Nat Mach Intell | 天然产物也需要自己的基础模型

Nat Mach Intell | 天然产物也需要自己的基础模型

MindDance
发布于 2026-05-09 13:49:50
发布于 2026-05-09 13:49:50
昨日,Nature Machine Intelligence 发表了一篇题目为 Pretraining a foundation model for small-molecule natural products的文章。这项工作由北京大学药学院等单位完成。
这篇文章的核心问题:以通用小分子或合成小分子数据为主训练出来的分子模型,真的适合天然产物吗? 作者给出的答案偏谨慎,也很有启发性。天然产物有自己的生物合成逻辑、骨架组织方式、结构复杂性和来源信息。把它们简单当成普通小分子去建模,可能会错过最关键的领域知识。基于这个判断,作者提出了一个面向小分子天然产物的基础模型 NaFM。
NaFM 不是一个单纯做分类或回归的专用模型,也不是一个直接生成天然产物结构的生成模型。它是一个为天然产物构建通用表征的预训练框架:先在大规模未标注天然产物结构上学习,再迁移到分类、来源识别、基因簇相关预测、活性预测和虚拟筛选等任务中。
速览
天然产物是药物发现中非常重要的一类化合物,尤其在抗感染、抗肿瘤等方向长期发挥作用。但天然产物的发现和表征并不容易。传统路线往往需要从生物样本中提取代谢物,再经过活性追踪分离、结构鉴定、来源确认和靶点探索,整个流程费时费力。
过去几年,分子机器学习已经在性质预测、虚拟筛选和分子表示学习中取得很多进展。但现有方法大多面向合成小分子,或者采用一个任务训练一个模型的监督学习模式。这类方法在天然产物研究中会遇到两个问题:一是标注数据有限,二是天然产物的结构和生物合成规律与普通合成小分子并不完全相同。
NaFM 的做法是把天然产物最有代表性的结构单元,也就是 scaffold,分子骨架 放到预训练中心。作者认为,天然产物的骨架往往连接着生物来源、BGCs、合成途径和生物活性;侧链和官能团则更多体现酶介导的修饰。于是,NaFM 同时使用 scaffold-subgraph reconstruction 和 scaffold-aware contrastive learning 两个任务,让模型既能理解骨架,也能保留侧链信息。
结果显示,NaFM 在多个天然产物相关任务上优于传统指纹和多种分子预训练基线。它在 NP taxonomy classification 中取得更高 AUPRC;在 biological source 任务中,模型经 LOTUS 数据微调后,能在表示空间中区分动物、细菌、chromista、真菌和植物来源的天然产物;在 MIBiG/Pfam 相关任务中能从代谢物结构反推 BGC 编码蛋白家族;在 NPASS 活性回归中,除 HIV type-1 reverse transcriptase 上略低于 N-Gram 外,NaFM 在其余目标上均取得最低 r.m.s. error;在 AChE 虚拟筛选案例中,NaFM 排名前列的天然产物候选在计算验证中表现出更有利的预测结合自由能。
