自主科研 AutoResearchClaw :用五个机制把"流水线"变回了"循环"

自主科研 AutoResearchClaw :用五个机制把"流水线"变回了"循环"

唐国梁Tommy
发布于 2026-06-25 21:43:48
发布于 2026-06-25 21:43:48
如果你最近关注 AI for Science,多半见过这样一条故事线:从一句研究问题出发,AI 自动查文献、写代码、跑实验、出论文。几分钟一篇 paper,听起来像科研的 ChatGPT 时刻。
但真正坐过实验室的人都知道:科研最难的部分从来不是"把想法写成 paper"。难的是想法被质疑了之后怎么办、实验跑挂了之后怎么办、做了二十次发现方向不对怎么办。这些"挂掉之后"的事,恰好是当前绝大多数自主科研系统会原地停摆的地方。

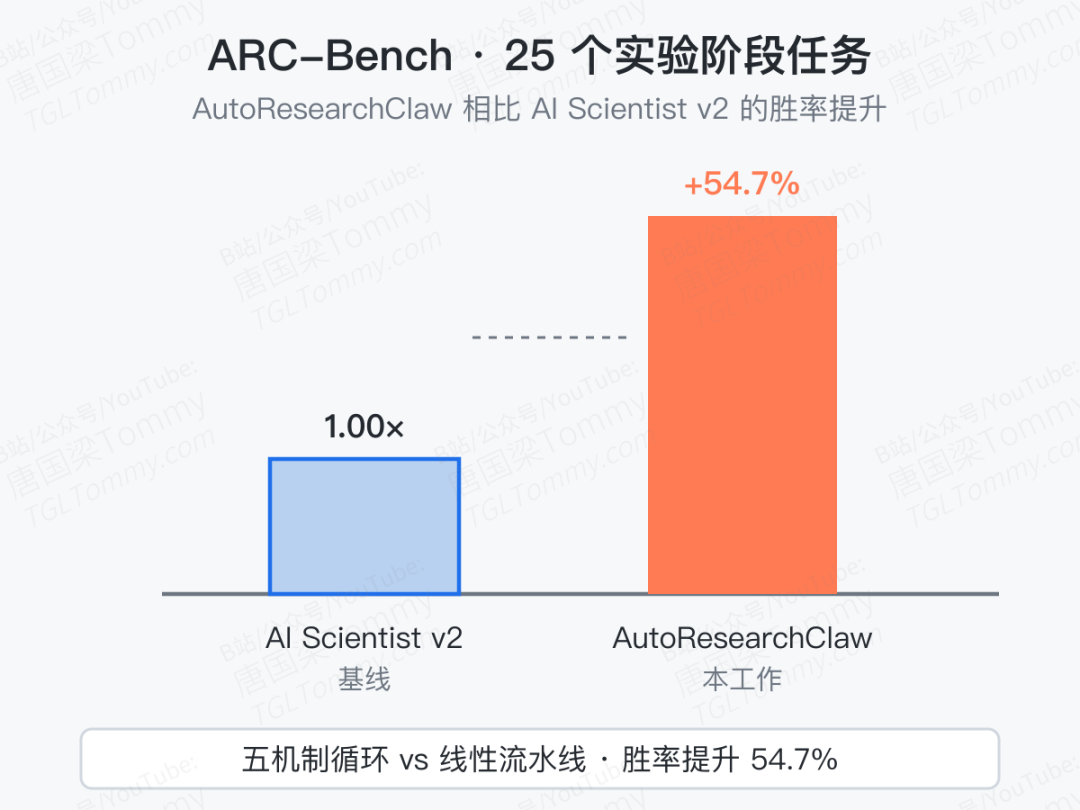
来自 UNC、Salesforce、Stanford 等十几家机构的一支联合团队提出了一个叫 AutoResearchClaw 的多智能体科研流水线,正是冲着这个"停摆点"去的。它把自主科研当成一个会自愈、会反思、会跨轮积累经验的循环,而不是一条线性的传送带。在他们自建的 ARC-Bench(25 个实验阶段任务)上,相比 AI Scientist v2 拿到了 54.7% 的胜率提升。

