从“显式奖励”到“隐式引导”,揭秘字节团队Pass@k训练背后的“接力”策略

从“显式奖励”到“隐式引导”,揭秘字节团队Pass@k训练背后的“接力”策略

唐国梁Tommy
发布于 2026-06-25 20:59:53
发布于 2026-06-25 20:59:53
今天,我们要深入探讨一篇来自字节Seed团队的最新研究——《Pass@k Training for Adaptively Balancing Exploration and Exploitation of Large Reasoning Models》。这篇论文不仅提出了一种创新的训练方法,更重要的是,它为我们揭示了一种可能改变游戏规则的训练哲学:“隐式奖励设计”。

如果你和我们一样,关注如何让AI模型在数学、编程和逻辑推理等复杂任务上变得更“聪明”,那么这篇论文绝对不容错过。它直面了当前强化学习训练中的一个核心痛(堵)点:模型在训练中为了追求“标准答案”而变得畏首畏尾,最终限制了自身潜力的发挥。
让我们一起揭开这篇研究的神秘面纱,看看它是如何通过一种巧妙的机制,教会AI“不怕犯错”,并最终在推理能力上实现惊人飞跃的。
背景:“只认满分”的训练困境
近年来,通过强化学习与可验证奖励( RLVR)来提升大语言模型(LLM)的推理能力已成为主流。这个过程很像一位严格的老师在训练学生解题:
- • 学生解题(模型生成答案):模型针对一个问题(如一道数学题)生成一个解答。
- • 老师批改(奖励验证):一个“验证器”(可以是一个简单的程序,用于检查最终答案是否正确)来判断答案的对错,并给出奖励——通常是答对给1分,答错给0分。
- • 学生反思(模型优化):模型根据奖励信号,调整自身策略,以期下次能获得更高的分数。

这种模式在实践中非常有效,诞生了像DeepSeek-R1这样的顶尖推理模型。然而,一个根本性的问题也随之浮现:探索(Exploration)与利用(Exploitation)的困境。
标准的RLVR训练通常采用 Pass@1 作为优化目标,也就是最大化“一次就答对”的概率。这相当于老师只认可那些次次都考100分的学生。在这种“高压”环境下,模型会迅速形成一种保守策略:
- • 过度“利用”:一旦模型偶然发现某条推理路径能得到正确答案,它就会反复使用这条路径,因为这是最稳妥的得分方式。
- • 扼杀“探索”:模型会极度害怕尝试新的、不确定的解法。因为任何不完美的尝试都可能导致0分,从而受到惩罚。
这种模式的后果是灾难性的。模型可能会满足于一个局部最优解,再也无法发现更简洁、更通用或更鲁棒的解法。它的潜力被自己对“犯错”的恐惧所封印。这篇论文的核心动机,就是要打破这个“只认满-分”的魔咒,让模型敢于探索,从而突破能力的上限。
核心贡献:从Pass@k奖励到隐式设计
为了解决上述困境,论文提出了一系列环环相扣、思想层层递进的贡献:
1. 引入Pass@k作为奖励信号:
这是论文的出发点。Pass@k是一个衡量 “在k次尝试内,至少有一次成功” 的指标。将它用作奖励,相当于老师的评分标准从 “你这次必须考100分”变成了“ 给你k次机会,只要有一次考100分,就算你通过”。这自然地为模型的探索行为提供了容错空间。
2. 提出三种渐进式实现方案:
为了将Pass@k奖励高效、稳定地应用于训练,作者设计了三种方法:
- • 全采样(Full Sampling):最直观但效率低下的方法。
- • 自举采样(Bootstrap Sampling):通过随机抽样提升了效率,但引入了不稳定性。
- • 解析推导(Analytical Derivation):本文最核心的技术贡献。它用一个确定性的数学公式完全取代了随机采样,实现了稳定且高效的训练。
3. 升华至“隐式奖励设计”哲学:
这是论文思想的真正飞跃。作者发现,解析推导法的本质,其实是绕过了对“奖励”本身的定义,而是直接设计了最终指导模型学习的信号——优势函数(Advantage Function)。这开启了一扇新的大门:我们或许不再需要煞费苦心地设计复杂的奖励函数,而是可以直接塑造我们期望模型拥有的学习行为。
简单来说,这篇论文的思路是:从一个实际问题(模型不敢探索)出发,提出一个直观的解决方案(Pass@k奖励),在工程实现上不断优化,最终在理论层面提炼出一种全新的、更强大的训练范式。