这篇文章提出了一种思路:天然产物基础模型不能只复用通用分子预训练套路,而应该把天然产物的生物合成逻辑写进预训练目标。
为什么天然产物值得单独做基础模型
天然产物,通常指由细菌、真菌、动物、植物等生物体产生的代谢物或次级代谢物。它们结构多样、活性丰富,是药物发现中极具价值的化学来源。很多抗菌、抗肿瘤和免疫相关药物,都直接来自天然产物或由天然产物启发改造而来。
但天然产物也很难做。一个天然产物从发现到确认价值,往往要经历样本采集、提取、分离纯化、结构解析、活性检测、来源追踪和靶点研究。即便数据库建设已经取得进展,例如 COCONUT、LOTUS、NPASS、MIBiG 和 Natural Products Atlas 等资源逐渐丰富,天然产物研究仍然面临一个很现实的问题:结构很多,标注有限;任务很多,通用模型不足。
现有天然产物分类工具中,ClassyFire 和 NP Classifier 等方法已经被广泛使用,但它们主要依赖规则或监督学习。监督学习的问题并不是不能用,而是容易受限于标签数量、类别不均衡和数据偏差。对于天然产物这种长尾类别明显、结构空间复杂、来源信息多样的对象,只靠一个任务一个模型,很难形成可迁移的通用表征。
这也是作者提出 NaFM 的背景。通用小分子预训练模型通常把天然产物当作普通分子图来处理,学习目标分布在整个分子上。但天然产物并不只是原子和键的集合。许多天然产物的核心骨架与生物合成途径密切相关,同类或相似骨架往往来自相关生物来源、相近基因簇或类似酶促过程。文章用一个很形象的概念来概括这种联系:天然产物的生物来源、BGCs、合成途径和生物活性,可以通过分子骨架连接起来。
换句话说,天然产物里的 scaffold 不只是化学结构中的主干,它还携带了生物合成层面的信息。NaFM 的预训练策略,正是围绕这一点展开。
NaFM 的核心设计:遮住骨架,让模型学会补回来
NaFM 的预训练使用来自 COCONUT 数据库的未标注天然产物结构。模型骨干采用图神经网络,具体是经过改造的 Graph Isomorphism Network。预训练任务主要由两部分组成:scaffold-subgraph reconstruction 和 scaffold-aware contrastive learning。
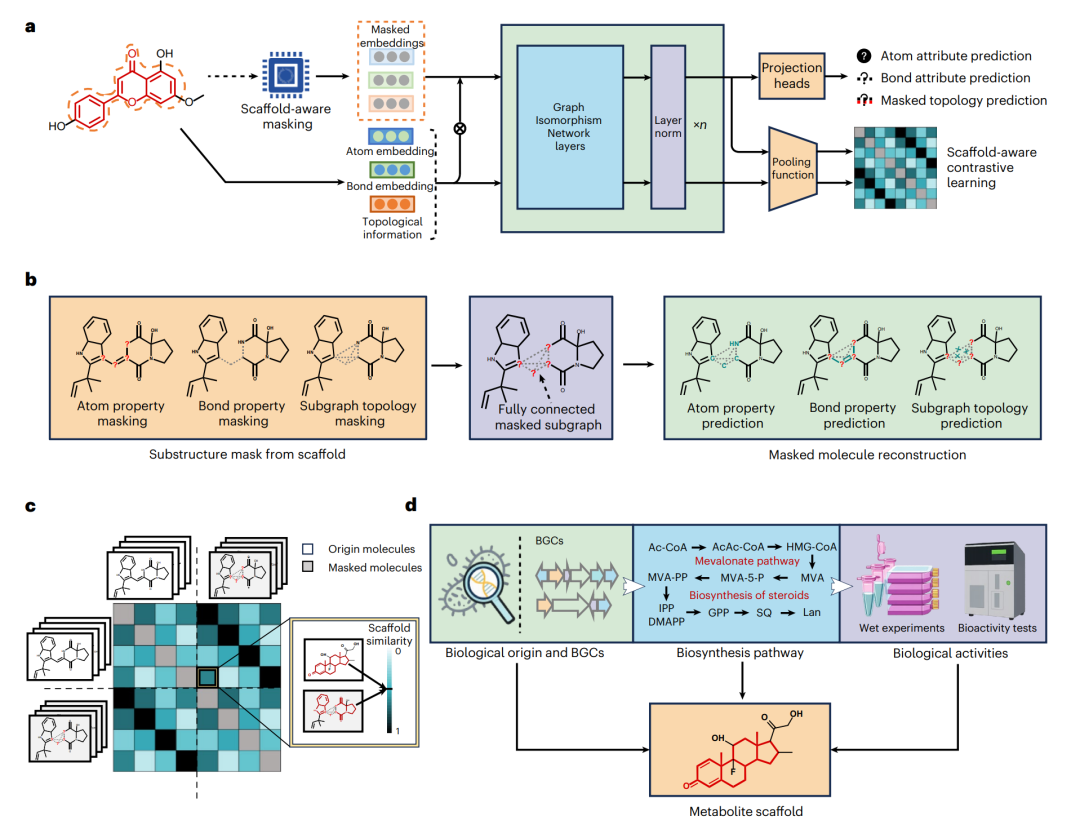
NaFM 的 scaffold-aware 预训练框架
NaFM 的 scaffold-aware 预训练框架
