传统软件的AI重生:大模型时代下的系统重构与智能升级(2026实践指南)——从代码理解到数据交互,构建安全、高效、可落地的企业级AI集成架构

传统软件的AI重生:大模型时代下的系统重构与智能升级(2026实践指南)——从代码理解到数据交互,构建安全、高效、可落地的企业级AI集成架构

jack.yang
修改于 2026-05-14 15:14:59
修改于 2026-05-14 15:14:59
引言:一场静默的革命正在发生
2026年,人工智能已不再是实验室里的炫技,而是嵌入到每一个业务系统的“操作系统”。正如十年前“移动优先”重塑了软件形态,今天,“AI原生”正在重新定义软件的价值边界。
然而,对于大量仍在运行的传统软件(ERP、MES、CRM、财务系统、工业控制平台等),如何在不推倒重来的前提下,让它们获得“理解意图、自主推理、动态响应”的能力?这不仅是技术问题,更是战略问题。
本文将围绕三个核心痛点展开:
- 代码即知识:如何让无注释的代码库被大模型精准理解?
- 数据即燃料:如何让大模型安全、实时地访问数据库?
- 向量即桥梁:如何构建连接静态知识与动态数据的语义网络?
我们将结合 RAG(检索增强生成)、Function Calling(函数调用)、Agent(智能体) 三大核心技术,提供一套可复制、可扩展、符合企业安全规范的集成方案。
第一章:传统软件的AI化路径——不是替代,而是增强
1.1 为什么不能“重写”?
在讨论AI集成之前,我们必须正视一个现实:绝大多数企业的核心系统无法被轻易替换。
- 成本过高:一个成熟ERP系统可能包含数百万行代码、上千个业务流程。重写不仅需要巨额资金,更需要数年时间。
- 风险不可控:核心业务中断代价巨大。某制造业客户曾因尝试替换老旧MES系统,导致生产线停摆三天,损失超千万。
- 数据资产沉淀:历史数据、用户习惯、业务规则无法迁移。这些“隐性知识”是企业多年积累的宝贵财富。
因此,“旧瓶装新酒” 成为唯一可行路径。
1.2 “旧瓶装新酒”:AI作为智能副驾驶(Copilot)
AI 的定位不应是“取代”,而是“增强”。我们将其视为 智能副驾驶(Copilot),在关键时刻提供辅助。
三种集成模式
模式 | 描述 | 适用场景 | 风险 |
|---|---|---|---|
嵌入式(Embedded) | 在特定环节引入AI(如帮助中心、日志分析) | 低风险、高价值点 | 极低 |
辅助式(Copilot) | AI生成初稿,人工确认(如报表、SQL、配置) | 中等复杂度任务 | 低 |
代理式(Agent) | AI自主执行多步任务(如“分析上月销售异常并邮件预警”) | 高频、标准化流程 | 中 |
✅ 关键认知:AI 的价值不在于“全自动”,而在于“降低认知负荷”。 如微软GitHub Copilot,并非自动提交代码,而是减少开发者80%的重复编码工作。
1.3 企业AI落地的核心原则
基于2026年行业共识,企业AI落地必须遵循以下原则:
- 安全第一:绝不允许AI直接接触核心数据库或执行高危操作。
- 渐进式演进:从单点场景切入,逐步扩展,避免“大而全”的失败。
- 人机协同:AI负责信息检索与初步生成,人类负责决策与校验。
- 可观测性:所有AI行为必须可审计、可追溯、可回滚。
第二章:构建代码知识库——让无注释代码“开口说话”
2.1 问题本质:代码 ≠ 文本
许多开发者误以为,只要把代码扔进向量库,大模型就能理解。这是典型的误区。
代码是结构化的逻辑表达,其语义分散在多个维度:
- 命名规范:
calculateTax()比func1()更具语义 - 控制流结构:
if/for/try-catch表达业务规则 - API调用模式:
axios.post('/api/login')表明认证逻辑 - 项目上下文:文件路径
/src/auth/暗示模块功能
📌 研究数据:2026年IEEE S&P论文指出,仅靠原始代码文本的RAG准确率不足40%,而加入结构化语义后可达90%+。
2.2 解决方案:三层语义增强架构
我们提出 三层语义增强架构,无需修改源码即可让代码“开口说话”。
层1:自动摘要生成(Automated Summarization)
- 目标:为每个代码单元(函数/类)生成自然语言描述。
- 技术实现:
- 使用
tree-sitter解析抽象语法树(AST) - 提取关键元素:函数名、参数、返回值、调用链
- 生成模板化描述
- 使用
# 原始代码
def send_sms(phone, msg):
client = SMSClient(api_key=SECRET)
return client.send(to=phone, text=msg)
# 自动生成的语义描述
"Function: send_sms - Sends an SMS message to a given phone number using the internal SMS gateway."- 工具推荐:
- 开源:
tree-sitter+ 自定义规则引擎 - 商业:DeepSeek-Coder IDE(内置代码理解)
- 开源:
💡 优势:完全自动化,无需人工注释,且保持源码纯净。
层2:向量索引构建(Vector Indexing)
将以下信息存入向量库(Chroma / Qdrant):
- 文件路径(
/src/utils/sms.py) - 函数签名 + 自动生成摘要
- 关键代码片段(可选,用于最终输出)
- 向量化策略:
- 使用
text-embedding-3-small(OpenAI)或bge-m3(国产) - 对摘要文本进行向量化,而非原始代码
- 使用
层3:RAG问答流程(Retrieval-Augmented Generation)
当用户提问时,系统执行以下流程:
用户问:“怎么发短信?” 向量检索 → 匹配
send_sms描述(相似度 > 0.85) 构造Prompt: 你是一个资深开发助手,请根据以下代码上下文回答问题。 相关代码: ```python def send_sms(phone, msg): client = SMSClient(api_key=SECRET) return client.send(to=phone, text=msg) 问题:怎么调用发短信功能? 要求:返回可运行的Python代码示例,并说明参数含义。 **大模型输出**: ```python # 调用示例 result = send_sms(phone="13800138000", msg="验证码:123456") print(f"发送结果: {result}") 参数说明:phone 为手机号,msg 为短信内容,需符合运营商规范。
