RL驱动的研究自动化:10篇综述解构Deep Research的技术内核与当前边界

RL驱动的研究自动化:10篇综述解构Deep Research的技术内核与当前边界

唐国梁Tommy
发布于 2026-06-25 21:33:14
发布于 2026-06-25 21:33:14
Deep Research(DR)不是RAG的升级版,它是一种范式转变——LLM从被动的信息消费者变成了主动的研究Agent。 这是我在通读这份综合了10篇核心综述的技术报告后最核心的判断。这10篇综述来自浙江大学、宾夕法尼亚州立大学、上海交通大学、哈尔滨工业大学、华为、多伦多大学等机构,覆盖了系统分类、RL优化、AI for Science等不同视角,发表时间横跨2025年3月到11月。如果你在构建基于检索的AI系统,或者跟踪研究型Agent的技术路径,这份跨文档综合分析有相当高的参考价值。

一、DR vs RAG:本质区别不在检索,在控制闭环
很多工程师看到"检索+生成"就觉得和RAG没有本质区别,但这个直觉是错的。山东大学综述给出了清晰的三维对比:
传统RAG是在预索引语料上做单次检索,工作流是固定管线,输出没有验证机制。Deep Research则完全不同:它通过搜索引擎、Web API、代码执行器等多工具进行动态交互;工作流是闭环控制,支持多轮推理和自主规划修正;输出有可验证机制,需要与有据可查的证据对齐。
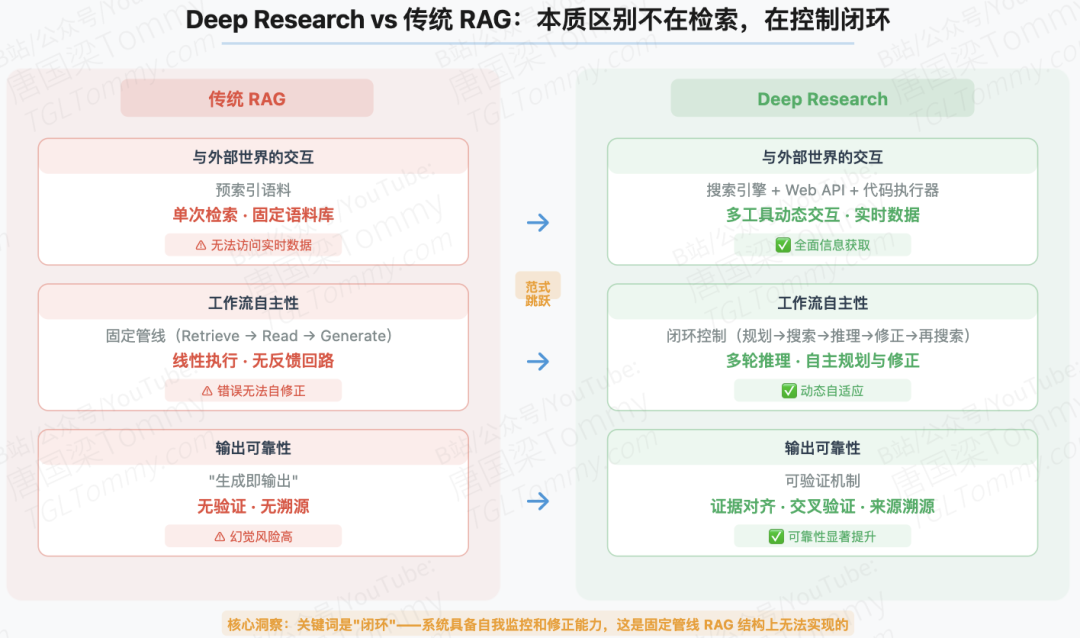
关键词是"闭环"。这不是术语堆砌,而是说系统具备了自我监控和修正能力。当一次检索结果不满足需求时,DR系统会重新规划查询策略;当发现信息冲突时,它会尝试交叉验证,而不是直接综合。这种动态自适应能力是固定管线的RAG结构上无法实现的。
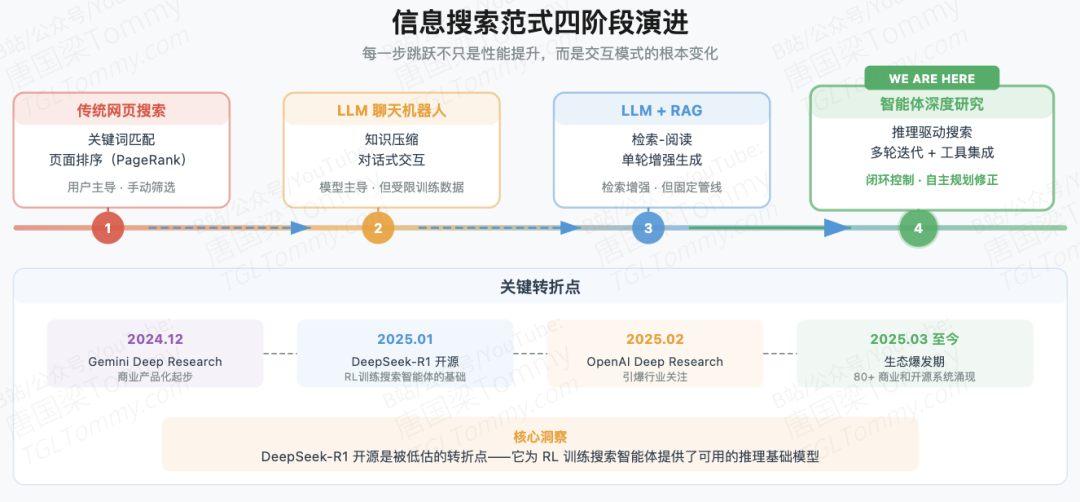
范式演进路径在多篇综述中高度一致:
关键词搜索聊天深度研
每一步跳跃都不只是性能提升,而是交互模式的根本变化。值得注意的是,2025年1月DeepSeek-R1的开源是一个被多篇综述认为的重要转折点——它为用RL训练搜索Agent提供了可用的推理基础模型,直接推动了Search-R1等工作的出现。
