Hermes Agent的设计哲学


之前分享过Openclaw的记忆哲学:Clawdbot的记忆设计哲学
用过Hermes的人都会认同它是一个越用越聪明的Agent。
最新的罗永浩十字路口,重新访谈了李想。
李想也谈到了这一点,他觉得用Openclaw久了之后会觉得变傻,所以他已经切换到用Hermes了。
Hermes之所以越来越聪明,关键在于记忆和技能的设计。
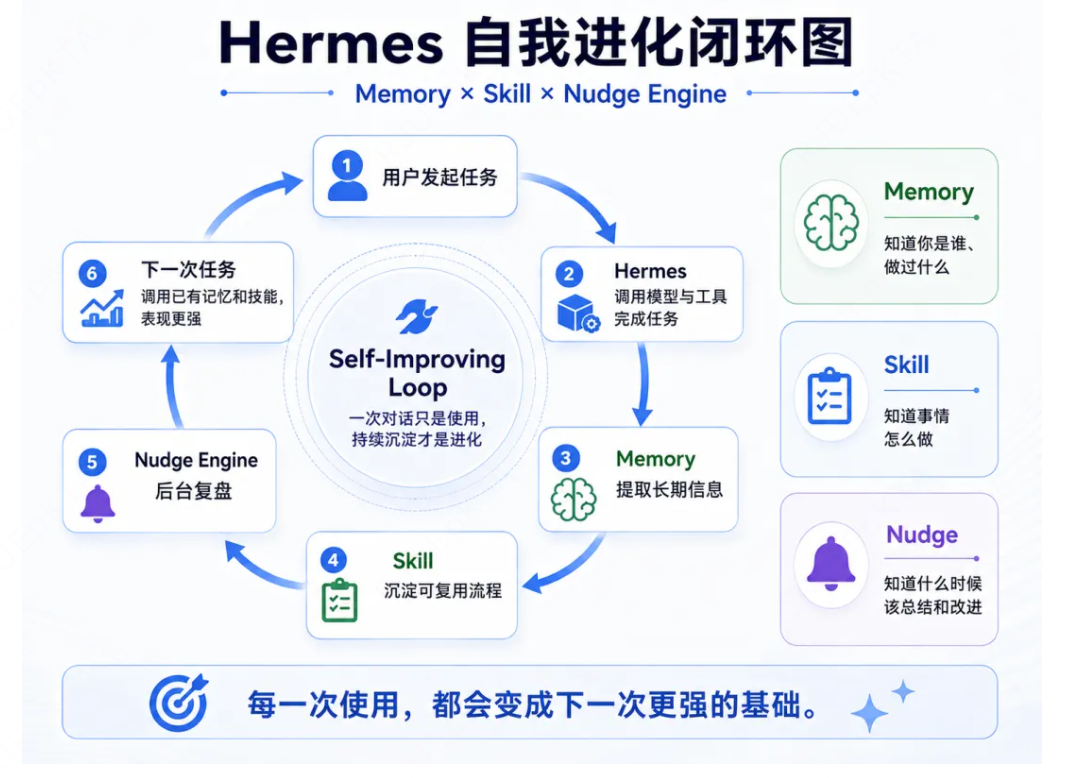
实现了一套创建技能--使用中改进--持久化知识--搜索历史会话--建立用户理解的飞轮,即:“反思--进化”。
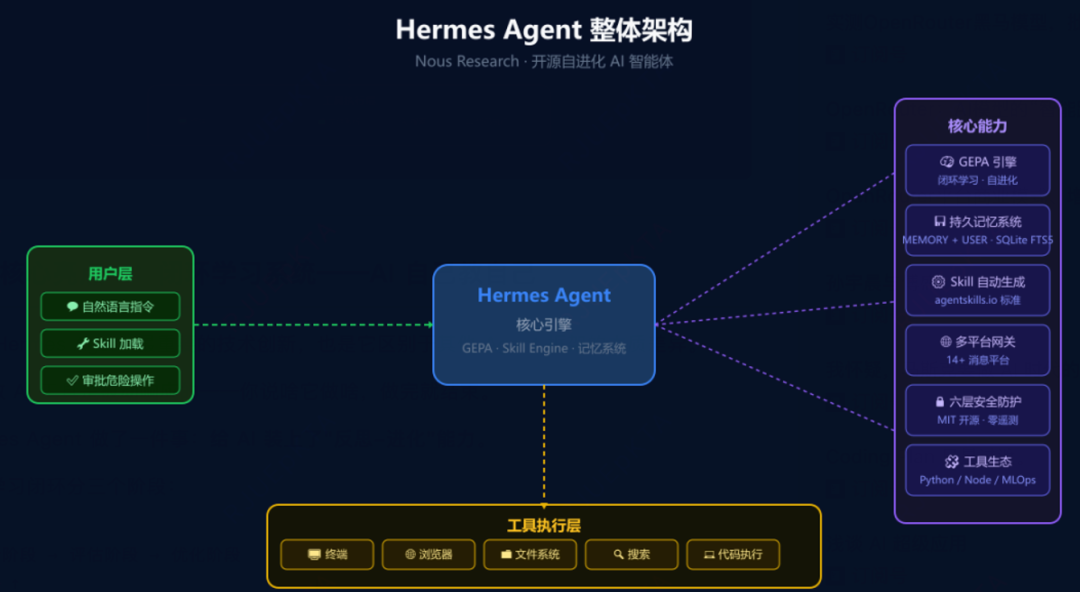