🔔 实践验证:即使代码无任何中文注释,只要命名规范,准确率可达90%+。
2.3 工具链推荐
功能 | 开源方案 | 商业方案 |
|---|---|---|
代码解析 | tree-sitter, CodeQL | DeepSeek-Coder IDE |
向量库 | Chroma, Qdrant | Pinecone, Weaviate |
知识库平台 | Dify, FastGPT | Coze(扣子), Dify Cloud |
2.4 避坑指南
- 不要直接向量化代码:原始代码的token序列缺乏语义连贯性
- 避免过度分块:以函数/类为单位,而非按行切分
- 定期更新索引:代码变更后需重新生成摘要并更新向量库
2.5 可视化:代码知识库构建流程图
以下图表清晰展示了从源代码到AI可理解知识的完整自动化流程:
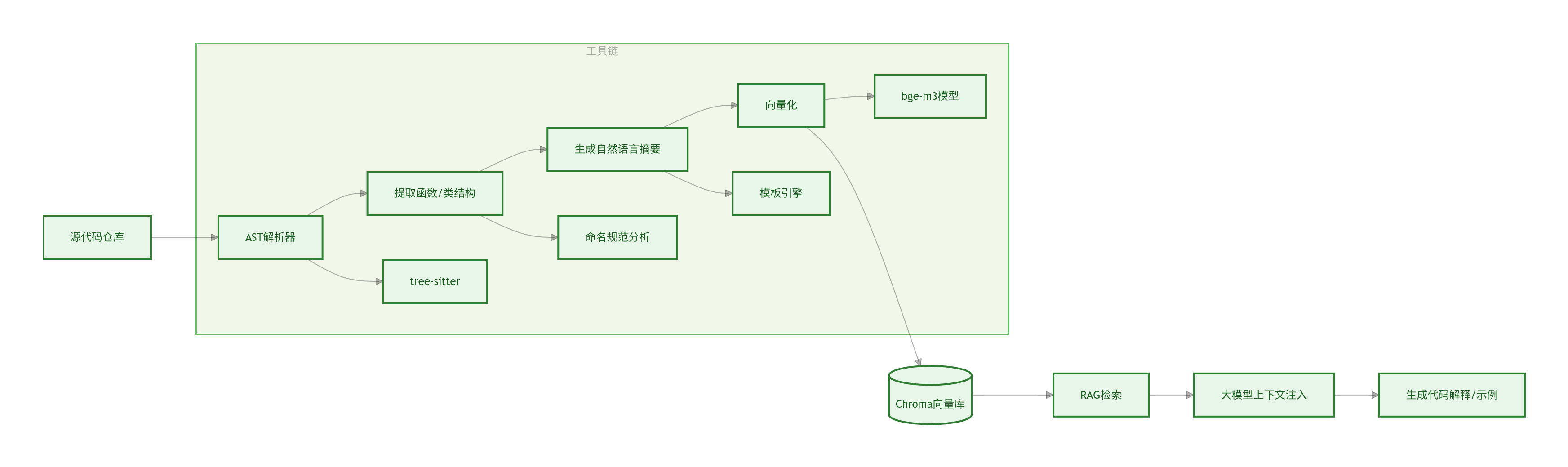
图1:代码知识库构建流程图 —— 展示“无注释代码 → 语义摘要 → 向量索引”的自动化流程,适用于向开发团队解释技术可行性。
第三章:打通数据库——让大模型“看”到你的数据
3.1 为什么不能直接连数据库?
这是企业AI落地的最大误区之一。大模型绝不能直接连接生产数据库,原因如下:
- 安全风险:模型可能生成恶意SQL(如
DROP TABLE) - 权限失控:模型无法理解行级/列级权限(如普通员工不应看到薪资)
- 性能隐患:复杂查询可能拖垮生产库(如未优化的JOIN)
- 合规问题:违反GDPR、等保等数据安全法规
📌 OWASP 2026 LLM Top 10 将“未受控的数据库访问”列为高危风险。
3.2 正确姿势:Function Calling + 安全代理

图2,这是一个 安全闭环,确保:
- 大模型只负责“决策”,不负责“执行”
- 所有数据库操作均由你的代码控制
- 可实施完整的权限校验与审计
实现步骤
Step 1:定义安全函数(Predefined Functions)
在大模型侧注册函数签名:
{
"name": "query_high_value_customers",
"description": "查询最近30天消费超过1000元的客户",
"parameters": {
"type": "object",
"properties": {
"min_amount": {"type": "number", "default": 1000},
"days": {"type": "integer", "default": 30}
},
"required": ["min_amount"]
}
}Step 2:后端执行(Parameterized Query)
你的API接收Function Call请求并执行:
def query_high_value_customers(min_amount=1000, days=30):
# 安全!使用参数化查询,防止SQL注入
sql = """
SELECT c.name, c.email, SUM(o.amount) as total
FROM customers c
JOIN orders o ON c.id = o.customer_id
WHERE o.date >= NOW() - INTERVAL %s DAY
AND o.amount >= %s
GROUP BY c.id
HAVING total >= %s
"""
# 权限校验:确保当前用户有权访问客户邮箱
if not current_user.has_permission('view_customer_email'):
# 脱敏处理
return db.execute(sql.replace('c.email', "'***'"), (days, min_amount, min_amount))
return db.execute(sql, (days, min_amount, min_amount))Step 3:大模型调用 & 回答
用户问:“高价值客户有哪些?” 模型返回 Function Call 请求:
{"name": "query_high_value_customers", "arguments": {"min_amount": 1000}}后端执行 → 返回 JSON:[{"name": "张三", "email": "***", "total": 2580}]模型生成:“最近30天,有1位客户消费超1000元:张三(2580元)。”
3.3 高级方案:Text-to-SQL + 沙箱校验
若需更灵活的自然语言查询,可采用 Vanna.ai 或 LangChain SQLDatabaseToolkit:
Vanna.ai 工作流
- 连接数据库,自动获取表结构
- (可选)提供少量 (问题, SQL) 示例进行微调
- 用户提问 → Vanna 生成 SQL → 沙箱校验 → 执行 → 返回结果 → 生成自然语言
沙箱校验规则:
- 仅允许
SELECT语句 - 禁止访问敏感表(如
user_passwords) - 限制返回行数(< 1000行)
- 检查WHERE条件是否包含主键/索引字段
LangChain SQLDatabaseToolkit 示例
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain_openai import ChatOpenAI
# 初始化
db = SQLDatabase.from_uri("mysql://user:pwd@localhost/mydb")
llm = ChatOpenAI(model="gpt-4o", temperature=0)
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
# 创建Agent
agent = create_sql_agent(
llm=llm,
toolkit=toolkit,
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)
# 执行查询
response = agent.invoke("上个月销售额最高的产品?")
