OpenSpec 管需求,Superpowers 管落地,中间还差一座桥

OpenSpec 管需求,Superpowers 管落地,中间还差一座桥

java金融
发布于 2026-06-11 19:34:30
发布于 2026-06-11 19:34:30
事情是这样的。
有个跑了几年的 Java 订单系统,Spring Boot 写的,支付链路也不算复杂。
用户下单以后跳三方支付,支付平台回调我们系统,我们再把订单从 WAIT_PAY 改成 PAID,顺手写一条支付流水,再发一个发货事件。
一开始都挺正常。
直到有天测试同学模拟支付平台重复回调,同一个 payTradeNo 连续打了两次。
第一次返回成功。
第二次也返回成功。
表面看没问题,支付平台本来就可能重复通知,回调接口做成幂等也应该返回成功。
但看数据库的时候,大家沉默了。
订单状态是 PAID,这个没错。
支付流水插了两条。
发货事件也发了两次。
更麻烦的是,AI 第一版修复看起来还挺像那么回事:加了 if (order.isPaid()) return success,补了几个单测,接口也能跑。
然后 code review 一看,问题又来了。
并发回调时两个线程同时读到 WAIT_PAY 怎么办?
事务边界放在哪里?
唯一约束加在哪张表?
消息发送是在事务内还是事务后?
如果三方金额和本地订单金额不一致,应该返回成功、失败,还是记录异常等待人工?
这类需求最容易让 AI 编程翻车。
不是因为 AI 不会写 Java。
而是支付回调幂等不是一个 if 判断,它是业务状态机、数据库约束、事务边界、并发测试和外部协议一起构成的工程问题。
OpenSpec 和 Superpowers 的组合,真正要解决的就是这个问题。
我先给一句判断:
OpenSpec 管方向,Superpowers 管施工,但中间必须有一层桥。没有桥,双框架混用反而会制造更多返工。
OpenSpec 负责锁住「做什么、为什么做、哪些不做」。
Superpowers 负责约束「怎么拆、怎么测、怎么 review、怎么收尾」。
二者不是竞品。
它们更像一张建筑蓝图和一套施工规范。
蓝图再好,施工乱来会出事故。
施工再规范,方向错了也是精装修烂尾。
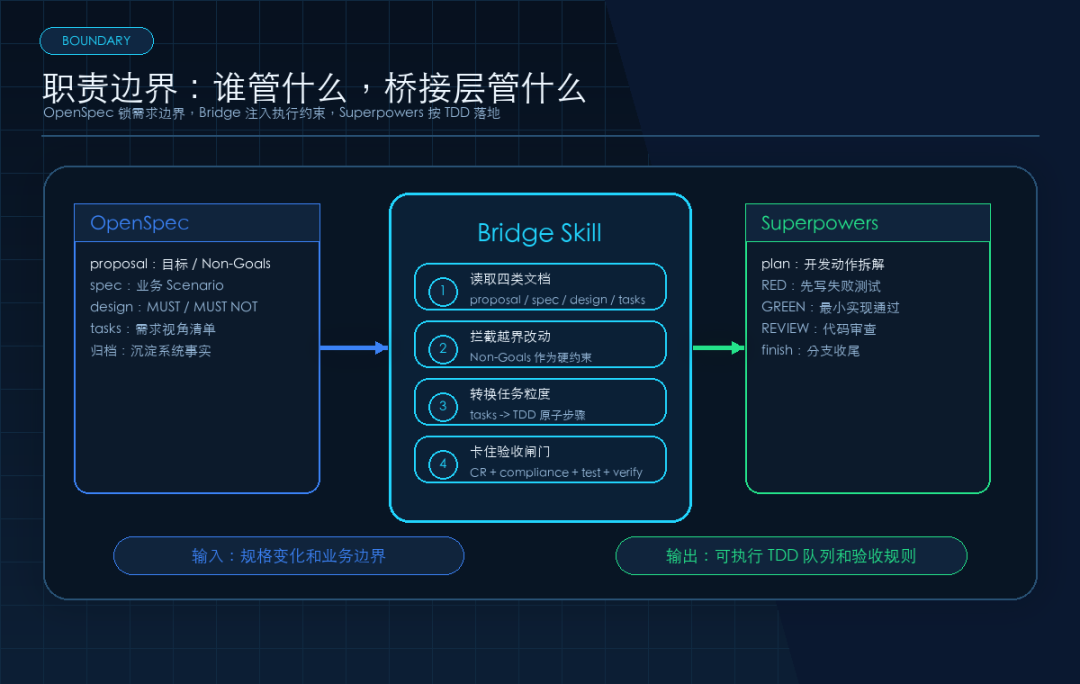
先把分工讲清楚,不然后面一定乱
OpenSpec 的核心价值,是把一句模糊需求变成可审查、可归档、可同步的规格变化。
在一个正常 change 里,它通常会沉淀这些东西:
openspec/
changes/
add-payment-callback-idempotency/
proposal.md
design.md
tasks.md
specs/
payment-callback/
spec.md
这些文件分别回答不同问题:
产物 | 解决的问题 | 支付回调幂等里的例子 |
|---|---|---|
proposal.md | 为什么改,改什么,不改什么 | 修复重复回调,不改三方协议,不重做支付网关 |
spec.md | 系统必须满足哪些业务场景 | 首次成功、重复通知、并发通知、金额不一致 |
design.md | 技术方案和约束 | 幂等表唯一键、事务边界、状态机、事务后发事件 |
tasks.md | 需求视角的落地清单 | 幂等表、服务改造、并发测试、回归测试 |
