多模态视频流式推理提效56%:揭秘TWW的分段级动态记忆机制

多模态视频流式推理提效56%:揭秘TWW的分段级动态记忆机制

唐国梁Tommy
发布于 2026-06-25 21:33:22
发布于 2026-06-25 21:33:22
论文链接:https://arxiv.org/abs/2603.11896
项目链接:https://github.com/wl666hhh/Think_While_Watching.git直击痛点:流式视频推理的"感知-生成"互斥锁
尽管多模态大语言模型(MLLMs)在离线视频理解基准测试中屡创佳绩,但在诸如直播分析、具身智能机器人、实时安防等连续视频流场景中,它们的表现往往令人大跌眼镜。当前的流式大模型普遍采用"交错式感知-生成"(Interleaved Perception-Generation)范式:模型看一段视频,停下来生成文本,然后再看下一段。
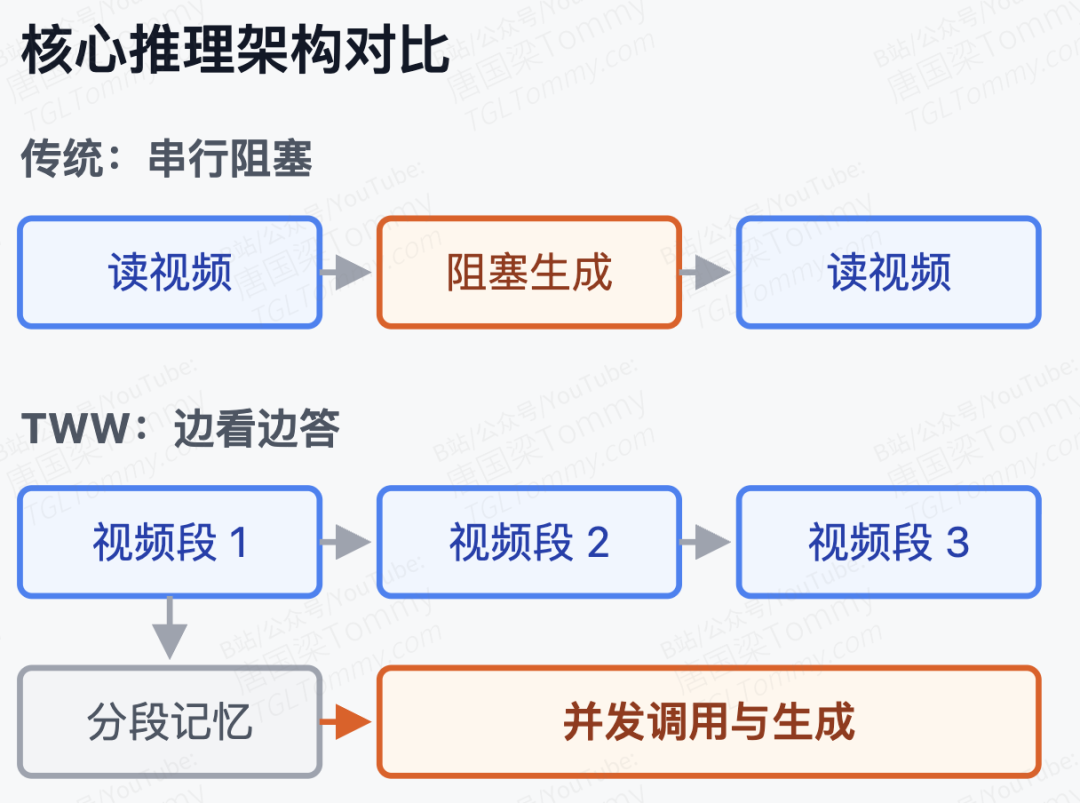
