AI 不需要记住一切,它需要的是学会学习,这项记忆革命让Deep Research Agent学会思考

AI 不需要记住一切,它需要的是学会学习,这项记忆革命让Deep Research Agent学会思考

唐国梁Tommy
发布于 2026-06-25 21:39:07
发布于 2026-06-25 21:39:07
爱因斯坦有句广为人知的忠告:"永远不要记那些你能查到的知识。"
这句话放到今天的AI世界里,显得无比刺眼。

过去两年,Deep Research Agent(深度研究型智能体)成了科技圈最热门的赛道。从OpenAI的Deep Research到Anthropic的Claude with Extended Thinking,AI正在从"聊天机器人"进化为能独立完成数小时调研任务的"研究助理"。
但支撑这些能力的"记忆系统",却走了一条让人越走越窄的路——疯狂存储过去的搜索记录。就像一个人为了变得更聪明,把一辈子读过的每一本书都塞进客厅,结果每次找资料都得在书堆里翻半小时。
这不是爱因斯坦想要的那种聪明。
记忆系统的三个"沉默杀手"
让我们直白一点:现在大多数Deep Research Agent的记忆系统,本质上是个文件柜。
你让AI查资料、调用工具、写报告,它把每一次操作都存成一条"轨迹"。下次遇到相似问题,就从柜子里翻几份"最相关"的轨迹塞进提示词里当参考。
听起来合理?实际上有三个致命问题:
第一,成本是头吞金兽。 随着使用次数增加,存储的记忆呈指数级膨胀。检索速度变慢,维护成本飙升。这不是存储问题,是可扩展性危机。
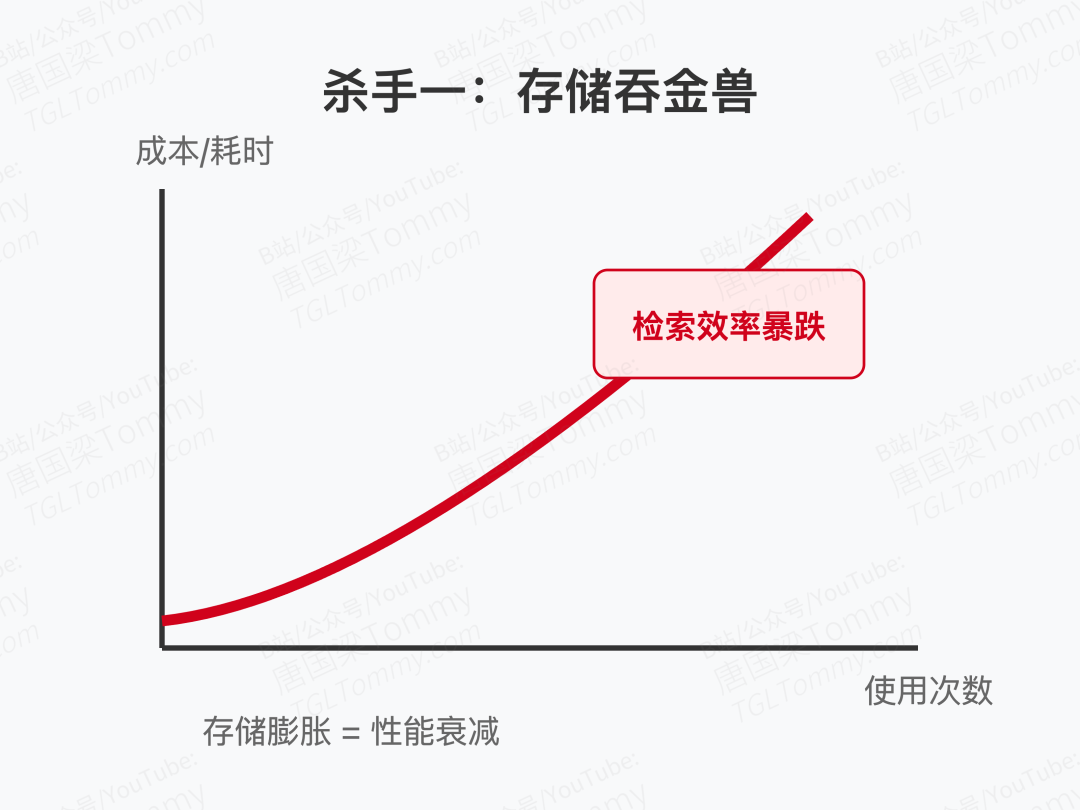
第二,AI并不会真"内化"经验。 记忆存了一大堆,但模型参数一点没变。今天犯的错误,明天换个问法照样犯。这就像学生把错题本抄了十遍,却从不真正理解错在哪。

第三,离不开人工监督。 要让系统知道"这条路径好、那条路径差",必须有人写正确答案。在真实的开放世界里,哪有那么多现成的标准答案?