先说Hermes Agent的记忆设计。
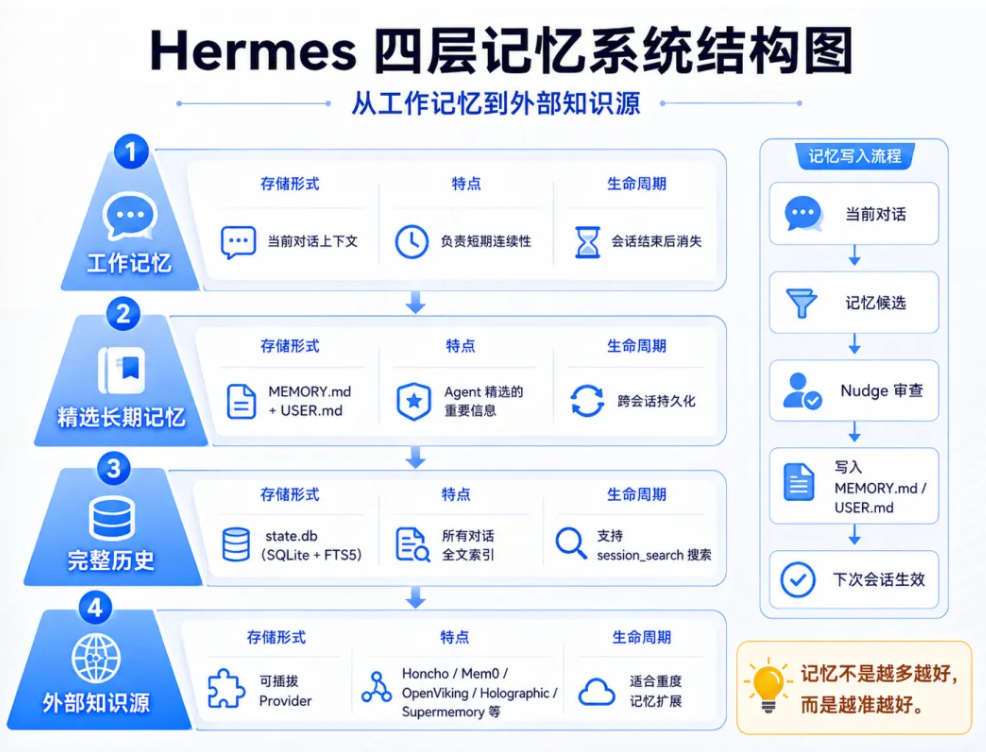
Hermes Agent记忆系统分为四层。
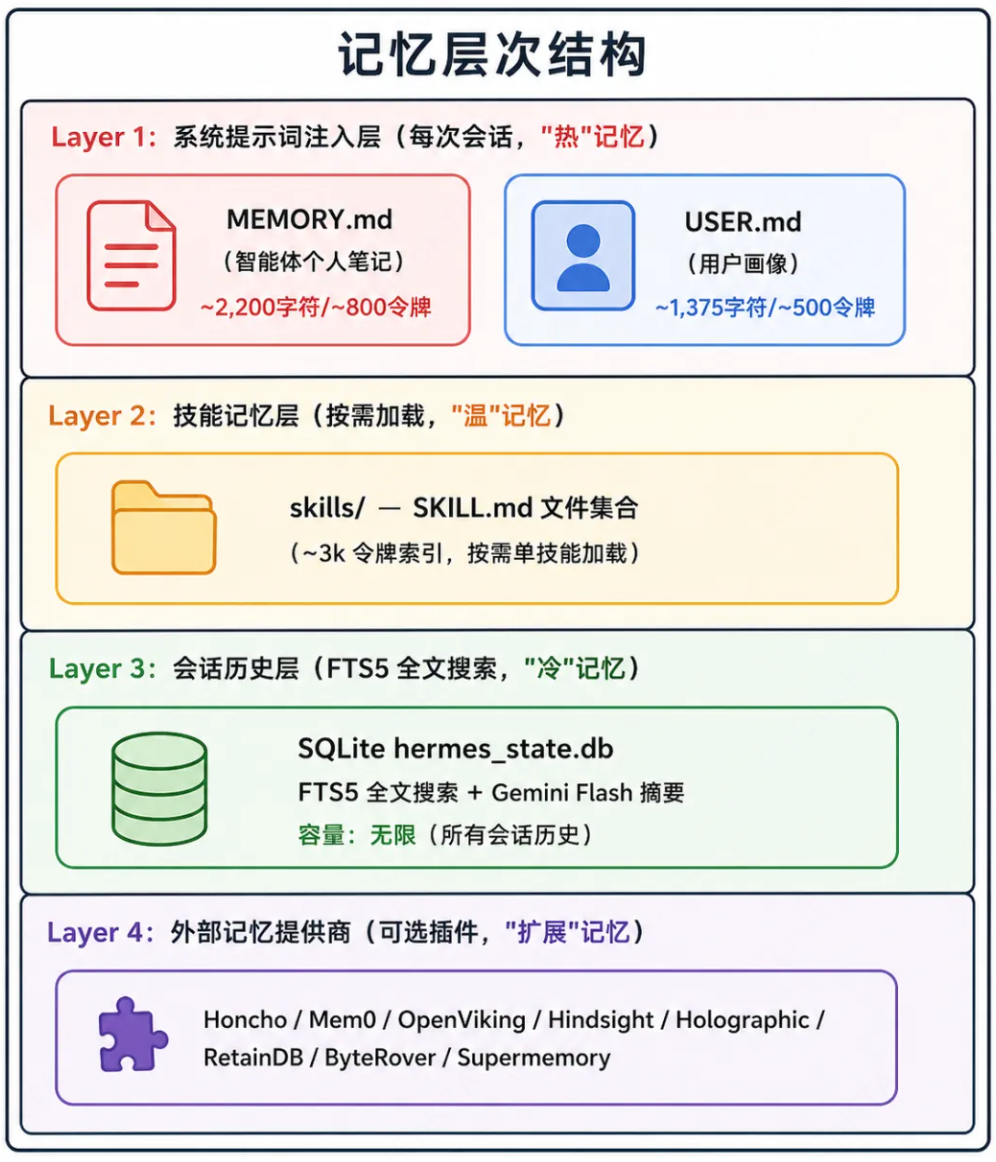
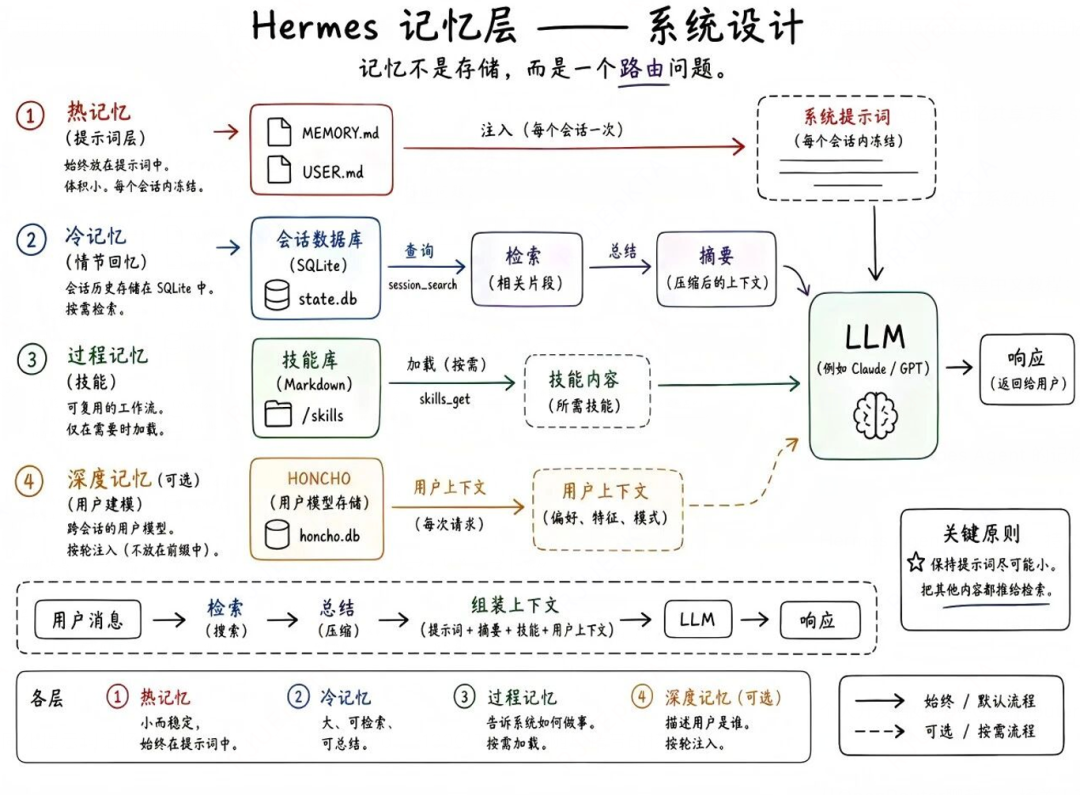
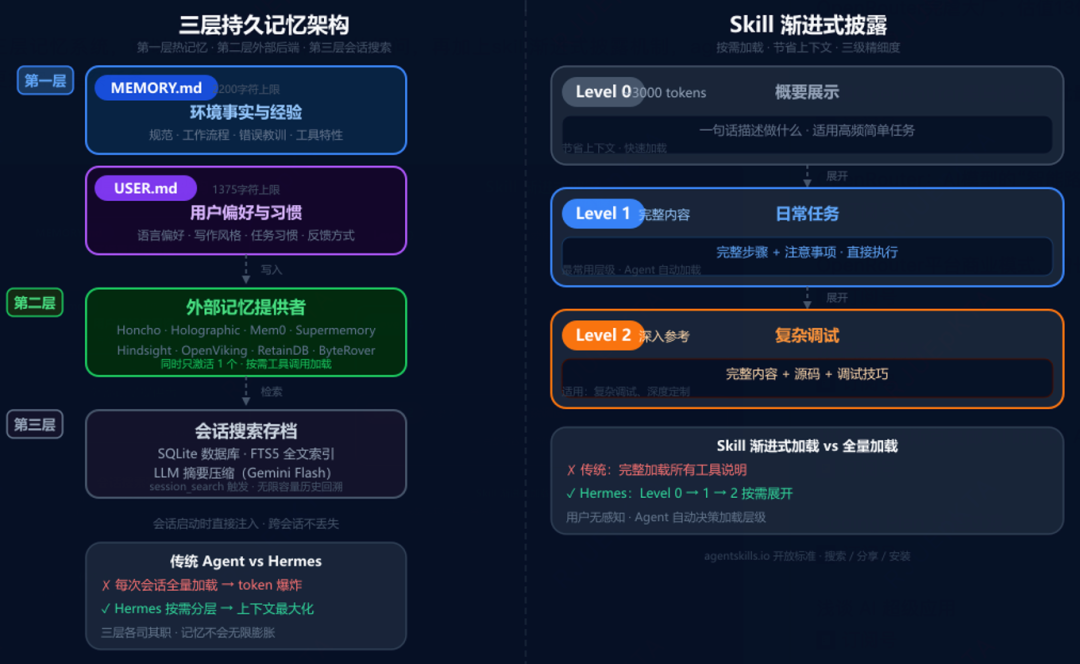
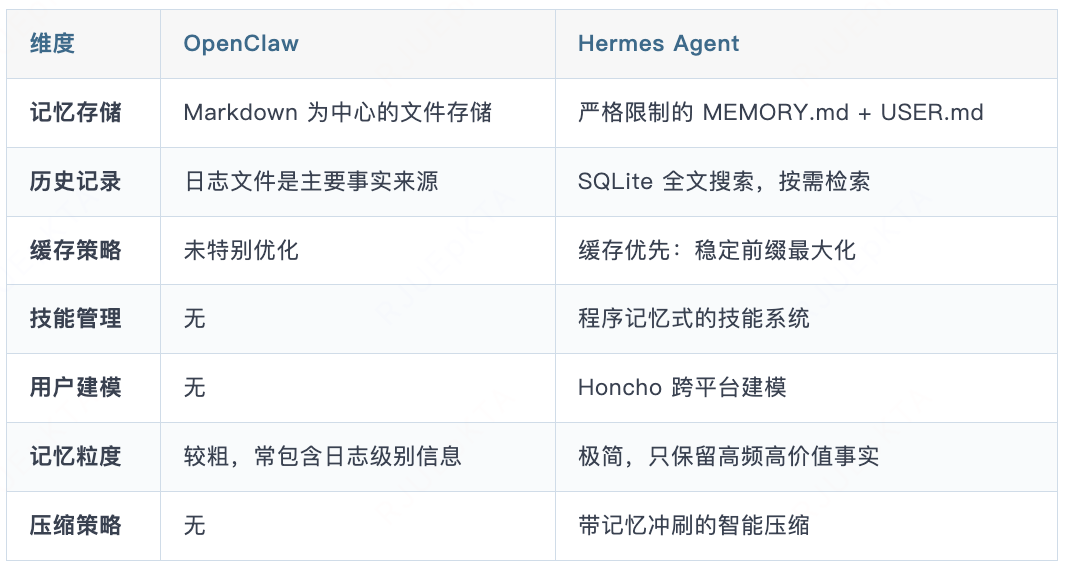
第一层:持久化记忆(memory.md、user.md)。