我认为,这种将感知与生成强行串行化的设计存在两个致命缺陷。首先是记忆侵蚀(Memory Erosion)。在多轮问答中,后续问题往往高度依赖早期的视觉线索,但交错式的文本解码会阻断长程时序特征的连续建模,导致模型"看后面忘前面"。其次是严重的延迟积压。论文作者在附录中用排队论给出了精妙的理论解释:假设视频以速率 到达,模型处理速率为 (负载率 )。在非抢占式的解码耗时 期间,系统停止接收视频,导致积压 。更可怕的是,系统为了追平这部分积压,需要耗费的追赶时间为:
这意味着,随着负载率接近满载,哪怕仅仅几秒钟的生成停顿,也会引发系统级联式的延迟崩溃。这种"感知-生成"的互斥锁,是阻碍多模态大模型走向真实在线场景的最大绊脚石。
TWW的核心解法:维护连续的分段级记忆流
为了打破上述困境,这篇论文提出了 Think While Watching (TWW) 框架。TWW 的核心洞察在于:流式多模态推理不应该是一次性的"阅后即焚",而应该建立一个基于时间锚点的分段级记忆(Segment-Level Memory)机制。
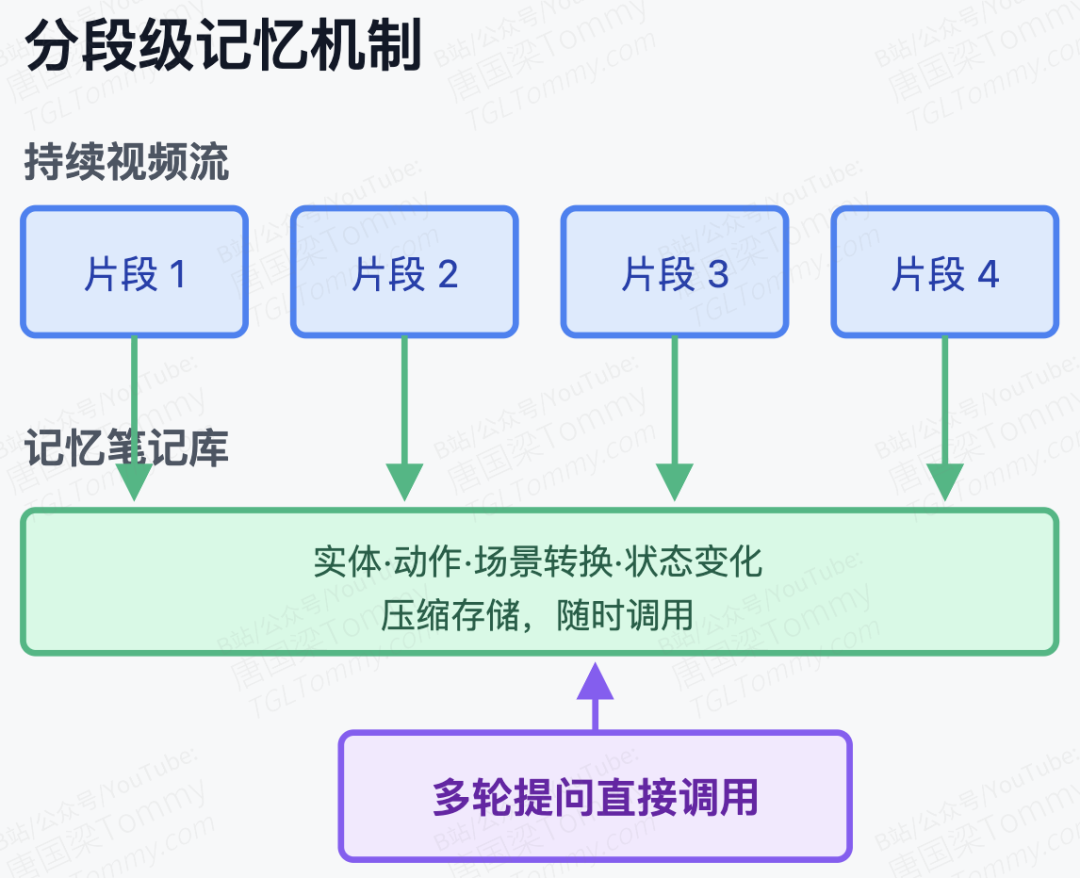