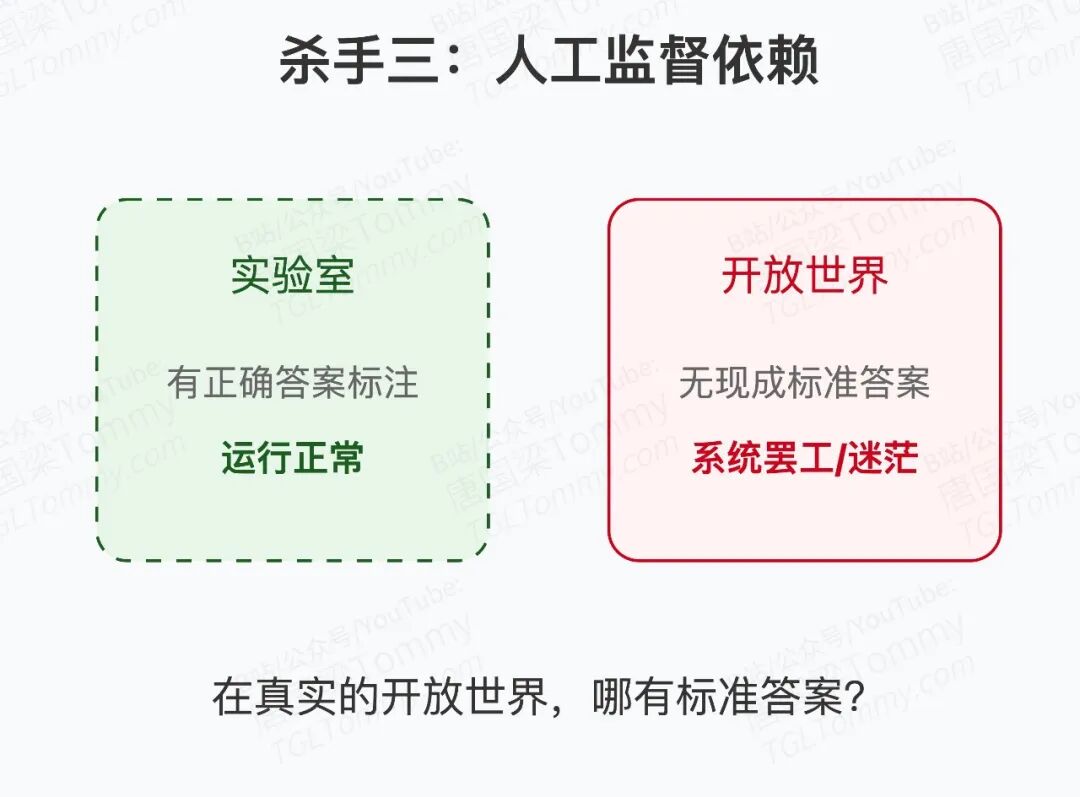
这三个问题叠加在一起,导致一个尴尬的局面:记忆系统越复杂,往往表现越差。因为那堆"历史记录"对AI来说,可能只是噪音。
一个"三元脑"架构
华东师范大学的团队给这种困境开了个新方:把记忆系统拆成三个角色,让它们各自干擅长的事。
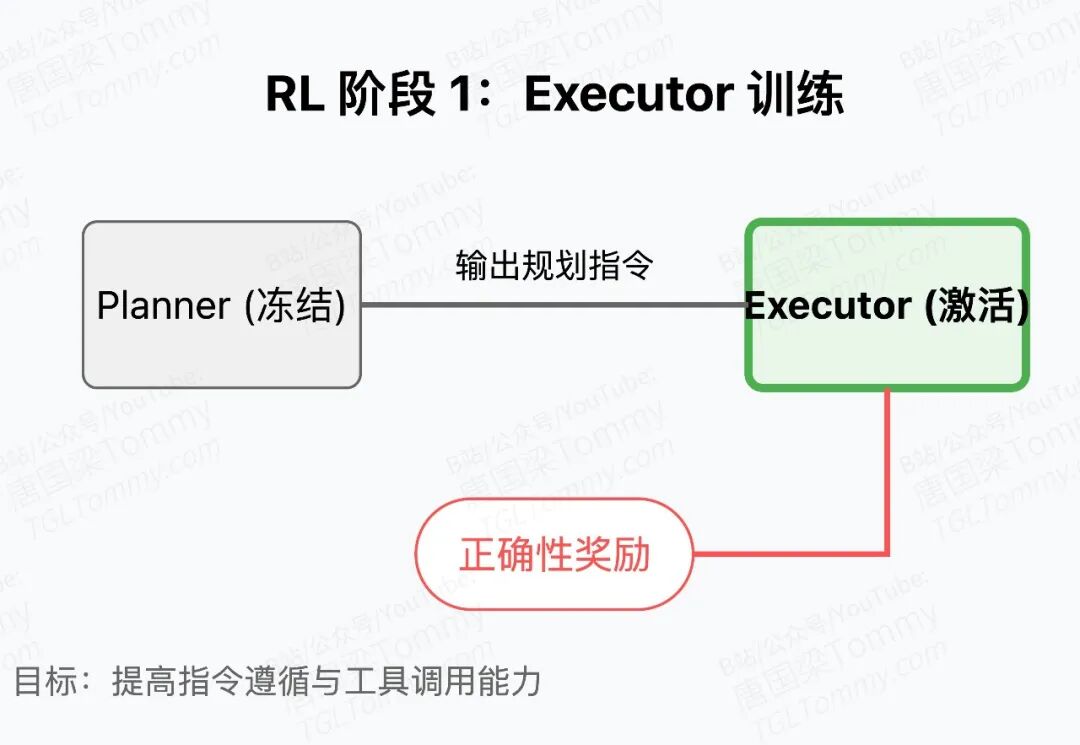
这个叫 MIA(Memory Intelligence Agent) 的框架,抛弃了传统的"单一记忆库"设计,改为 Manager-Planner-Executor 三元架构。