传统 masked graph modelling 往往只遮住单个原子或单条键。这样做的难度有限,因为模型可以从邻近节点和边中轻松推断缺失信息。NaFM 选择了更难的方式:从 scaffold 中随机选取一个子图,同时遮蔽原子属性、键属性和拓扑信息。为了重建这个子图,模型必须判断哪些边是真实存在的,哪些边只是为了遮蔽拓扑而人为加入的虚拟边。
这个设计的意义在于,模型不能只靠局部邻居走捷径,而要理解更大范围的骨架结构。对于天然产物中常见的复杂多环骨架和精细连接关系,这种训练方式更贴近任务本身。
NaFM 的第二个关键设计是 scaffold-aware contrastive learning。普通对比学习通常把同一个样本的不同增强视图作为正样本,把其他样本作为负样本。但在分子,尤其是天然产物中,这个设定并不总是合理。两个不同天然产物可能共享高度相似的骨架;同一个天然产物经过结构扰动后,局部差异也可能对生物活性产生较大影响。简单地把所有其他分子都当成强负样本,可能会误导模型。
因此,NaFM 引入 scaffold similarity 作为负样本权重。骨架越相似的分子,被当作强负样本的程度越低;骨架差异越大的分子,才更适合充当明确负样本。这样一来,模型学习到的表示空间更符合天然产物的生物合成关系,而不是机械地把所有分子推开。
这套设计可以概括为一句话:NaFM 不是单纯学习天然产物长什么样,而是试图学习天然产物为什么长成这样。
一:天然产物分类任务中,NaFM 在低数据场景尤其稳
文章首先评估的是天然产物 taxonomy classification。作者使用 NP Classifier 数据集,清洗掉过于稀疏的标签后,得到约 77,000 个条目,覆盖 7 类 biosynthetic pathways、70 个 SuperClasses 和 563 个 Classes。
为了测试模型在不同数据规模下的表现,作者限制每个 Class 的训练样本数,从每类 4 个样本一直增加到每类 64 个样本。评价指标使用 AUPRC。
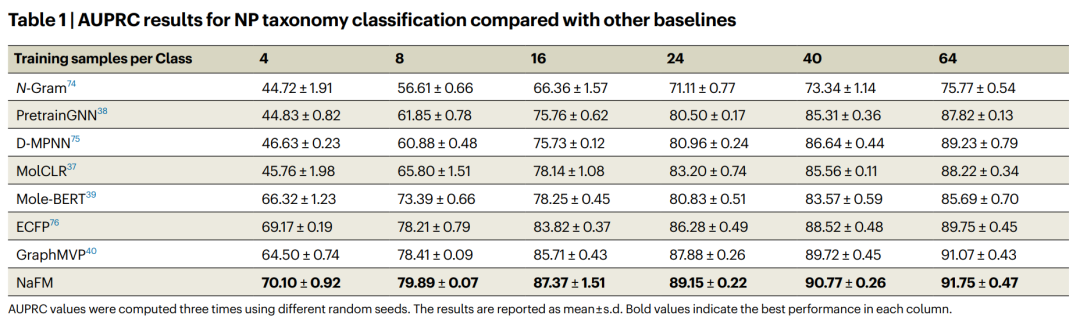
这个结果说明,NaFM 学到的天然产物表征不是只在大数据条件下才有效。对于天然产物这种长尾类别很明显的领域,低数据场景下的稳定性尤其重要。很多天然产物类别很稀有,很难收集到大量标注样本;如果预训练模型能在少量样本下依然表现较好,就更有实际价值。
作者还把 NaFM 与领域内常用的 NP Classifier 做了直接比较。NaFM 在 7 个 biosynthetic pathways 上全部优于 NP Classifier,其中对 amino acids and peptides 的识别提升达到 24% 。在 SuperClass 层面,NaFM 在 53 of 71 个类别中取得更高 AUPRC;对于 Carotenoids C45、Tetramate alkaloids、Peptide alkaloids 和 Anthranilic acid alkaloids 等类别,提升超过 20% 。