二、技术架构:四大组件的成熟度分布不均
综合所有综述,DR系统的技术架构可以归纳为四个核心组件:查询规划、信息获取、记忆管理、报告生成。这四个组件的成熟度差异相当大,值得分别评估。
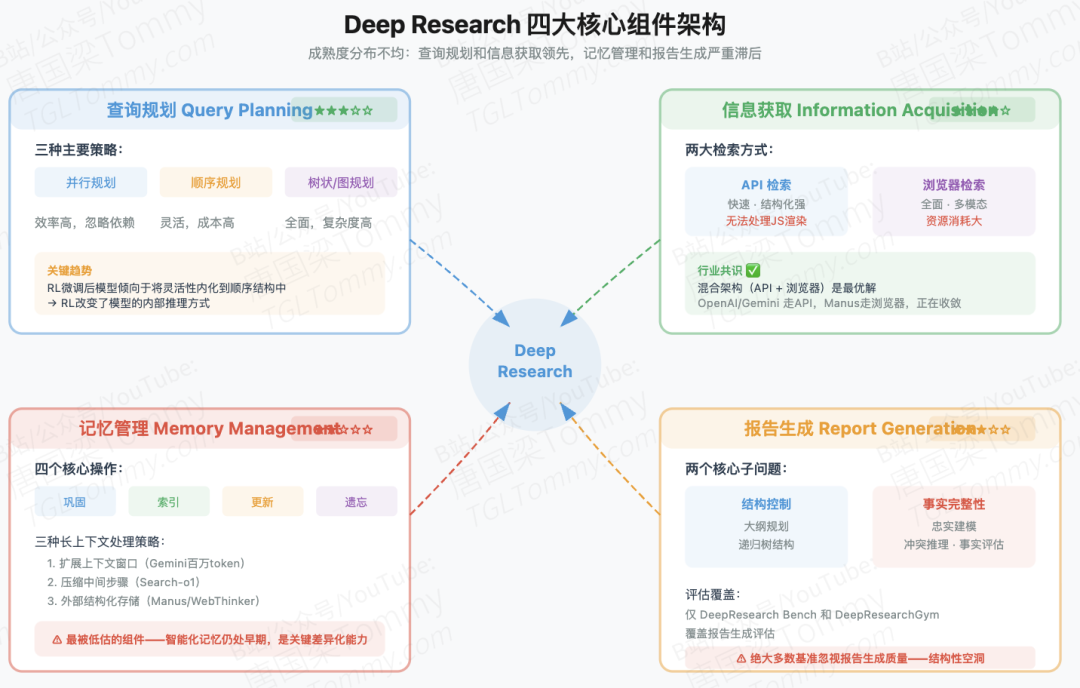
查询规划方面,三种策略各有适用场景:并行规划效率高但忽略依赖关系;顺序规划处理逻辑依赖但计算成本高;树状/图规划(MCTS、DAG递归建模)兼顾效率与深度但复杂度最高。一个值得关注的趋势是:经过RL微调的模型倾向于将规划灵活性内化到顺序结构中,不再需要显式的外部规划模块——这说明RL训练确实在改变模型的内部推理方式,而不只是在表面行为层面做调整。
信息获取方面,行业已形成共识:混合架构(API+浏览器)是最优解。API检索快速高效但无法处理JS渲染的动态内容;浏览器检索全面但资源消耗大。OpenAI DR和Gemini DR选择了API路线,Manus和AutoGLM选择了浏览器路线,但几乎所有高性能系统都在向混合方向收敛。
记忆管理是目前最被低估、最需要工程投入的组件。山东大学综述提出了记忆的四个操作——巩固、索引、更新、遗忘,这个框架颇具启发性。当前主流解决方案是扩展上下文窗口(Gemini支持百万token窗口)或压缩中间步骤(Search-o1的"Reason-in-Documents"方案),但这些都是被动策略。真正的智能化记忆——根据任务预测需要保留什么、丢弃什么——还处于早期研究阶段,成熟度只有★★☆☆☆。
报告生成是另一个被大量忽视的组件。香港城市大学综述区分了两个子问题:结构控制(长文本的连贯性)和事实完整性(与证据的对齐)。问题在于,现有大多数评估基准根本不评估报告生成质量,导致这个组件的研究进展相对滞后,形成了技术发展的结构性空洞。
三、RL是核心优化引擎:为什么SFT和DPO不够
这是技术报告中最值得深挖的部分。三篇综述(宾夕法尼亚大学、华为、上海交通大学)对此进行了深入分析,华为综述的论证最为清晰。

