记忆不是被检索出来的,而是被重建出来的:给 LLM Agent 装上一颗会联想的大脑

记忆不是被检索出来的,而是被重建出来的:给 LLM Agent 装上一颗会联想的大脑

唐国梁Tommy
发布于 2026-06-25 21:49:46
发布于 2026-06-25 21:49:46

一个 AI 助手反复栽跟头的小场景
设想你和一个 AI 助手聊了三个月。某天你问它:「我朋友 Caroline 七月那会儿在忙什么来着?」
今天主流的「记忆增强」Agent 大多会这样做:把你的问题丢进一个向量库,按语义相似度捞出一批最相关的片段,然后基于这堆片段作答。问题是,你这句话里几乎没有「Caroline 七月」的直接线索——相似度搜索只会捞回一大堆和「朋友」「最近」沾边的噪声,唯独漏掉真正的答案。
论文链接:https://arxiv.org/pdf/2606.06036
而一个真正像人的助手会怎么想?它会先愣一下,顺着记忆往回捋:七月……那段时间我们聊过 Nate 的电竞比赛,那场比赛正好是七月办的,Caroline 当时还提过她那阵子在准备一个剧本投稿——找到了。

这两种方式的差别,正是这篇来自新加坡国立大学(Bryan Hooi 团队)的论文想讲清楚的事。它的标题本身就是一句宣言:记忆是被重建的,而不是被检索的(Memory is Reconstructed, Not Retrieved)。论文提出的系统叫 MRAgent,核心洞见来自认知神经科学:人脑回忆从来不是「打开抽屉拿出一张照片」,而是由线索触发、一步步把碎片拼回完整经验的主动过程。