Superpowers 的关注点不一样。
它不是需求库,而是一套 AI 编码纪律。
它会把开发过程拆成 brainstorm、写计划、TDD、子 Agent 执行、代码审查、分支收尾这些动作。
所以二者天然互补:
维度 | OpenSpec | Superpowers |
|---|---|---|
核心问题 | 做什么,为什么做 | 怎么做,做到什么标准 |
主要产物 | proposal、spec、design、tasks、归档规范 | 计划、测试、实现、review、分支收尾 |
最大价值 | 防止 AI 做错需求 | 防止 AI 野蛮编码 |
最大风险 | 规范写完,落地质量失控 | 代码质量很好,业务方向跑偏 |
单独用 OpenSpec,常见情况是需求写得很漂亮,但 AI 实现时一次性改一堆文件,测试少,提交粒度粗。
单独用 Superpowers,常见情况是 TDD 很认真,代码也干净,但它没有稳定读取需求边界,容易自主扩功能。
所以这篇文章只讨论一个主问题:
怎么让 OpenSpec 的规格约束,真正进入 Superpowers 的 TDD 执行链路。
真实场景,Spring Boot 订单支付回调幂等改造
先把业务边界写死。
项目现状:
已有能力:
- Spring Boot 订单服务接收三方支付回调
- 回调成功后更新订单状态 WAIT_PAY -> PAID
- 插入 payment_record 支付流水
- 发布 OrderPaidEvent 给后续发货链路
新增目标:
- 同一个三方支付流水重复回调只能处理一次
- 并发重复回调最多只能产生一条支付流水
- 已处理成功的重复回调仍返回 SUCCESS,避免三方持续重试
- 金额不一致、订单不存在、状态非法时进入异常分支,不触发发货
明确不做:
- 不改三方支付平台回调协议
- 不重构整套支付网关
- 不改变订单主状态机定义
- 不把历史支付流水批量迁移
这个「明确不做」非常关键。
很多 AI 编程事故,不是它少写了东西。
是它太积极,顺手把不该动的东西也动了。
proposal.md 里可以这么写:
# Proposal: add-payment-callback-idempotency
## Why
支付平台可能重复推送同一笔支付回调。当前系统只判断订单状态,
无法防住并发重复回调,存在重复支付流水和重复发货事件风险。
## What Changes
- 新增 payment_callback_idempotency 幂等表
- 以 channel + pay_trade_no 建立唯一约束
- 回调处理进入事务,先抢占幂等记录,再更新订单和支付流水
- 重复成功回调返回 SUCCESS,但不重复写流水、不重复发事件
- 金额不一致或订单状态非法时记录异常,不触发后续业务动作
## Non-Goals
- 不修改三方支付平台回调协议
- 不重构支付网关和支付渠道抽象
- 不改变订单主状态机定义
- 不处理历史脏数据迁移
spec.md 要写成可验收场景。
比如并发重复回调这个坑,必须提前写进去:
### Requirement: Payment callback idempotency
The system SHALL process the same payment callback only once.