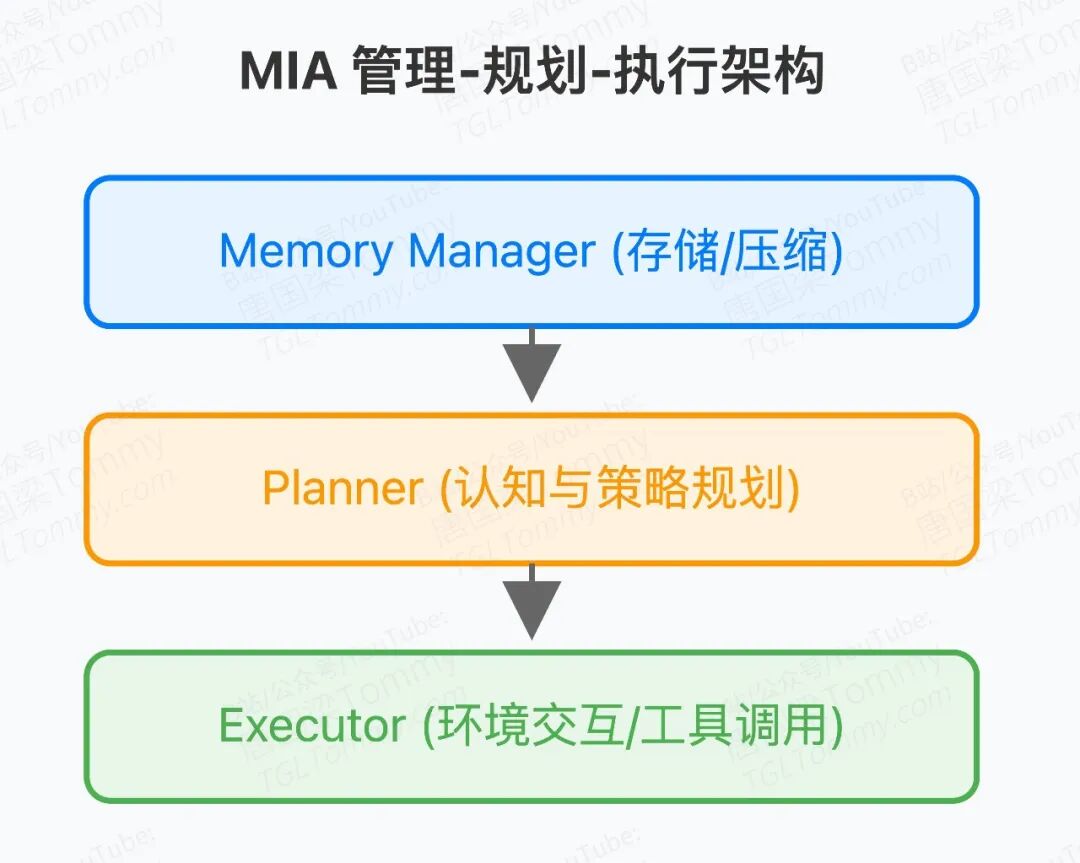
Manager(记忆管理员):不存原始记录,只存"压缩后的工作流范式"。好比老师写教案,不抄整本教材,只保留最核心的教学框架。
Planner(规划师):它是一个参数化模型,专职"思考"你该怎么做。它不是搜索助理,而是把历史经验内化为策略能力的决策中枢。
Executor(执行者):听从计划,老实干活,负责与外部工具交互。
这里没有"Search Agent"常见的拉拉扯扯。Manager提供经验参考,Planner决策怎么做,Executor负责执行。分工明确,相互解耦。
