Hermes Agent 的记忆系统:为什么它修正了 OpenClaw 的错误

Hermes Agent 的记忆系统:为什么它修正了 OpenClaw 的错误

山行AI
发布于 2026-05-13 12:25:02
发布于 2026-05-13 12:25:02
Hermes Agent 的记忆系统:为什么它修正了 OpenClaw 的错误
原文:Manthan Gupta(@manthanguptaa)
中文对比图
如果你读过我之前关于 ChatGPT memory、Claude memory 和 OpenClaw memory 的文章,你大概已经知道,我一直在追问同一个问题:这些 agent 到底是怎么“记住”的?
Hermes Agent 之所以特别有意思,是因为这一次,我不需要只靠行为去逆向推理。Hermes 是开源的,仓库和文档都公开。所以我不必拿 prompt 去试探一个黑箱,而是直接查看那些负责构建 prompt 状态、持久化会话、刷新记忆、查询历史对话的代码路径。
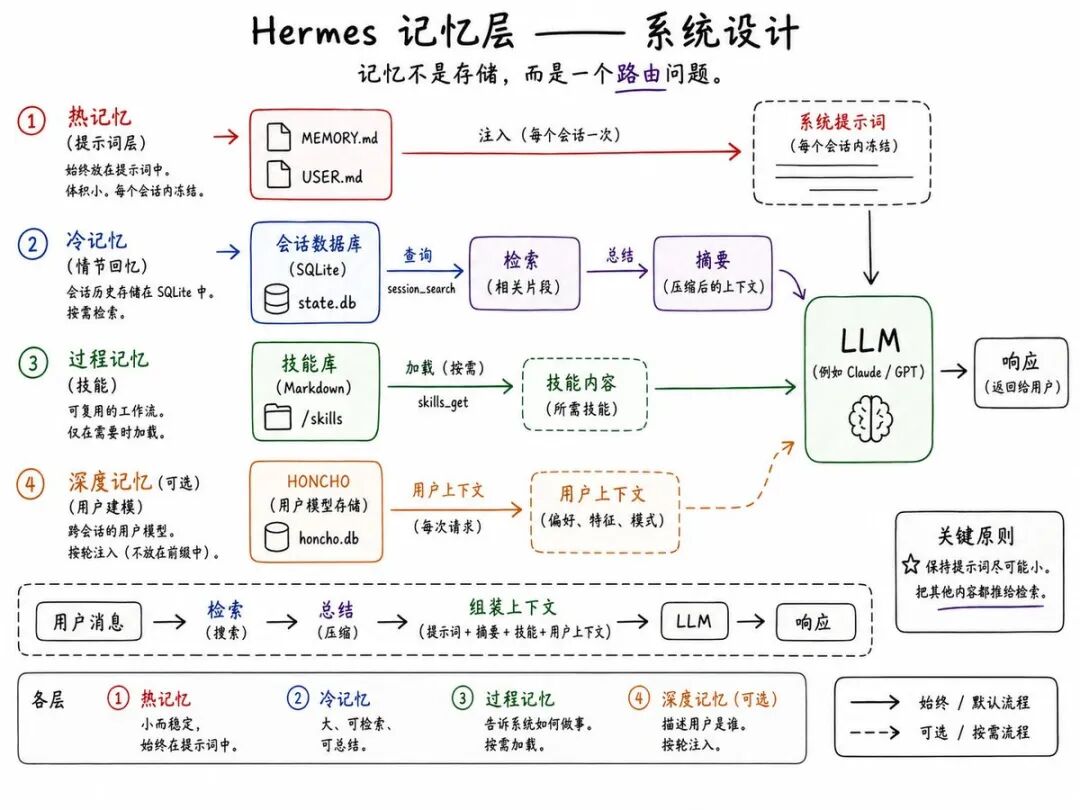
简短来说:Hermes 不是只有一个记忆系统,它有四个。
- 一个非常小、经过筛选的 prompt 记忆,存放在
MEMORY.md和USER.md - 一个可搜索的 SQLite 历史会话归档,通过
session_search暴露 - 由 agent 管理的 skills,充当程序性记忆
- 一个可选的 Honcho 层,用于更深层的用户建模
把它们串起来的关键设计很简单:保持 prompt 稳定以便缓存,把其他一切交给工具。
让我们直接开始。
Hermes 的上下文结构
在理解记忆之前,先理解 Hermes 到底把什么发给模型。
系统 prompt 大致会这样组装:
[0] 默认 agent identity
[1] 面向工具的行为指导
[2] Honcho 集成块(可选)
[3] 可选 system message
[4] 冻结的 MEMORY.md 快照
[5] 冻结的 USER.md 快照
[6] skills 索引
[7] 上下文文件(AGENTS.md、SOUL.md、.cursorrules、.cursor/rules/*.mdc)
[8] 日期/时间 + 平台提示
[9] 对话历史
[10] 当前用户消息
这件事很重要,因为 Hermes 在优化 provider 侧的 prompt caching。源码里对此说得很明确:稳定的前缀要尽可能保持稳定。
这一个决定,几乎解释了 Hermes 记忆架构的大部分设计。
如果某条信息应该每轮都可用,Hermes 会尽量把它压得很小,只注入一次。若信息很大、很历史化,或者只有偶尔才有用,Hermes 就把它移出 prompt,改为按需检索。
第一层:冻结的 prompt 记忆
内置记忆系统其实小得惊人。
Hermes 把持久化记忆存放在 ~/.hermes/memories/ 下的两个文件里:
文件 | 作用 | 限制 |
|---|---|---|
MEMORY.md | 关于环境、约定、工具习惯、经验教训的 agent 笔记 | 2,200 字符 |
USER.md | 用户画像:偏好、沟通风格、身份信息 | 1,375 字符 |
这并不多,加起来大约 1,300 tokens。
而且这是刻意设计的。
在会话开始时,Hermes 会加载这两个文件,把它们渲染成一个 prompt 区块,然后在整个会话里冻结这份快照。会话中途对文件的写入会立即落盘,但不会改变已经构建好的 system prompt。只有新会话开始,或者在压缩触发 prompt 重建之后,这些变化才会进入 prompt。
渲染出来的格式大致如下:
MEMORY(你的个人笔记)[67% — 1,474/2,200 字符]
§
User's project is a Rust web service at ~/code/myapi using Axum + SQLx