#### Scenario: same callback arrives concurrently
- GIVEN an order is in WAIT_PAY status
- AND two callbacks have the same channel and payTradeNo
- WHEN both callbacks are handled concurrently
- THEN only one payment record is inserted
- AND the order is changed to PAID exactly once
- AND only one OrderPaidEvent is published
- AND both callbacks return SUCCESS to the payment channel
这几行不是文档装饰。
它后面会变成 TDD 测试用例。
如果 specs 没写,AI 很可能只测「重复调用两次返回成功」。
但真正线上会炸的,是两个线程同时进来。
坑 1,跳过 Explore,AI 会按默认经验乱选方案
很多人一上来就让 AI 生成 proposal。
这很危险。
支付回调幂等至少有几种常见落地方式:
方案 | 优点 | 问题 |
|---|---|---|
只判断订单状态 | 改动最小 | 并发下两个线程可能同时读到 WAIT_PAY |
Redis 分布式锁 | 能挡住部分并发 | 锁超时、释放、事务提交顺序都要处理 |
数据库唯一幂等表 | 约束强,易审计 | 需要设计幂等状态和异常分支 |
悲观锁锁订单行 | 直观 | 容易扩大锁范围,影响订单主流程 |
如果不先 Explore,AI 很容易直接写:
if (order.getStatus() == OrderStatus.PAID) {
return CallbackResult.success();
}
这在串行调用里能过。
并发下一点都不稳。
所以第一个固定动作应该是 Explore。
如果你用的是自定义命令,可以类似这样:
/opsx:explore add-payment-callback-idempotency
目标:
- 修复支付平台重复回调导致的重复流水和重复发货事件
- 必须覆盖并发重复回调
- 已成功处理的重复回调仍返回 SUCCESS
- 不改三方回调协议
- 不重构支付网关
请比较:
- 只判断订单状态
- Redis 分布式锁
- 数据库唯一幂等表
- 悲观锁订单行
输出:
- 推荐方案
- 不选其他方案的原因
- 事务边界
- 并发测试方案
- 待写入 design.md 的关键约束
这里的 /opsx:explore 可以理解成你自己封装的 OpenSpec 工作流命令。
OpenSpec 官方 core profile 里常见的是 propose、explore、apply、sync、archive 这类动作;具体 slash command 名称取决于你在 Claude Code、Cursor、Codex 里的接入方式。
关键不是命令名字。
关键是:先讨论方案,再生成规范。
坑 2,Proposal 不写 Non-Goals,AI 会顺手扩需求
支付回调幂等里最容易被 AI 顺手改的,是支付网关抽象和订单状态机。
因为从工程洁癖看,顺手重构一下很诱人。
但这次业务要求只是修复回调幂等。
所以 proposal.md 里必须写 Non-Goals,而且后面还要让合规检查读取它。
一个不合格的 proposal 是这样:
## What Changes
- Add idempotency for payment callback.
- Update payment callback service.
- Add tests for duplicate callback.
看起来没错。
但它没有说「不改什么」。
更稳的写法是这样:
## Non-Goals
- Do not change payment channel callback contract.
- Do not redesign PaymentGateway abstraction.
- Do not change order state machine definitions.
- Do not migrate historical payment records.