但真正的突破在一个循环:
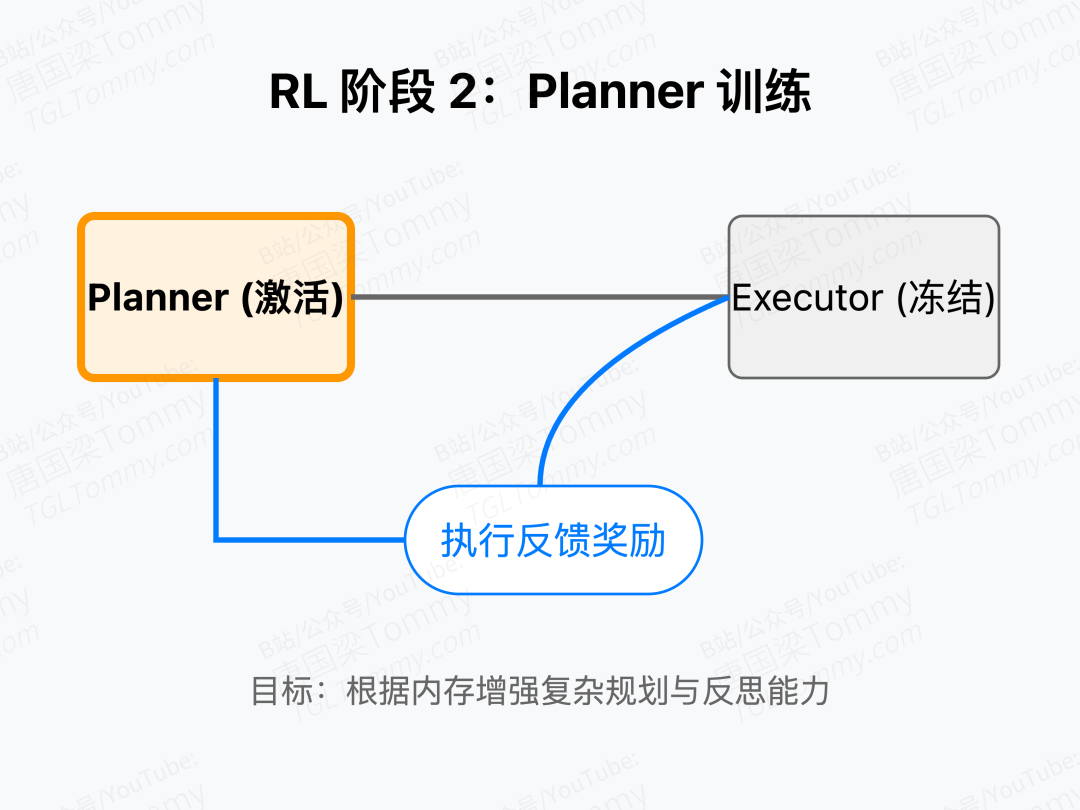
非参数记忆(Manager)和参数记忆(Planner)之间可以进行双向转 换。
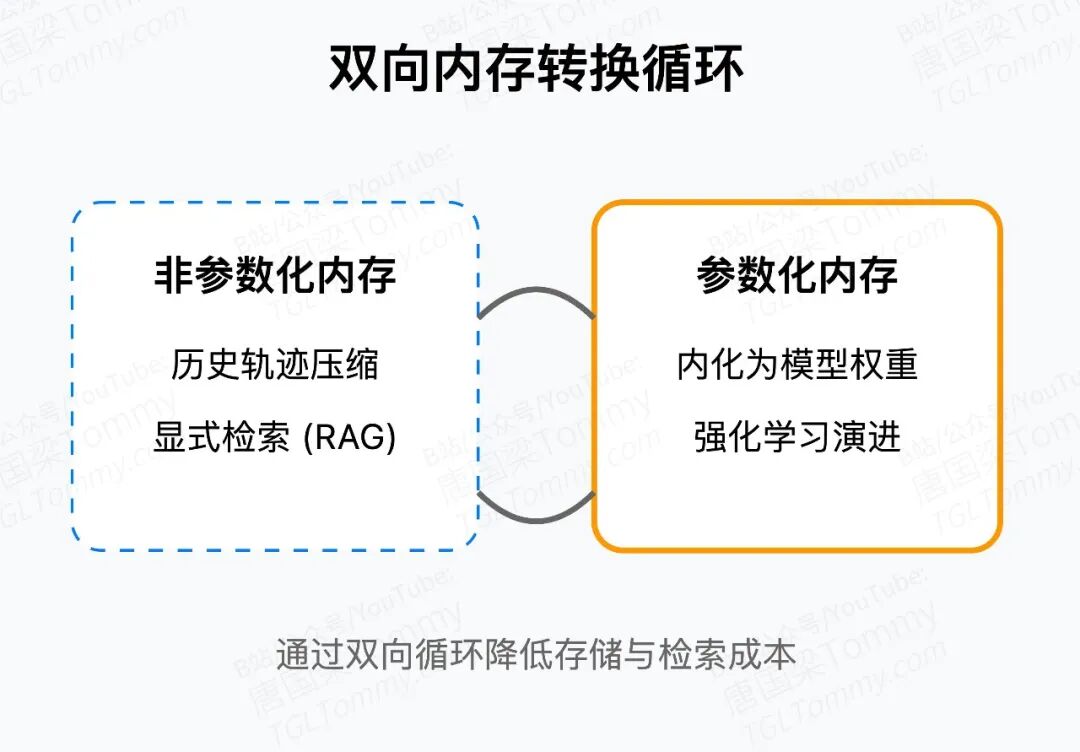
当Planner搞定了新任务,成功经验会被压缩成工作流存回Manager;Manager里的有效范式又能通过强化学习训练Planner的参数。这不是简单的存储搬运,而是认知的不断内化与重构。
就像一位研究员:Manager是他的文献管理器,Planner是他的大脑,Executor是他的实验室助手。三者配合,科研能力才能随着项目不断增长。