具体而言,TWW 放弃了传统模型将整个视频历史视作无差别上下文的粗暴做法。在视频流持续输入的过程中,TWW 会在后台静默运行,为每个到来的视频片段主动生成"记忆笔记"(Memory Notes)。这些笔记提取并压缩了当前片段中的关键实体、动作状态和场景转换。当用户在任意时刻突然插入多轮连问时,模型不需要重新回溯庞大的原始视频 Token,而是直接调用这些已经结构化的分段记忆进行链式思考(Chain-of-Thought, CoT)。这套机制就像人类看长篇纪录片时在脑海中不断做知识快照,既保证了长程依赖的连贯性,又大幅降低了多轮对话中的认知负担。
弥补数据断层:三阶段合成流式CoT指令集
有了架构构想,随之而来的挑战是:开源界几乎不存在带有"流式记忆注释"的高质量多轮对话数据集。为弥合这一训练数据缺口,作者调用 GPT-5.2 精心合成了一个包含三个阶段的流式 CoT 数据集,并设计了阶段匹配的渐进式训练策略。
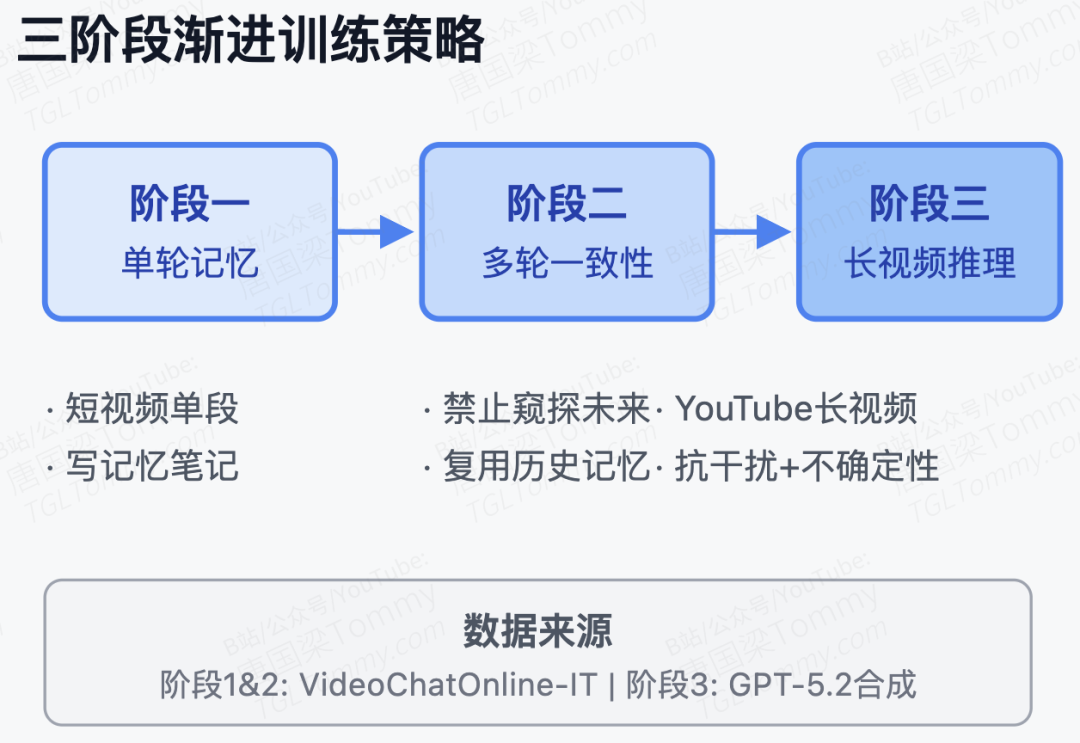
- 第一阶段(短视频单轮):训练模型针对单一视频片段提取状态并撰写记忆笔记的能力。