长程记忆,为什么是 LLM 的阿喀琉斯之踵
大模型有一种被研究者称为「锯齿状」的能力画像:做数学、写代码出类拔萃,可一旦任务需要在很长的交互历史里持续记事、跨越多次对话去回溯,它就明显力不从心。根子在于有限的上下文窗口——再长的窗口也装不下三个月的聊天记录。
于是大家给 Agent 外挂「记忆系统」。从最早的 RAG(把历史切块存进向量库、按相似度召回),到后来更结构化的知识图谱式记忆(显式记录实体与关系),方案越来越复杂。但论文一针见血地指出:这些系统骨子里都是被动检索。
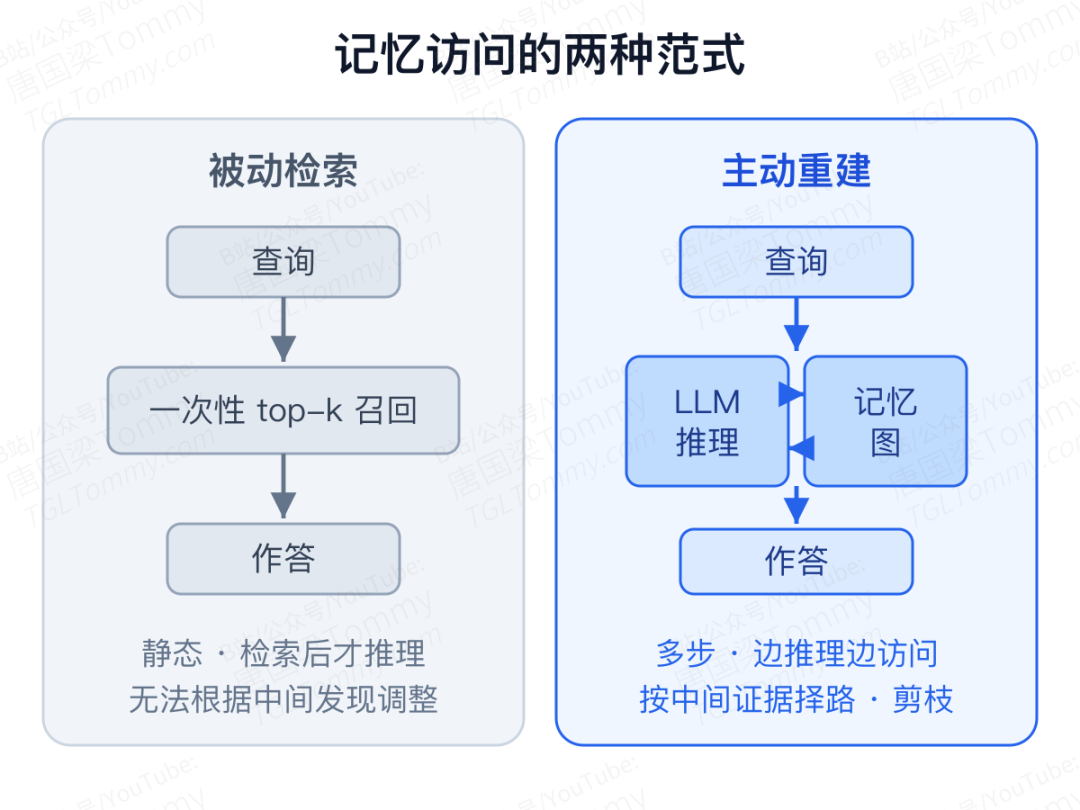
被动检索可以归成两类,它们各有一道天花板:
- 相似度检索(如 Mem0、MemoryBank):只看问题和记忆片段表面的语义相似度,做一次性的 top-k 召回。线索一旦藏在字面之下(比如那个关键的「七月」),它就抓瞎。
- 图结构检索(如 A-Mem、Zep):在相似度种子的基础上,再机械地向外扩展 N 跳邻居。可一旦正确证据和查询不在图里直接相连,扩得再多也够不着,反而把一堆无关邻居一起拖进来当噪声。

论文把被动检索的病灶概括成一句话:它没法在访问记忆的同时进行推理。由此带来三个硬伤——无法根据中间发现修正策略(比如临时意识到「七月」是个时间锚点)、固定聚合方式不断累积噪声、过度依赖预先建好的结构因而难以扩展。
向大脑借一个设计:联想,然后重建