memory.md是agent的个人记忆,用于存储智能体所需记住的工作环境事实信息、工作流等信息。
user.md用于存储用户身份、偏好、沟通风格的信息。
这些记忆在每次会话打开时作为冻结快照注入到会话的系统提示词中,这是为了保护Prompt Cache。
冻结快照的意思是,会话一开始被捕获一次,会话中途不会改变。
System Prompt构建如下:

如果会话过长,Hermes会压缩对话以节省空间,但摘要是有损的,可能导致事实数据的丢失。
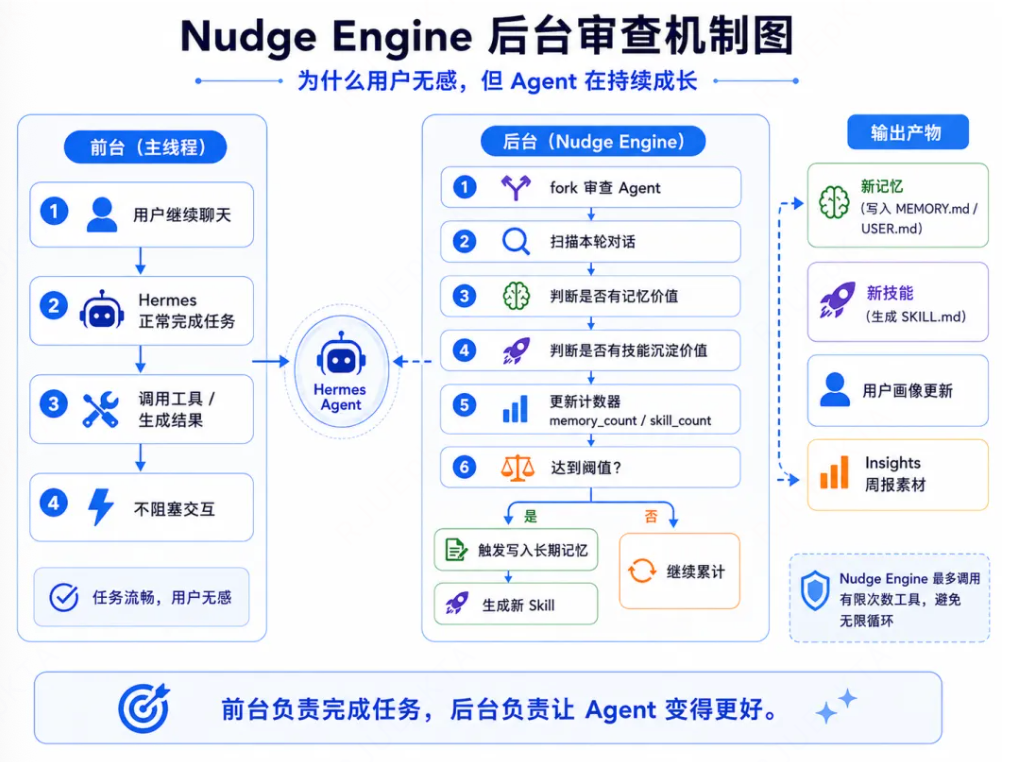
于是Hermes会先发一次记忆冲刷指令,告诉模型:会话即将压缩,请保存任何值得记住的东西,优先保存用户偏好、修正建议和重复模式,而非具体的任务细节。