§
This machine runs Ubuntu 22.04, has Docker and Podman installed
§
User prefers concise responses, dislikes verbose explanations
我喜欢这里的几个设计细节:
- 它用字符限制,而不是 token 限制 这样 memory 逻辑就和具体模型无关了。Hermes 不需要为了判断是否写满记忆,而去依赖某个模型的 tokenizer。
- 它使用非常简单的分隔文本格式 条目之间用
§分隔。没有向量数据库,没有自定义二进制存储,只有纯文本文件。 - 它故意把系统 prompt 记忆保持得很小 这大概是整个设计里最关键的一点。Hermes 并不想把整个历史都塞进 prompt memory,它只想把最高价值的信息放进去。
- 它把记忆当作经过筛选的状态,而不是日记 这也是 Hermes 和 OpenClaw 很不同的地方。 OpenClaw 的每日日志更像是追加式的。Hermes 则明确朝相反方向走。 工具 schema 和测试都说得很清楚:
- 保存用户偏好
- 保存环境事实
- 保存反复出现的纠正
- 保存稳定约定
- 不保存任务进度
- 不保存会话结果
- 不保存临时 TODO 状态
说白了,Hermes 想让 MEMORY.md 和 USER.md 保持热、保持小、保持缓存友好。
memory 工具
Hermes 通过一个 memory 工具来管理这些文件,只有三个动作:
addreplaceremove
当前工具表面上没有真正的 read 动作,因为记忆在会话开始时已经注入到 prompt 里了。
另一个很贴心的细节是,replace 和 remove 用的是子串匹配。你不需要内部 ID,只需要传一个能唯一定位原内容的子串即可。
例如:
memory(
action="replace",
target="memory",
old_text="dark mode",
content="User prefers light mode in VS Code, dark mode in terminal"
)
系统还会拒绝完全重复的内容,并在进入 prompt memory 之前拦截危险内容。源码会扫描记忆条目中的 prompt injection 模式、凭证外泄字符串、SSH 后门暗示和不可见 Unicode 字符。
这很合理。因为一旦写入 memory,它就等于会变成未来系统 prompt 的一部分。
第二层:session_search,用于情景回忆
如果 MEMORY.md 和 USER.md 是 Hermes 的热记忆,那么 session_search 就是它的长尾召回系统。
所有过去的会话都存放在 ~/.hermes/state.db 里,这是一个 SQLite 数据库,包含:
sessions表messages表- FTS5 全文搜索索引
- 通过
parent_session_id建立的链路关系
当模型需要回忆之前对话时,Hermes 不会去搜 MEMORY.md,而是去搜会话数据库。
流程大致如下:
FTS5 搜索历史消息 → 按 session 分组 → 解析 parent/child lineage → 载入最匹配的 sessions → 截断与相关匹配附近的 transcript → 用便宜的辅助模型总结每个 session → 把聚焦后的 recap 返回给主模型
这和那种试图把每一条记忆笔记都做语义索引的系统,是完全不同的思路。
Hermes 的意思基本是:
- 让始终注入的记忆保持小
- 把真正的历史存进 SQLite
- 只有需要时才搜索
- 搜索结果先总结,再交回主模型
这是很务实的设计。 它也比把长历史硬塞进每次 prompt 里更省钱。
文档里把 session_search 描述成这样几类问题的答案:
- “我们上周讨论过这个吗?”
