
测频谱图阵列
我需要一个记录频率的谱图。我目前正在使用scipy.signal.stft函数来获得一个震级数组。但是输出频率是线性间隔的。
import librosa
import scipy
sample, samplerate = librosa.load('sound.wav', sr=64000)
f, t, Zxx = scipysignal.stft(sample, fs=samplerate, window='hamming', nperseg=512, noverlap=256)我基本上需要f的日志间隔从1Hz到32 1Hz(因为我的声音有一个64千赫的采样)。
我只能拿到上面的声谱图。我需要底部光谱图的实际值数组。我可以通过各种可视化功能(librosa specshow,matplotlib yscaled等)获得它。但我找不到一个实际的二维数量级数组的解决方案,它的频率是对数间隔的。
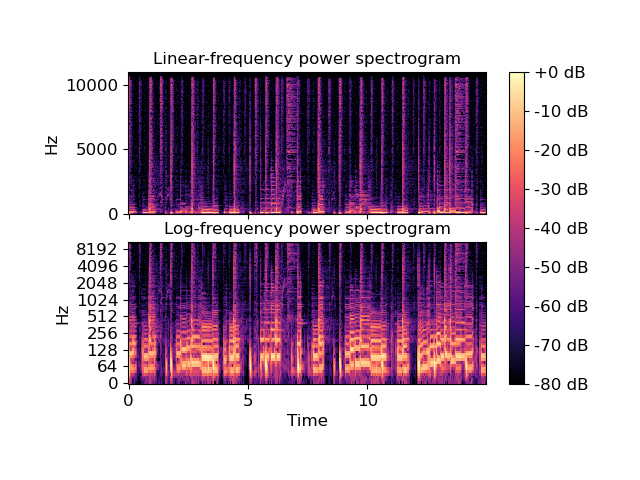
任何关于使用什么方法的帮助或提示都将受到极大的感谢!
回答 2
Stack Overflow用户
发布于 2022-08-26 13:03:32
我只是偶然发现了一个很好的解决你问题的方法。nnAudio库是一个以PyTorch卷积神经网络为后端的音频处理工具箱。虽然它也可以作为一个独立的解决方案。
安装时只需使用:
pip install git+https://github.com/KinWaiCheuk/nnAudio.git#subdirectory=Installation若要将音频转换为带有日志间隔的频率箱的谱图,请使用:
from nnAudio import features
from scipy.io import wavfile
import torch
sr, song = wavfile.read('./Bach.wav') # Loading your audio
x = song.mean(1) # Converting Stereo to Mono
x = torch.tensor(x).float() # casting the array into a PyTorch Tensor
spec_layer = features.STFT(n_fft=2048, hop_length=512,
window='hann', freq_scale='log', pad_mode='reflect', sr=sr) # Initializing the model
spec = spec_layer(x) # Feed-forward your waveform to get the spectrogram
log_spec =np.array(spec)[0]# cast PyTorch Tensor back to numpy array
db_log_spec = librosa.amplitude_to_db(log_spec) # convert amplitude spec into db representation 用librosa谱图绘制出的日志频率谱图使用y_axis=‘线性’标志将给出在实际的2d数组中表示的要求:)
plt.figure()
librosa.display.specshow(db_log_spec, y_axis='linear', x_axis='time', sr=sr)
plt.colorbar()该库还包含一个逆函数和大量其他特性:https://kinwaicheuk.github.io/nnAudio/intro.html
虽然制作了一个好看的日志-频率谱图,但我很难将STFT恢复回时间域。所包含的iSTFT对我来说不起作用。也许其他人能从这里捡起来?
Stack Overflow用户
发布于 2022-08-30 11:00:00
实际上,为了记录在案,我发现我需要做的是做一个恒Q变换,这正是一个基于日志的光谱图。但你选择的起始频率,在我的例子中,非常有用。为此,我使用了librosa.cqt
https://stackoverflow.com/questions/73381525
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号