后面 code review 时,如果 AI 改了 PaymentGatewayFactory 或者把订单状态机重写了,这就不是「实现选择」。
这是明确违反 proposal。
坑 3,OpenSpec tasks 和 Superpowers plan 粒度天然不一样
OpenSpec 的 tasks.md 通常是需求视角:
## Tasks
- [ ] Add payment callback idempotency table
- [ ] Add repository for idempotency record
- [ ] Update payment callback service
- [ ] Add duplicate callback tests
- [ ] Add concurrent callback tests
- [ ] Add spec compliance check before archive
这对需求评审够了。
但对 TDD 执行还太粗。
Superpowers 的 plan 需要拆到开发动作:
Task: Add payment callback idempotency table
1. Write failing repository test for unique channel + payTradeNo
2. Add migration for payment_callback_idempotency
3. Add PaymentCallbackIdempotencyEntity
4. Add repository insert method
5. Run ./mvnw test -Dtest=PaymentCallbackIdempotencyRepositoryTest
6. Refactor naming and indexes
7. Commit idempotency table only
这就是桥接层要做的第一件事:
把 OpenSpec 的需求任务,转换成 Superpowers 能执行的 TDD 原子步骤。
如果不做转换,AI 很容易一口气把表、Service、Controller、消息发送、异常处理全改完。
最后你 review 的不是一个小任务。
是一锅粥。
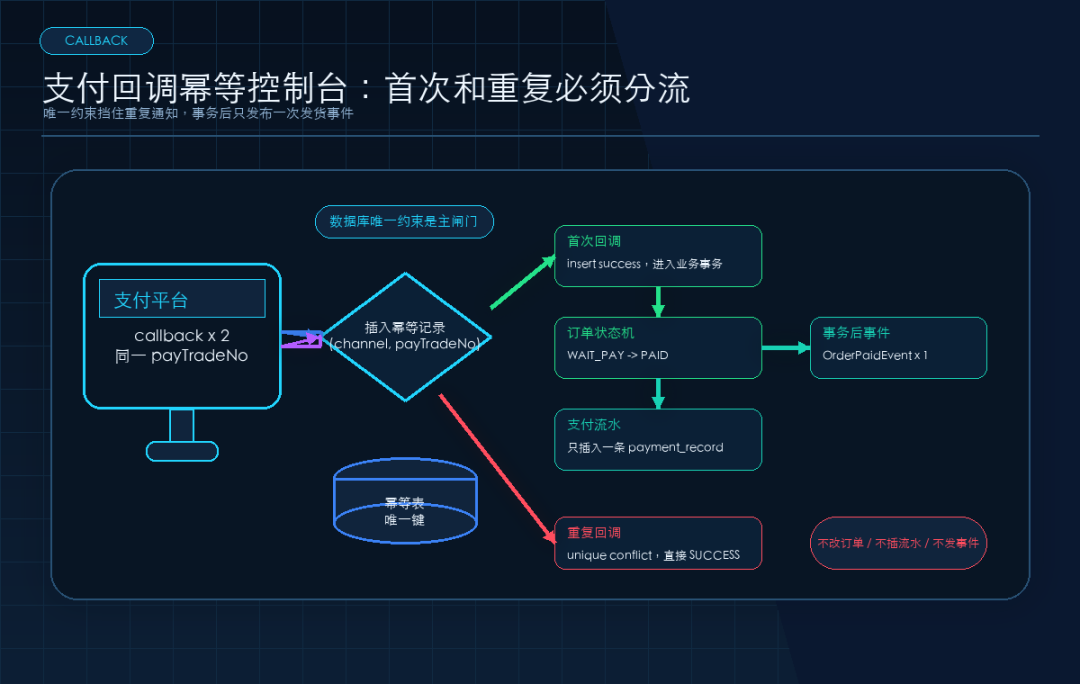
坑 4,Superpowers 空跑,会无视 design 技术约束
另一个很典型的翻车是:
OpenSpec 的 design.md 写了数据库唯一幂等表。
但 Superpowers 开始执行时,没有读取 design.md。
于是 AI 自己实现了一个本地锁或者内存 Set。
private final Set<String> processed = ConcurrentHashMap.newKeySet();
public CallbackResult handle(PaymentCallbackCommand command) {
if (!processed.add(command.payTradeNo())) {
return CallbackResult.success();
}
// update order and insert payment record
}
这段代码在单机单测里可能完全没问题。
但线上一多实例部署,直接失效。
design.md 里应该明确写:
## Idempotency design
- The system MUST use database unique constraint for idempotency.
- Unique key MUST be `(channel, pay_trade_no)`.
- Idempotency record and order payment update MUST be in one transaction.
- OrderPaidEvent MUST be published after transaction commit.
- In-memory idempotency cache is forbidden because service runs with multiple replicas.
- Redis lock MAY be used as optimization, but MUST NOT replace database unique constraint.