自主科研系统的根本误读:把循环当成了流水线
读完这篇论文,最大的体感是:作者并不打算多堆一个 agent、多调一次 GPT,他们想纠正一个架构层面的误读。
现有的大多数 autonomous research 系统,本质上长这样:单个 agent 拿到 idea → 写代码 → 跑实验 → 写报告。有任何一步挂掉,整条链断掉,整次运行作废。而且下一次运行,系统完全不记得上一次因为什么挂掉。

这种结构有三个隐性假设:研究是线性的;单 agent 的判断足够稳;失败=结束。可凡是真做过研究的人都清楚,三条都不成立。真正的研究是循环的——假设要被多角度挑战,实验失败本身是信息,经验要跨轮累积。
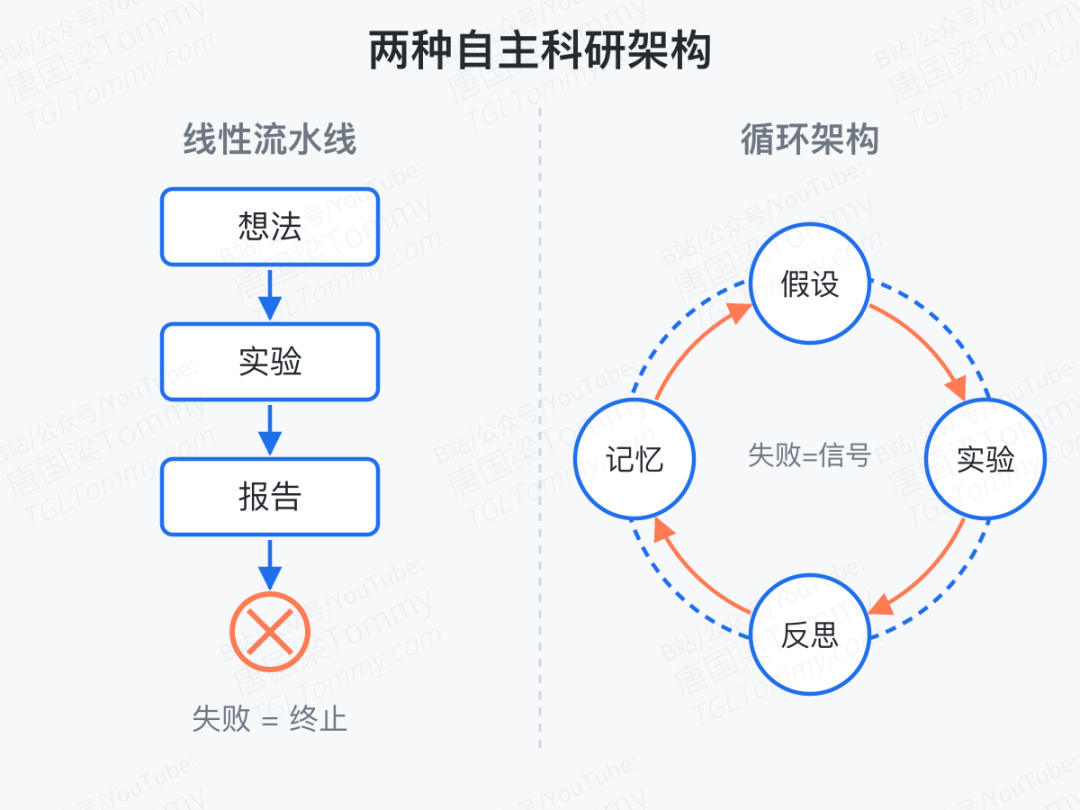
AutoResearchClaw 把整套系统重新建模成一个循环过程:每一次失败、每一次质疑、每一轮跨实验的经验,都被设计成喂回系统的输入,而不是终止信号。
辩论 + 自愈:让系统在失败中学习
要把流水线改造成循环,第一道关键改造是把"单 agent 单次判断"换成"多 agent 结构化辩论"。