人脑是怎么做的?认知神经科学给出的图景是:回忆是一个序贯展开的重建过程。某个上下文线索先激活一小片「记忆痕迹」(engram),这片痕迹的激活又会反过来约束、偏置接下来能想起什么,如此一环扣一环,逐渐拼出一段连贯的记忆。而记忆本身又分两种——记录具体事件的情景记忆,和沉淀概念与知识的语义记忆。
MRAgent 几乎是照着这套机制来搭的。它要解决两个问题:其一,怎么把记忆访问从「一次性检索」变成「多步重建」;其二,怎么把记忆组织得便于联想式探索。答案分别落在两件东西上——一张关联记忆图,和一套主动重建机制。
第一块拼图:Cue–Tag–Content 关联记忆图
MRAgent 不把记忆存成一堆扁平的可检索条目,而是组织成一张异构图,核心结构是 Cue–Tag–Content(线索–标签–内容):
- Cue(线索):细粒度的关键词,比如某个实体、某个属性;
- Content(内容):具体的记忆条目;
- Tag(标签):连接线索与内容的「带类型的关系」,是整套设计的点睛之笔。
标签的妙处在于它充当了语义桥梁。检索因此被拆成两步:先用线索点亮一小撮相关的标签,再顺着选中的标签去取具体内容。这样一来,Agent 可以在还没碰到昂贵的长篇情景内容之前,就靠标签判断「这条路值不值得走」,从而剪掉无关分支——既避免了 N 跳邻居那种组合爆炸,又比纯相似度多了一层语义引导。
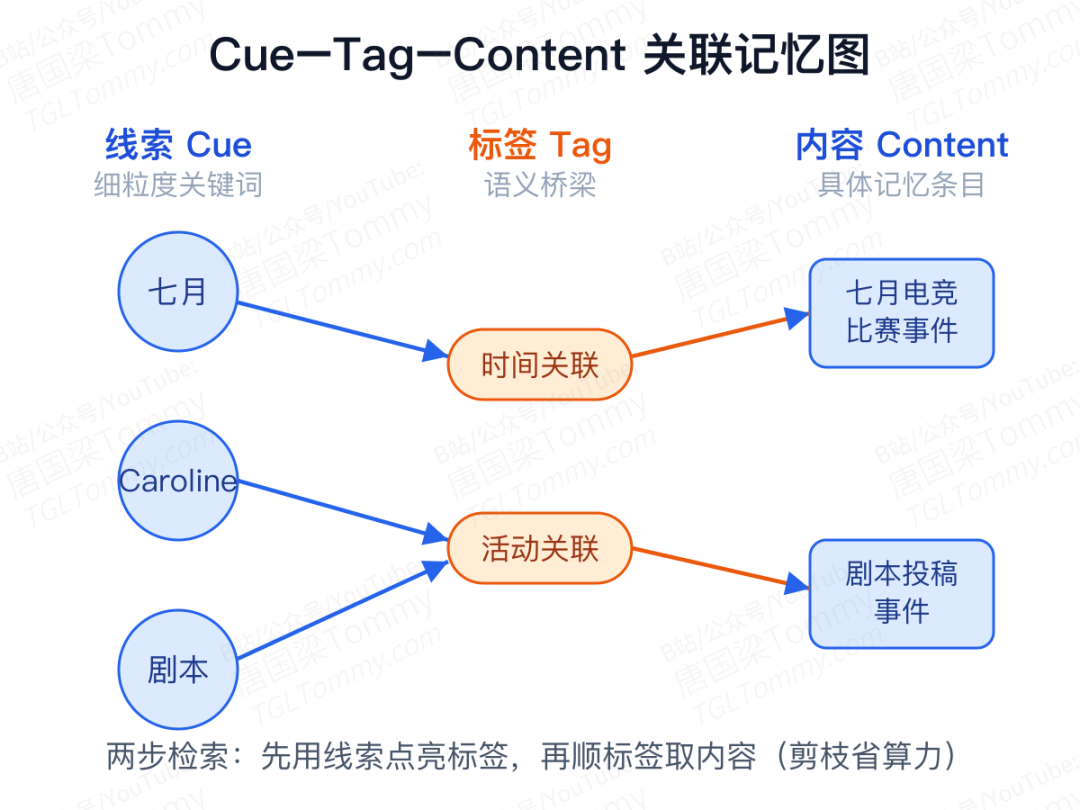