方法解析:三种方法如何“教会”AI探索
为了让大家彻底理解这套方法的精妙之处,我们将沿用“老师与学生”的比喻,并结合论文图2中的具体案例进行剖析。
情境设定:
- • 问题:一个零食罐头桃子有40卡路里,是每日所需热量的2%。问每日总共需要多少卡路里?(答案:2000)
- • 学生(模型)的8次尝试:其中3次答对(
ŷ₁,ŷ₃,ŷ₄),5次答错。
1. 基线方法:Pass@1训练 —— “严苛的老师”
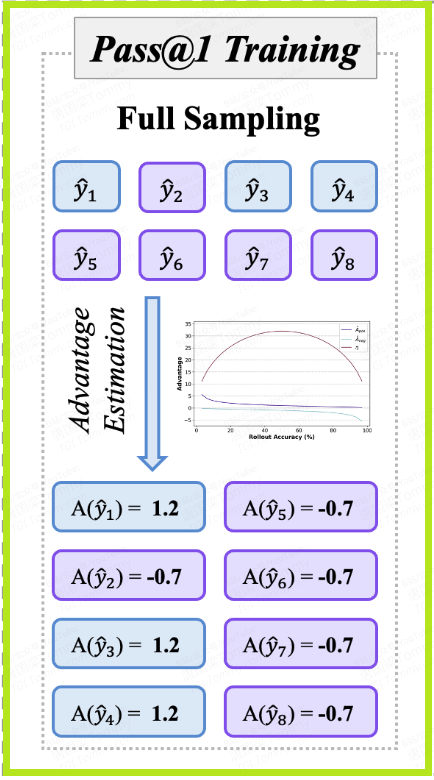
- • 教学方法:对每一份答卷独立评分,对就是1分,错就是0分。
- • 反馈机制:
- •
ŷ₁,ŷ₃,ŷ₄(正确答案)因为得分高于平均分,会收到一个强烈的正向反馈(优势值Â ≈ +1.2)。老师在说:“做得好!以后就这么写。” - • 所有错误答案,因为得分低于平均分,会收到一个强烈的负向反馈(优势值
 ≈ -0.7)。老师在说:“完全错误!以后不许这么写。”
- •
- • 后果:学生会变得非常保守,只敢写那些最有把握的解法,思维逐渐僵化。
2. 核心方法:Pass@k训练 —— “鼓励小组讨论的老师”
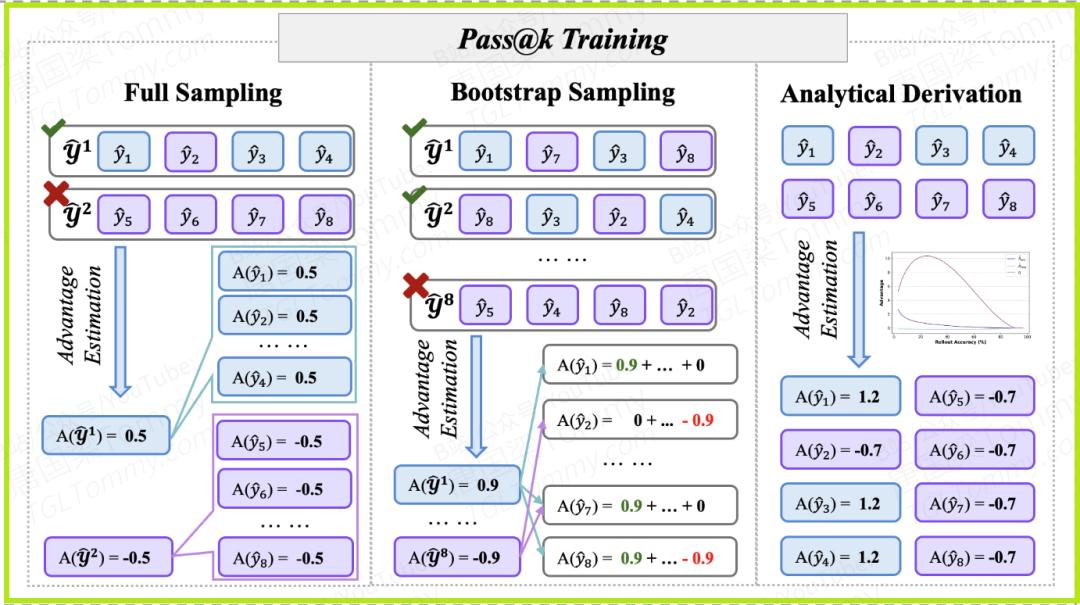
Pass@k训练的核心是改变评分单位,从评判“个人”转向评判“小组”。我们以 k=4 为例。
实现一:全采样(Full Sampling)
- • 教学方法:在学期初将8名学生分成2个固定的项目组。
- • 第1组:{
ŷ₁,ŷ₂,ŷ₃,ŷ₄} - • 第2组:{
ŷ₅,ŷ₆,ŷ₇,ŷ₈}
- • 第1组:{
- • 反馈机制:
- • 第1组因为组内有学霸(
ŷ₁,ŷ₃,ŷ₄),整个小组被评为“成功”,获得正奖励。组内所有成员,包括那个答错的ŷ₂,都收到了一个正向反馈(优势值Â = +0.5)。 - • 第2组因为全是错误答案,小组被评为“失败”,所有成员都收到了负向反馈(优势值
 = -0.5)。
- • 第1组因为组内有学霸(
- • 亮点与问题:
- • 亮点:那个犯了错的