在推理的间隙,模型突然"顿悟"了
但这还不是MIA最反直觉的部分。
传统AI是这样的:训练一堆数据 → 模型定型 → 部署推理。一旦上线,参数就锁死了,遇到新问题爱莫能助。
MIA干了件"极不规矩" 的事:它在推理过程中更新自己的参数。
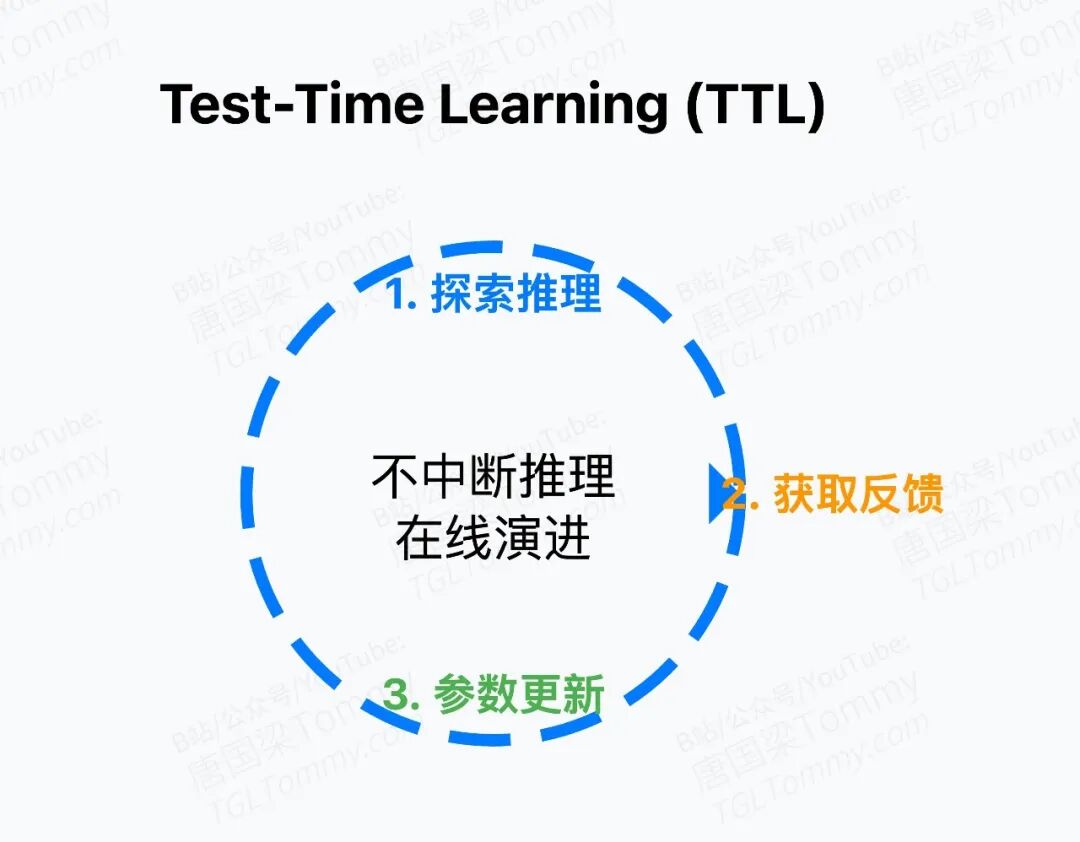
他们给这个机制起了个名字,叫 Test-Time Learning(测试时学习),缩写TTL。
具体怎么操作?当模型面对一个新问题时:
- 同时生成多个不同的解决方案(Plan1、Plan2、Plan3...)