SFT的根本问题是"暴露偏差"——训练时看到的是正确轨迹,推理时遇到工具失败或意外检索结果就无法恢复。DPO的问题是优化目标错位:它优化的是文本替代而非状态-动作回报,主要依赖离线数据,难以学习从错误中恢复的策略。RL的优势恰好对症:端到端的多步信用分配。当一个DR任务需要经过十几轮检索-推理-修正,最终答案的对错需要回溯归因到每一个中间决策,只有RL能做到这个级别的信号传播。
GRPO(Group Relative Policy Optimization)已成为DR领域主流算法,约占相关工作60%以上。核心优势是消除了独立价值网络,通过组内奖励归一化估计优势函数:
这个设计在实践中被证明是正确的——工程团队采用GRPO的理由不只是性能,更是内存开销显著低于PPO,在资源有限的训练环境下直接决定了可行性。PPO因其在长horizon任务下的稳健性仍被Search-R1等工作采用,DAPO则专为长链推理场景做了四项改进,在移动端等资源受限场景展现优势。

奖励设计的演进同样值得关注。第一代是简单的精确匹配EM+格式奖励,信号稀疏;第二代引入过程级奖励(StepSearch的信息增益奖励、R-Search的证据效用奖励);第三代开始探索多面向组合奖励,包括正确性、效率、多样性、证据质量的联合优化。华为综述提出的MT-GRPO混合即时搜索质量反馈与部分结果信号,代表了信用归属技术的重要进步。过程级奖励设计目前是RL方向最高价值的研究课题之一,当前结果级奖励信号太稀疏的问题在长程任务中尤为突出。
训练范式上,"SFT冷启动 + RL微调"的两阶段管线已成为行业标准。约半数工作采用这个路线,普遍报告更好的早期稳定性和更快收敛。ZeroSearch探索了无需SFT的纯RL路线(将LLM转化为检索模块模拟搜索引擎),大幅降低训练成本,在特定场景下展现了可行性,但尚未成为主流。EvolveSearch实现了"RL训练→生成高质量轨迹→蒸馏回SFT数据"的自强化循环,代表了迭代自演进方向的探索。
四、评估体系:领域最大的技术债务
我认为评估滞后是当前制约DR领域发展最严重的问题之一,但在日常讨论中被严重低估。
几乎所有综述都指出了同一个缺口:现有基准主要评估QA准确性,而DR系统的核心产出是结构化研究报告。HotpotQA考验多跳推理,GAIA测试多步任务执行,BrowseComp评估开放式网络搜索——这些都有价值,但它们评估的是"找到正确答案"的能力,而不是"生成高质量研究报告"的能力。