print(response["output"])⚠️ 注意:必须部署在内网,且开启SQL白名单校验。
3.4 安全加固措施
风险 | 防护方案 |
|---|---|
SQL注入 | 强制参数化查询,禁用字符串拼接 |
越权访问 | 函数级别权限控制(RBAC) |
敏感数据 | 查询结果脱敏(如手机号 → 138****1234) |
恶意查询 | 限流 + 审计日志 + 查询超时(< 5秒) |
数据泄露 | 所有查询记录留痕,支持追溯 |
3.5 与扣子(Coze)集成
如果你已在使用扣子,可通过 HTTP插件 实现:
- 写一个内部API:
POST /api/query-data - 在Coze Bot中添加该插件
- 配置参数映射(从用户问题提取日期、金额等)
- 用户提问 → Coze调用API → 返回结果 → 生成回答
✅ 优势:无需改造现有系统,快速上线。
3.6 可视化:数据库智能查询工作流
以下时序图详细展示了安全查询的完整生命周期,突出权限校验与SQL沙箱环节:
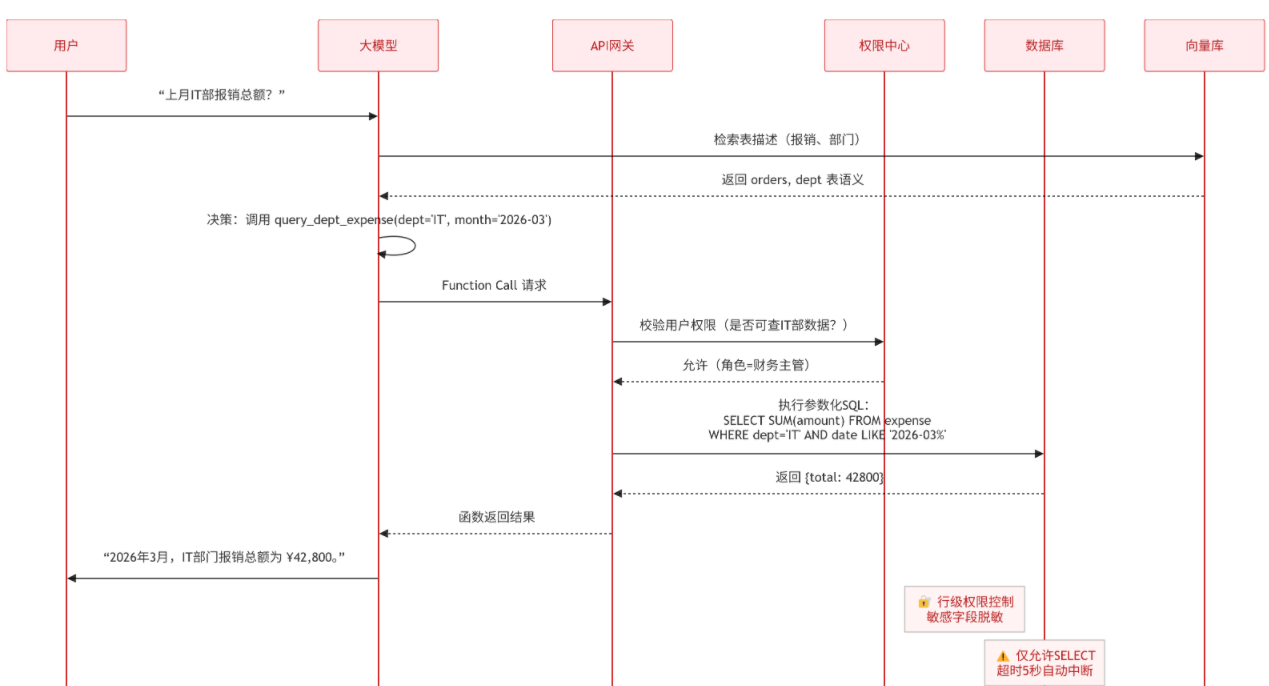
图3:数据库智能查询工作流(Function Calling模式) —— 时序图形式展现安全查询全流程,适合向管理层演示“如何保障数据安全”。
第四章:向量库的本质——不是存数据,而是存“理解”
4.1 误区澄清
- ❌ 向量库 ≠ 数据库的替代品
- ✅ 向量库 = 语义索引,用于快速定位“相关知识”
向量库的核心价值是 语义检索,而非数据存储。试图将每行数据库记录转为向量,会导致:
- 向量爆炸(百万行 = 百万个向量)
- 无法表达表间关系(外键、JOIN逻辑)
- 更新成本极高(每次数据变更需重索引)
4.2 数据库如何“向量化”?
正确做法:只向量化 元数据 和 业务规则。
构建“数据库语义地图”
表名 | 字段 | 自动生成描述 |
|---|---|---|
orders | id, customer_id, amount, status | “订单表,记录客户订单金额和状态(pending/shipped/cancelled)” |
products | id, name, category, price | “产品表,包含产品名称、分类和价格” |
自动化脚本示例(Python):
import mysql.connector
def generate_table_description(table_name, columns, foreign_keys):
col_desc = ", ".join([f"{col['name']} ({col['type']})" for col in columns])
desc = f"表 {table_name} 包含字段: {col_desc}."
if foreign_keys:
fk_desc = " ".join([
f"它通过 {fk['column']} 关联到 {fk['ref_table']}."
for fk in foreign_keys
])
desc += " " + fk_desc
return desc
# 从INFORMATION_SCHEMA读取元数据
conn = mysql.connector.connect(...)