- “我们之前对 X 做了什么?”
- “正如我之前提到的……”
换句话说,MEMORY.md 用来存持久事实,而 session_search 用来做情景回忆。
第三层:压缩与 memory flush
Hermes 另一个很聪明的地方,是它在压缩长对话之前会做什么。
随着会话变长,Hermes 最终会把中间部分摘要掉,以维持在模型上下文窗口内。但摘要是有损的,重要事实可能会丢失。
所以 Hermes 会先做一次 memory flush。
在压缩前,它会注入一条合成的系统/用户指令,大意是:
- 会话正在被压缩
- 把值得记住的东西保存下来
- 优先保存用户偏好、纠正和反复出现的模式,而不是任务特定细节
然后它只允许调用 memory 工具,再跑一次模型调用。 如果模型判断某些信息应该跨越压缩期存活下来,就会把它们写入 MEMORY.md 或 USER.md,再让对话内容被摘要掉。
这真的是一个很好的模式。 它给了模型最后一次机会,在中间对话被折叠前,把真正耐久的部分提炼出来。
更好的是,压缩之后 Hermes 会让缓存的 system prompt 失效并重建,从磁盘重新加载记忆。这样,刚刚 flush 进去的内容就会进入下一轮稳定的 prompt 快照。
所以整个流程是:
长对话 → 把耐久事实 flush 到 memory → 压缩旧轮次 → 重建 prompt → 用更小的上下文和更新后的记忆继续
这让 Hermes 真正像一个记忆架构,而不是一个外挂笔记本。
第四层:Skills 作为程序性记忆
Hermes 的记忆故事不只是事实和 transcript。 它还有 skills。
Skills 存在于 ~/.hermes/skills/ 下,扮演可复用知识文档的角色。文档明确把它们描述为 agent 的程序性记忆。
当 Hermes 发现一个非平凡工作流、修复过一个棘手问题,或者学到一种更好的做法时,它可以把这套方法保存成 skill,以后复用。
这很重要。 大多数记忆系统只关注语义召回:名字、偏好、事实和摘要。但 agent 还需要记住“怎么做”,而不只是“发生了什么”。
Hermes 通过把程序性知识和 prompt memory 分开,解决了这个问题:
MEMORY.md/USER.md:紧凑、持久的事实session_search:情景回忆skills:可复用工作流
这里还有一个很不错的 token 效率技巧:Hermes 不会把每个 skill 都硬塞进 prompt,而只是注入一个紧凑的 skills 索引,需要时再加载完整内容。
这样程序性记忆就能随时可用,但不会每轮都付出完整 token 成本。
第五层:Honcho,更深的用户建模
还有一个可选层:Honcho。
如果本地记忆是 Hermes 的精选笔记本,那么 Honcho 就是它尝试构建更丰富用户模型的方式。
Honcho 默认以 hybrid 模式和内置记忆系统一起运行,它提供:
- 跨会话的用户建模
- 跨机器、跨平台连续性
- 对用户上下文的语义搜索
- 关于用户或 AI 伙伴的辩证式 LLM 回答
有趣的是 Hermes 是怎么在不破坏 prompt caching 的情况下接入它的。
在会话的第一轮,预取的 Honcho 上下文可以被烘进缓存的 system prompt。
而在后续轮次里,Hermes 会避免修改那个稳定的 system prompt。相反,它只在当前用户轮次的 API 调用时附加 Honcho 的召回结果。这意味着:
- 稳定前缀依然稳定