这是一次额外的模型调用,模型会识别出什么东西该留下来,什么东西被洗掉,最终写入memory.md,这相当于将什么值得记住这个判断权交给了模型本身,而非硬编码的规则。
而且在记忆写入时,用了11种正则模式扫描,防止Prompt注入、角色劫持、凭证泄露等。
因为对于agent来说,记忆是核心攻击面。
第二层:技能记忆(skills)
技能是agent的过程性记忆,当agent解决复杂问题时,它会将工作流写成可复用的skill,以便持久化这部分领域技能。
第三层:SQLite数据库,会话历史层。
全量的会话历史,支持FTS5全文检索。
agent通过session_search工具搜索过去的对话,返回过去几周讨论的相关内容和相关的对话,配合gemini flash摘要。
第四层:扩展记忆。
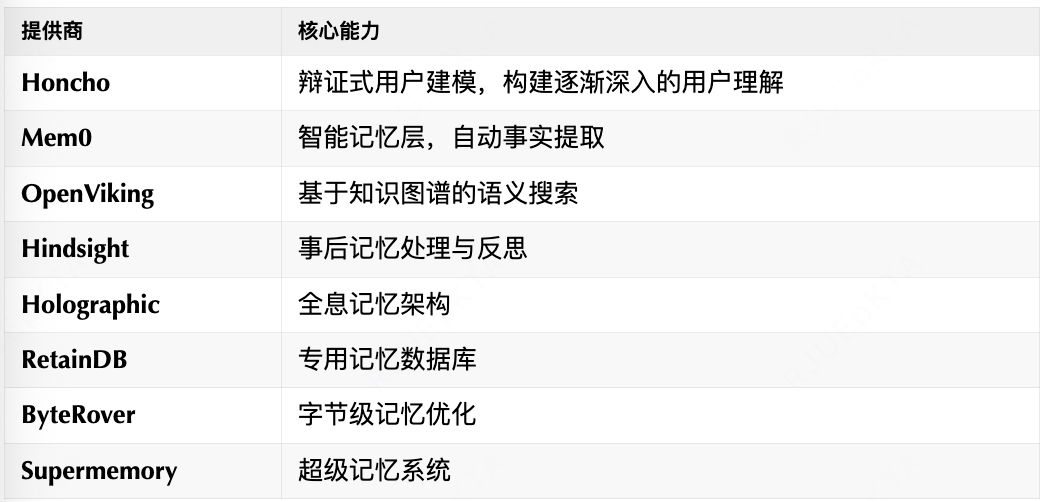
通过可拔插方式,引入外部记忆插件,比如知识图谱、语义搜索、自动事实提取和跨会话的用户建模等。
再说Hermes Agent的技能设计。
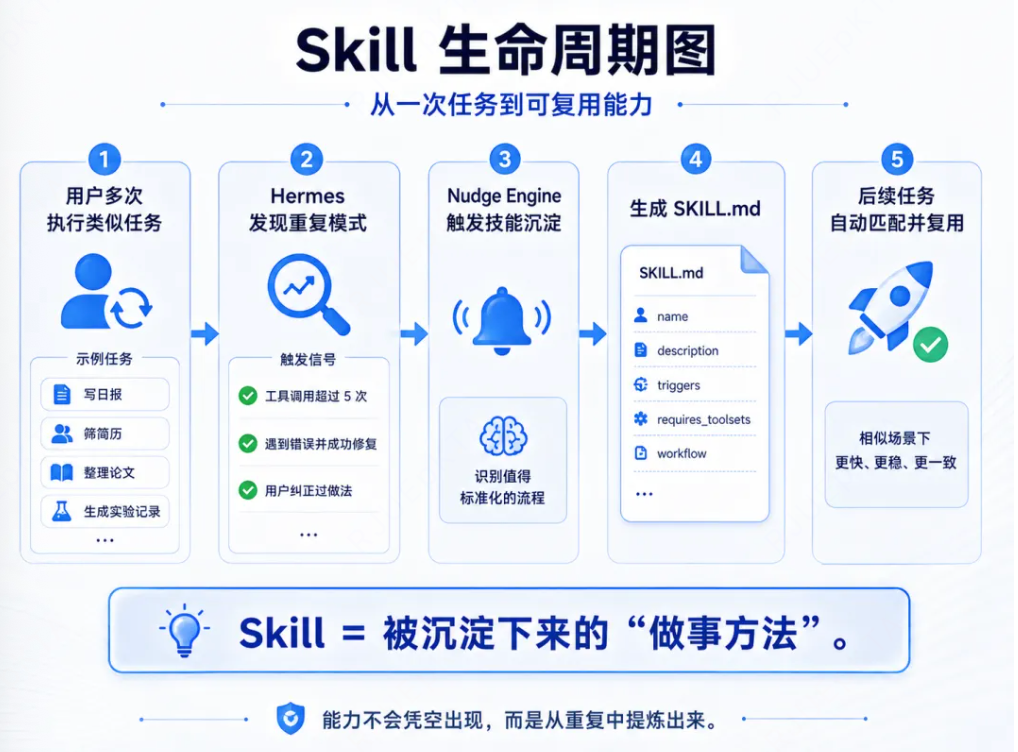
agent会将解决完复杂问题之后的知识,沉淀为技能实现从经验中学习。
skill是按需加载的md文档,遵循渐进式披露,以最小化token使用,agent只有真正需要某个skill时,才会加载完整技能内容。