- 每个都跑一遍看看结果如何
- 哪个方案好就奖励自己,哪个差就惩罚自己
- 更新Planner的参数,然后继续做这道题
整个过程就在解决当下这个问题的流程中完成,不需要额外的离线训练周期,不需要中断服务。
换句话讲,MIA的Planner在回答你的问题时,正边答边学。答得越多,它越聪明。
这解决了Deep Research Agent最真实的痛点:部署后继续进化。不再是"上线即巅峰,随后抗遗忘曲线下降"。
无监督也能自我进化?他们模拟了"学术评审"
但更棘手的问题在于:在开放世界里,谁来评判这些方案的好坏?
如果每次都需要人工标注正确答案,那这套系统依然无法大规模应用。
MIA团队用了一个看似曲折,实则巧妙的设计:模拟学术会议的"同行评审"机制。
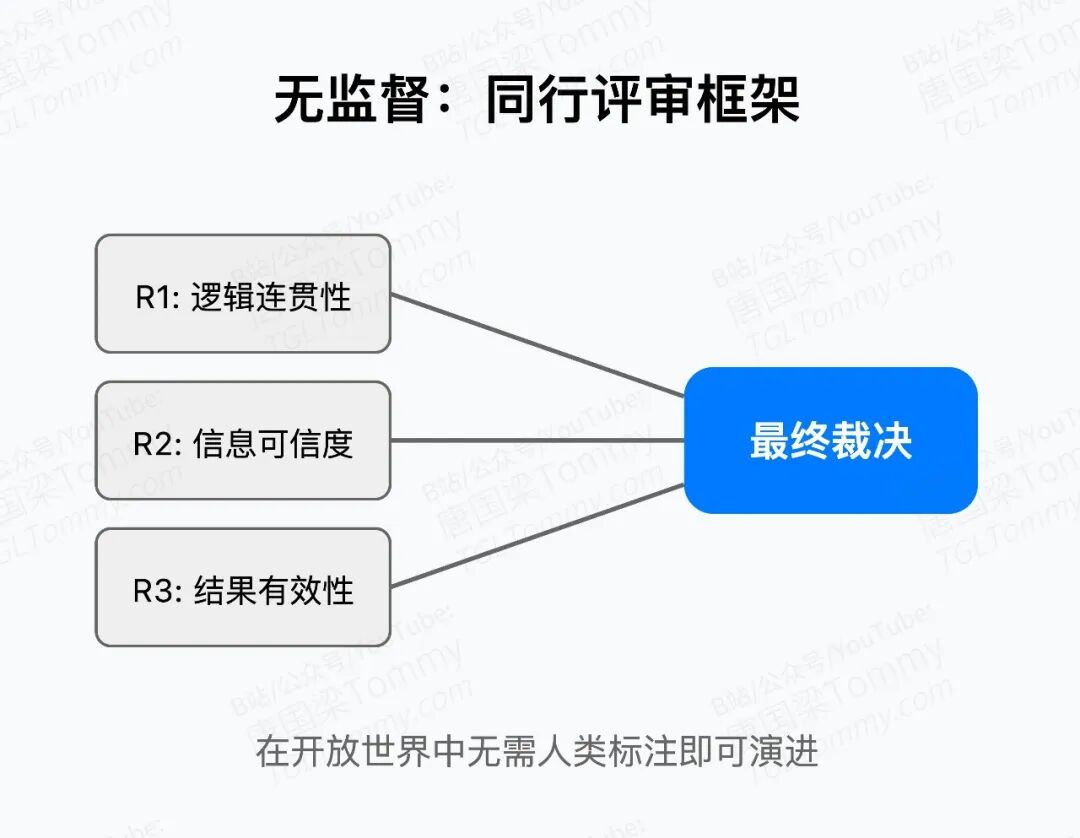
他们安排三个"AI评审员"分别检查不同维度:逻辑链是否通顺、信息源是否可靠、任务是否真正完成。然后一个"领域主席"综合三方的意见,给出最终A/B判决。
这套体系最有趣的地方在于:它不需要知道标准答案是什么。 只要过程具备"严格逻辑+可信来源+最少幻觉",就算好的学习信号。
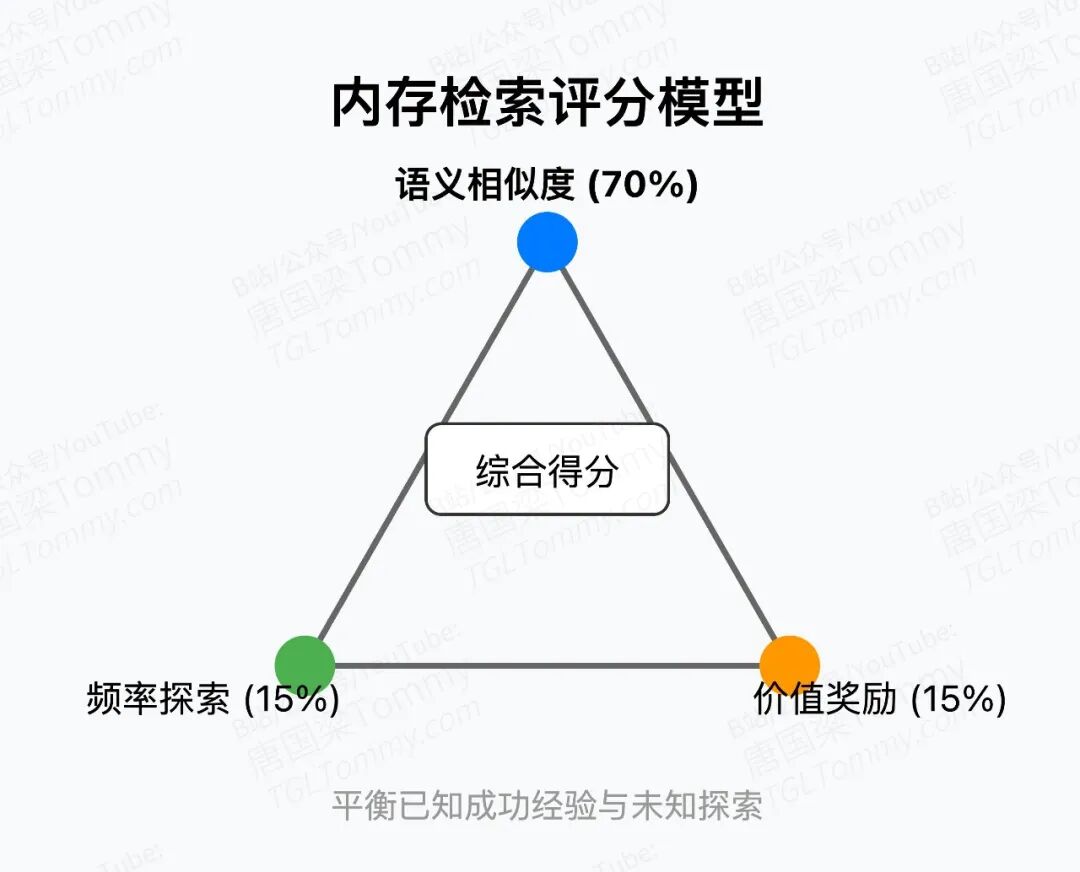