ŷ₂,因为和学霸们“沾了光”,没有受到惩罚反而得到了鼓励。这相当于老师在说:“虽然你这次错了,但你参与的这个小组讨论方向是好的,这种尝试值得肯定!” 这就是对探索的保护。 - • 问题:效率太低。8次尝试最终只产生了2个反馈数据点,而且如果总人数不是小组大小的整数倍,还会有人被“浪费”掉。
- • 亮点:那个犯了错的
实现二:自举采样(Bootstrap Sampling)
- • 教学方法:为了解决效率问题,老师变得更灵活。每次都从8名学生中随机抽取4人组成一个“临时委员会”进行汇报,重复多次(比如8次)。这样,一个学生可以参加多个委员会。
- • 反馈机制:每个学生的最终得分,是他参加的所有委员会得分的总和。
- • 亮点与问题:
- • 亮点:数据利用率大大提升。8次尝试可以生成8个甚至更多的反馈数据点,反馈信号的估计更准确。
- • 问题:引入了随机性。一个学生这次的得分,很大程度上取决于他被随机分配给了哪些“神队友”或“猪队友”。这种不确定性会导致学生的学习过程(模型训练)非常不稳定,成绩时好时坏。
实现三:解析推导(Analytical Derivation)
这是本文最高明的部分。这位超级教师认为,既然随机分组会导致成绩不稳定,那我何必多此一举去分组呢?我可以直接从全局的数学期望出发,为每个学生计算出一个最公平、最稳定、最能反映其贡献的“指导分数”。
教学方法:完全跳过分组过程。
1️⃣ 清点全局信息:老师首先看清全局:班里有8份答卷,3份正确 (N_pos=3),5份错误 (N_neg=5)。我要评估的是大小为4 (k=4)的小组。
2️⃣ 进行理论计算:
- • 计算平均成功率:老师心算:“如果我随机从这8份答卷里抽4份,这个小组完全失败(全是错误答案)的概率是 。那么,小组的平均成功率就是 。” 这就是组的平均奖励 。
- • 计算波动情况:老师接着算出这种成功率的理论标准差 ,大约是 。
3️⃣ 给出最终指导分数(优势值):
- • 对于任何一份正确答卷:老师认为,它的贡献是明确的,它确保了自己所在的小组100%成功。因此,它的指导分数是“成功”相对于“平均成功率”的优势。
所有正确答案都会得到这个完全相同的正向指导分。