启动 Superpowers 实现前,必须把这些文件作为上下文输入:
请先读取:
- openspec/changes/add-payment-callback-idempotency/proposal.md
- openspec/changes/add-payment-callback-idempotency/design.md
- openspec/changes/add-payment-callback-idempotency/specs/payment-callback/spec.md
- openspec/changes/add-payment-callback-idempotency/tasks.md
执行要求:
- 严格遵守 design.md 技术约束
- 不得修改 proposal.md 的 Non-Goals 范围
- 每个 task 拆成 TDD 步骤
- 每个 task 完成后做 spec compliance check
这一步省不了。
OpenSpec 产物没有进入执行上下文,就等于没写。
坑 5,原生代码审查不等于规范合规审查
Superpowers 的 code review 很适合抓代码质量问题。
比如命名、异常处理、测试缺口、重复逻辑。
但它不一定知道这段代码是否违反了 OpenSpec。
举个例子。
代码质量看起来没问题:
@Transactional
public CallbackResult handle(PaymentCallbackCommand command) {
Order order = orderRepository.findByOrderNo(command.orderNo())
.orElseThrow(() -> new OrderNotFoundException(command.orderNo()));
if (order.isPaid()) {
return CallbackResult.success();
}
order.markPaid(command.payTradeNo(), command.paidAt());
paymentRecordRepository.save(PaymentRecord.from(command));
eventPublisher.publishEvent(new OrderPaidEvent(order.getOrderNo()));
return CallbackResult.success();
}
这段代码的结构很顺。
但它至少有三个合规风险:
- 没有
(channel, payTradeNo)唯一幂等记录 - 并发下可能重复插入支付流水
- 事件在事务内发布,事务回滚和消息消费顺序要重新确认
如果 spec.md 写了「并发重复回调只插入一条支付流水、只发布一次发货事件」,那这段代码就不合规。
普通 CR 可能会说:
代码结构清晰,事务注解存在,异常处理合理。
spec 合规检查必须再问:
- 是否覆盖 same callback arrives concurrently 场景?
- 是否存在数据库唯一约束?
- 支付流水是否和幂等记录在同一事务内?
- OrderPaidEvent 是否只发布一次?
- 是否违反 proposal 里的不改支付网关协议?
所以我建议加一个 spec-compliance-check skill。
最小规则可以这么写:
# spec-compliance-check
When reviewing code for an OpenSpec change:
1. Read proposal.md, design.md, tasks.md and all changed specs.
2. For every Scenario in spec.md, map it to:
- test file
- implementation path
- observed behavior
3. Check every Non-Goal in proposal.md against changed files.
4. Check design.md MUST / MUST NOT rules against implementation.
5. Report any mismatch as BUG, not suggestion.
注意最后一句。
违反 spec 不是风格建议。
是 bug。

坑 6,只做一种校验,会漏掉另一半问题
这里要把三个东西分开:
校验 | 主要回答 | 能抓什么 | 抓不到什么 |
|---|---|---|---|
Superpowers code review | 代码质量行不行 | 命名、异常、测试、结构 | 需求边界是否正确 |
spec compliance check | 实现是否符合规格 | Non-Goals、Scenario、design 约束 | 代码是否真的能跑 |
OpenSpec verify | 规范和实现是否一致 | 规格完整性、变更一致性 | 全量运行时问题 |
所以固定顺序应该是:
1. Superpowers code review
2. spec-compliance-check
3. ./mvnw test
4. OpenSpec verify
如果只做 code review,可能出现「代码很好,但需求错了」。
如果只做 OpenSpec verify,可能出现「规范合规,但测试没全跑」。
如果只跑 ./mvnw test,可能出现「测试全过,但支付网关协议被顺手改了」。
这三类问题不是一回事。
别用一个检查替代另一个检查。
坑 7,Archive 前不跑全量测试,归档的是隐患
OpenSpec 的 archive 很有价值。
它会把本次 change 合并进主规范,让后续 AI 能读到新的系统事实。
但也正因为这样,archive 前必须更谨慎。
如果你把一个有 bug 的增量规范归档,后续 AI 会把这个错误当成项目真相。
归档前至少要卡住这几个条件:
Archive Gate:
- proposal Non-Goals 无违反
- 所有 spec Scenario 均有测试或明确说明
- design.md MUST / MUST NOT 全部满足
- ./mvnw test 通过
- OpenSpec verify 通过
- Superpowers code review 无阻断问题
这个 gate 不应该靠人记。
最好写进桥接 skill。
自动化桥接,用一个 skill 把 5 个坑收住
真正落地时,不能指望每次都靠人手动复制文档。
我更建议写两个自定义 skill。
第一个是 spec-compliance-check,前面已经讲了。
第二个是 openspec-superpowers-bridge。
它负责把 OpenSpec 产物喂给 Superpowers,并把 tasks 转成 TDD plan。
一个可执行的规则草案如下:
# openspec-superpowers-bridge
## Trigger
Use this skill when starting implementation for an active OpenSpec change.