这张图还按人脑的样子分了三层:情景层(Cue–Tag–Episode,沿统一时间线组织,专门支持「七月」这类时间推理)、语义层(Cue–Tag–Semantic,存人物属性、偏好、稳定事实,不必每次都翻长长的事件流)、以及更高一层的主题抽象层(把反复出现的模式归纳成主题节点,支持自顶向下先定位主题、再下钻到具体事件)。整张图由一条 LLM 蒸馏流水线自动构建:把输入流切成事件单元,再用 LLM 抽取标签与线索连成关系。

第二块拼图:把推理塞进记忆访问的「主动重建」
有了图,MRAgent 真正的引擎是主动重建过程。它不再执行一条写死的检索流水线,而是维护一个重建状态:当前可供下一步探索的「活跃元素集合」,加上之前已经积累下来的「重建上下文」。
在这张图上,Agent 可以做的动作既有正向(线索→标签、「线索+标签」→内容),也有反向(内容→「线索+标签」)——反向动作让已经取到的内容反过来激活新的线索,从而调头或改道。
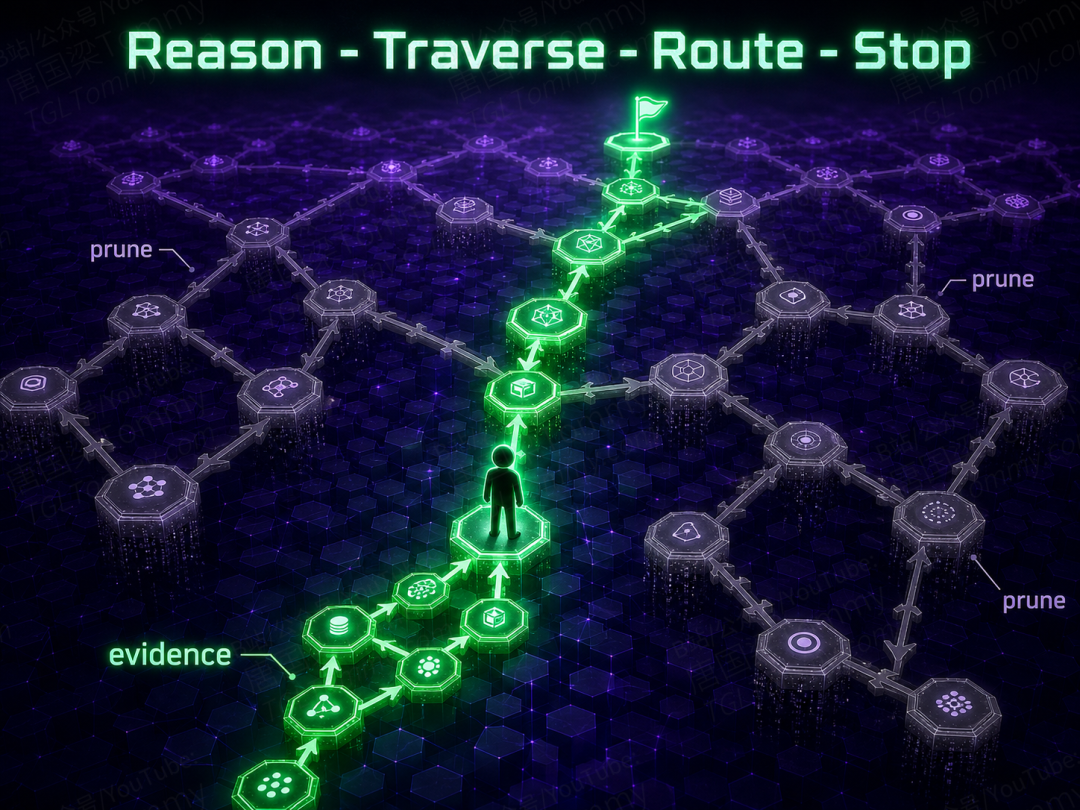
整个过程是一个循环:
- LLM 推理与动作选择:结合查询和已积累的上下文,挑选这一步该往哪些方向扩展;
- 受控记忆遍历:执行选中的遍历动作,生成候选节点(注意是 LLM 挑方向,而不是穷举式地全图扩展);
- LLM 路由与状态更新:从候选里留下最相关的、剪掉无关分支,让上下文始终保持精炼;
- 判断是否收敛:评估现有证据是否足以回答,不够就再来一轮。
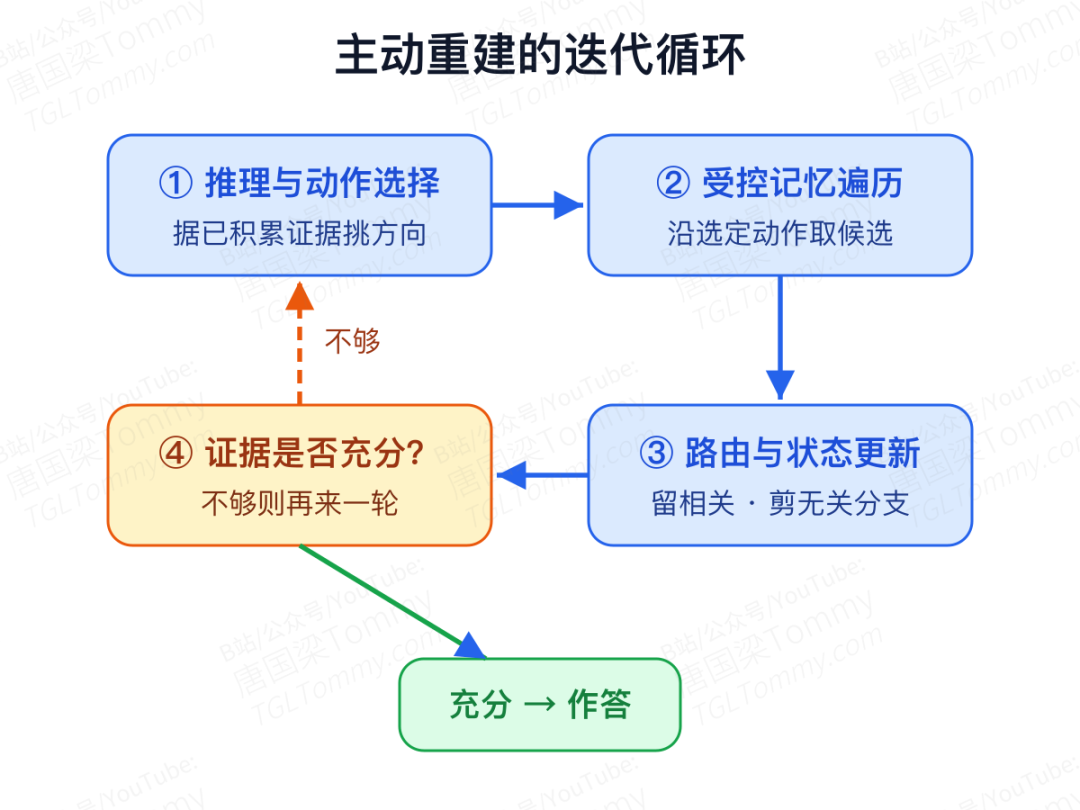
这正是开篇那个场景里「先想到七月、再顺藤摸到 Caroline」的过程——把中间发现实时变成新的检索约束,去够到被动策略永远够不到的证据。