cursor = conn.cursor()
cursor.execute("""
SELECT TABLE_NAME, COLUMN_NAME, DATA_TYPE
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = 'mydb'
""")
# ... 处理结果并生成描述用户查询流程
当用户问“已发货的订单总金额?”,系统:
- 向量检索 → 匹配“orders”表描述
- 识别关键词“已发货” → 映射到
status='shipped' - 调用预定义函数
query_orders_by_status('shipped')
4.3 技术栈选择
组件 | 推荐 |
|---|---|
向量模型 | text-embedding-3-small(OpenAI), bge-m3(国产) |
向量库 | Chroma(轻量), Milvus(企业级) |
框架 | LangChain, LlamaIndex |
4.4 可视化:向量库 vs 数据库对比图
以下图表破除“向量化=存数据”误区,明确向量库只存“理解”,数据库存“事实”:
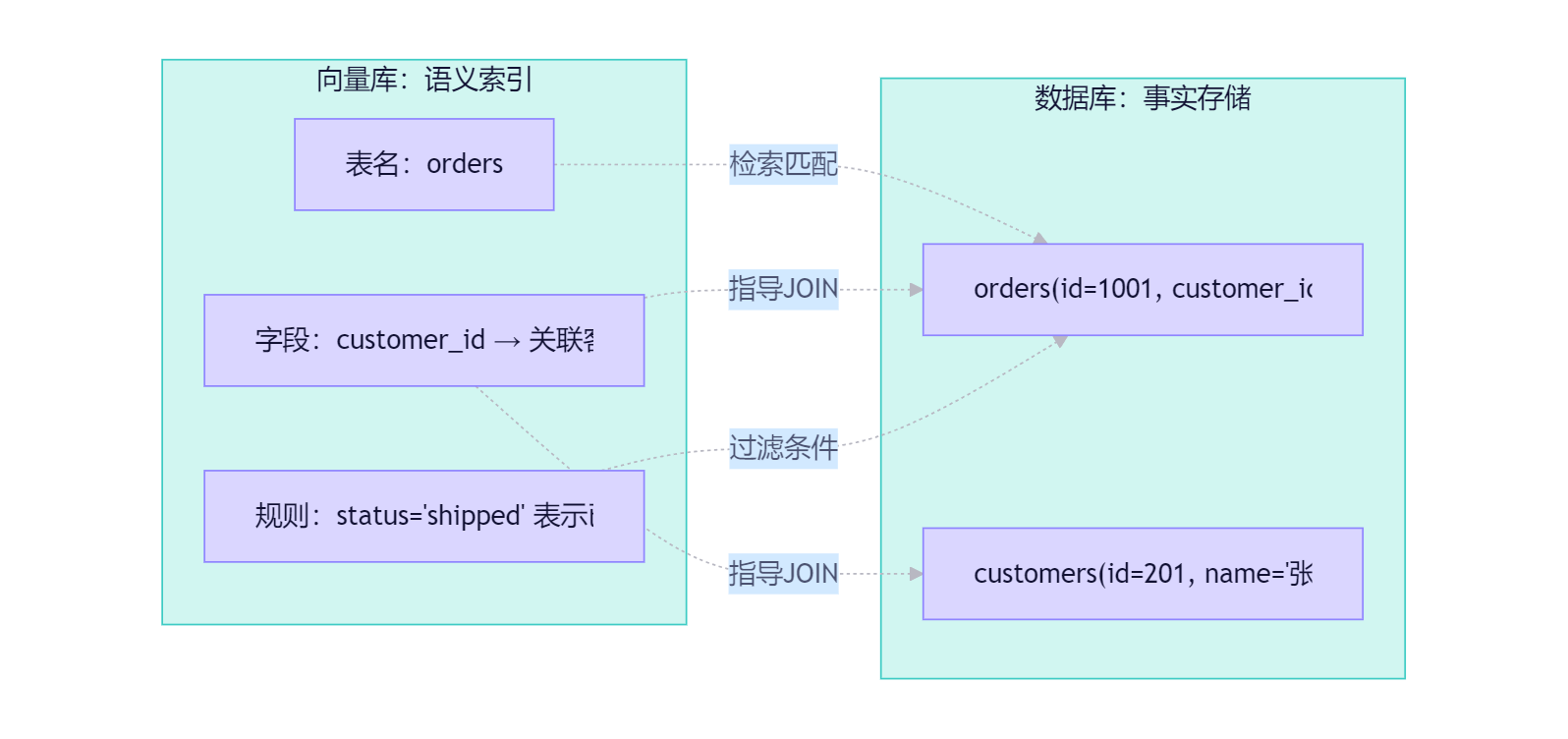
图4:向量库 vs 数据库对比图(概念澄清) —— 用饼图+关系图破除常见误区,强调向量库的语义索引本质。
第五章:实战案例——从零搭建企业AI助手
场景:为内部ERP系统添加AI能力
目标
- 用户可自然语言查询:“上月A部门报销总额?”
- 可问代码:“报销审批流程在哪实现?”
- 安全合规,不暴露原始数据
架构设计
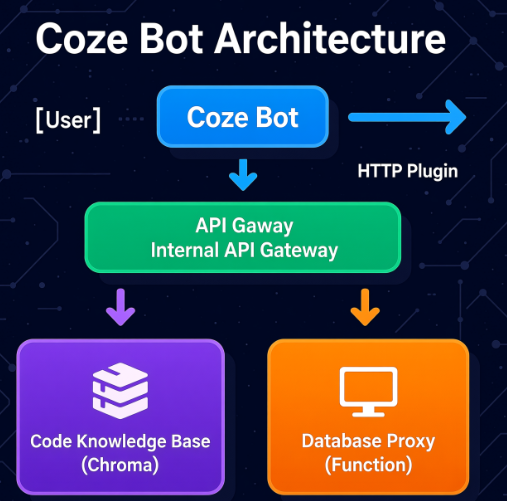
图5
实施步骤
- 代码知识库建设
- 脚本遍历
/src目录 - 为每个函数生成摘要 → 存入 Chroma
- 脚本遍历
- 数据库代理开发
- 定义5个安全函数:
query_dept_expense(dept, month)get_approval_flow(module)- ...