- 第二阶段(短视频多轮):培养多轮对话间的一致性,强制要求模型在回答后续问题时复用之前的记忆笔记,且绝对禁止窥探未来尚未发生的视频片段。
- 第三阶段(长视频复杂推理):引入 YouTube 长视频(如动辄数十分钟的教程或讲座),训练模型在海量干扰信息下长程召回线索、处理不确定性的能力。
值得注意的是,在数据合成和模型训练期间,TWW 实施了极其严格的因果性约束。对于包含 个视频片段和 个问题的输入流,模型必须精准生成 个推理块。为了在底层机制上杜绝"偷看未来",TWW 引入了流式因果掩码(Streaming Causal Mask)和流式旋转位置编码(Streaming RoPE),确保每个问题查询只对截至当前时间戳的视觉内容可见。
推理工程优化:双KV Cache与自适应注意力
在工程落地层面,如何在有限算力下做到真正的"边看边想"?TWW 在推理管道设计上给出了非常漂亮且实用的工程解法:读写分离的自适应流水线。
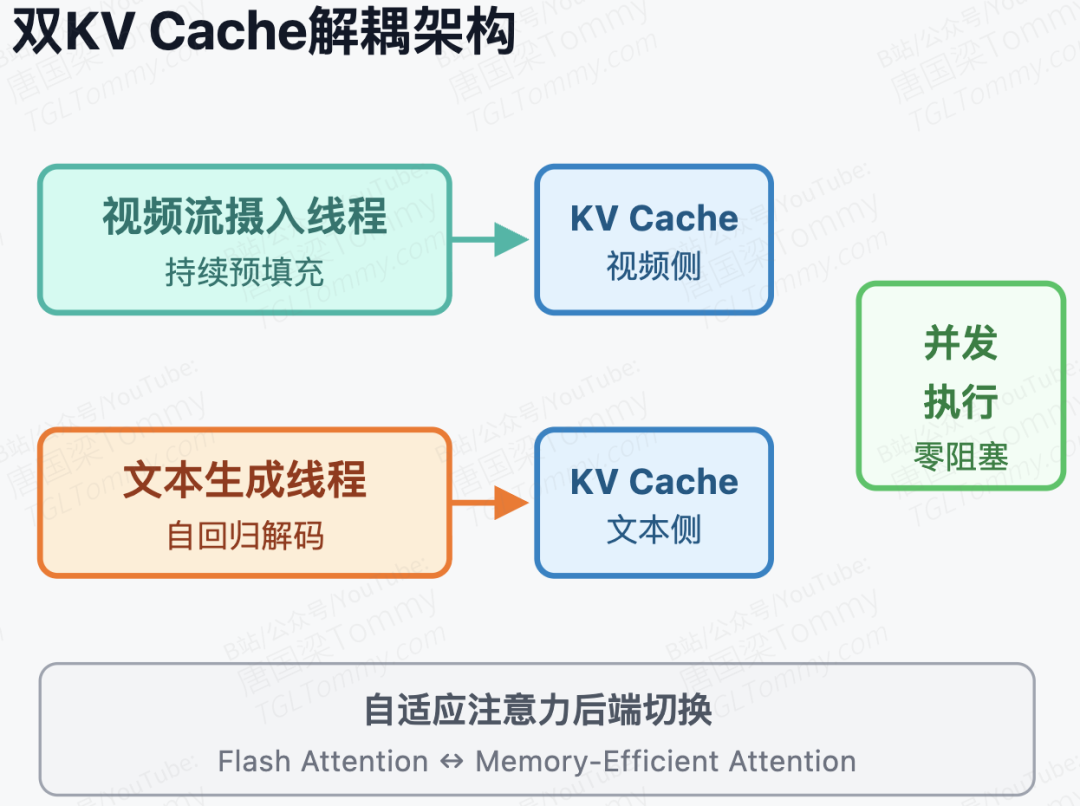
