微软 VibeVoice:迈向超长、高质量、多人的对话语音生成

微软 VibeVoice:迈向超长、高质量、多人的对话语音生成

唐国梁Tommy
发布于 2026-06-25 21:09:24
发布于 2026-06-25 21:09:24
今天我们要深入探讨一项来自微软研究院的最新力作——VibeVoice。
在AI语音合成领域,我们已经习惯了手机导航的清晰指引、智能音箱的简短应答。这些单一、短句的文本到语音(Text-to-Speech, TTS)技术已相当成熟。但如果我们想让AI生成一段长达90分钟、多人参与、情感丰富、氛围自然的播客,或者一本多人角色扮演的有声书呢?现有的技术往往会捉襟见肘,拼接感、机械感和情感断层的问题立刻暴露无遗。

这正是VIBEVOICE试图攻克的难题:如何实现可扩展、高质量的长篇多说话人对话语音合成。这篇技术报告不仅展示了惊人的成果——生成长达90分钟、支持最多4位说话人的对话,并且在各项评测中超越了包括谷歌和ElevenLabs在内的顶尖模型——更重要的是,它为我们揭示了一套极具启发性的技术范式。
这篇文章将带你深入技术细节,用最通俗的语言,为你拆解VIBEVOICE背后的核心思想、关键算法和工程巧思。
从“朗读机器”到“虚拟对话伙伴”的鸿沟
传统的TTS系统,本质上是一个“朗读机器”。你给它一段文字,它为你生成一段语音。这种模式在处理短文本时表现出色,但在长篇对话中却面临三大核心挑战:

1. 上下文连贯性:
长对话中,情感和语调会随着上下文动态变化。简单的句子拼接无法捕捉这种微妙的流动感,导致听起来像多个独立的句子被生硬地粘合在一起。
2. 说话人身份与自然转换:
在多人对话中,不仅要保持每个说话人音色的高度一致性,还要模拟真实对话中的轮流、停顿和节奏感。这远比单一说话人朗读要复杂得多。
3. 计算与稳定性的瓶颈:
音频是高维度的连续信号,一分钟的高保真音频就包含数百万个数据点。要一次性生成或在自回归模型中稳定维持数十分钟的上下文,对计算资源和模型稳定性都是巨大的考验。
VIBEVOICE的三大创新支柱