目前仅DeepResearch Bench和DeepResearchGym两个基准覆盖了报告生成在内的全部四个模块。DeepResearch Bench是"首个专为DR设计的报告评估基准",评估PhD级研究报告质量;DeepResearchGym提供覆盖全流水线的研究任务沙箱。这两个基准的出现是积极信号,但在实际使用中的覆盖率还远不够。
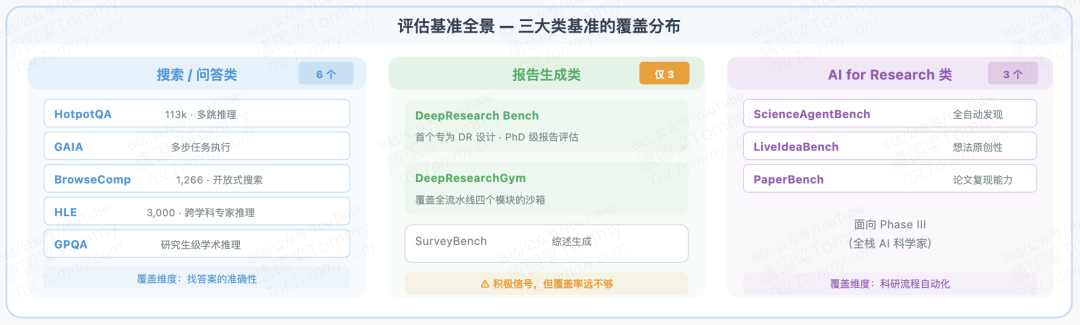
更深层的问题有几个:LLM-as-Judge存在系统性偏差(长度偏好、风格偏好);多模态推理的评估基准几乎空白;长文本逻辑连贯性没有成熟评估方法;区分创造性重组与无根据臆测的边界模糊。当我们说某个DR系统"GAIA达到67.4%"时,这个数字捕获的只是能力的一个切面。

对研究者来说,这里有高价值的机会:设计覆盖报告生成质量、事实完整性、引用准确性的综合评估框架,是一个既有学术价值又有工程需求的研究方向。
五、当前真实位置:Phase I到Phase II的过渡期
山东大学综述提出的三阶段路线图是整份报告中我最认可的分析框架:Phase I(Agent搜索)相对成熟,Phase II(集成研究)快速发展,Phase III(全栈AI科学家)处于早期探索。多伦多大学更给出了六级自动化分级(类比自动驾驶),目前最先进的系统大致处于Level 2(智能助手)阶段。
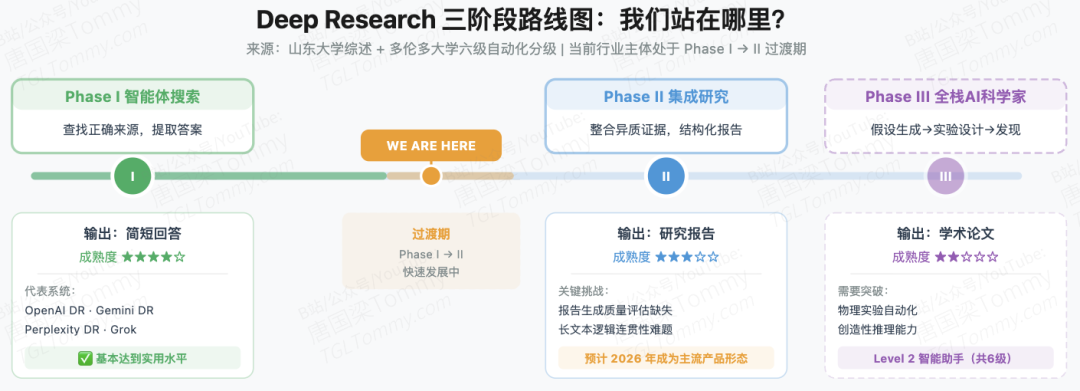
这个定位比大多数商业宣传要诚实得多。当前行业主体处于Phase I到Phase II的过渡期:商业问答任务基本达到实用水平,但真正的"集成研究"——从多源异质信息中生成有学术价值的综合报告——仍然是难题,Phase III需要"物理实验自动化、创造性推理等根本性突破",不是短期能跨越的门槛。
商业系统能力对比中有几个数字值得关注:OpenAI DR(基于o3)在GAIA达到67.4%、HLE达到26.6%;Manus(Claude 3.5+GPT-4o)在GAIA高达86.5%;Perplexity DR用开源DeepSeek-R1在SimpleQA上达到93.9%。最后这个案例意义重大——开源模型+工程优化确实能追上闭源商业系统,这对整个开源社区是强有力的激励信号。