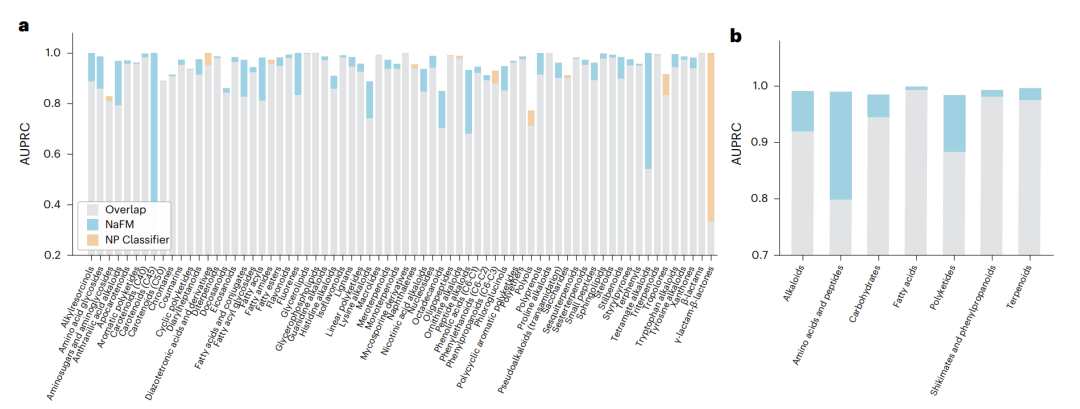
NaFM 与 NP Classifier 在天然产物分类上的比较
NaFM 与 NP Classifier 在天然产物分类上的比较
需要注意的是,少数类别的差距不能过度解读。例如 γ-lactam-β-lactones 类别在数据集中只有 8 个样本,测试集中只有 1 个实例。这类极端稀疏类别,本身就很难给出稳定统计结论。
二:NaFM 的表示空间能区分天然产物来源,也能连接到 BGC 信息
天然产物的一个特殊之处在于,它不只是一个化学结构,还带有生物来源。一个分子来自植物、真菌、细菌还是动物,往往与其骨架、合成路径和活性空间有关。
作者用 LOTUS 数据集对 NaFM 进行微调。LOTUS 中包含约 130,000 个带有 biological source labels 的数据点。结果显示,NaFM 可以在表示空间中把动物、细菌、chromista、真菌和植物来源的天然产物分开。原文图示还将预训练/微调后的表征投影到 Natural Products Atlas 的天然产物上,显示出较清晰的来源聚类。即便 chromista 相关数据很少,约只占 1% ,NaFM 仍能形成相对清晰的区分。相反,同样模型架构如果不做预训练,从头训练时难以区分这些来源。
这种结果很有意义。它提示 NaFM 的表征至少不只是按照分子大小、官能团数量或普通结构相似性来分组,而是保留了一部分与生物来源相关的结构模式。当然,文章也很谨慎地指出,某些误分类来自真实生化重叠,例如植物、真菌和动物之间共享的 terpenoid 或 indole scaffolds。这类错误不一定是模型无能,反而可能反映天然产物生物合成空间本身存在交叉。
更进一步,作者还评估了从 metabolite structure 反推 BGC 相关信息的能力。传统 genome mining 更多是从 BGC 推断可能产物,而这里的问题方向相反:给定天然产物结构,能否预测与其相关的 BGC-encoded protein families。严格来说,这不是直接还原完整 BGC 序列,而是预测 BGC 编码的蛋白家族特征。
作者从 MIBiG 收集了超过 2,000 个细菌和真菌 BGC,并结合 Pfam 蛋白家族信息,训练模型从代谢物结构预测 BGC 编码的蛋白家族。在最常见的 128 个 protein families 上,NaFM 在几乎所有被分析的高频蛋白家族中优于 MolCLR、ECFP 和 PretrainGNN 等基线。图中还显示,在 Conserved Protein Domain Family 和 HATPase_c 等保守功能相关家族上,NaFM 与基线之间的差距尤为明显。