这到底是监督还是无监督?纽约大学统计学家哈德可能也答不上来。但可以确定的是,它让MIA在没有任何人工标注的情况下完成了自我训练,并且性能稳步提升:从第一轮到第三轮,多项指标持续爬坡。
7B参数击败32B:这个数字意味着什么
讲完概念,来看硬数字。
MIA在11个基准测试上全面进化。最吸引眼球的是这个结果:
用Qwen2.5-VL-7B作为执行器,在7个数据集上平均提升31%,击败了参数大近5倍的Qwen2.5-VL-32B,差距高达18%。
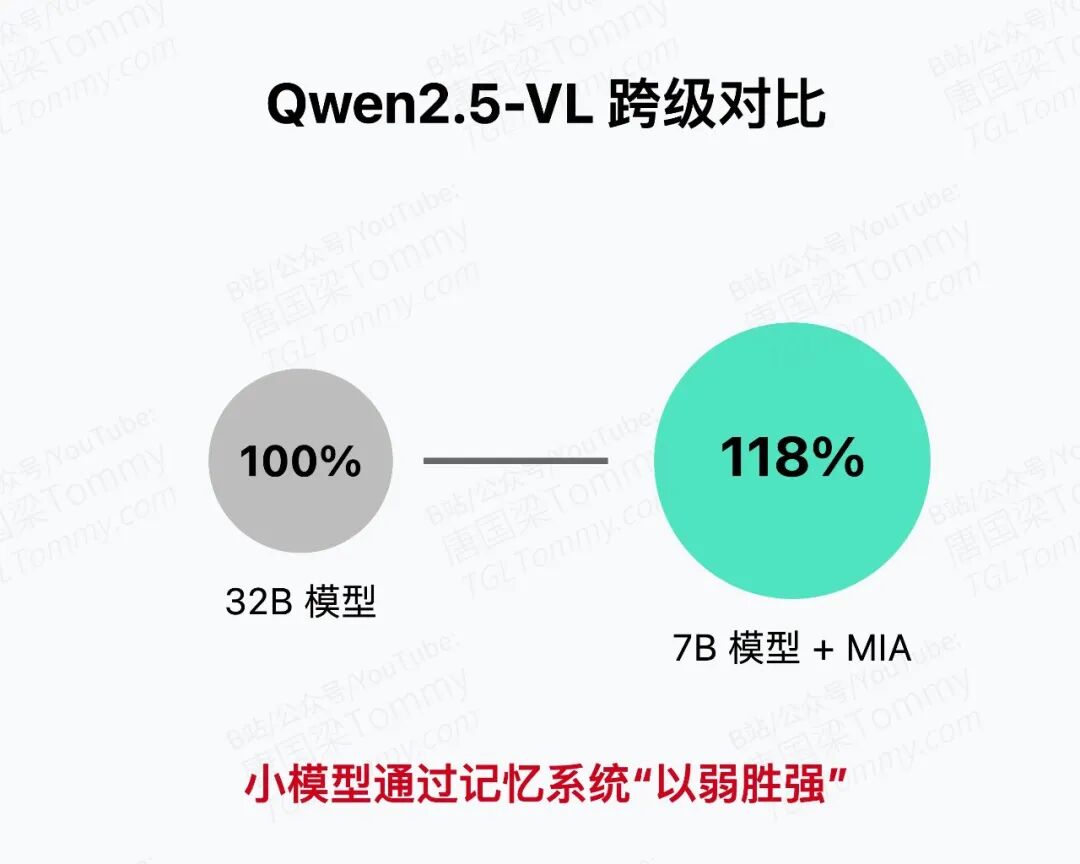
为什么小模型能击败大模型?
因为记忆架构的智能,正在超越单纯的参数规模优势。 MIA让7B的"身体"拥有了原来70B才可能具备的"经验学习能力"。
另一个值得注意的数字:相比GPT-5.4,MIA在LiveVQA任务上提升了101%(从21.5到43.1)。LiveVQA是面向实时信息的问答基准,极为考验系统的动态知识获取能力。这表明MIA的协作架构在"动手查资料"这件事上,超过了纯粹靠预训练知识的大模型。
而传统的"长上下文记忆"方法(如RAG、Mem0)反而表现比"无记忆"基线更差。这不是技术没作对,而是思路错了——记住更多≠变得更聪明。
AI记忆的本质是什么?
在论文的最后一页,作者们引用了爱因斯坦的那句话,作为整个项目的注脚。