系统通过双 KV Cache(Dual KV Cache)机制,将视频流的持续摄入与文本的自回归解码完全解耦。视频处理线程和文本生成线程可以并发执行,从根本上消除了前文提到的 延迟积压效应。
更有趣的是作者针对不同生成阶段设计的自适应注意力后端(Adaptive Attention Backend)。在流式掩码规则下,注意力机制的查询长度()与键长度()经常发生变化。TWW 会进行动态路由:当进行源视频特征的预填充()或标准的单步自回归解码()时,系统调用极致优化的 Flash Attention 以追求最大吞吐;而在遇到 的特殊流式问答阶段时,由于需要施加不规则的定制因果掩码,系统会无缝切回到 Memory-Efficient Attention。这种因地制宜的底层调度,保证了流式推理既满足严格的时序因果逻辑,又不失极致的推理速度。
惊艳的数据表现:减半Token消耗并反哺离线
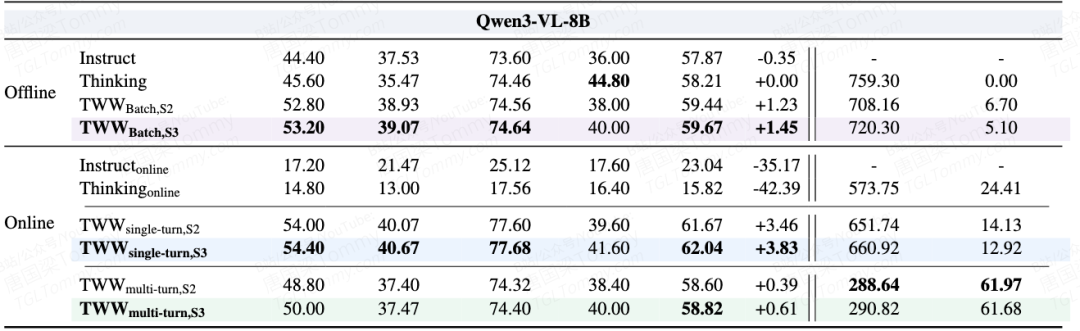