六、主要技术分歧:哪些问题还没有定论
单Agent vs. 多Agent架构是目前最大的分歧。Search-R1等工作认为单一强大模型通过端到端RL就能胜任;OPERA、OWL、Manus则认为专业化分工是处理复杂任务的必要条件。我的判断是:这个分歧不会被简单"解决",而是会根据任务复杂度分层收敛。简单标准化任务单Agent更高效,复杂多源研究多Agent更灵活,两种架构会长期并存,不存在统一的最优解。
"冷启动是否必要"的争论也未完全决出:WebSailor等工作认为SFT冷启动对复杂Web任务不可或缺;ZeroSearch等探索纯RL训练,已展现出可行性。主流仍采用冷启动路线,但我认为随着基础模型推理能力的持续提升,纯RL路线的适用范围会逐渐扩大。

七、给从业者的清醒判断
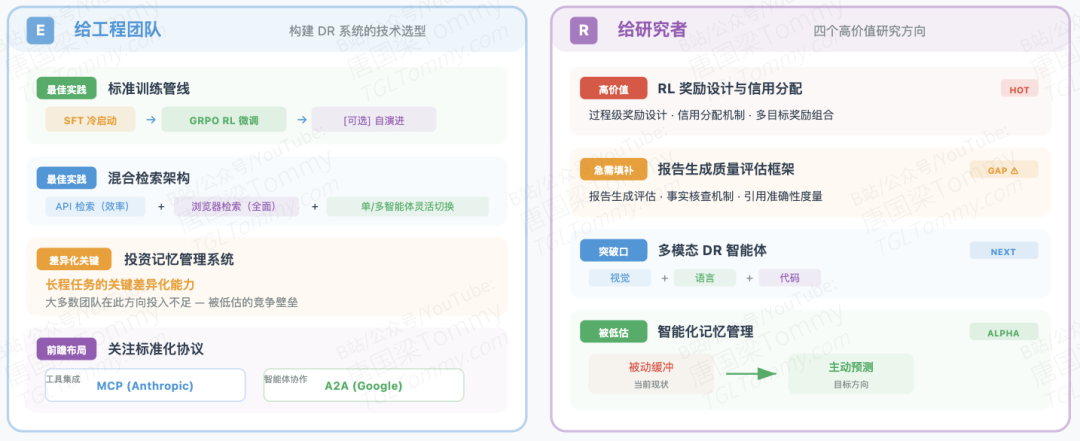
对构建DR系统的工程团队:采用SFT冷启动 + GRPO微调的标准训练管线;混合检索架构(API+浏览器)是当前最佳实践;记忆管理系统是长程任务的关键差异化能力,这是目前大多数团队投入不足的方向;关注MCP(Anthropic提出的工具集成协议)和A2A(Google提出的多Agent协作协议)的生态演进,为工具集成做好架构准备。
有一个判断我认为特别值得重视:垂直领域DR(金融、医学、法律)的商业价值高于通用DR。垂直领域有更清晰的评估标准、更高的决策价值、更容易形成护城河。通用DR市场由OpenAI、Google等头部公司主导,创业公司和中小研究团队在垂直领域有更大的空间。
对研究者:过程级奖励设计和信用分配机制是RL方向的高价值课题;报告生成质量评估框架是急需填补的空白;多模态DRAgent(视觉+语言+代码)是下一个重要突破口;智能化记忆管理(从被动缓冲到主动预测)是被低估的基础设施研究方向。
当前最清醒的认知是:我们现在的Deep Research,主要仍是"更智能的信息获取",距离真正意义上的"研究自动化"还有明显距离。评估体系的滞后、事实核查机制的不成熟、全栈AI科学家仍在Level 2的现实——这些提醒我们,最有价值的投资是把Phase I到Phase II的过渡做扎实,而不是跳跃式地追求Phase III的愿景。技术浪潮来得足够猛,但清楚地知道自己站在哪里,比跟着热度走更重要。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号