在 AutoResearchClaw 里,假设生成和结果分析这两个最容易"一言堂"的环节,都被设计成多智能体辩论:不同 role 的 agent 从不同角度挑战提案,分歧被显式记录,由协调 agent 综合输出。一个假设要"活下来",得先扛过同伴的反驳——这和真实科研组会的样子很像。
第二道改造更关键,叫 self-healing executor。当代码跑挂,系统不会傻等用户接手,而是进入一个 Pivot / Refine 决策环:
- Refine:错误是小修——比如包没装、参数写错、shape 对不上——就在原方向上修正后重试;
- Pivot:错误暴露了方向性问题——比如这个方法根本算不动——就主动调整实验设计,而不是死磕到底。
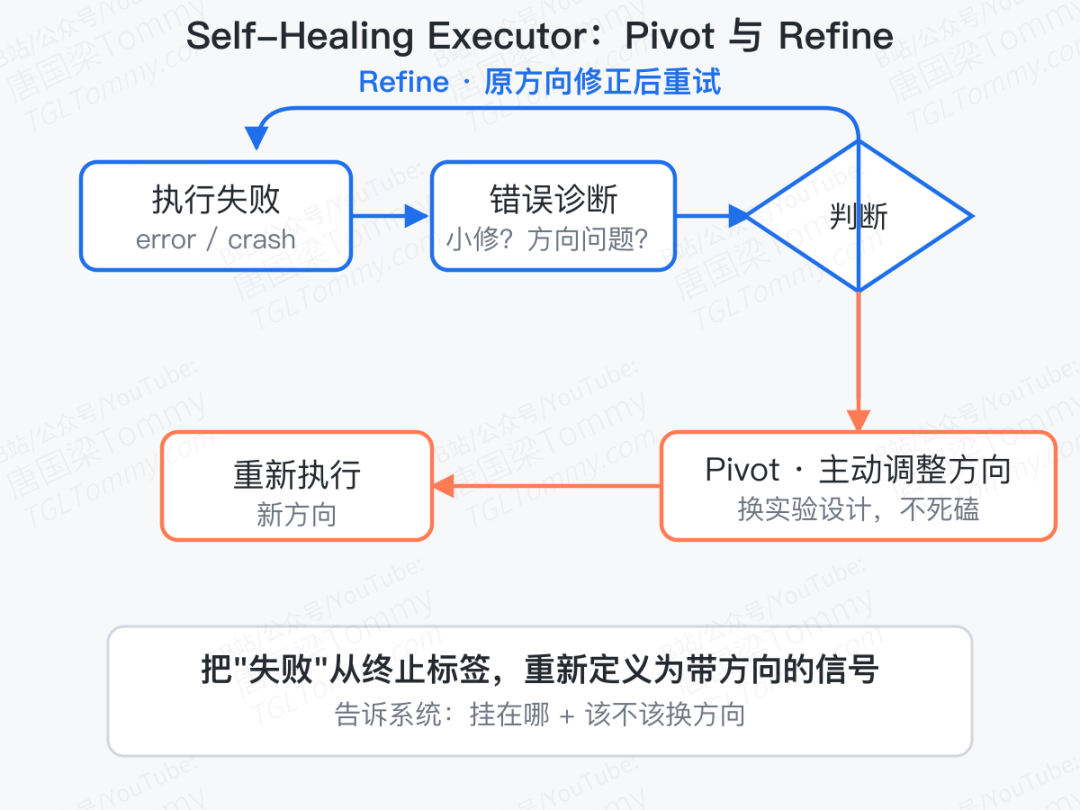
这个机制最妙的地方在于:它把"失败"从二元的成功/失败标签,重新定义为一种带方向的信号。失败现在告诉系统两件事——挂在哪里、该不该换方向。这一步从根上改变了系统对错误的态度。
拒绝编造数字:可验证的结果报告
LLM 科研系统最让人不放心的,从来不是"它的实验没做完",而是"它说做完了但其实没做"。一个会编实验数字、编引用的 agent,写出来的 paper 看起来天衣无缝,实际上是垃圾。