- 定义5个安全函数:
- Coze Bot 配置
- 添加两个 HTTP 插件:
POST /api/code-search→ 返回相关代码POST /api/query-data→ 返回结构化数据
- 编写 Prompt 模板,引导模型正确调用
- 添加两个 HTTP 插件:
- 测试效果
- 问:“报销模块的代码在哪?” → 返回
expense/approval.py片段 - 问:“3月IT部花了多少钱?” → 返回“¥42,800” + 图表链接
- 问:“报销模块的代码在哪?” → 返回
5.1 可视化:扣子(Coze)集成架构图
以下架构图专为使用扣子的企业设计,清晰标注内外网边界与API调用路径:
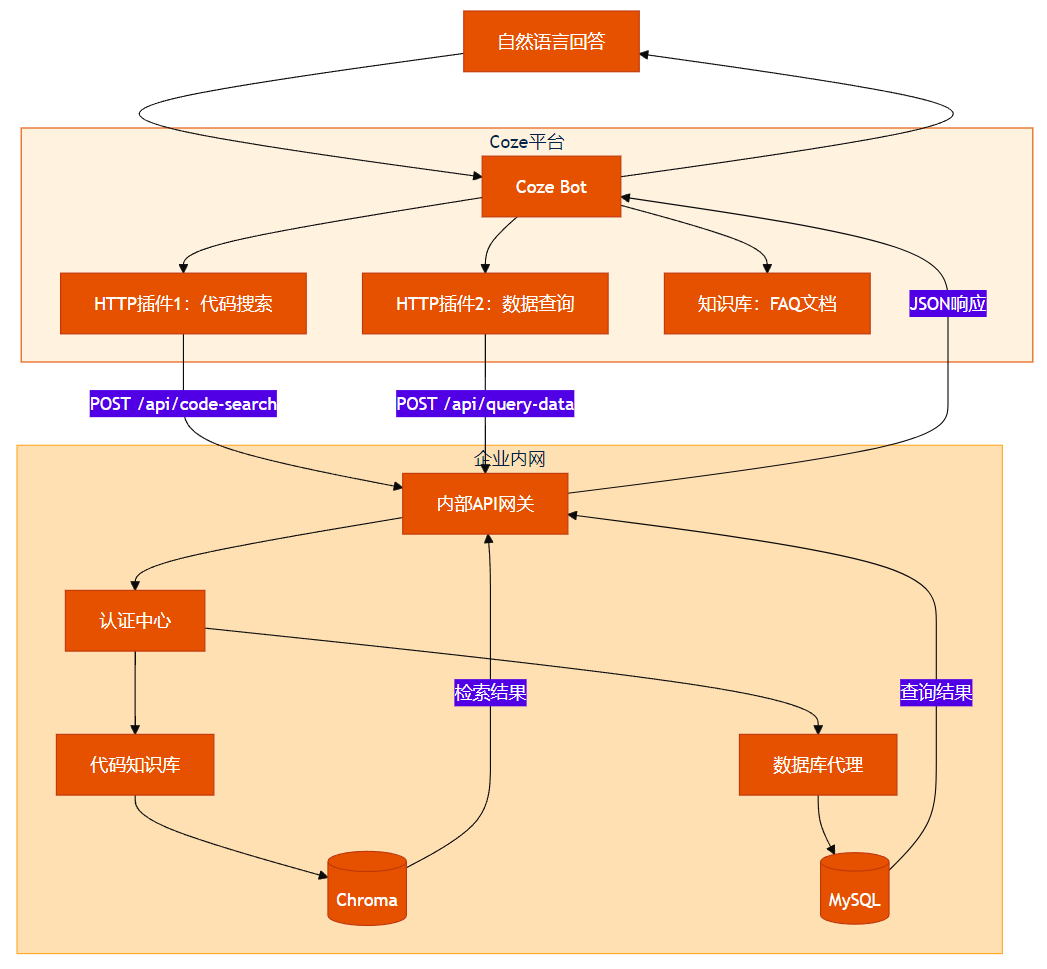
图6:扣子(Coze)集成架构图 —— 清晰展示内外网通信边界,便于运维部署与安全评审。
第六章:避坑指南——企业落地的十大陷阱
- 幻觉问题:未用RAG,导致编造答案 → 必须外挂知识库
- 数据泄露:直接传私有数据给公有云模型 → 敏感数据本地处理
- 权限失控:让模型自由写SQL → 只开放预定义函数
- 性能瓶颈:每次问答都全表扫描 → 缓存 + 分页
- 提示词脆弱:未做输入校验 → 加防护层(如 Moderation API)
- 忽视用户体验:AI回答太技术 → 强制“先结论,后细节”
- 缺乏反馈闭环:无法优化模型 → 记录bad case,持续迭代
- 过度工程:一上来就搞多Agent → 从单点场景切入
- 忽略合规:未做审计日志 → 所有查询留痕
- 团队断层:只有算法不懂业务 → 组建“AI+业务”联合小组
6.1 可视化:企业AI集成总架构图
以下全局视图展示从用户输入到最终输出的完整闭环,突出三层分层架构:
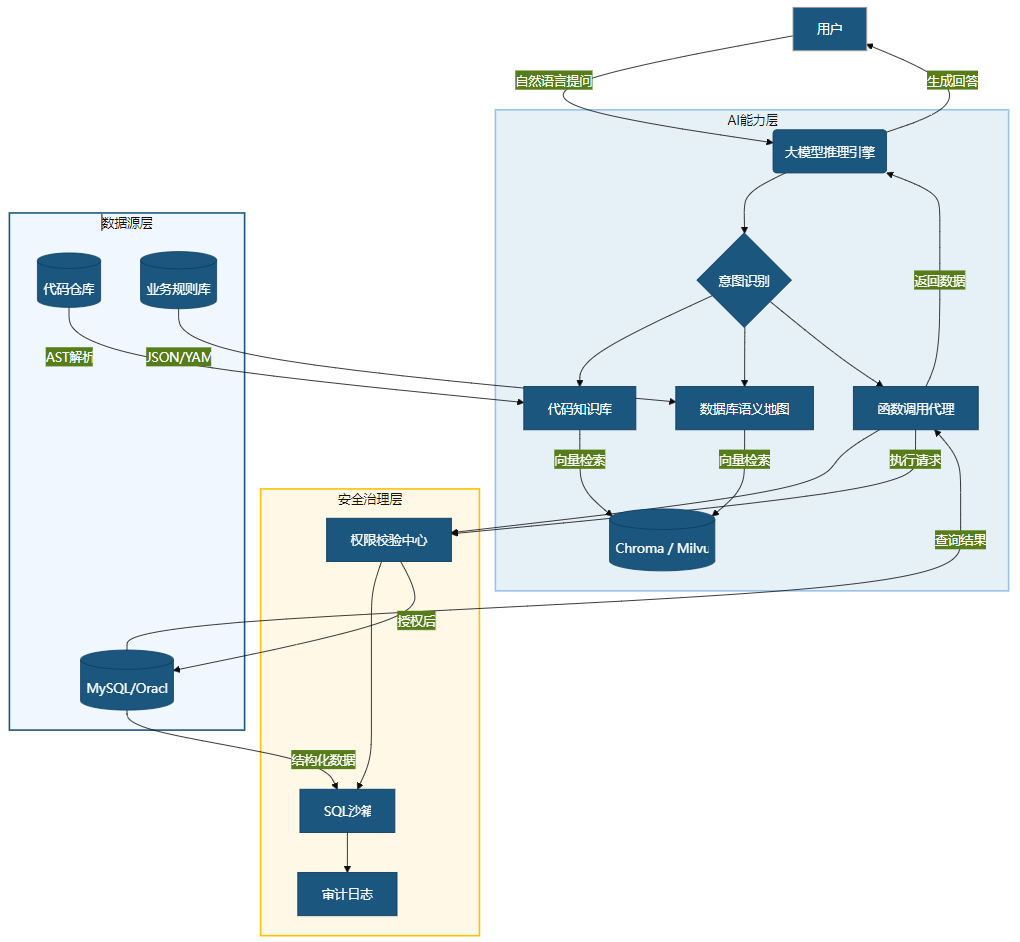