- prompt caching 仍然可用
- 第 N 轮可以消费第 N-1 轮后台预取的上下文
这是一个非常聪明的折中。
Honcho 自身还会为两个对象建模:
- 用户
- AI assistant
所以 Hermes 不只是试图记住你,它还可以逐渐建立对自身的表征。 这既酷,也有点野。
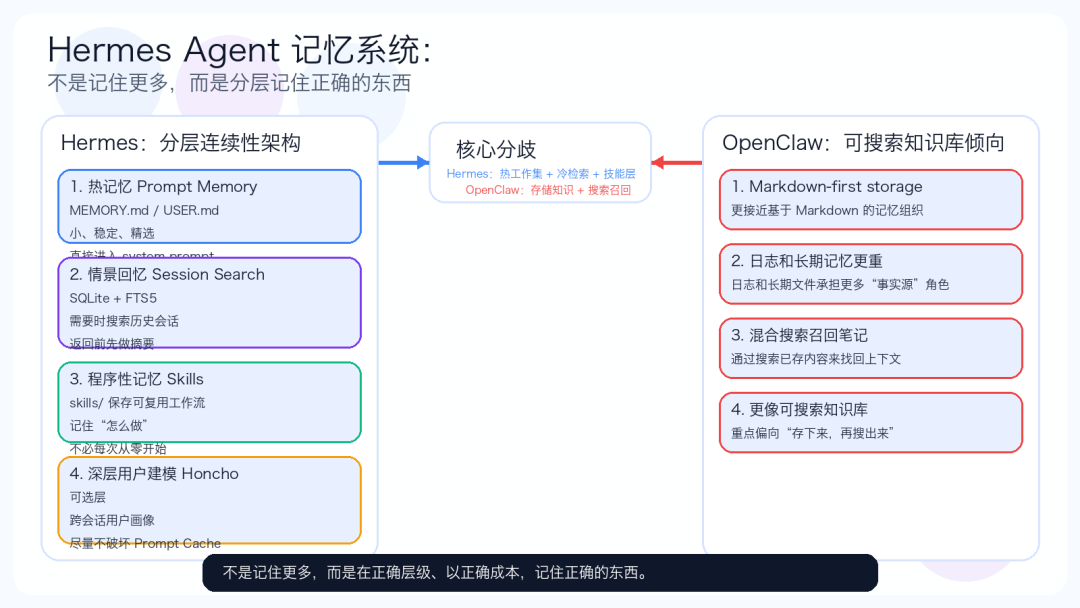
Hermes 和 OpenClaw 的差异
既然我最近写过 OpenClaw,这里的对比就值得明确说出来。
OpenClaw:
- 记忆更接近 Markdown-first 存储
- 日志和长期记忆文件更像主要事实来源
- 召回更依赖对已存笔记的混合搜索
Hermes:
- prompt memory 被严格限制
- 会话历史存放在 SQLite,而不是 prompt memory 文件里
- 过去工作通过
session_search召回 - 程序性记忆放进 skills
- 更深层的用户建模交给可选的 Honcho
关键洞察是:Hermes 比 OpenClaw 更“缓存感知”。
OpenClaw 更偏向“记忆就是可搜索的存储知识”。Hermes 则更偏向“记忆是热工作集 + 冷检索层”。
我其实觉得,这更适合生产环境里的 agent。
不是所有东西都值得活在 system prompt 里。
(图片来自宝玉的x)
Hermes 做对的三件事
看完仓库和文档后,我觉得 Hermes 做对了三件大事。
1. 它把热记忆和冷召回分开了
这是最核心的架构胜利。
小型 prompt memory 只放那些永远重要的东西;需要时才去搜索其他内容。
2. 它把 prompt 稳定性当成一等约束
很多 agent 系统谈记忆,却不谈缓存。Hermes 很明显同时在意两者。
冻结快照、延迟 prompt 更新、轮次级 Honcho 注入、压缩后的重建,这些都指向同一个设计原则:如果你想要更好的延迟和成本,就不要随便改 prompt。
3. 它承认记忆是复数
Hermes 没有假装一个存储就能解决所有问题。 它有:
- 语义型画像记忆
- 情景型会话回忆
- 通过 skills 形成的程序性记忆
- 通过 Honcho 实现的可选高阶用户建模
这才更像真实世界里 agent 需要的东西。
结论
Hermes 的记忆系统不是一个巨大的知识库,也不是一个包装得很漂亮的向量存储。它是一种分层连续性架构。
中心是一个很小的精选 prompt 记忆:MEMORY.md 和 USER.md。外面包着一个可搜索的 SQLite 历史层,用于情景回忆。再外面是一个 skills 系统,用于程序性复用。如果启用 Honcho,Hermes 还会在其上增加更深层的用户模型。
这一切背后的设计原则,最打动我的地方是:记忆应该帮助 agent 保持有用,而不是破坏 prompt 稳定性。
这才是关键。
不是记住更多,而是在正确的层级、以正确的成本,记住正确的东西。
参考
- Hermes Agent GitHub Repository
- Hermes Persistent Memory Docs
- Hermes Prompt Assembly Docs
- Hermes Session Storage Docs
- Hermes Skills Docs
- Hermes Honcho Docs
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号