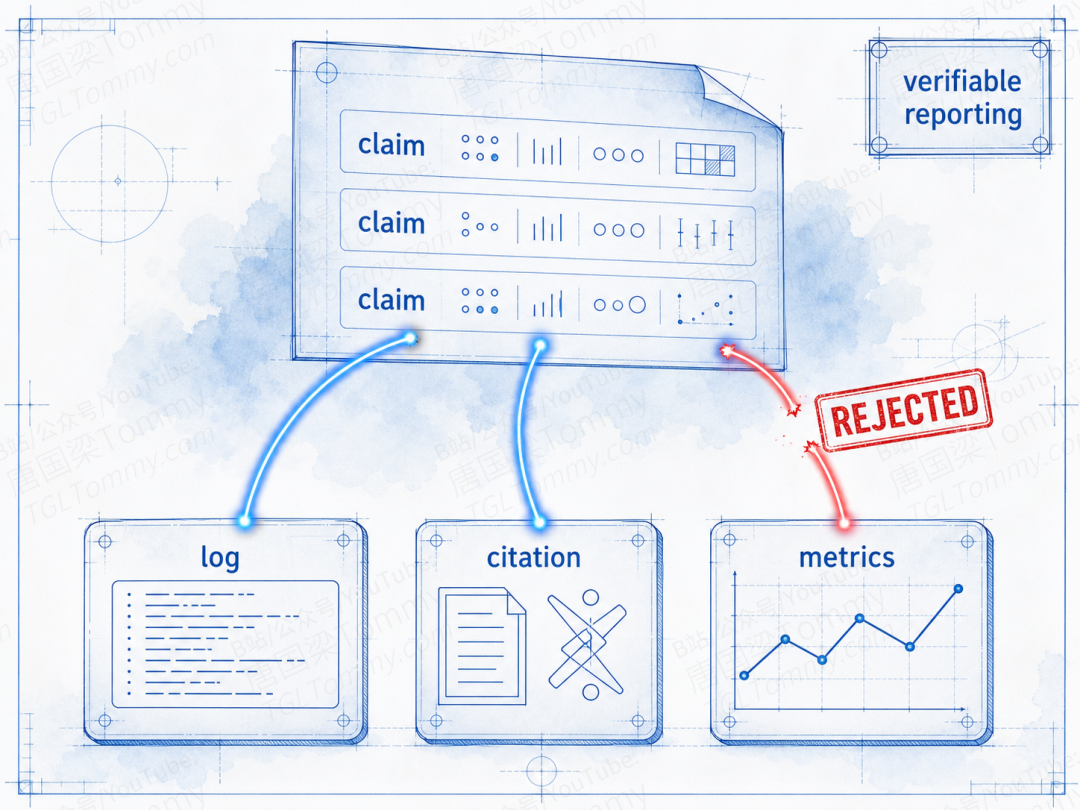
AutoResearchClaw 设了一个 verifiable result reporting 层:报告中出现的每一个数字、每一条引用、每一个 claim,都必须能被反向追溯回真实的实验日志或可达的文献。没有真实痕迹的内容会被该层直接打回,不允许进入最终报告。
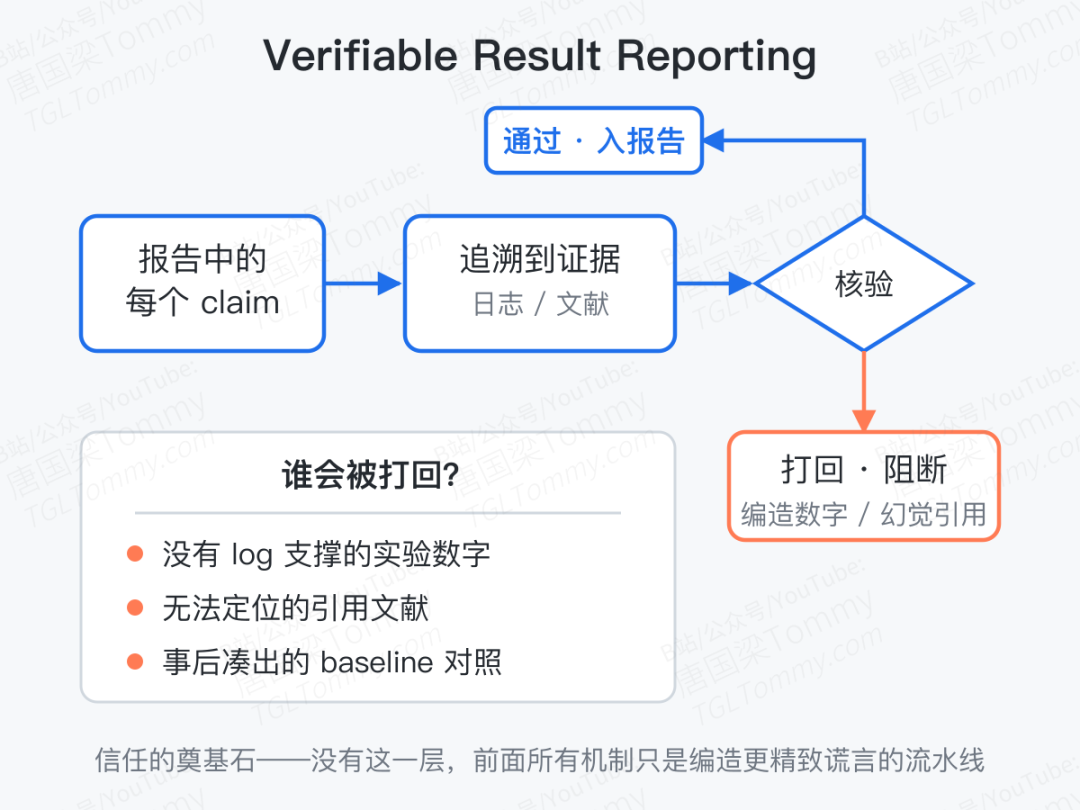
这听起来像是工程层面的小事,但在自主科研里其实是信任的奠基石。没有这一层,前面所有的多智能体辩论、自愈循环都成了"为编造一个更精致的谎言而生的流水线"。论文里把这条机制单列出来强调,分寸感是对的。
七种人机协作模式:精准比"全程监督"更有效
整篇论文里我最喜欢的一节,是关于人到底应该在什么时候介入的实验。

作者沿着"完全自主 ←→ 每一步都需要人确认"这条轴,设计了 7 种 intervention modes,从最 hands-off 到最 hands-on 都覆盖了。然后他们在 ARC-Bench 上做了一个非常诚实的 ablation:到底哪种合作模式效果最好?