- • 对于任何一份错误答卷:老师的思考更深入。一份错误答卷,有可能“搭便车”成功,也有可能导致小组失败。它的最终指导分数应该是这两种情况的期望值。经过计算(细节见论文Eq. 15),它会得到一个固定的负向指导分,大约是
≈ -0.167。
亮点:
- • 绝对稳定:完全消除了随机性,每次的反馈信号都是确定和稳定的。
- • 极致高效:只需一次全局计数和几次公式计算即可。
- • 智能调节:更神奇的是,这个指导分数是动态变化的。
- • 当班里正确答案很少时(探索初期), 会变得巨大(重奖稀有的成功),而 会接近于0(容忍普遍的失败)。
- • 当班里正确答案很多时(掌握后期), 会接近于0(没必要再强化已知知识),而 的惩罚力度会急剧增大(集中火力纠正顽固错误)。
这种方法,实际上就是我们前面提到的 “隐式奖励设计”。老师不再纠结于“这道题值几分”,而是直接设计了最终的、带有智能调节功能的“学习指导信号”。
实验结果:探索真的带来了回报
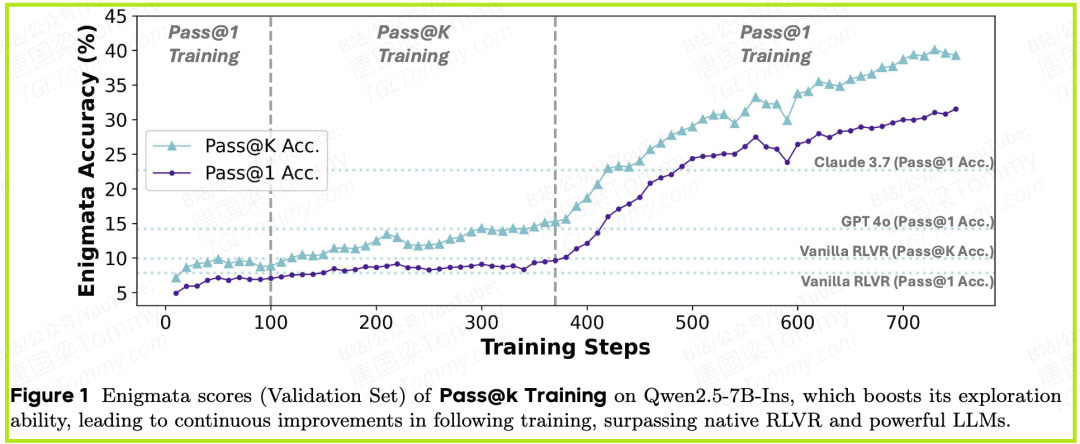
1. Pass@k训练有效且稳定:
- • 在论文的图3和图5中,我们可以清晰地看到,在Maze(走迷宫)任务上,传统的Pass@1训练很快就遇到了性能瓶颈,而所有Pass@k训练方法都能持续提升模型的Pass@k性能。
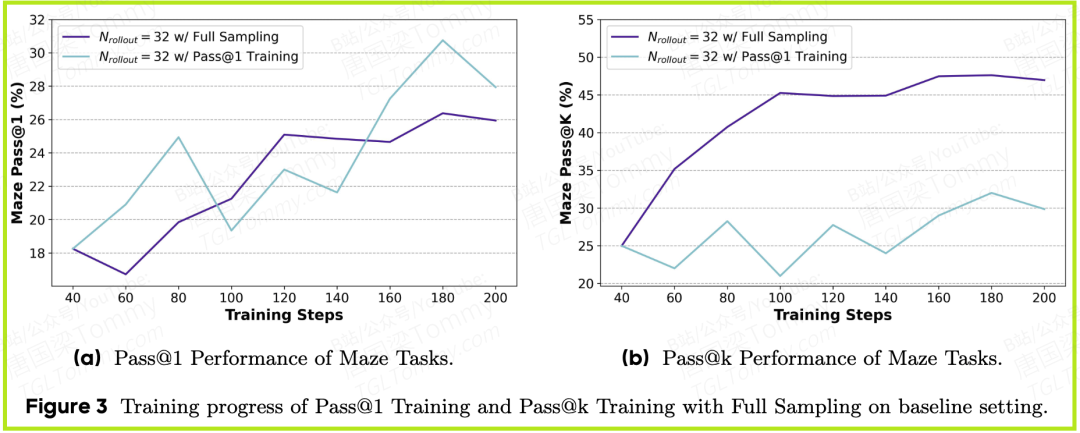
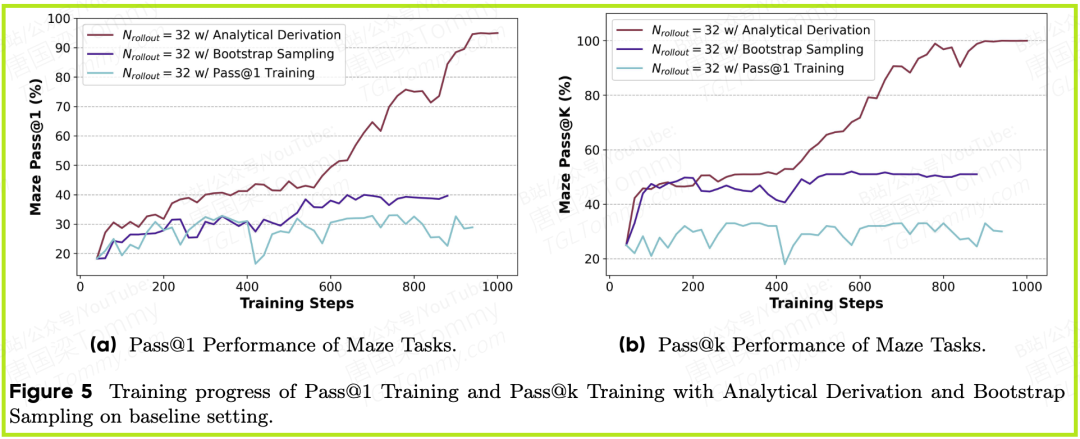
- • 其中,解析推导法的性能曲线最为平滑、上升趋势最稳定,验证了其消除采样方差的优越性。
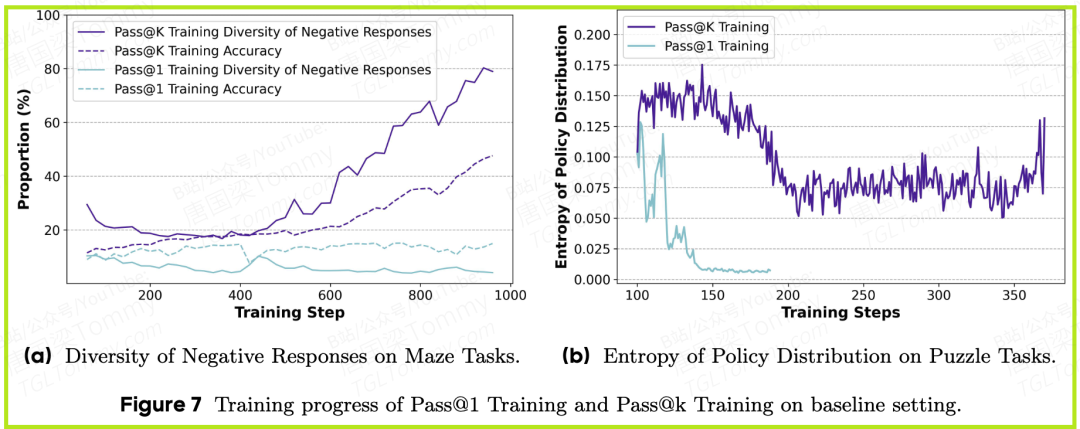
2. 探索能力的显著提升:
- • 答案更多样:图7a显示,Pass@k训练能让模型在犯错时,也尝试生成更多样化的错误答案,而不是重复同一种错误。这正是探索的体现。
- • 策略熵更高:图7b显示,Pass@k训练能将模型的策略熵维持在较高水平,意味着模型的“思路更开阔”,而不是固守一种解法。
3. 最惊人的发现:1 + 1 > 2 的训练策略