## Workflow
1. Locate active change under openspec/changes/.
2. Read proposal.md, design.md, tasks.md and all specs.
3. Confirm Explore and Propose are completed.
4. Skip brainstorming unless proposal is missing business boundary.
5. Convert tasks.md into Superpowers TDD plan:
- failing test
- run targeted test
- minimal implementation
- pass test
- refactor
- review
6. For every completed task:
- run targeted tests
- run spec-compliance-check
7. Before archive:
- run ./mvnw test
- run OpenSpec verify
- block archive on failures
它能自动收住 5 个坑:
坑位 | 自动化动作 |
|---|---|
坑 3,任务粒度错位 | 把 tasks 转成 TDD 原子步骤 |
坑 4,Superpowers 空跑 | 强制读取 OpenSpec 全套文档 |
坑 5,CR 不查合规 | 每个任务后调用 spec-compliance-check |
坑 6,校验二选一 | 固定 code review、合规、测试、verify 顺序 |
坑 7,归档前漏测 | archive gate 强制全量测试 |
坑 1 和坑 2 还得人来。
方案选择和需求边界,不能完全外包给 AI。
尤其是「不做什么」,这件事必须人类业务负责人拍板。
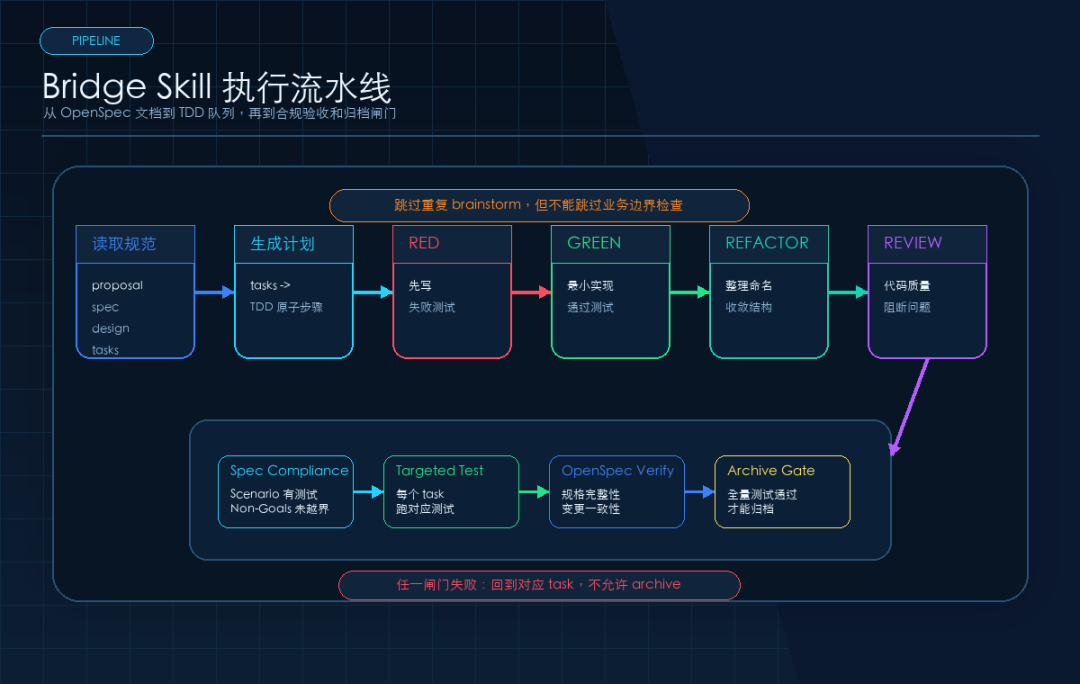
一套可复用的落地命令清单
下面这套流程可以直接套复杂需求。
如果你用的是自定义 slash command,命令名可以按自己的系统调整。
1. /opsx:explore add-payment-callback-idempotency
研讨技术路线,确认数据库唯一幂等表为主,Redis 锁最多作为优化。
2. /opsx:propose add-payment-callback-idempotency
生成 proposal.md、design.md、tasks.md、specs 增量规范。
3. 人工审核四类文档
重点看 Non-Goals、并发重复回调、金额不一致、事务边界、事件发布时机。
4. 启动 openspec-superpowers-bridge
加载 OpenSpec 文档,把 tasks 转成 Superpowers TDD plan。
5. 逐任务 TDD
RED -> GREEN -> REFACTOR,每个任务只改必要范围。
6. 单任务验收
targeted mvn test + code review + spec-compliance-check。
7. 全量验收
./mvnw test + OpenSpec verify。
8. Archive + 分支收尾
归档主规范,按 Superpowers finishing branch 流程合并、PR、保留或丢弃分支。
这个流程看起来比直接让 AI 写代码慢。
但复杂项目里,真正贵的不是写代码那半小时。