结果略反直觉——全程监督并不是最好,全自主当然也不是。赢家是"在高杠杆决策点做精准、有目标的合作"。换句话说,让人审 100 个决定,效果反而不如让人专注审那 3-5 个真正改变方向的决定。
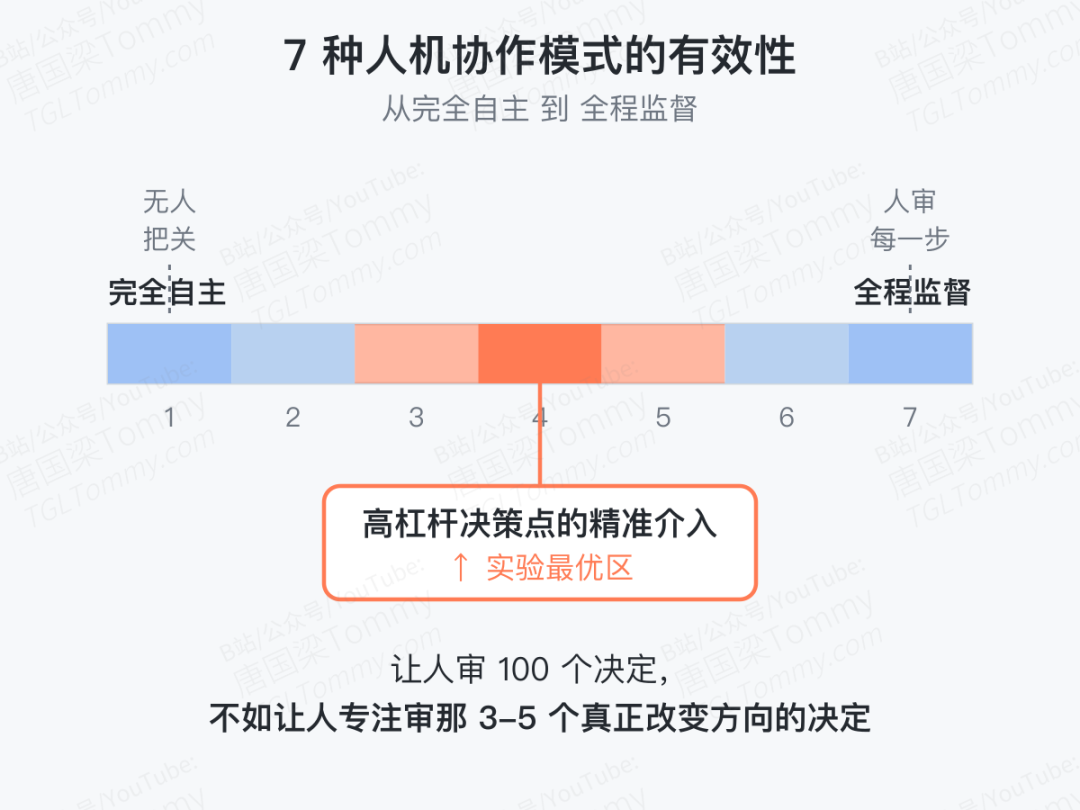
这个发现对实际落地非常有意义:它意味着自主科研系统不应该追求"完全无人"作为光荣勋章,反而应该精心设计若干 high-leverage 检查点,把人的判断力用在刀刃上。这一步也是 AutoResearchClaw 把自己定位为 "research amplifier 而非 replacer" 最有力的实证。
跨轮进化:把昨天的错误变成明天的护栏
最后一个机制叫 cross-run evolution——这是把"循环"两个字落到实处的一笔。

传统系统每次运行都是孤立的:上次因为 OOM 挂了,下次照样会因为 OOM 挂;上次因为某个 baseline 选错而结论翻车,下次照样会犯。AutoResearchClaw 把每一轮运行结束后的复盘信息——错误模式、被验证失败的假设、被 Pivot 掉的方向——结构化沉淀下来,变成下一轮运行启动时的护栏与提示。
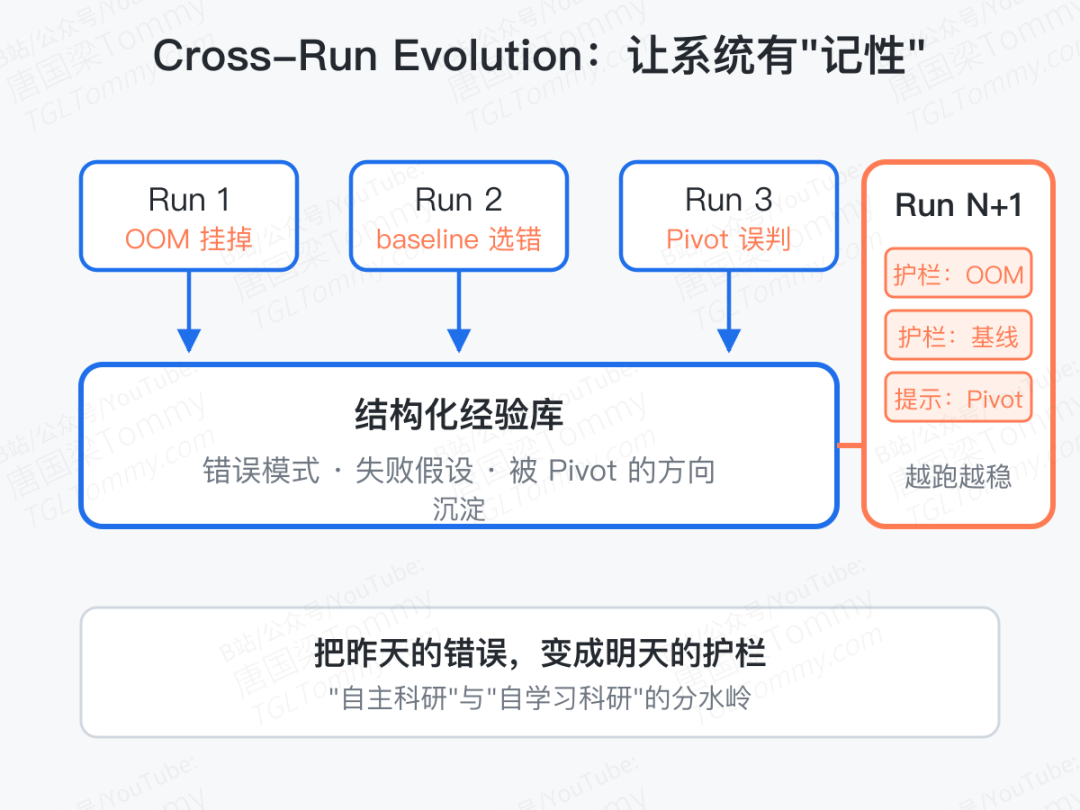