论文还给了一条理论背书:在同样的检索预算下(步数 T≥2),主动检索严格强于被动检索——主动策略能表达的输入输出映射,是被动策略的真超集。他们甚至构造了一个「二叉树里捞针」的任务族证明:主动检索能做到零误差,而被动检索除非把预算开到指数级,否则误差无法消除。
数据说话:更准,而且更省
光有漂亮的故事不够,关键看数。论文在两个长程记忆基准 LoCoMo 和 LongMemEval 上,对比了 RAG、LangMem、A-Mem、MemoryOS、Mem0 等一众强基线,分别用 Gemini-2.5-Flash 和 Claude-Sonnet-4.5 两个底座。
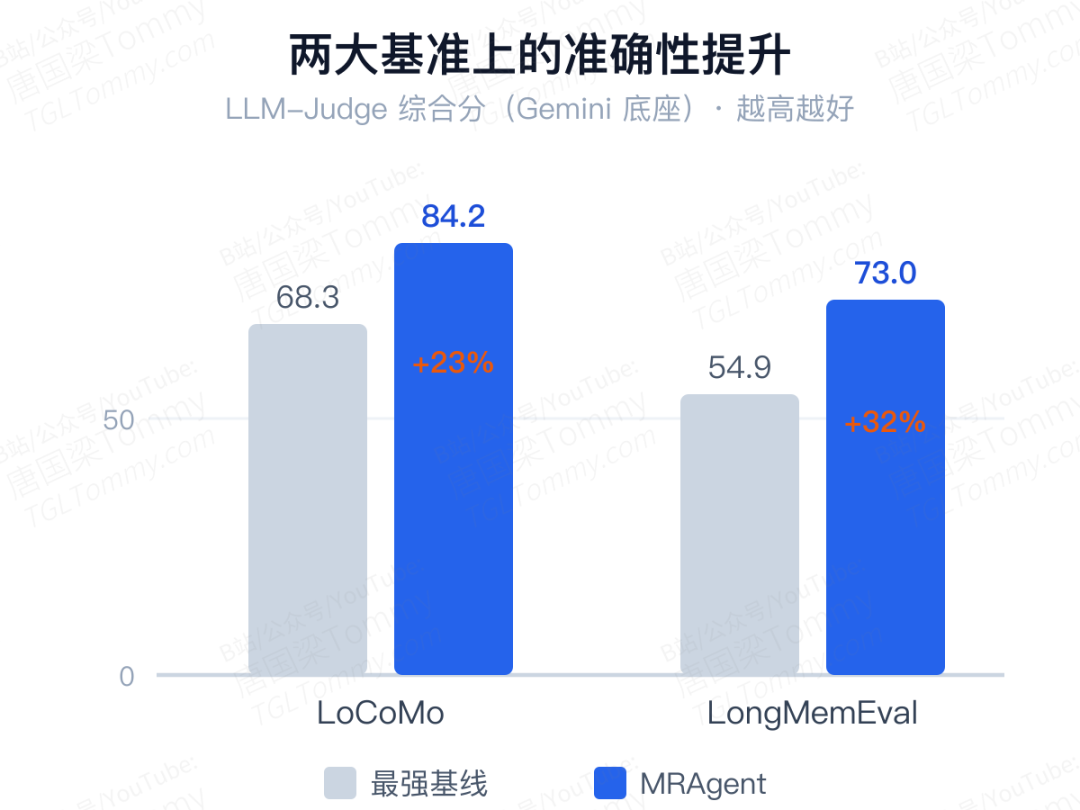
准确性——在 LoCoMo 上,以 LLM-Judge 综合分计,Gemini 底座下从最强基线的 68.31 提到 84.21(相对提升约 23%),Claude 底座下进一步做到 88.32。在交互更长、跨多轮会话的 LongMemEval 上,相对最强基线提升约 32%;而当用 Gemini 建记忆、换 Claude 来检索时,综合分一路冲到 86.76。提升最明显的恰恰是最难的多跳和时间推理类问题——这正是被动检索最容易翻车的地方。
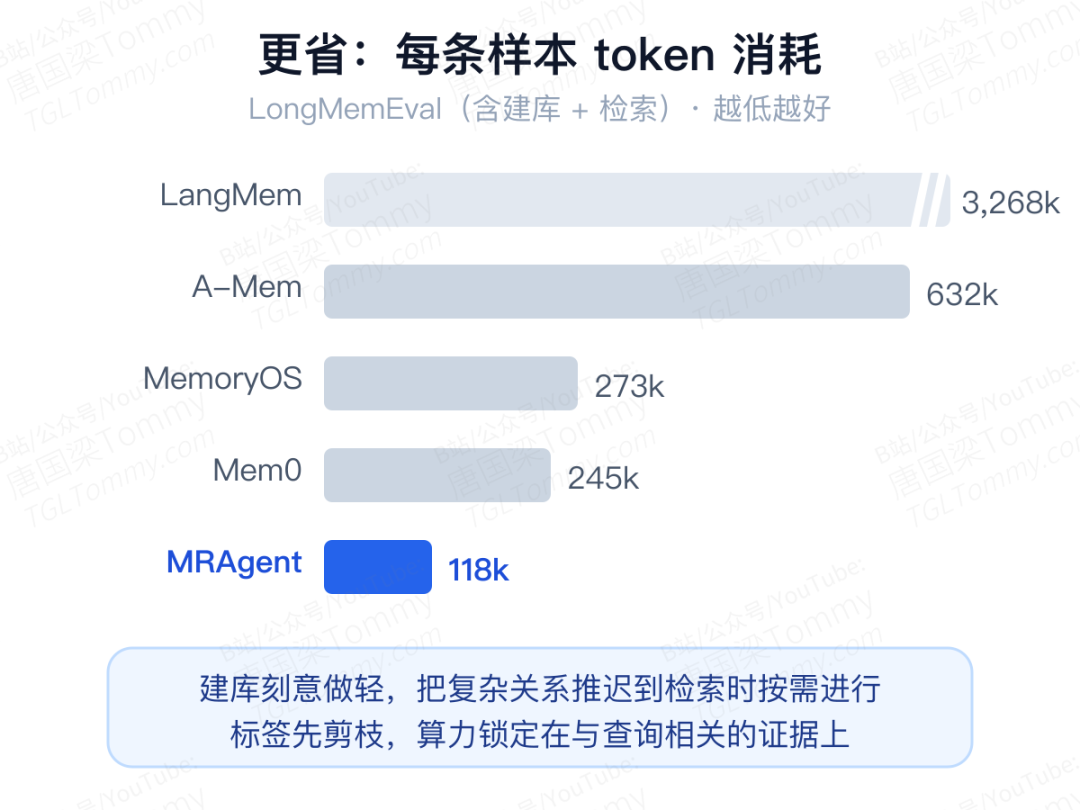
成本——这才是让人眼前一亮的部分。在 LongMemEval 上按每条样本统计(含建库与检索):