实验结果充分证明了 TWW 架构的有效性。在基于 Qwen3-VL(4B)的测试中,单轮流式设定下,TWW 在 StreamingBench 上将准确率从 58.52% 提升至 60.04%,在注重真实世界视频理解的 OVO-Bench 上则从 50.70% 跃升至 55.02%。
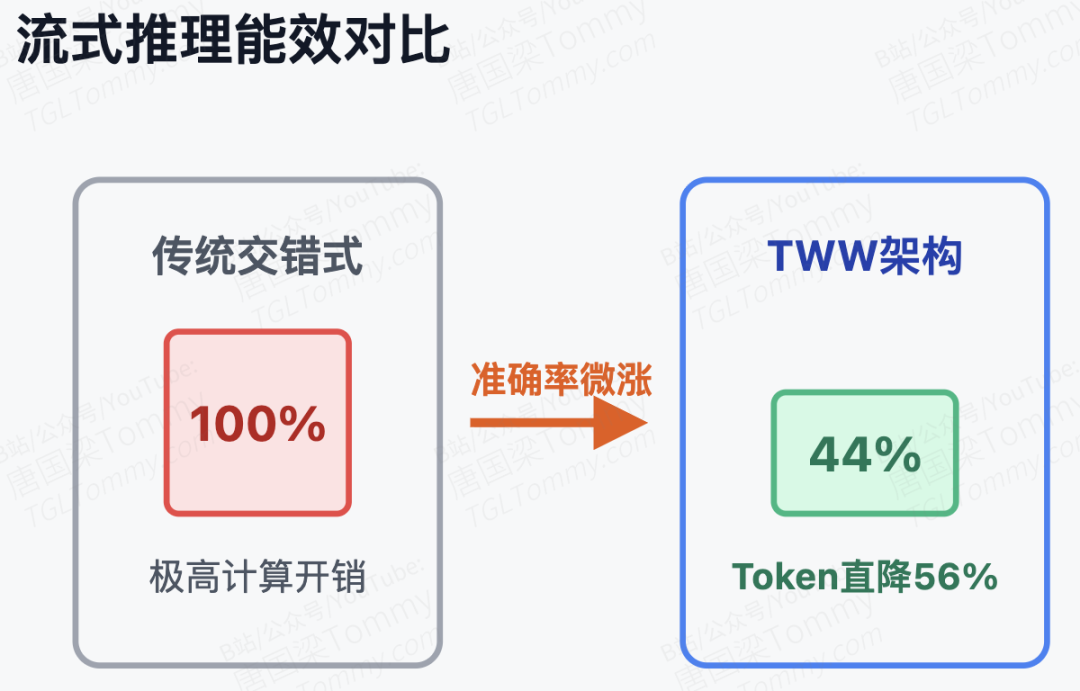
但我认为最振奋人心的数据出现在多轮对话协议下。在保持甚至微涨准确率的前提下,TWW 凭借其强大的分段记忆复用能力,将生成的平均 Token 数量暴降了 56%(在 OVO-Bench 上也下降了 45.8%)。在对时延和算力成本极度敏感的在线业务中,计算开销减半而能力不降,这是一个具有极高商业化价值的改进。此外,虽然这套范式专为流式场景设计,但它在离线的长视频基准测试(如 Video-MME 和 LV-Bench)中依然展现了强大的 Zero-Shot 泛化能力,证明"边看边想"的机制天然提升了模型处理极长上下文的内功。
技术启发与局限:流式智能的真正难点在"时机"
尽管 TWW 向我们展示了流式多模态推理的巨大潜力,但它目前的局限性也恰恰为未来的研究指明了方向。论文在附录中坦诚地展示了几个典型的失败案例,比如超长跨度下的细粒度实体身份遗忘,以及在存在频繁画面跳转干扰时的记忆污染。