这一步让系统第一次有了"记性"。它不再每次都是零经验的新手,而是会被自己的过去约束的、越跑越稳的研究者。这是把"自主科研"和"自学习科研"分开的分水岭。
数字之外的真正启示
ARC-Bench 25 个实验阶段任务、相比 AI Scientist v2 的 54.7% 胜率提升——这个数字是漂亮的,但不是最值得记住的事。
更值得记住的是这套系统传达的研究观:自主科研的瓶颈不在 LLM 本身有多聪明,而在于我们用什么架构去组织它、什么时候让它停下、什么时候让人接手、怎么让它带着过去的教训进入下一轮。

这套架构当然还远没"解决"自主科研。Pivot 的判断仍可能误判方向、可验证报告这一层在面对开放性人文社科问题时未必有效、7 种 intervention 模式的最优选择仍需要 human 凭经验做先验判断。但它给出了一个比"再大的模型 + 再贵的 API"更值得跟进的方向:与其追求 AI 自己跑通整条科研流水线,不如把它造成一个能与人长期共生的研究循环。
如果"AI 自动写论文"是过去两年的科研叙事,AutoResearchClaw 给出的下一句可能是——让 AI 学会失败、辩论、记住、并且知道什么时候喊人来。这才是把 AI 从"论文生成器"升级成"研究伙伴"应该走的路。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号