方法 | Token 消耗 | 运行时间(秒) |
|---|---|---|
A-Mem | 632k | 1,122 |
MemoryOS | 273k | 3,135 |
LangMem | 3,268k | 1,209 |
Mem0 | 245k | 533 |
MRAgent | 118k | 586 |
MRAgent 把 token 压到 118k,是众多基线里最低的,比动辄六位数、甚至三百多万 token 的方案省出一大截。原因也顺理成章:它的建库阶段刻意做得很轻,把「梳理复杂关系」这件重活推迟到检索时、按当前问题的需要按需进行;再加上标签先帮忙剪枝,算力被牢牢锁定在和查询相关的证据上。又准又省,而不是用更多算力换准确率,这是它最有说服力的地方。
拆开看:到底是哪一部分在起作用
消融实验把功劳拆得很清楚。沿着 CE(线索直连事件)→ CTE(加入标签中介)→ CTC(完整结构)逐步加料,即便不做多步推理,性能也单调上升——说明标签确实在提供有效的语义引导。而在每种结构上,开启多步推理(蓝条)都稳定碾压只靠结构的版本(绿条),证明主动多步推理才是性能跃升的主因,一次性检索根本啃不动多跳问题。此外,去掉语义记忆层会明显掉点,说明情景记忆与语义记忆是互补的。
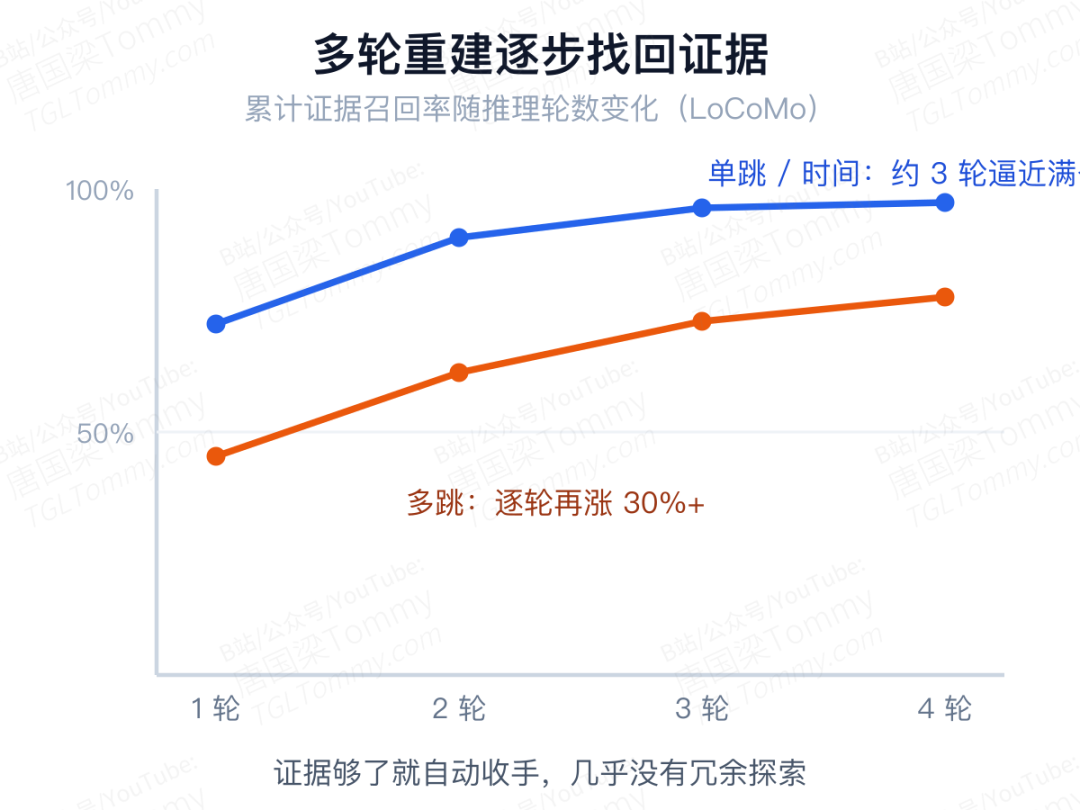
多轮分析则给出一张很直观的图景:单跳和时间类问题大约三轮就逼近满召回,而多跳问题在逐轮探索中召回率能再涨 30% 以上;更难得的是,Agent 能自己判断「证据够了该收手」——平均轮数和有效轮数几乎贴合,几乎没有冗余探索。论文还补了一刀:一味加大并行检索预算,替代不了更深的重建层数。