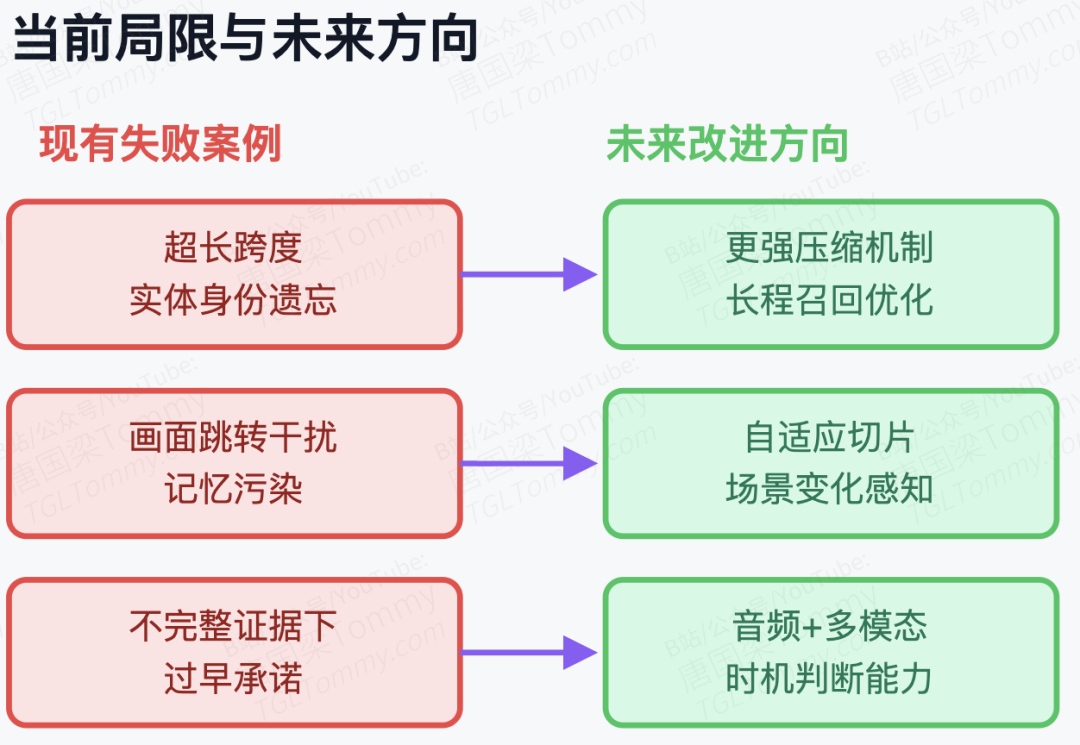
更深层的挑战在于"在不完整证据下的过早承诺(Premature Commitment)"。在实际测试中,当一个动作(如"球员正在开角球")刚刚发生到一半时被提问,模型往往无法做出"让子弹飞一会儿"的判断,而是基于不充分的半截画面过早给出确定性结论。这提醒我们,真正的在线智能不仅需要理解"发生了什么",还需要学会判断"现在是不是回答的最佳时机"。未来的工作如果能引入音频线索,或实现基于画面变化剧烈程度的自适应切片分割,这项技术将在具身智能和实时辅助驾驶领域爆发出更强大的威力。
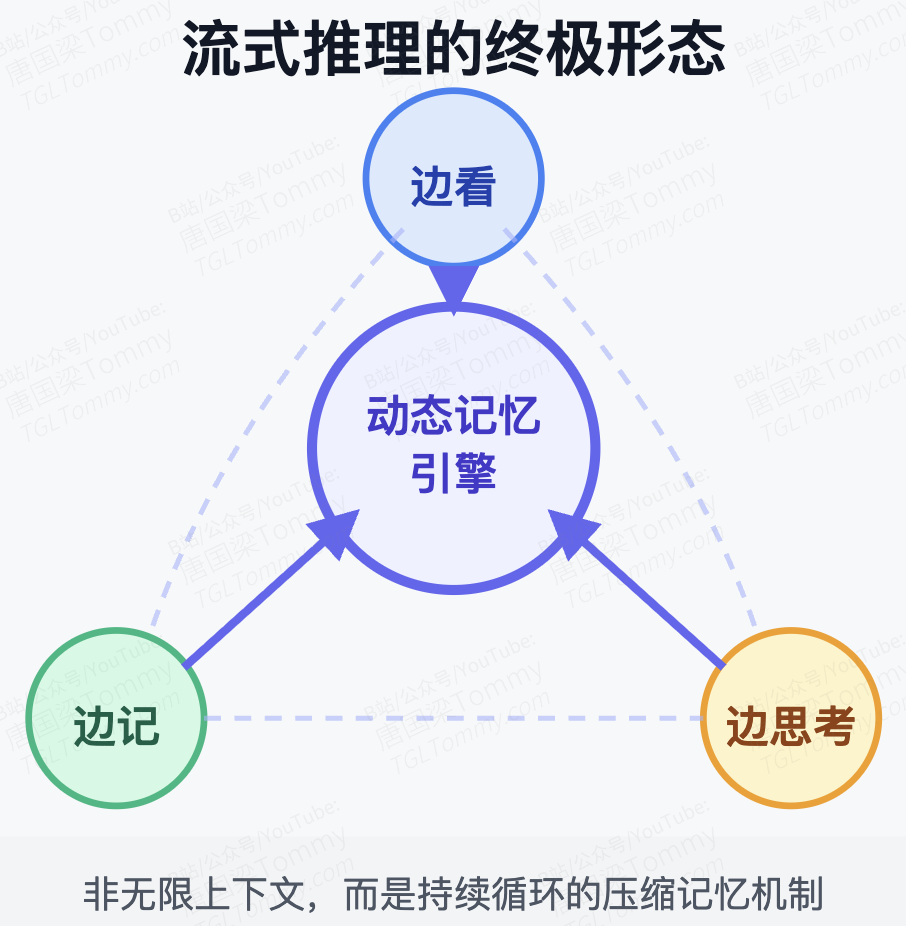
总结成一句话:流式推理的终局并非无限扩大上下文窗口,而是掌握一套边看、边记、边思考的动态记忆引擎。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号