Agent通过skill_manage工具自主创建、更新和删除技能。
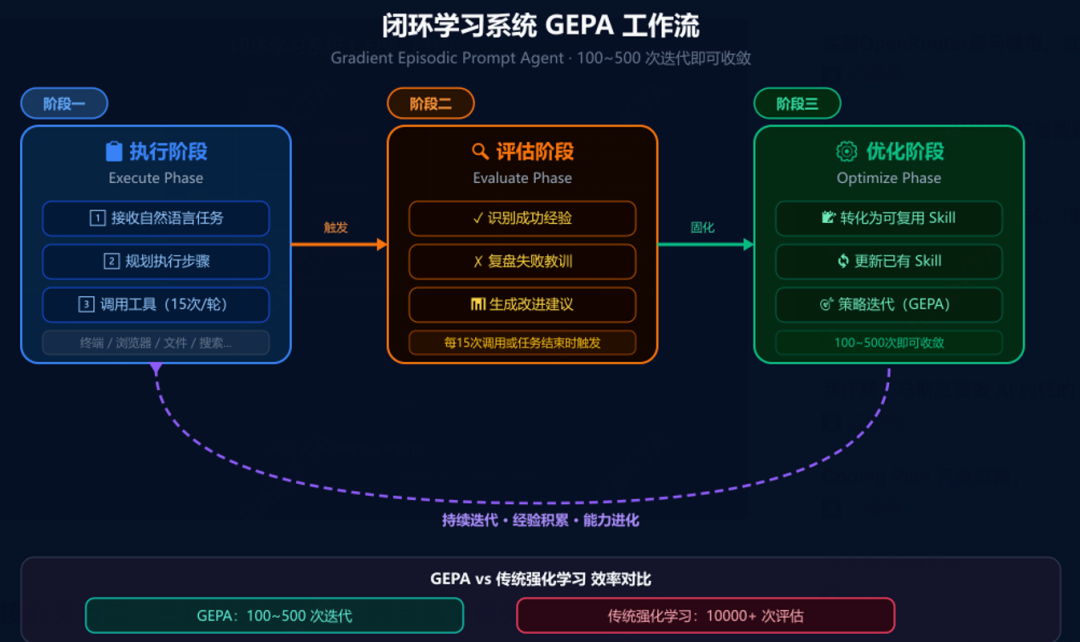
Hermes是一套自学习的Agent,在完成一个任务后,会自我评估,将有效的解题思路封装为一个skill.md文档,存入~/.hermes/skills/目录下。
每完成约15个任务,Hermes会自动回顾已有的skill进行自我评估和复盘,更新skill或者淘汰过时的skill,整个过程自动化,无需任何操作。
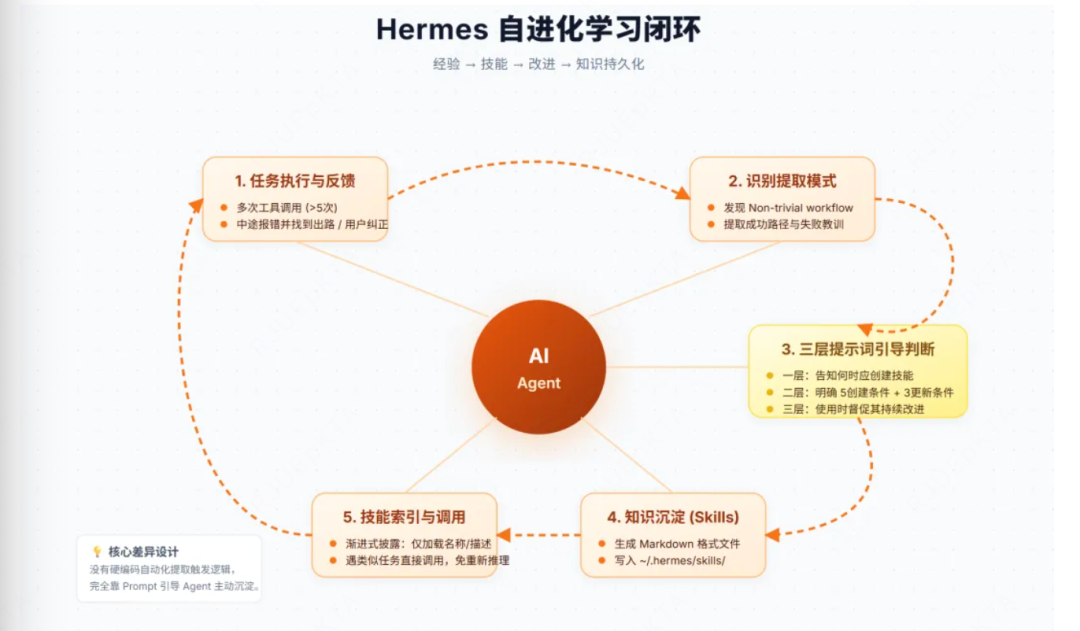
