AI驱动的蛋白质设计:系统综述与前沿进展

AI驱动的蛋白质设计:系统综述与前沿进展

DrugIntel
发布于 2026-04-28 13:01:42
发布于 2026-04-28 13:01:42

文献来源:Koh HY*, Zheng Y*, Yang M, Arora R, Webb GI, Pan S, Li L & Church GM. AI-driven protein design. Nature Reviews Bioengineering, 2025. DOI: 10.1038/s44222-025-00349-8 * 共同第一作者 | 哈佛医学院 · Monash大学 · Griffith大学 · Wyss研究所
目录
- 1. 文献概览与核心价值
- 2. 背景:为何蛋白质设计需要AI?
- 3. 两大设计范式与AI的介入方式
- 4. 七大AI工具包:分类体系与关键工具
- 5. AI蛋白质设计路线图
- 6. 四大实战案例深度解析
- 7. AI学习范式与模型架构基础
- 8. 工具成熟度评估与现实差距
- 9. 当前挑战与未来方向
- 10. 对研究者的启示
1. 文献概览与核心价值
这篇发表于《Nature Reviews Bioengineering》综述,由来自哈佛医学院(George M. Church 课题组)、Monash大学和Griffith大学的跨机构团队联合撰写。全文覆盖了AI驱动蛋白质设计领域从基础理论到实际应用的完整图景,具有以下独特价值:
核心贡献有三:
其一,提出了一套可操作的AI工具分类体系(七大工具包,T1–T7),将当前数百种AI工具按照功能与工作流阶段系统归类,解决了研究者面对工具爆炸时的选择困境。
其二,构建了一张从目标到验证的端到端路线图,清晰指导研究者在定向进化和理性设计两种范式下,如何分步骤整合AI工具,形成完整的实验-计算闭环。
其三,以四个真实实验案例(AAV衣壳、抗体、荧光素酶等)演示路线图的实际应用,每个案例均有明确的实验验证结果,不停留于概念层面。
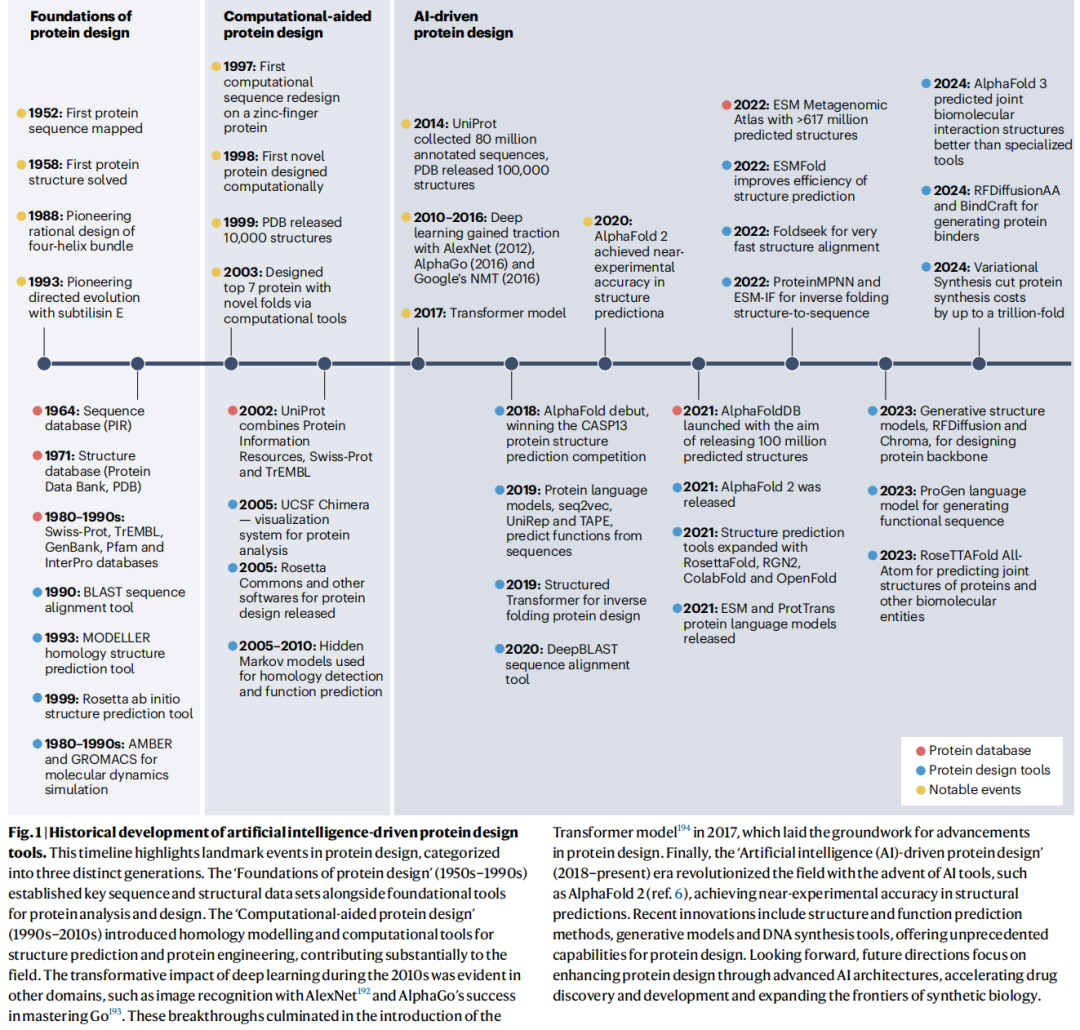
2. 背景:为何蛋白质设计需要AI?
