
我怎么能让麒麟990的NPU在TensorFlow Lite上工作呢?
根据TensorFlow,成功地将TensorFlow模型转换为TensorFlow Lite float16模型。
下面是转换模型的图表。
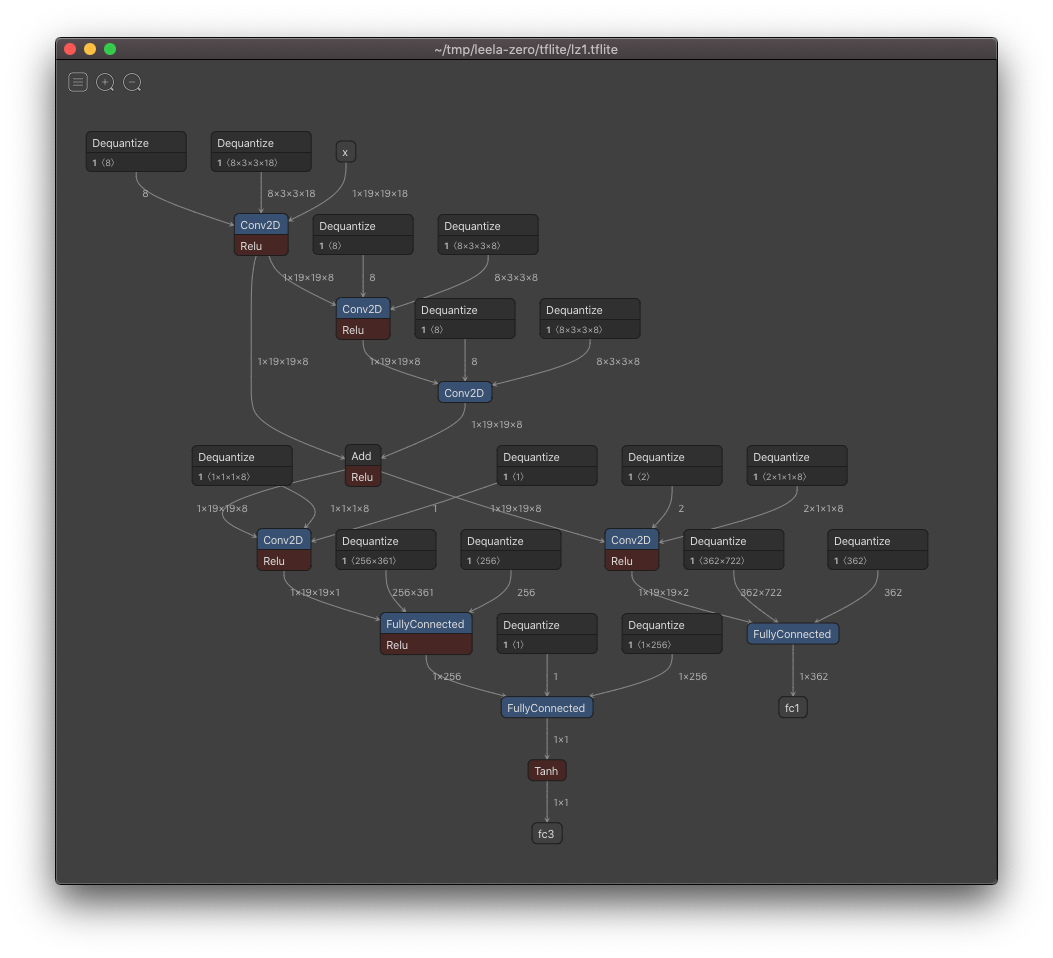
我用我的MatePad代码在C++ Pro(Kirin 990)上成功地运行了它。
我特别为NNAPI编写的是SetAllowFp16PrecisionForFp32和AllocateTensors之前的UseNNAPI。
m_interpreter->SetAllowFp16PrecisionForFp32(true);
m_interpreter->UseNNAPI(true);
m_interpreter->AllocateTensors();但表演不好。
我检查了adb logcat的日志,发现armnn和lite适配器(我认为两者都是华为的NNAPI驱动程序)无法支持主要的操作,比如CONV_2D和NNAPI引用,即NNAPI的CPU实现。
信息如下所示。
AndroidNN: AnnOpConvParser::isSupport1_1(280)::"Conv para is model Input err"为什么NNAPI驱动程序(nnapi引用除外)不能支持操作?
我怎么才能修好它呢?
我想知道转换模型中的去量化操作不应该存在,每个操作都应该有float16参数。
我不知道我的猜测是正确的,即使这是正确的,我不知道消除去量化运算。
(当然,我尝试了float32转换模型。float32模型的输出在SetAllowFp16PrecisionForFp32(false)和SetAllowFp16PrecisionForFp32(true)之间有很大的不同。
因此,我得出结论,NNAPI需要float16量化。)
以下是观察的摘要。
假设setUseNNAPI(真),
- float32模型和SetAllowFp16PrecisionForFp32(true)允许lite适配器工作,但是输出是错误的。
- float32模型和SetAllowFp16PrecisionForFp32(false)允许armnn作为后盾。
- float16模型和SetAllowFp16PrecisionForFp32(真或假)让nnapi参考工作作为后盾。
请给我建议!
回答 1
Stack Overflow用户
发布于 2020-06-23 01:10:18
我发现它没有在NPU上运行的原因如下。
- float16量化阻止了它的发生。
- 不支持的操作不仅会导致CPU操作的退步,而且会导致整个模型编译的失败。
一个更简单的模型运行在NPU上而不改变代码。
https://stackoverflow.com/questions/62466840
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号