- • 这篇论文最具实践指导意义的发现,体现在表2中。作者尝试了一种“接力”训练法:先进行Pass@k训练,再进行Pass@1训练 (
P@k T. + P@1 T.)。
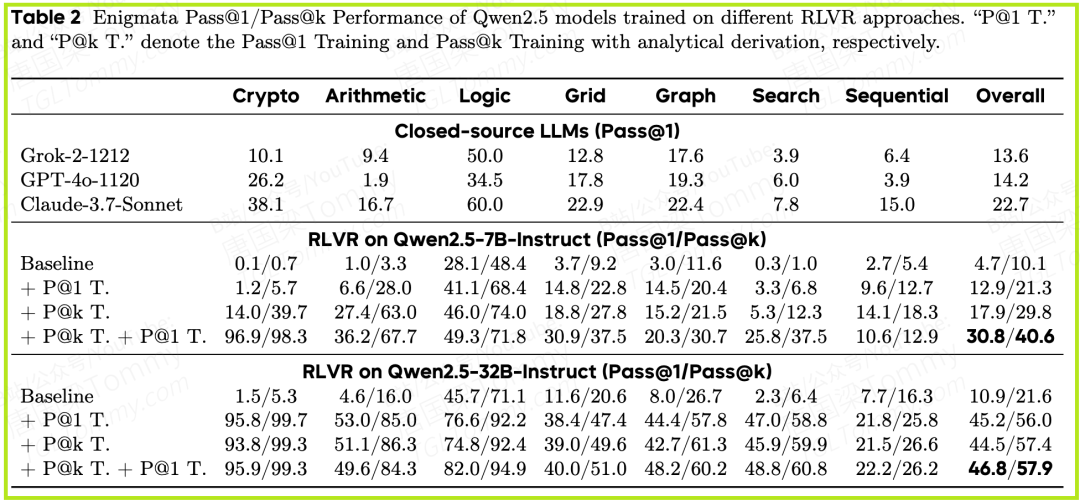
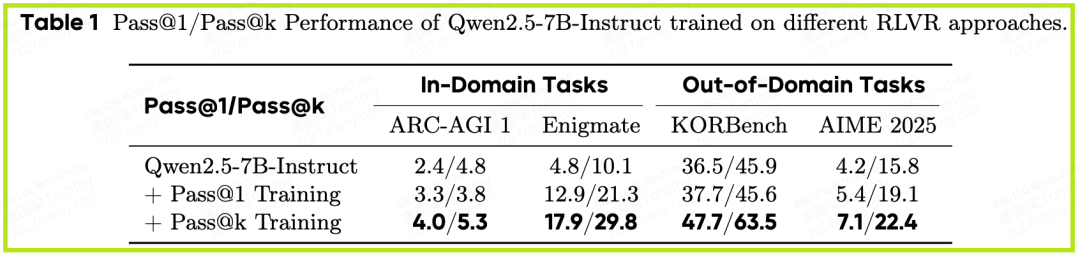
- • 结果如何? 在Enigmata这个复杂的逻辑推理基准上,7B参数的Qwen2.5模型,通过这种“先探索,后利用”的接力训练,其Pass@1性能(一次就答对的能力)实现了巨大飞跃,综合得分从基线的4.7飙升至30.8。
- • 更令人印象深刻的是,如图1所示,经过这样训练的7B模型,其Pass@1准确率甚至超越了像GPT-4o和Claude 3.7这样的业界顶尖闭源大模型。
这强有力地证明了:Pass@k训练并非仅仅提升了模型的“瞎猜”能力,而是真正为其打开了一个更广阔的解空间,使其能够发现并学习到以往无法触及的更优策略。 随后的Pass@1训练,则是在这个更优的起点上进行精细打磨,从而达到了前所未有的高度。
这篇论文带给我们的,不仅仅是一种名为“Pass@k”的训练技巧,更是一种思想上的启迪。
未来的强化学习研究,或许可以沿着“隐式奖励设计”的道路继续探索。我们不必再将自己局限于设计复杂的奖励函数,而是可以把目光投向更本质的目标:我们希望模型在学习的不同阶段,展现出什么样的行为? 我们可以尝试直接设计能够引导这些行为的优势函数曲线,从而对模型的成长过程实现更精细、更智能的控制。
论文名称:Pass@k Training for Adaptively Balancing Exploration and Exploitation of Large Reasoning Models
第一作者:字节
论文链接:https://arxiv.org/abs/2508.10751
最新日期:2025年8月14日
github:https://github.com/RUCAIBox/Passk_Training.git本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号