VIBEVOICE的成功并非源于单一技术的突破,而是建立在一套环环相扣、设计精妙的系统之上。我们可以将其核心创新归纳为三大支柱:
1. 范式革新:基于大语言模型(LLM)的“下一词元扩散”
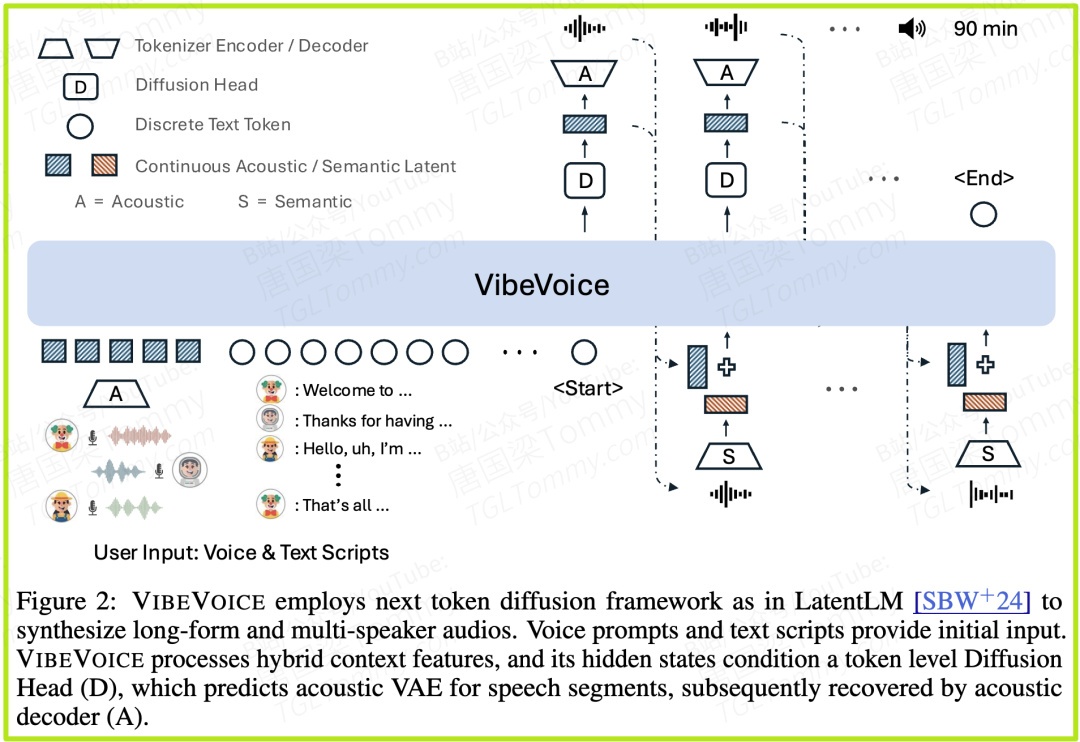
VIBEVOICE的引擎不再是传统的声码器或GAN,而是将当今AI领域最强大的两股力量——大语言模型(LLM)和扩散模型(Diffusion Models)——巧妙地结合了起来。它将语音合成重新定义为一个序列生成任务:LLM负责理解对话的宏观结构、上下文和语义,而扩散模型则在每个时间点上,精细地“雕琢”出高质量的声学细节。这种“LLM主导宏观,扩散模型精修微观”的范式,是其能够生成兼具逻辑连贯性与高保真度语音的根本原因。
2. 效率革命:3200倍压缩率的超低帧率语音令牌化器
要让LLM处理长达90分钟的音频,最关键的一步就是对音频数据进行极致的压缩。VIBEVOICE为此设计了一款堪称“黑科技”的语音令牌化器(Speech Tokenizer)。它能将24kHz的高保真音频,以3200倍的压缩率转换成每秒仅7.5帧的声学词元(token)。这意味着,原来需要24000个数字表示的一秒钟音频,现在只需7.5个“信息单元”即可概括。这一突破极大地降低了LLM处理长序列的计算负担,是VIBEVOICE能够将上下文窗口延伸至90分钟的物理基础。
3. 架构巧思:解耦的声学与语义双重表征
为了让模型更清晰地学习,VIBEVOICE没有将语音的所有信息(内容和风格)混杂在一起,而是采用了“关注点分离”的设计哲学。它使用了两个独立的令牌化器:
- • 声学令牌化器:专门负责捕捉“怎么说”——即说话人的音色、情感、韵律等声学风格。
- • 语义令牌化器:专门负责捕捉“说什么”——即语音的文本内容。
这种解耦设计,使得LLM可以像搭积木一样,清晰地将指定的“内容”与指定的“风格”进行组合,大大简化了学习任务的复杂度,提升了生成质量和可控性。
方法解析:VIBEVOICE是如何工作的?