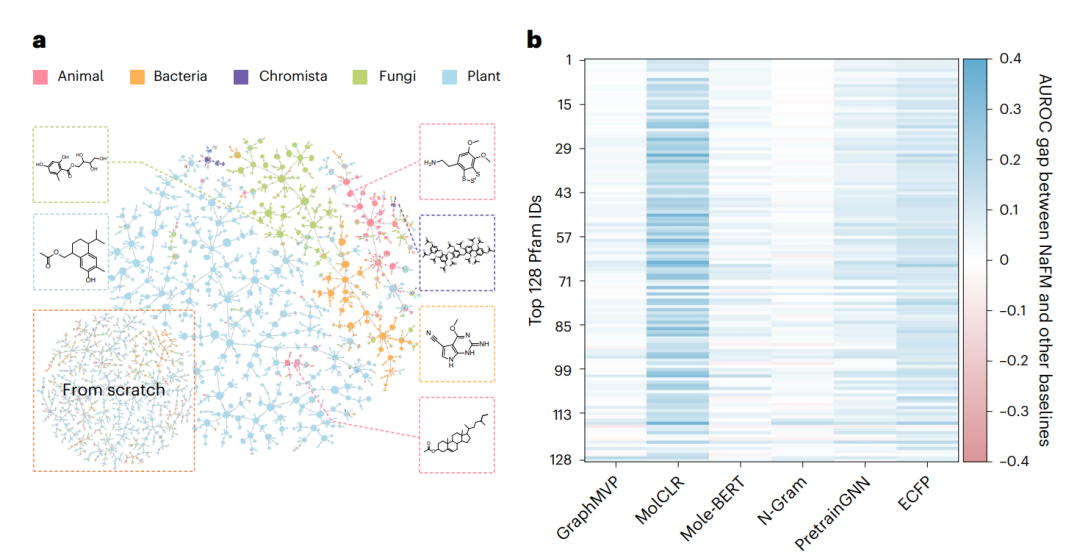
NaFM 的生物来源区分能力与反向 BGC 功能预测
NaFM 的生物来源区分能力与反向 BGC 功能预测
这部分结果是整篇文章最有天然产物特色的地方。很多分子模型只会回答这个分子有什么性质,而 NaFM 试图往前追一步:这个分子的结构可能来自怎样的生物合成背景。
三:活性预测中,NaFM 在多数靶点上取得最低误差
天然产物活性数据通常比合成小分子更稀缺。一方面,许多天然产物合成或提取困难;另一方面,细胞表型数据虽然相对多,但涉及多个蛋白、细胞器和信号通路,很难直接解释结构-活性关系。因此,作者选择了具有明确三维结构和结合位点的蛋白靶点,评估 NaFM 在 protein-target bioactivity prediction 中的表现。
数据来自 NPASS,作者筛选了每个靶点活性数据量大于 100 的人源蛋白靶点以及 HIV type-1 reverse transcriptase。活性值用 pIC50 表示,评价指标为 r.m.s. error。结果如下表所示。
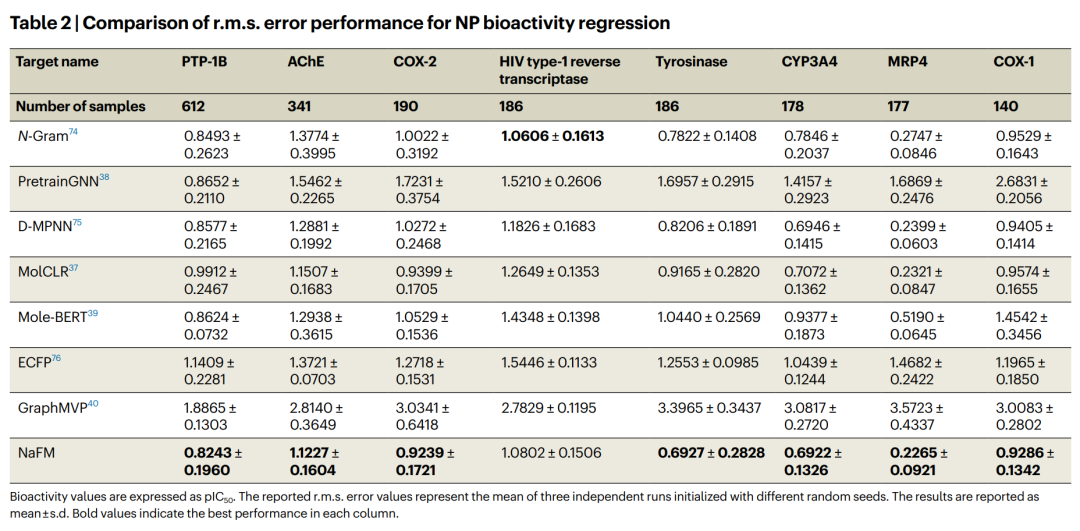
这组结果说明,NaFM 的预训练表征可以迁移到下游活性预测任务。尤其值得注意的是,GraphMVP 这类依赖几何信息的预训练方法在这些任务中表现较弱。作者认为,这可能与天然产物兼具刚性局部子结构和灵活整体构象有关。天然产物的三维构象分布复杂,几何预训练如果不能覆盖足够多样的构象空间,反而难以形成稳定优势。
四:AChE 虚拟筛选案例显示,NaFM 能帮助优先排序天然产物候选
为了进一步检验 NaFM 在药物发现中的应用价值,作者做了 AChE 虚拟筛选案例。AChE 是神经退行性疾病治疗相关的重要酯酶靶点。作者从 NPASS 中获取 AChE 的 IC50 数据,并用 micromolar cutoff 将化合物分为 active 和 inactive。模型微调后,被用于对 COCONUT 中的天然产物进行打分和排序。
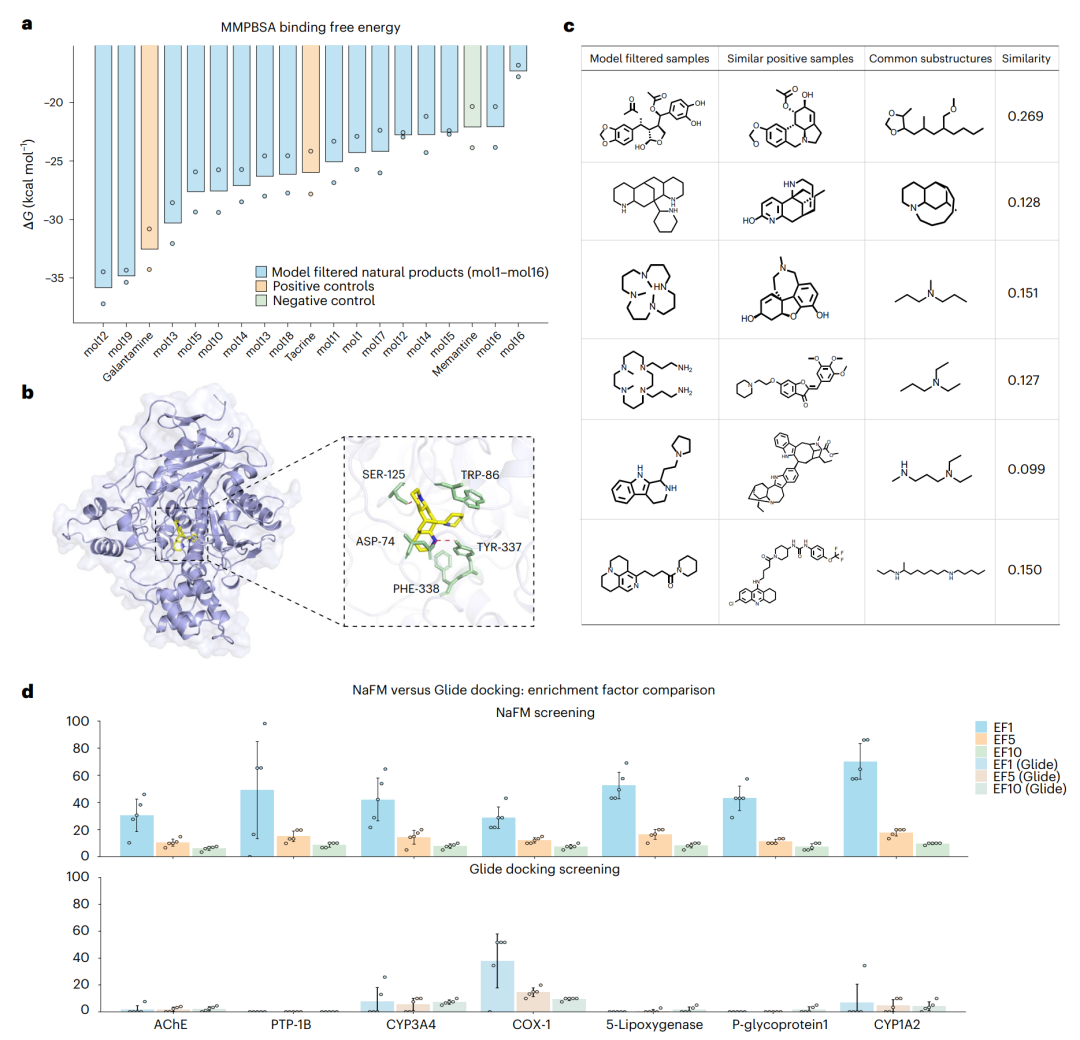
随后,作者对排名靠前的 16 个候选分子,以及三个参照分子进行计算验证。参照分子包括 AChE 抑制剂 galantamine 和 tacrine,以及临床联合使用但不结合或抑制 AChE 的 memantine。计算流程包括以 docking pose 作为初始构象、100 ns 分子动力学模拟和基于平衡轨迹片段的结合自由能估计。结合自由能使用平衡轨迹最后 10 ns 的片段进行计算,原文图注中称该计算为 MMPBSA,并说明采用 generalized Born model。