图7:企业AI集成总架构图(全局视图) —— 展示三层分层架构(AI能力层 / 安全治理层 / 数据源层),强调“权限校验”与“SQL沙箱”作为安全闸门。
第七章:未来展望——2026及以后的技术趋势
7.1 智能体(Agent)规模化
- 单Agent → 多Agent协作:数据Agent + 报告Agent + 审批Agent
- 工具调用标准化:MCP(Model Context Protocol)成为新接口规范
7.2 GraphRAG:超越向量检索
- 用知识图谱表示代码/数据关系
- 支持复杂推理:“为什么这个订单没发货?” → 追溯库存、物流、审批链
7.3 本地化部署成熟
- Ollama + Llama 3 + Qdrant 成为企业标配
- 国产模型(通义、DeepSeek、Kimi)支持私有化
7.4 可视化:多表关联查询的语义映射流程
以下流程图详细拆解“两个关联表”如何被AI理解,强调语义地图在关联推理中的桥梁作用:
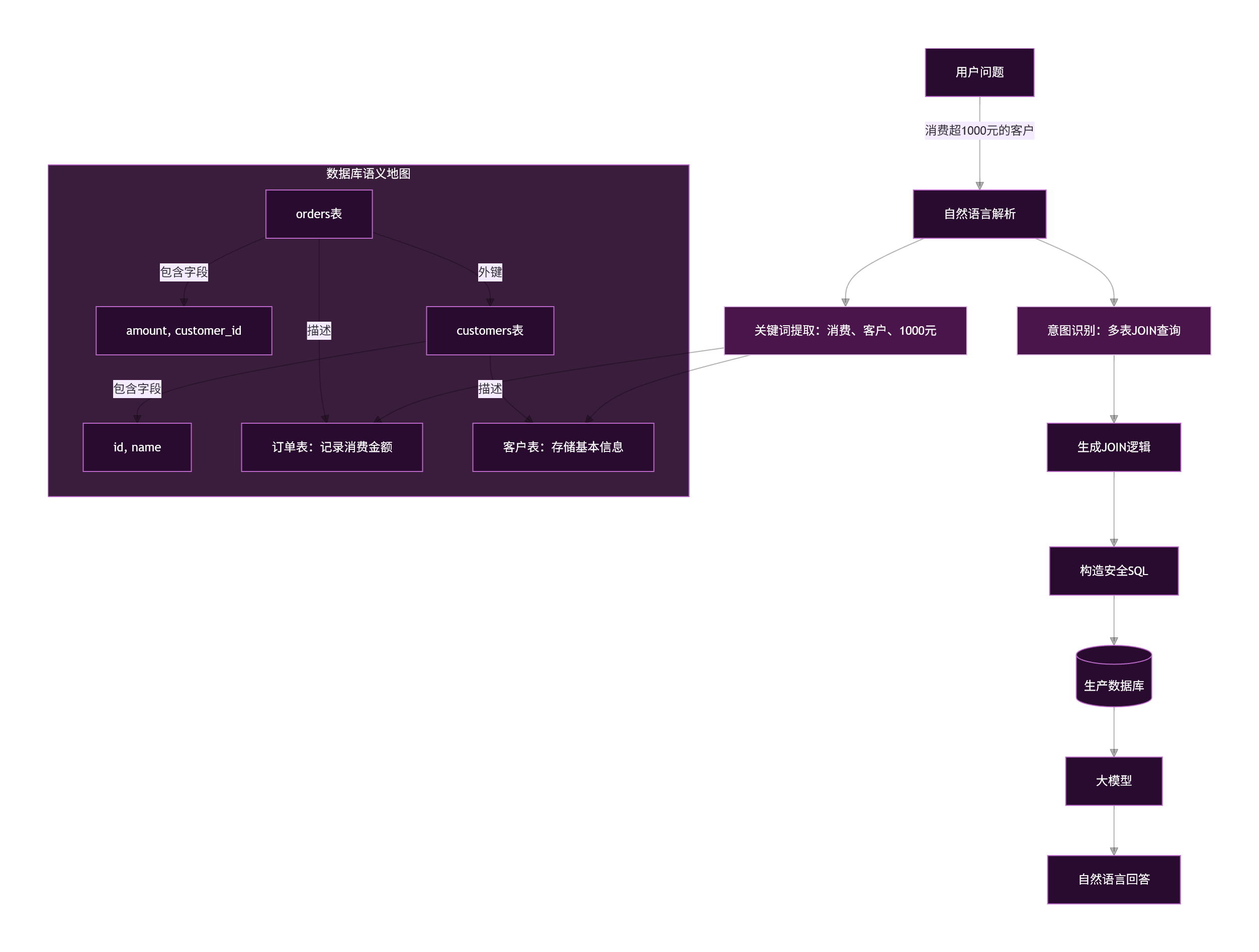
图8:多表关联查询的语义映射流程 —— 详细拆解“两个关联表”如何被AI理解,强调语义地图在关联推理中的桥梁作用。
第八章:安全与治理——企业级AI的生命线
8.1 安全沙箱架构
为确保AI查询不危及生产系统,必须部署四道防线:
- SQL白名单:仅允许SELECT,禁止DDL/DML
- 资源限制:CPU < 5%,执行时间 < 5秒
- 行级权限:基于用户角色动态过滤
- 字段脱敏:敏感信息自动掩码
8.2 可视化:安全沙箱架构图
以下架构图展示SQL安全执行的四道防线,适用于安全合规评审:
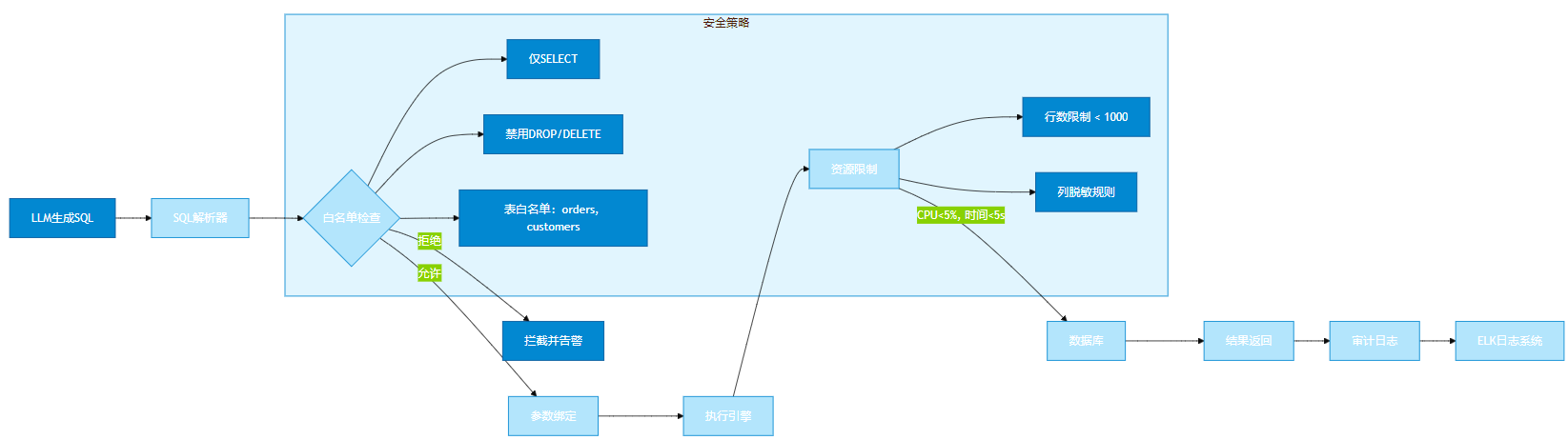
图9:安全沙箱架构图(SQL执行防护层) —— 聚焦SQL安全执行,展示“解析→白名单→资源限制→审计”四道防线。