理解了三大支柱后,让我们深入其工作流程。我们可以用一个“导演与演员”的类比来生动地解释这个过程。
场景设定:我们要生成一段播客,主持人Alice邀请嘉宾Bob进行对话。 核心角色:
- • 导演:大语言模型(LLM, Qwen2.5)
- • 演员A/B的声纹卡片:用户提供的Alice和Bob的语音样本
- • 剧本:用户提供的对话文本
- • 表演指导:词元级扩散头(Token-Level Diffusion Head)
- • 摄影机/录音师:语音令牌化器(Speech Tokenizers)
第一幕:选角与剧本围读(输入处理)
1. 演员试音(编码语音样本):“录音师”(声学令牌化器)拿到Alice和Bob的5秒语音样本。它会从中提取出最核心的声学特征,生成两张包含他们独特音色、风格的“声纹卡片”,我们称之为声学潜码和。
2. 剧本分发(编码文本):对话剧本被转换成标准的文本嵌入,这是“导演”(LLM)能够理解的语言。
3. 整合通告单:“导演”拿到一份清晰的指令序列,格式如下:
[定义说话人1的声纹是 z_Alice, 定义说话人2的声纹是 z_Bob] + [说话人1的台词是 T_Alice, 说话人2的台词是 T_Bob]
这份“通告单”清晰地告诉了导演,接下来有哪几位演员,他们的声音是什么样的,以及他们分别要说什么台词。
第二幕:导演的调度(LLM的上下文理解)
“导演”(LLM)开始阅读这份通告单。凭借其强大的长文本理解能力,它会构建一个完整的“导演构思”。对于剧本中的每一个词,它都会在脑海中形成一个详尽的调度计划——隐藏状态。这个计划包含了:
- • 当前是谁在说话?(Alice)
- • 她要用哪种声音?(基于声纹卡片)
- • 她要说什么内容?(剧本中的某个词)
- • 她应该带有什么样的情绪和语调?(基于上下文,例如,开场时应是热情欢迎的语气)
这个隐藏状态就是LLM为下一阶段生成的“指导蓝图”。
第三幕:精湛的表演(词元级扩散生成)
现在,“表演指导”(扩散头)登场了。它的工作是根据“导演”的蓝图,指导演员完成每一个瞬间的表演。
- 1. 从白板开始:对于每一个需要生成的语音词元,扩散过程都从一个完全随机的噪声向量开始。这可以想象成一个没有任何表演指令的演员,状态是混沌的。
