
对于线性回归,有改进DNN的方法吗?
对于线性回归,有改进DNN的方法吗?
提问于 2022-02-01 14:26:42
我正在创建一个用于线性回归的深度神经网络。该网络有3个隐藏层,每层256个单位。以下是模型:
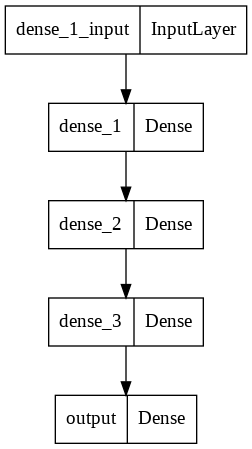
每个单元都有ReLU作为激活函数。我还用了早停,以确保它不过分适合。
目标是一个整数,在训练集中,它的值从0到7860。
经过训练,我损失了以下几分:
train_MSE = 33640.5703, train_MAD = 112.6294,
val_MSE = 53932.8125, val_MAD = 138.7836,
test_MSE = 52595.9414, test_MAD= 137.2564我尝试过许多不同的网络配置(不同的优化器、丢失函数、规范化、正则化.)但似乎没有什么能帮助我进一步减少损失。即使训练误差减小,测试误差也不会低于MAD = 130的值。
以下是我的网络行为:
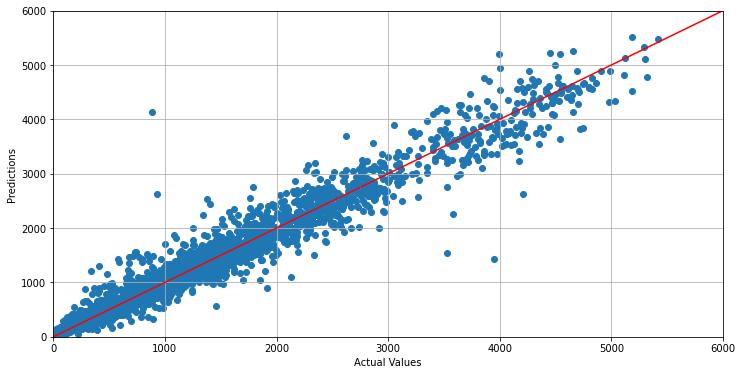
我的问题是,是否有一种方法可以提高我的能力来做出更准确的预测,或者这是我能用我的数据集达到的最好的结果?
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-02-01 16:45:14
如果您的问题本质上是线性的,这意味着数据后面的真正函数是from:y = a*x + b + epsilon,其中最后一个项只是随机噪声。
您将不会比拟合底层函数y = a*x + b更好。拟合espilon只会导致对新数据的泛化损失。
Stack Overflow用户
发布于 2022-02-01 14:36:04
你可以尝试很多不同的方法来改进DNN,
Activation
- Take
- 增加隐藏层
- 规模或规范化数据
- 尝试校正线性单元,因为 More data
- 会改变学习算法参数,如学习速率
<代码>G 211
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70942213
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号