它意味着什么,又还差什么
把这篇论文放回到大背景里看,它真正动的是一个范式假设:记忆系统不该是一个被动的「上下文供应商」,而应是一个会推理、会联想、会自己决定何时收手的主动参与者。当我们越来越期待 AI Agent 陪伴我们几个月、几年,能不能优雅地回溯长程记忆,可能比再多记住几条事实更重要。

当然也要冷静看待边界。MRAgent 的主动重建严重依赖底座模型的推理质量——它本质上是把记忆访问交给 LLM 来「开车」,底座越弱,路由和剪枝的判断就越不可靠(这也解释了为什么换上更强的 Claude 来检索,分数会再上一个台阶)。它目前的验证集中在对话型长程记忆基准上,迁移到代码、多模态、超大规模知识库时表现如何,仍有待检验。多步重建虽然总体省 token,但相比一次性检索引入了更多轮 LLM 调用,在对延迟极度敏感的场景里,这笔账需要重新算。
但方向是清晰的。下一代 Agent 的记忆,也许真的会越来越像我们自己的记忆——不是一座冷冰冰的档案库,而是一张随时能被一缕线索点亮、然后顺着联想一路重建下去的网。
🌟 关注“唐国梁TGLTommy”,一起持续追踪 AI 技术演进背后的长期趋势。
#大模型Agent #AI智能体 #AI大模型 #强化学习 #agentrl #Agent记忆 #AI论文 #LLM
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号