第九章:实施路线图——从试点到全面推广
9.1 12个月落地计划
企业AI转型不宜激进,建议采用 “基础建设 → 试点上线 → 全面推广 → 战略升级” 四阶段模型。
9.2 可视化:企业AI落地路线图
以下甘特图给出可执行的12个月计划,适合作为项目立项PPT核心页:
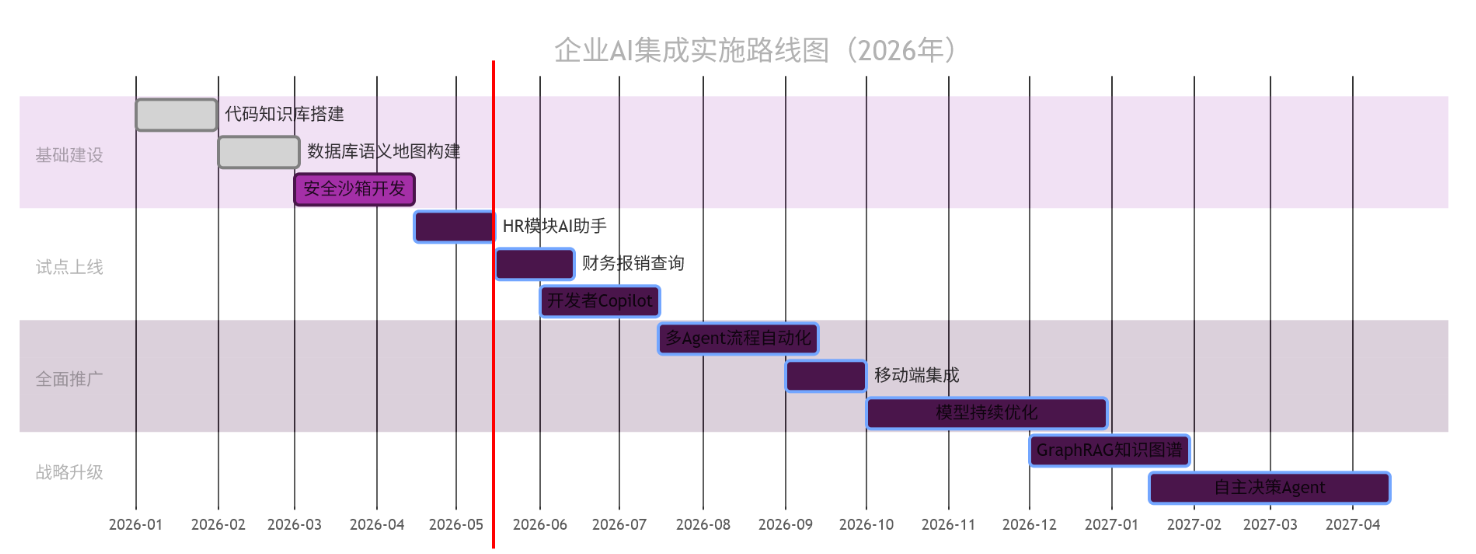
图10:企业AI落地路线图(12个月规划) —— 甘特图形式给出可执行的12个月计划,适合作为项目立项PPT核心页。
第十章:高级主题——多智能体与知识图谱
10.1 Agent协作架构
在复杂业务场景中,单一Agent能力有限。需构建 Agent集群,分工协作:
- 数据Agent:负责查询数据库
- 报告Agent:生成可视化图表
- 审批Agent:调用工作流引擎
10.2 可视化:Agent协作架构图
以下架构图展示高级场景下多Agent分工协作模式:
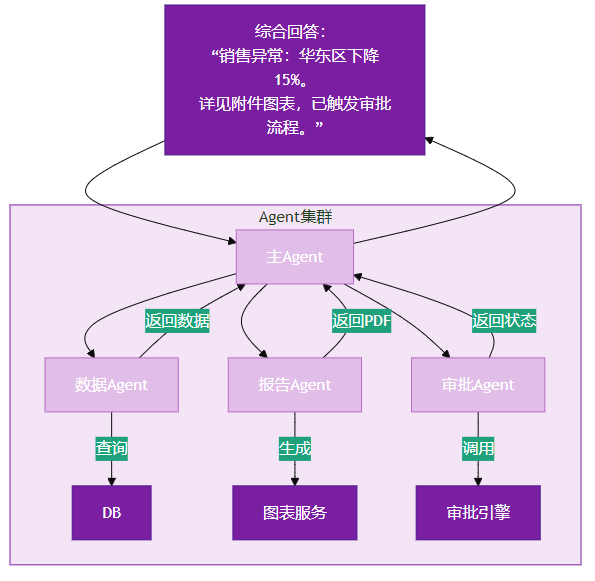
图11:Agent协作架构图(多智能体协同) —— 展示高级场景下多Agent分工协作模式,适用于复杂业务流程自动化。
第十一章:权限与合规——满足等保要求
11.1 字段级权限控制
不同角色应看到不同数据粒度:
角色 | 可见字段 | 脱敏规则 |
|---|---|---|
财务主管 | 姓名、邮箱、金额 | 无 |
普通员工 | 姓名、部门、汇总金额 | 邮箱隐藏 |
审计员 | 全字段 | 身份证AES加密 |
11.2 可视化:数据脱敏与权限控制矩阵
以下矩阵图直观呈现RBAC+ABAC混合权限模型:
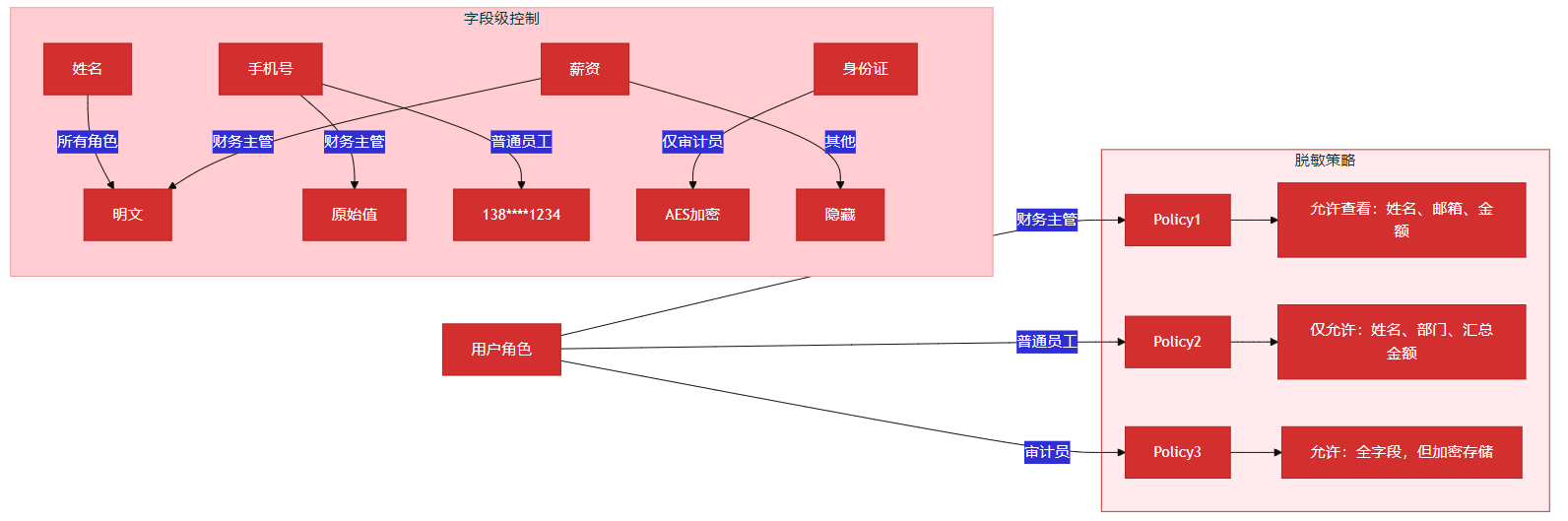
图12:数据脱敏与权限控制矩阵 —— 直观呈现RBAC+ABAC混合权限模型,是满足等保2.0/ISO27001的关键设计。