真正贵的是返工、误改老逻辑、上线后补洞、规范漂移。
什么时候不用双框架
这套东西不是所有任务都要上。
如果只是改按钮文案、修拼写、补一条日志,直接写就行。
如果是一次性脚本,用完就删,也没必要沉淀 OpenSpec。
但符合下面条件,我会建议双框架:
条件 | 建议 |
|---|---|
代码生命周期超过 1 个月 | 上 OpenSpec |
3 人以上协作 | 上 OpenSpec |
涉及权限、支付、认证、账务 | 双框架 |
存量系统新增核心能力 | 双框架 |
需要长期让 AI 读历史规范 | 双框架 |
支付回调、权限、订单状态机、租户隔离、账务对账,这些都属于双框架值得上的场景。
因为它们最怕的不是代码写不出来。
是写出来以后,看起来能跑,但业务边界已经歪了。
新手 3 分钟记住这三条
如果你不想记那么多,就记三条。
第一,永远先 Explore 再 Propose。
别让 AI 盲猜技术方案。
第二,Superpowers 开始写代码前,必须加载 OpenSpec 的 proposal、design、specs、tasks。
没有上下文的 TDD,只是在认真地跑偏。
第三,验收必须分三层。
代码质量审查
↓
规范合规审查
↓
全量测试 + OpenSpec verify
少一层,都可能漏问题。
回到开头那个支付回调
回到开头那个 Spring Boot 订单系统。
支付回调幂等不是难在怎么写一个 if (paid) return success。
这个 AI 很会。
难的是别重复入账,别重复发货,别把三方协议改坏,别让事务内事件和数据库提交顺序打架,别让 specs 和代码各走各的。
OpenSpec 负责把这些边界写清楚。
Superpowers 负责让 AI 按工程纪律一点点落地。
但中间那层桥,必须你自己搭起来。
没有桥,两个框架各自都对,项目还是会错。
有了桥,AI 编程才不只是「写得快」。
它开始变成一套能审查、能回滚、能归档、能复用的工程系统。
这才是复杂 Java 项目里真正值得追求的提效。
参考资料
- OpenSpec GitHub 仓库,https://github.com/Fission-AI/OpenSpec
- Superpowers GitHub 仓库,https://github.com/jessejvincent/superpowers
- Superpowers Skills,https://github.com/jessejvincent/superpowers/tree/main/skills
- Spring Framework Transaction Management,https://docs.spring.io/spring-framework/reference/data-access/transaction.html
- Spring Framework MockMvc,https://docs.spring.io/spring-framework/reference/testing/mockmvc.html
- Redis SET 命令,https://redis.io/docs/latest/commands/set/
- Redisson Locks and Synchronizers,https://redisson.pro/docs/data-and-services/locks-and-synchronizers/
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号