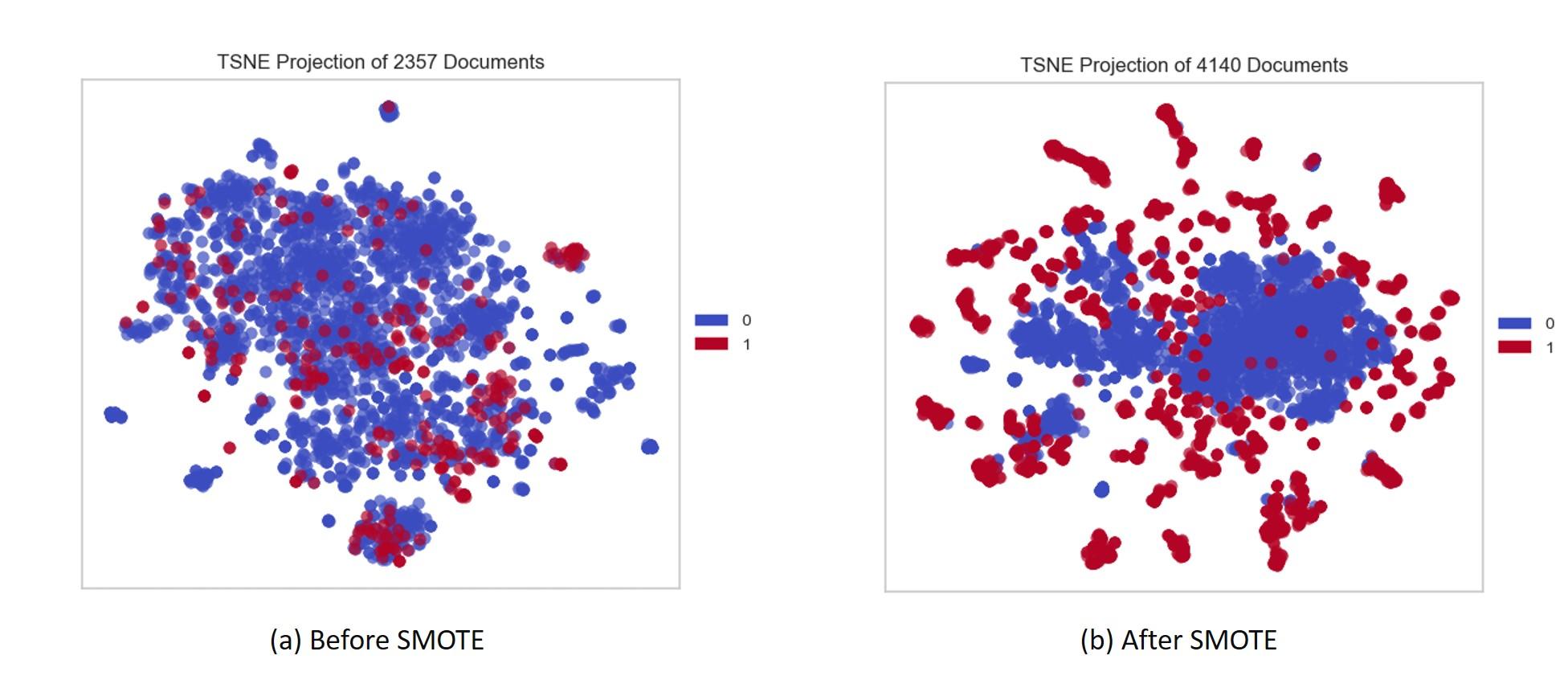
图a对于类0有更多的数据点,而对于类1则很少。
如您所见,在应用SMOTE (图b)之后,它将为少数派类(在本例中为类1)生成新的数据点,以平衡数据集。
试着阅读:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/60721496
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号