- 2. 迭代式指导:“表演指导”会看着“导演”的调度计划,然后对演员进行多轮(论文中为10轮)指导。每一轮指导,都会将演员的混沌状态向目标表演(即最终的声学特征)修正一点点。这个过程使用了DPM-Solver++这一高效的采样器来加速。
- 3. 最终呈现:经过10轮精细打磨,演员的状态从完全随机的噪声,变成了一个完美的、蕴含了正确内容、音色和情感的声学表演——声学特征。
第四幕:后期制作与成片(音频解码)
所有表演片段(声学特征序列)都已完成,现在需要“录音师”(声学令牌化器)的解码器将其“渲染”成最终的音频。解码器接收这些高度压缩的声学特征,将它们还原成我们能听到的、高保真度的24kHz音频波形。
至此,一段高质量的对话片段就生成了。而对于长达90分钟的播客,VIBEVOICE采用自回归的方式,将刚刚生成的音频片段编码后,作为新的上下文信息,反馈给“导演”(LLM),让它在生成下一句话时,能够“听到”前一句话,从而实现对话的无缝衔接和自然流动。
实验结果与分析:VibeVoice 的实力认证
空谈理论不如实战检验。VIBEVOICE在多项严格的评估中展示了其卓越的性能。
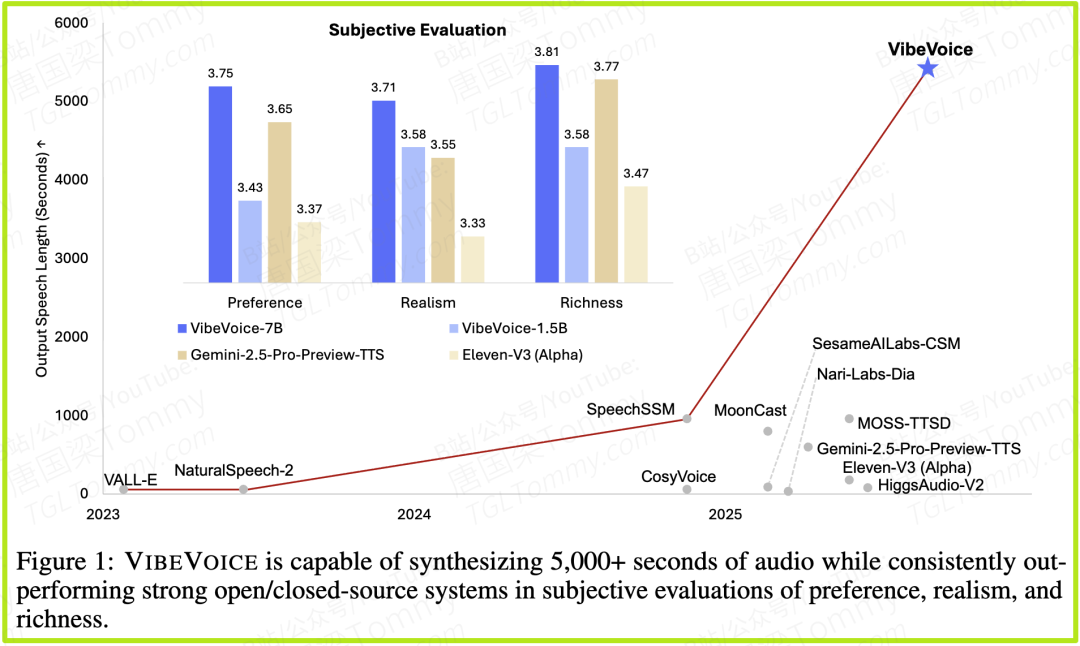
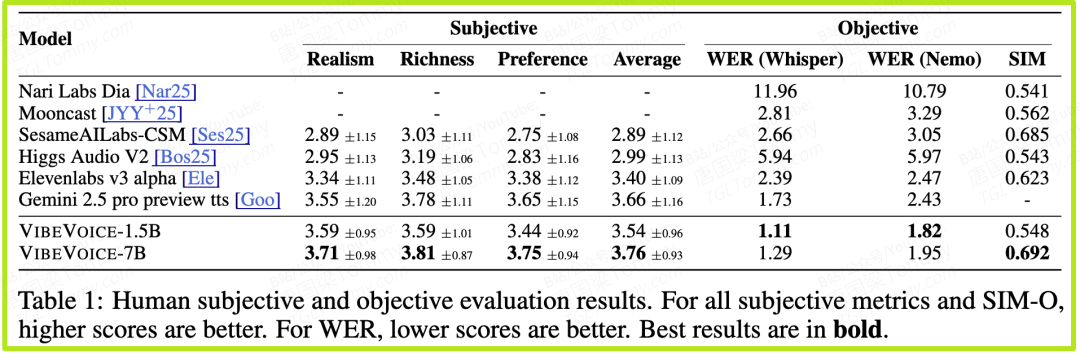
- 1. 长篇对话主观评测(表1)
- • 评测方式:研究者招募了24名人类评估员,让他们从真实感(Realism)、**丰富度(Richness)和综合偏好(Preference)**三个维度,对VIBEVOICE和多个顶尖模型(包括谷歌的Gemini 2.5 Pro Preview TTS、ElevenLabs v3等)生成的长篇对话进行盲听打分。
- • 关键结果:VIBEVOICE-7B模型在所有三项主观指标上均获得了最高分。例如,其真实感得分为3.71,偏好度得分为3.75,显著优于所有竞争对手。这直接证明了在人类听众的感知中,VIBEVOICE生成的多人对话是最自然、最富表现力、最令人愉悦的。
- 2. 客观指标分析
- • 词错误率(WER):VIBEVOICE-1.5B模型取得了最低的WER(1.11),意味着其语音转录后的文本准确率最高。有趣的是,性能更强的7B模型WER略高(1.29),但这反而揭示了一个深刻的洞见:在对话场景中,完美的吐字清晰度(低WER)并非唯一追求,更自然的韵律和情感(高主观分)可能更重要。