所以,对于Hermes来说,持续进化来源于记忆+技能+后台审视的持续进化loop(self-improving loop):
用户下发复杂任务--Agent推理执行,调用工具链完成任务--执行完成后,自动分析解决过程--提取为客服用的技能markdown文件--下次遇到类似任务,直接调用已有技能--使用过程持续改进今年,查漏补缺。
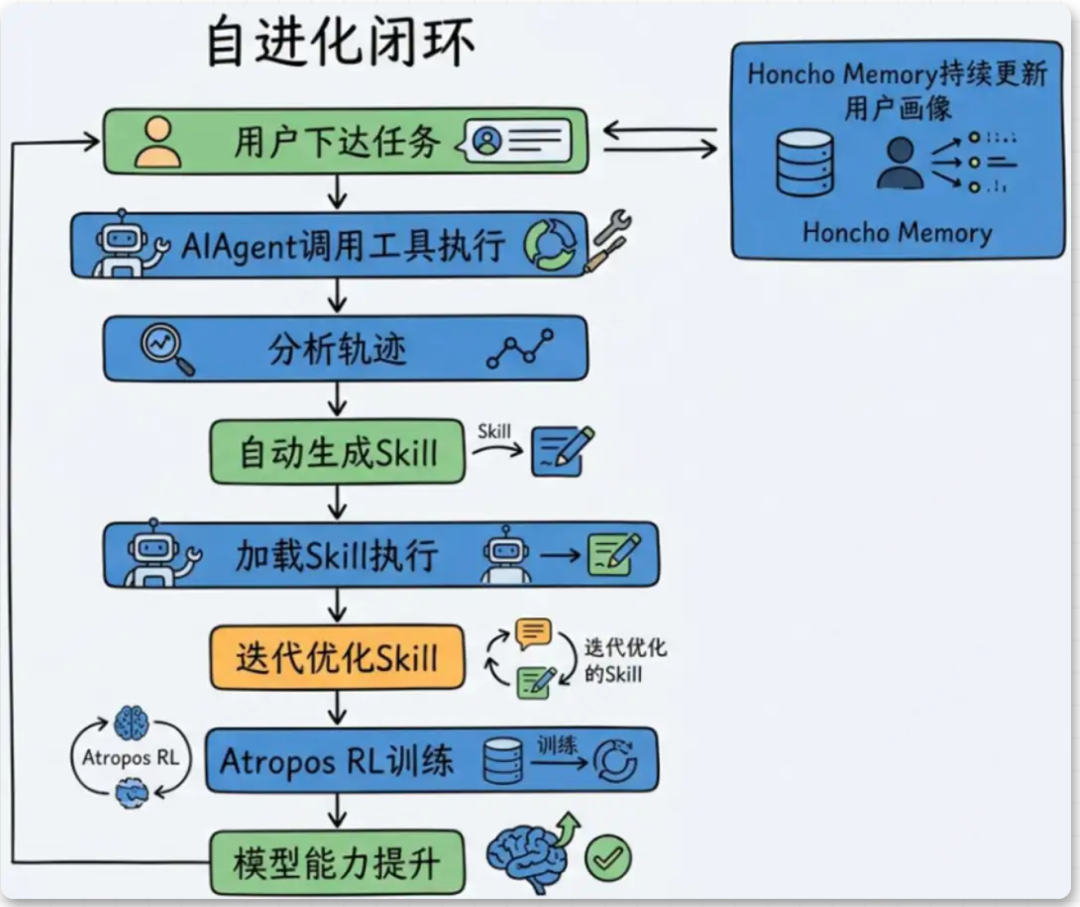
对于OpenClaw,Hermes的记忆设计存在一些不同。
Openclaw的记忆哲学是:全量记录。
以markdown文件为核心存储形式,日志和长文件是记忆主体,偏向于流水账式的全量记录,理念上是记得越多越好、越详细越好。
Hermes的记忆哲学是:精选+分层。
严格限制提示词的记忆容量,历史全量记忆存入SQLite,仅通过全文检索实现按需检索。一切设计服务于提示词缓存效率,实现了分层记忆。
我更倾向于Hermes这种记忆设计的方案,可控性和效率更高。但如果哪一天我们的agent变成了一个人形机器人,可能Openclaw这种全文记忆更合适一些,因为这样它会更了解你。
就像我之前一直说的那样,做好一个agent关键在于做好记忆。
从大火的Openclaw和Hermes来看,记忆如何设计和实现,基本上有了较为清晰的路径,后续的记忆实现大体应该差不多了。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号