这绝非巧合。MIA的核心洞见正是:让AI记住"如何学习"的路径,而非"每次搜索的文字内容"。
传统方法堆砌记忆,就像学生猛抄笔记。MIA的方法则是建立"元认知"——学会学习的能力。
但这套架构并非没有代价。Test-Time Learning需要同时生成多个计划并运行验证,推理成本至少是常规方法的3-4倍。Manager需要常驻显存,32B的"大脑"意味着不小的硬件开销。
所以MIA不适用于那种"秒回消息"的实时场景。 它更适合需要深度调研、可接受分钟级等待的任务:写一份财报分析、完成一次竞品研究、诊断复杂的系统故障。
在这些场景里,推理的"成本"换"质量"的权衡是值的。
写在最后
Deep Research Agent正处在从"能用"走向"好用"的关键阶段。
管道式的Memory RAG正在触及天花板,而具备自我进化能力的智能体正在打开新的天花板。
MIA的意义不在于又刷了多少分,而是它提供了一个新范式:不记所有东西,而是学会如何处理信息;不依赖人工监督,而是学会自我评判;不只在训练时学习,而是在推理时也能进化。
或许这才是爱因斯坦真正想告诉我们的:真正的智慧,不在于你脑子里的存量,而在于你获取、处理、内化新知的增量能力。
到这个程度,AI或许才真正开始拥有类似人类的"智慧"。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号