
Mlflow与KerasTuner集成
Mlflow与KerasTuner集成
提问于 2021-01-22 17:17:09
我正在尝试将KerasTuner和Mlflow集成在一起。我想记录每一次Keras Tuner试验的每一个时代的损失。
我的方法是:
class MlflowCallback(tf.keras.callbacks.Callback):
# This function will be called after each epoch.
def on_epoch_end(self, epoch, logs=None):
if not logs:
return
# Log the metrics from Keras to MLflow
mlflow.log_metric("loss", logs["loss"], step=epoch)
from kerastuner.tuners import RandomSearch
with mlflow.start_run(run_name="myrun", nested=True) as run:
tuner = RandomSearch(
train_fn,
objective='loss',
max_trials=25,
)
tuner.search(train,
validation_data=validation,
validation_steps=validation_steps,
steps_per_epoch=steps_per_epoch,
epochs=5,
callbacks=[MlflowCallback()]
)然而,损失值报告(顺序)在一个单一的实验。有办法独立记录吗?
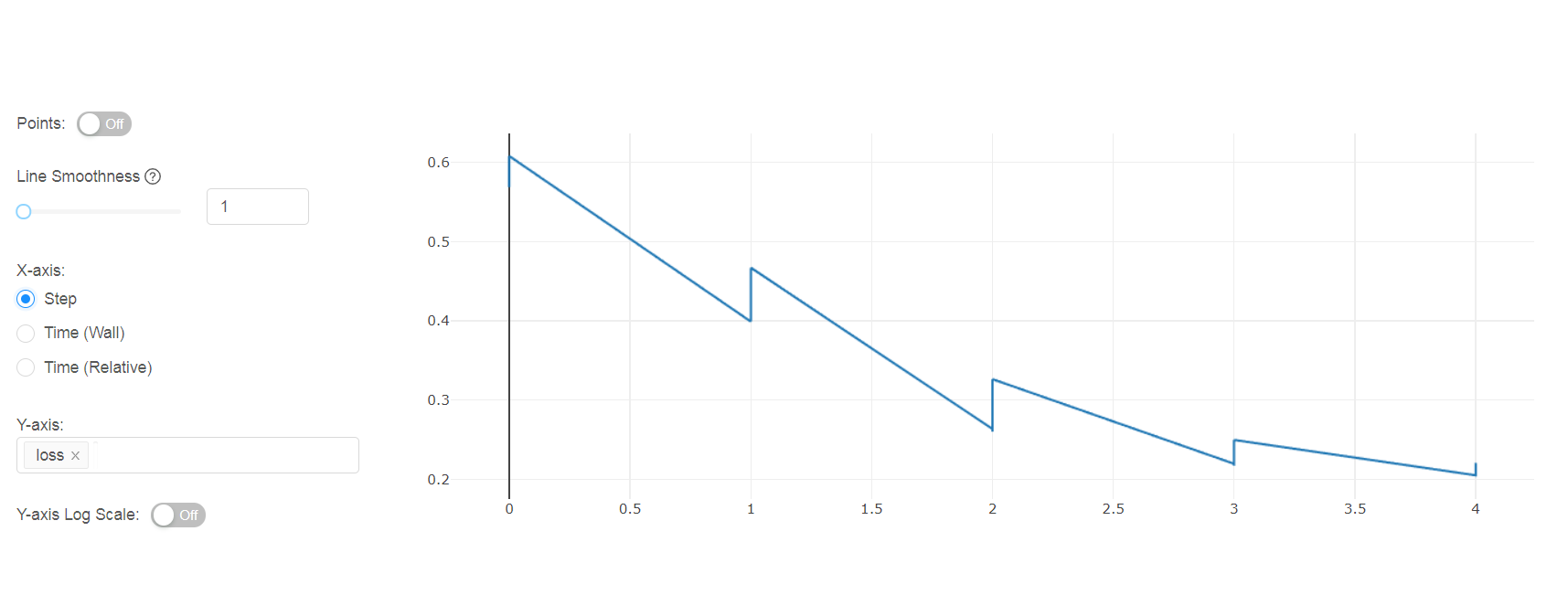
回答 2
Stack Overflow用户
发布于 2022-02-02 14:38:07
线
with `mlflow.start_run(run_name="myrun", nested=True)` as run:是什么导致每一次训练都存储在同一个实验中。不要使用它,mlflow会自动为tuner.search进行的每一次训练创建一个不同的实验
Stack Overflow用户
发布于 2022-12-02 15:06:22
答案非常简单,而不是使用回调,您需要像这样从HyperModel中子类KerasTuner:
# Create a HyperModel subclass
class SGNNHyperModel(keras_tuner.HyperModel):
def build(self, hp):
# Create your model, set some hyper-parameters here
model = SomeModel()
return model
def fit(self, hp, model, *args, **kwargs):
with mlflow.start_run():
mlflow.log_params(hp.values)
mlflow.tensorflow.autolog()
return model.fit(*args, **kwargs)然后像这样使用这个类:
tuner = BayesianOptimization(
SGNNHyperModel(),
max_trials=20,
# Do not resume the previous search in the same directory.
overwrite=True,
objective="val_loss",
# Set a directory to store the intermediate results.
directory="/tmp/tb",
)参考资料:
https://medium.com/@m.nusret.ozates/using-mlflow-with-keras-tuner-f6df5dd634bc
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65849787
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号