结果显示,16 个候选分子中有 2 个 的预测结合自由能低于两个阳性对照,意味着在该计算评估中具有更有利的结合趋势。排名靠前的 Mol12 在 AChE active-site gorge 中形成了较密集的相互作用网络,其铵基与 ASP74、SER125 和 TYR337 形成氢键,同时与 TRP86 和 PHE338 形成疏水或范德华接触。
作者还比较了候选分子与已知阳性分子的结构相似性。尽管微调集中包含 44 个活性分子和 37 个 Bemis-Murcko scaffolds,NaFM 选出的多个候选与已知活性分子的 ECFP4 Tanimoto 相似性仍较低,图中示例值大约位于 0.099 到 0.269。这提示 NaFM 并不是简单找回微调集中高度相似的结构,而是可能帮助发现新 scaffold 候选。
NaFM 在 AChE 虚拟筛选中的计算验证和多靶点 enrichment factor 比较
NaFM 在 AChE 虚拟筛选中的计算验证和多靶点 enrichment factor 比较
作者还把 NaFM 与 Glide docking 进行了比较,使用 AChE、PTP-1B、CYP3A4、COX-1、5-lipoxygenase、P-glycoprotein 1 和 CYP1A2 七个靶点进行 enrichment factor 评估。结果显示,NaFM 在 EF1%、EF5% 和 EF10% 上大多优于 Glide,唯一例外是 COX-1 的 EF1% 略低。
这部分结果需要客观看待。它说明 NaFM 表征对天然产物虚拟筛选有帮助,但主要还是 计算验证和基于已有活性数据的筛选评估证据,不能直接等同于湿实验确认的先导发现。真正推进到药物发现,还需要合成或获取样品、体外活性验证、选择性评估和 ADMET 相关实验。
消融实验:优势来自目标设计,而不只是数据集变大
一个模型如果表现好,常见质疑是:是不是因为用了更合适或更大的预训练数据?作者对此做了消融分析。
首先,完整 NaFM 在分类任务中取得最高结果,AUPRC 为 70.10 ± 0.92,accuracy 为 64.78 ± 0.80。移除 masked graph modelling 后,accuracy 降到 57.87 ± 2.13;移除 contrastive learning 后,accuracy 降到 61.75 ± 2.05。这说明两个预训练目标是互补的,scaffold-subgraph reconstruction 和 contrastive learning 都在发挥作用。
