LLM 幻觉的架构级修复:推理参数、RAG、受约束解码与生成后验证

LLM 幻觉的架构级修复:推理参数、RAG、受约束解码与生成后验证

deephub
发布于 2026-04-28 20:58:45
发布于 2026-04-28 20:58:45
大型语言模型可以写代码、起草合同、总结论文,但它有一个致命缺陷:撒谎的时候极其自信。
这就是我们所说的幻觉,它是一个跨层级的问题:推理参数、系统架构、生成策略、生成后验证、模型训练、持续评估,每一层都有份,所以不能把它当成单点问题来处理。
这篇文章会逐层拆开来讲,从最简单的运行时参数一直到生产级的验证管道。
幻觉防御架构
先看全局架构。每一层针对不同的失败模式,真正稳健的系统会把所有层一起部署。

第 1 层:推理时参数
这些是调用模型时在运行时设置的参数。它们是第一道防线,也是最容易被高估的一道。
Temperature
Temperature 控制 token 选择的随机度,取值越低模型越确定,越高则越有创造性——代价是更容易编造。
ValueBehavior0.0完全确定——每次都选概率最高的 token0.1 – 0.3接近确定——略有波动,仍然受约束0.7 – 1.0创造型——波动明显,容易虚构> 1.0混乱——不要用在事实性任务上
一个常见的误解:把 temperature 设成 0 并不能消除幻觉,只是让幻觉变成稳定复现的版本。temp=0 的模型如果错了,它会每次都以完全一致的方式错下去。确定性和正确性不是一回事。
Top-P(核采样)
Top-P 把候选 token 限定在累积概率质量达到阈值 P 的范围内。top_p = 0.1 意味着只有处于概率质量前 10% 的 token 才有机会被选中。
反幻觉场景下建议取 0.1 到 0.5。再与低 temperature 搭配使用——temp=0.1, top_p=0.1 ——就能得到相当保守的生成行为。
Top-K
Top-K 用的是硬截断:每一步只保留最可能的 K 个 token 作为候选。top_k=1 等价于贪婪解码(和 temp=0 表现一致)。事实性问答场景里,top_k=5 配低 temperature 通常足够稳定。
频率惩罚和存在惩罚(Frequency / Presence Penalties)
这两个参数微妙但不能忽视:

注意:过高的 presence penalty 反而会增加幻觉——它在逼着模型引入新的、可能是凭空编造的概念。用的时候要克制。
Max Tokens
这是被低估得最厉害的一个参数。幻觉在长输出中出现的比例远高于短输出,原因是模型会逐渐偏离起初的事实依据。根据任务合理限定输出预算——事实检索类任务给 256 到 512 tokens 就足够了——留给模型游离开来的空间就小得多。
参数速查表
下面是两类最常见任务配置的对照:

事实性任务在每个维度上都要求收紧约束,创造性任务则反过来全部放开。两者混用——比如拿创造性参数去做财务数据抽取——基本等同于主动邀请幻觉。
第 2 层:架构策略
推理参数属于缓解手段不是解决方案。它们降低的是输出分布上的噪声,却不触及根本——模型仍然是在从参数化记忆里生成,而不是从已验证的事实里生成。
真正的修复必须在架构层面做。
检索增强生成(RAG)
把 LLM 绑定到事实信息上,RAG 是迄今最具杀伤力的一种技术。思路很直白:不让模型去训练数据里回忆事实,而是从经过验证的知识库中检索相关事实,再直接注入到 prompt 里。
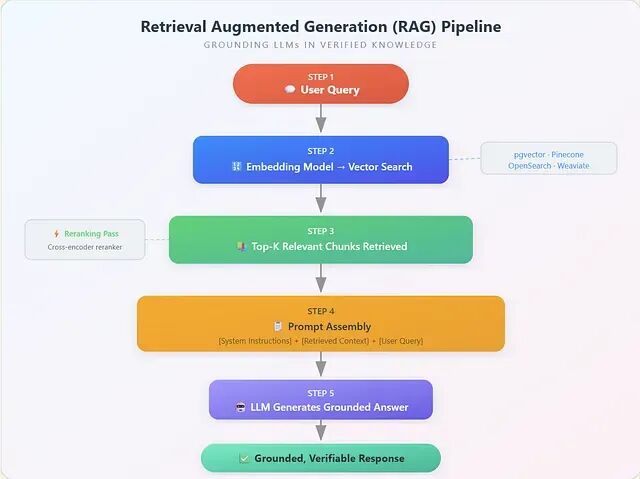
管道看起来简单,魔鬼藏在调参里。每个组件都有直接影响幻觉率的参数:

Chain-of-Thought 与自一致性
CoT prompting 强制模型把推理过程外化出来。模型不能直接跳到答案,而必须一步一步推出来。

这个方法之所以奏效是因为推理一旦外化,错误就变得可见;自一致性投票里,相互矛盾的推理链会彼此抵消。实验数据显示,开启自一致性能把幻觉率降低 10% 到 40%。
受约束解码与结构化输出
这类技术从另一个维度切入:把模型关进一个预定义语法里,它根本吐不出 schema 之外的内容。

Outlines、LMQL、Guidance 这类库把语法级约束直接作用到 token 采样环节。模型从字面上就无法生成允许模式之外的 token,生产系统几乎总需要输出遵守特定结构。
置信度校准与不确定性量化
产生幻觉的 LLM 有一个特别危险的属性:它呈现捏造信息时的自信程度,和呈现事实时完全一样。校准训练针对的就是这一点。