- • 说话人相似度(SIM):VIBEVOICE-7B获得了最高的说话人相似度(0.692),表明其对用户提供的语音样本音色模仿得最为逼真。
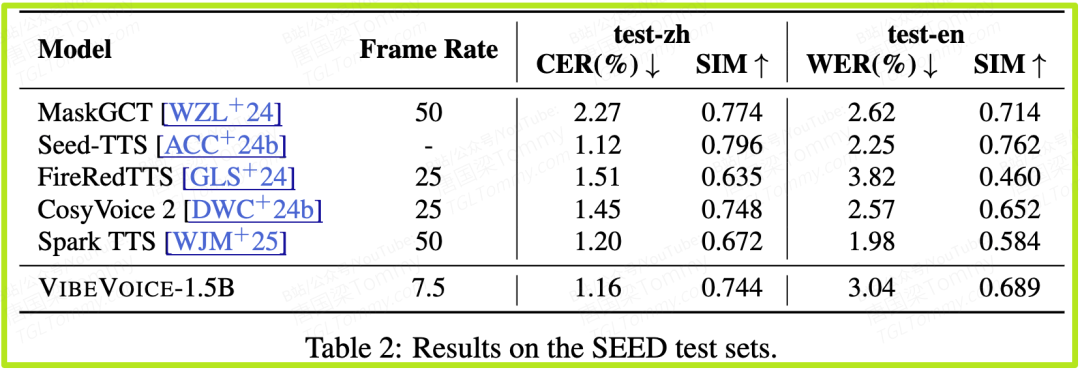
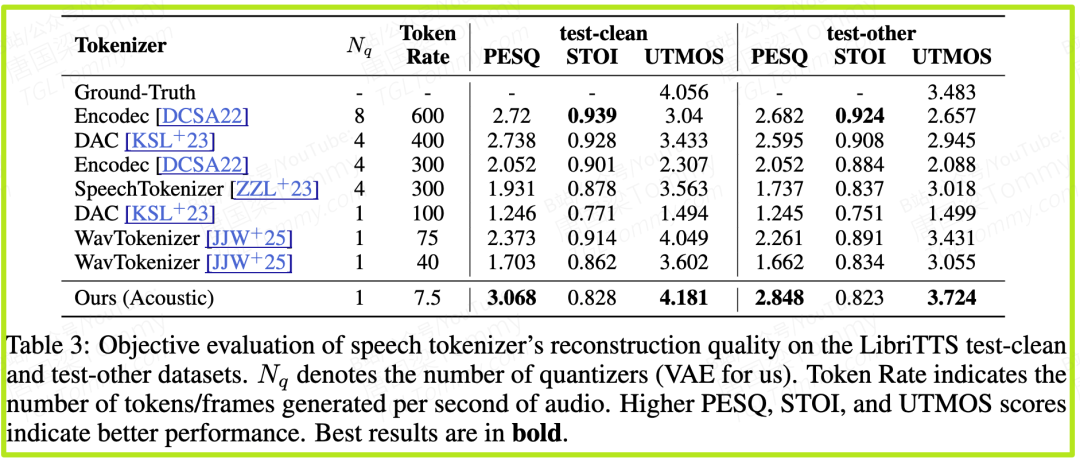
- 3. 令牌化器性能验证(表3)
- • 这是支撑整个系统有效性的基石。实验证明,VIBEVOICE的声学令牌化器,在7.5 Hz的超低帧率下,其重建音频的客观感知质量得分(UTMOS)高达4.181。相比之下,像Encodec这样的模型,即使在400Hz或600Hz(即数十倍于VIBEVOICE的数据量)下,其UTMOS得分也远低于VIBEVOICE。这强有力地证明了其令牌化器在极致压缩和高保真度之间取得了无与伦比的平衡。
通往无限逼真语音生成的未来
VIBEVOICE无疑是对话式AI语音生成领域的一个里程碑。它不仅在性能上树立了新的标杆,其技术范式也为我们指明了未来的方向。
尽管成就斐然,论文作者也坦诚地指出了当前的局限性,而这些局限性正是未来研究的金矿:
- • 多语言支持:目前模型仅支持中英文,向更多语种的扩展是必然趋势。
- • 非语音音频的融合:未来的模型需要能够生成带有背景音乐、环境音效的完整音频场景,而不仅仅是纯净的语音。
- • 复杂对话动态的建模:真实对话充满了打断、重叠和犹疑。如何对这些更复杂的动态进行建模,将是提升真实感的下一个关键。
VIBEVOICE的出现,让我们离那个AI可以作为创意伙伴,与我们共同创作播客、有声书、乃至完整影视作品的未来,又近了一大步。它证明了,通过巧妙的架构设计,我们可以驾驭LLM和扩散模型这两股强大的力量,去创造前所未有的逼真和富有表现力的听觉体验。
论文名称:VibeVoice Technical Report
第一作者:微软
论文链接:https://arxiv.org/abs/2508.19205
最新日期:2025年8月26日
github:https://github.com/microsoft/VibeVoice.git本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号