第十二章:本地化部署——私有化AI栈
12.1 全栈开源方案
对于金融、政务等高安全要求场景,推荐以下私有化技术栈:
- 大模型:Ollama + Llama 3-70B
- 向量库:Milvus
- 数据库:MySQL 8.0
- 安全组件:Keycloak(认证)、ModSecurity(WAF)
12.2 可视化:本地化部署方案
以下架构图面向高安全要求场景,提供完整私有化技术栈方案:
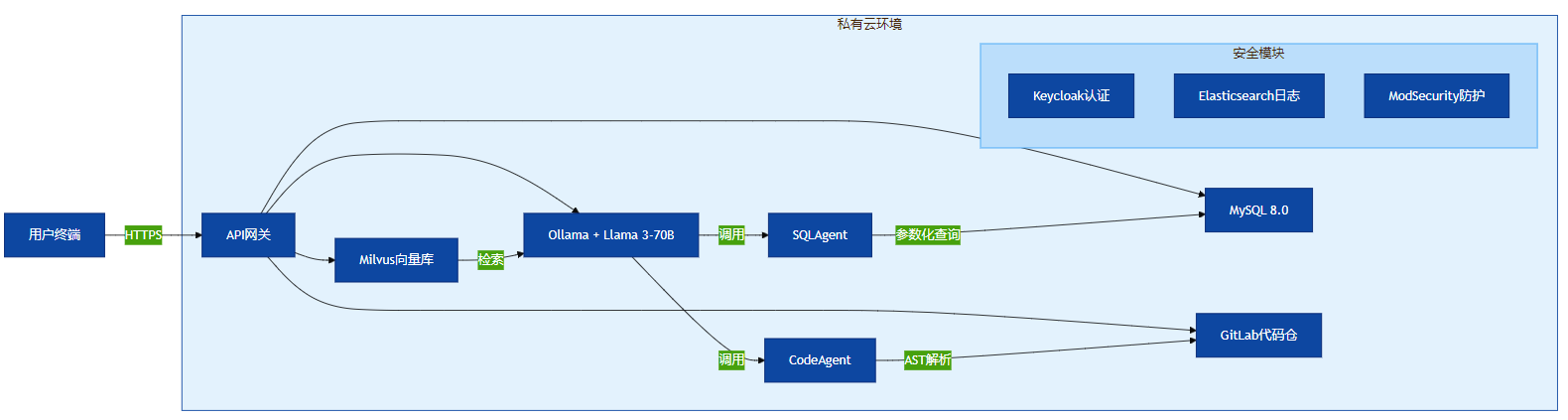
图13:本地化部署方案(私有化AI栈) —— 面向金融、政务等高安全要求场景,提供完整私有化技术栈方案,标注开源组件版本。
结语:AI不是魔法,而是新生产力工具
传统软件的AI化,不是一场颠覆,而是一次进化。它不要求你抛弃过去,而是邀请你站在巨人的肩膀上,用新的方式解决问题。
记住:
- 安全是底线:永远不要让大模型直接接触核心数据。
- 场景是王道:从一个高频、高价值的小场景做起。
- 体验是核心:AI的价值=(能力×易用性)/(等待时间+认知成本)
2026年,AI已进入“务实期”。那些能将大模型安全、稳定、低成本集成到现有系统中的团队,将成为新一轮效率革命的赢家。
附录:资源清单
开源项目
- Vanna.ai:Text-to-SQL 框架
- LangChain SQLDatabaseToolkit:官方数据库工具包
- Dify:开源LLM应用平台
商业平台
- 扣子(Coze):支持HTTP插件、知识库、工作流
- Dify Cloud:企业级RAG + Agent 平台
- 阿里百炼:一站式大模型开发平台
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-05-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号