
计算损失时的Keras值
计算损失时的Keras值
提问于 2021-01-09 13:56:32
我的问题与这一个有关
我正在努力实现tM5RY8Hv-opK4Z-H/view文章中描述的方法。最后使用的算法在这里(它在第6页):

- D是单位向量
- xhi是一个非空数。
- D是损失函数(在我的例子中是稀疏交叉熵)。
其思想是进行对抗性训练,将数据修改到网络对小变化最敏感的方向,用修改过的数据训练网络,但使用与原始数据相同的标签。
用于训练模型的损失函数如下:
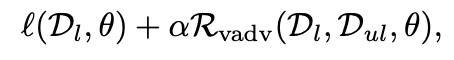
- L是标记数据上的损失度量。
- Rvadv是算法1图像中梯度内的值。
- 本文选择alpha =1
其思想是在损失中纳入标记数据集的模型的性能。
我试图在Keras中使用MNIST数据集和一个小型批处理的100个数据来实现这个方法。当我尝试做最后的梯度下降来更新权重时,经过几次迭代,我得到了出现的南值,我不知道为什么。我把笔记本贴在了可乐课上(我不知道它能坚持多久,所以我也把代码放在要点中):
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-01-10 01:57:07
这是NaN在培训中的一种标准问题,我建议您阅读亚当·索尔弗作为常见案例的原因和解决方案。
基本上,我只是做了两个变化和代码运行,没有NaN的梯度:
- 将
model.compile优化器的学习速度降低到optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3), - 将
C = [loss(label,pred) for label, pred in zip(yBatchTrain,dumbModel(dataNoised,training=False))]替换为C = loss(yBatchTrain,dumbModel(dataNoised,training=False))
如果您仍然有这样的错误,那么接下来可以尝试的几件事是:
- 裁剪损失或梯度
- 将所有张量从
tf.float32切换到tf.float64
下次遇到这种错误时,可以使用数字学查找NaN的根本原因。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65643459
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号