程序化地拿到置信度,靠的是 logprobs:

由此可以搭出一个天然的分级漏斗:高置信度响应走自动通道,置信度不足的被标记并转交人工审核。在金融服务这种高风险领域,这个漏斗不可省略。
第 3 层:生成后验证
架构再好,也总会有幻觉漏过去。生成后验证层的任务,就是把前面几层没拦住的抓回来。
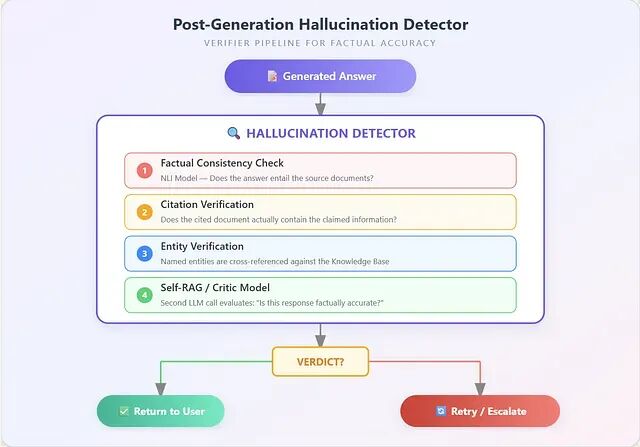
检测器会串行跑四项独立检查:
- 事实一致性检查——用一个 NLI(Natural Language Inference)模型判断生成答案是否能被源文档蕴含(entailed)。答案里有源文件支撑不了的说法,这一步就挂。
- 引用验证——如果响应里带了引用,这一步会核对被引用的文档里是否真的包含所声称的信息。捏造引用是幻觉里最常见、也最丢脸的一类。
- 实体验证——抽出响应中的命名实体(人名、机构、日期、财务数字),在知识库里做交叉比对。编造出来的实体会直接触发失败。
- Self-RAG 或 critic model——再发起一次 LLM 调用,用一个聚焦的 prompt 去评估响应:"给定上述上下文,这条响应事实上是否准确?" 这一步相当于系统内部的同行评审。
四项全部通过的响应才返回给用户。任何一项不通过的,要么以更严格的上下文约束重试,要么升级给人工审核员。
第 4 层:微调与训练端的杠杆
面对领域特有的幻觉——模型在某个专业领域根本缺乏知识——光靠推理端的调节已经不够,必须在训练层面干预。
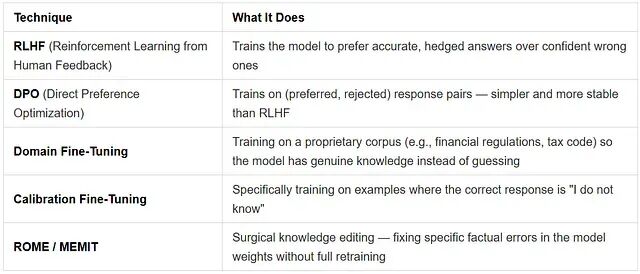
对企业应用最具价值的一条路,是把领域微调和校准训练结合起来。一个既在专有语料上训练过、又被训练成敢于承认不确定性的模型,从根本上比一个靠花哨 prompt 拼凑的通用模型更值得信赖。
第 5 层:评估与测量
度量不到的问题无法修复。先定义指标,再做好仪表化,长期跟踪趋势。

这些指标不是评估一次就能放下的东西,需要在生产环境里作为自动化评估管道的一部分持续运行。随着数据分布漂移、prompt 迭代、模型升级,幻觉率会一直在变。缺了持续监控,上个季度还安全的系统,这个季度就可能在大规模编造。
整合:生产落地手册
把上面几层装配成一个生产就绪的反幻觉栈,大致步骤如下:
- 设定保守的推理参数:temp=0.1、top_p=0.2、top_k=5、收紧 max_tokens。这是噪声底线。
- 部署带 reranker 的 RAG:从已验证知识库中检索,接上 cross-encoder 重排,配好相似度阈值过滤掉不相关的片段。模型只在已经落地的上下文上作答。
- 强制结构化输出:用受约束解码(JSON Schema、Outlines 或 Guidance)挡掉结构性幻觉。每个响应都要求带 confidence 字段和 citations 数组。
- 接入生成后验证器:NLI 事实一致性检查、引用验证、实体交叉比对一起上。失败的响应要么重试,要么升级。
- 在领域数据上做微调:用专有语料训出真正懂业务的模型,训练样本里要包含"答案应当是我不知道"的校准案例。
- 持续测量:在生产中跑 RAGAS 忠实度评分和幻觉率跟踪,配置回归告警,定期复盘被标记的响应。
- 铺一条人在回路的升级通道:验证器置信度跌破阈值时,直接转人工。在一条被编造出来的数字可能造成真金白银损失的场景里,这一步不能省。
总结
真正该问的问题从来不是"怎么让我的 LLM 不再产生幻觉"。这个问法本身就错了。LLM 是概率化的文本生成器,幻觉不是 bug而是这门技术的固有属性。
正确的问法是:怎么围绕 LLM 建一套系统,能在幻觉触达用户之前把它检测出来、阻断掉、并恢复过来。
Dr. Murali Nandigama
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-23,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 DeepHub IMBA 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号