其次,作者比较了 scaffold-aware contrastive learning 的不同设计。不使用 scaffold-based weighting 的标准对比学习,在每 Class 只有 4 个训练样本时 AUPRC 为 65.24 ± 0.86;加入 scaffold weighting 和动态调度后,提升接近 5 个百分点。不同调度策略中,cosine schedule 表现最好,达到 70.10 ± 0.92;exponential 和 logarithmic schedule 分别为 65.64 ± 0.43 和 67.12 ± 0.36。
最后,作者把 MolCLR、PretrainGNN 和 Mole-BERT 等支持预训练的基线也重新在同一个 COCONUT 数据集上预训练。结果显示,重新预训练并没有让这些基线追上 NaFM。这说明 NaFM 的优势并不只是来自 COCONUT 数据本身,而是来自更适合天然产物的预训练目标。
这个结论对于分子基础模型很重要。领域模型的关键不只是数据规模,而是训练目标是否尊重领域结构。 对天然产物来说,这个领域结构就是 scaffold、生物来源、BGCs 和生物活性之间的内在联系。
启发思考
第一,天然产物不是普通小分子的子集。它们确实可以用分子图表示,但它们的结构组织方式、来源信息和生物合成逻辑更复杂。把通用合成小分子模型直接搬过来,未必能捕捉天然产物最关键的信息。
第二,scaffold 在天然产物建模中应该被赋予更高权重。药物化学中 scaffold 一直重要,但在天然产物中,它还承载了更强的生物合成意义。NaFM 的设计提醒我们,面向天然产物的分子学习不应只看局部官能团或整体拓扑,还应把骨架作为组织表示空间的核心。
第三,对比学习在分子领域不能照搬图像领域。图像增强后仍然通常代表同一对象,但分子的轻微结构变化可能带来活性突变。对于天然产物,不同分子也可能共享相近骨架。NaFM 用 scaffold similarity 软加权负样本,是一个很自然也很必要的改造。
第四,天然产物基础模型的价值不只在药物筛选。文章展示的任务包括 taxonomy classification、biological source discrimination、BGC protein family prediction、bioactivity regression 和 virtual screening。这说明 NaFM 更像一个跨任务的天然产物研究底座,而不是某个单一预测器。
第五,模型表现仍然需要谨慎解读。AChE 案例中的 MD 和结合自由能计算很有价值,但仍属于计算验证。NaFM 排序出的候选分子是否真正具有体外或体内活性,还需要实验确认。对于 rare classes、低样本靶点和复杂来源数据,模型也可能受到数据库偏差影响。
Forward?
NaFM 的一个亮点,是把天然产物特有的生物合成先验融入了预训练目标。但这也引出一些新的问题。
首先,scaffold-aware 设计对不同天然产物类别的适用性可能并不完全相同。对于典型多环骨架、萜类、甾体或聚酮类天然产物,这种方法很直观;但对于高度糖基化、肽类、多修饰或边界模糊的天然产物,scaffold 定义本身可能会影响模型学习。
其次,NaFM 的预训练核心仍主要建立在 2D molecular graph、scaffold 及其拓扑信息上。虽然模型的节点特征中包含手性等属性,但三维构象并不是核心预训练信号。天然产物的立体化学和构象复杂性对活性影响很大,如何把更可靠的三维构象、构象集合、反应路径或酶促修饰信息纳入模型,仍然是后续值得探索的问题。
第三,从 metabolite structure 反推 BGC 编码蛋白家族是一件很有想象力的事,但现实中天然产物结构和基因簇之间可能存在多对多关系。模型如果要走向实际 genome mining,还需要与宏基因组、质谱、代谢组和实验注释进一步结合。
第四,虚拟筛选结果虽然显示 NaFM 优于 Glide 的若干 enrichment factor,但这并不意味着 docking 不重要。更合理的路线可能是将 NaFM 的天然产物表示能力与结构基础筛选、分子动力学、自由能计算和实验验证结合起来,形成多阶段筛选流程。
总结
这篇文章把天然产物研究中的一个核心事实摆到了模型设计中心:天然产物的结构不是随机出现的,它们受到生物来源、BGCs、合成途径和酶促修饰共同塑造。
NaFM 的思路正是围绕这一点展开。它通过 scaffold-subgraph reconstruction 让模型理解骨架结构,通过 scaffold-aware contrastive learning 避免把生物合成相关的相似分子错误推开,再通过下游任务证明这种表征可以迁移到分类、来源识别、BGC 相关预测、活性预测和虚拟筛选中。
对于天然产物药物发现而言,NaFM 代表了一种更有领域感的基础模型路线。它并不试图用一个模型替代天然产物分离、结构解析和实验验证,而是为这些流程提供更好的计算表征和优先级排序。
天然产物基础模型的关键,不是把分子模型做得更大,而是让模型真正学到天然产物自己的生物合成语言。
参考资料
Ding, Y., Qiang, B., Li, S. et al. Pretraining a foundation model for small-molecule natural products. Nat Mach Intell (2026). https://doi.org/10.1038/s42256-026-01226-8
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号