2.1 序列空间的天文数字挑战
蛋白质设计的本质是一个极端困难的组合优化问题。即使对于一个仅有350个氨基酸的中等大小蛋白质,其可能的序列空间也高达:
这一数字远超宇宙中原子的总数(~10⁸⁰),使得任何穷举搜索策略都完全不可行。传统方法——无论是基于物理的分子动力学模拟还是经典计算工具(Rosetta等)——在面对这一空间规模时都捉襟见肘,难以有效利用现代硬件的并行计算能力,也无法弥合对蛋白质生物物理学理解的固有缺口。
2.2 传统方法的核心瓶颈
方法 | 优势 | 核心局限 |
|---|---|---|
定向进化(传统) | 无需机制理解,实验反馈驱动 | 劳动密集、耗时、实验成本高 |
理性设计(传统) | 目标精准,机制可解释 | 严重依赖高质量结构数据,结构未知蛋白难以处理 |
经典计算方法(Rosetta等) | 物理学基础扎实 | 无法充分利用GPU并行计算,搜索效率低 |
2.3 AI带来的范式转变
AI(尤其是深度学习)的引入从根本上改变了这一局面:
- • 结构预测:AlphaFold 2 将蛋白质结构预测精度提升至近实验水平,消除了理性设计对实验结构的强依赖;
- • 序列生成:蛋白质语言模型(如ESM系列)从数亿条进化序列中学习到深层的序列–结构–功能关系,可生成进化上可信、功能上有效的新序列;
- • 从头设计:扩散模型(RFDiffusion)和幻觉方法(Hallucination)将全新蛋白质骨架的生成变为可能,突破了以往只能改造天然蛋白的限制;
- • 虚拟筛选:AI预测模型将传统的湿实验前置筛选搬入计算空间,可在数小时内完成过去需要数月的候选过滤工作。


3. 两大设计范式与AI的介入方式
3.1 定向进化(Directed Evolution)
核心逻辑:结果导向,无需理解机制。模拟自然选择过程——突变、筛选、迭代。
AI改造的关键节点:
- 1. 亲本蛋白筛选:用蛋白质语言模型嵌入(T1a)和GO功能注释(T3a)快速定位具有基线活性且可进化性良好的亲本;
- 2. 关键区域识别:用结合位点预测(T3b)和结构稳定性预测(T2c)缩小突变目标区域(例如,将350残基蛋白的可探索空间从20³⁵⁰收缩至20¹⁰);
- 3. 库多样化:以进化引导生成(T4a)替代随机突变,生成进化上可信的变体,大幅提升库的有效性;
- 4. 虚拟预筛:用序列–功能预测模型(T6a)在实验前虚拟过滤库,仅保留高潜力候选。
典型适用场景:功能目标易于筛选或预测,但结构机制不明确;基因治疗载体(如AAV衣壳)的进化优化;抗体亲和力成熟化。
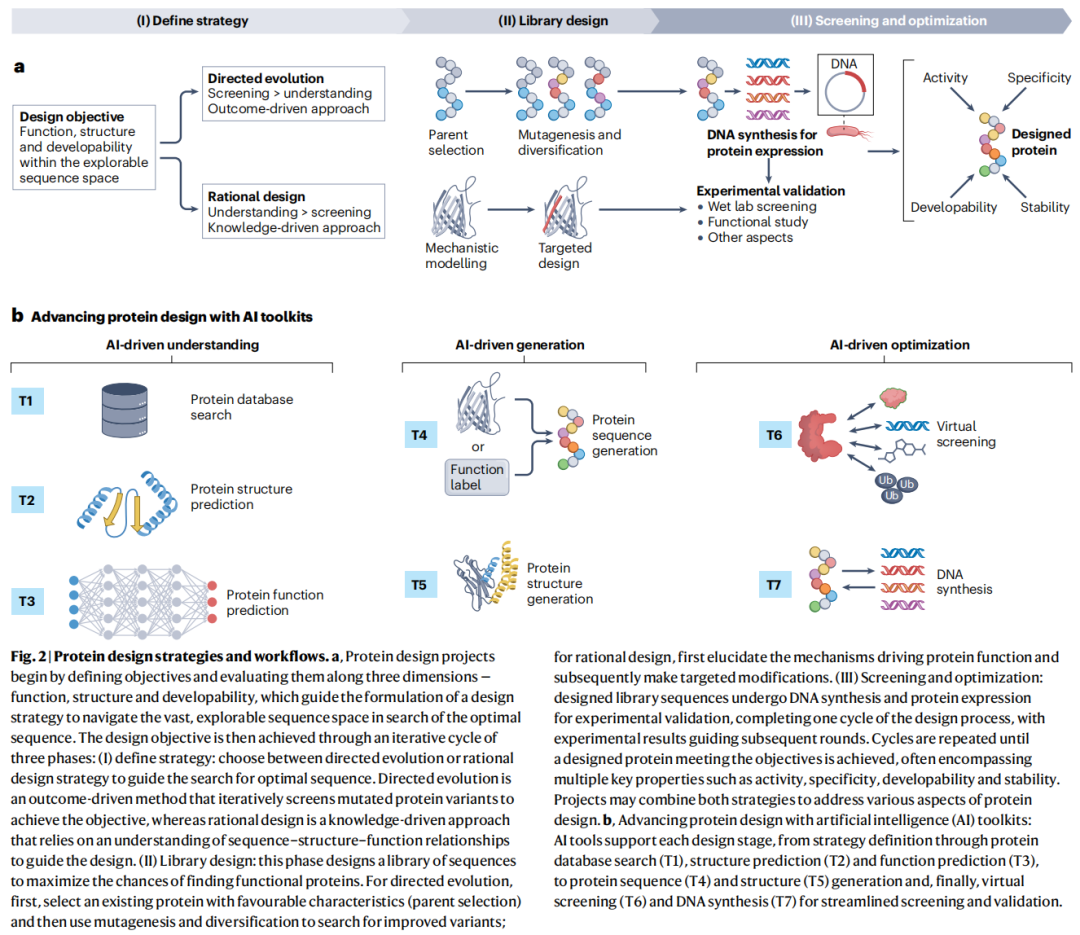
3.2 理性设计(Rational Design)
核心逻辑:机制导向,依赖对序列–结构–功能关系的深刻理解。
AI改造的关键节点:
- 1. 功能骨架构建:根据设计目标选择三种路径之一——
- • 基于骨架(Scaffold-based):在已有骨架上重设计功能位点(如抗体CDR区改造);
- • 基于功能基序(Motif-based):从已知活性基序出发,AI生成围绕它的新骨架;
- • 从头设计(De novo):从随机噪声出发,AI完整生成满足功能约束的蛋白质骨架;
- 2. 逆向折叠(Inverse Folding):给定骨架,用T4c工具包生成能稳定折叠进该骨架的氨基酸序列;
- 3. 验证与精修:用结构预测(T2)验证折叠一致性,用虚拟筛选(T6)评估活性,再用T4c生成多样化变体库。
典型适用场景:目标靶点结构已知;需要精确控制结合界面;从头设计没有天然对应物的新功能蛋白(如合成荧光素酶、新型蛋白结合剂)。
4. 七大AI工具包:分类体系与关键工具
论文将当前AI工具系统归纳为七个功能工具包(T1–T7),每个工具包下设若干子工具包,涵盖从数据检索到实验合成的完整流程。
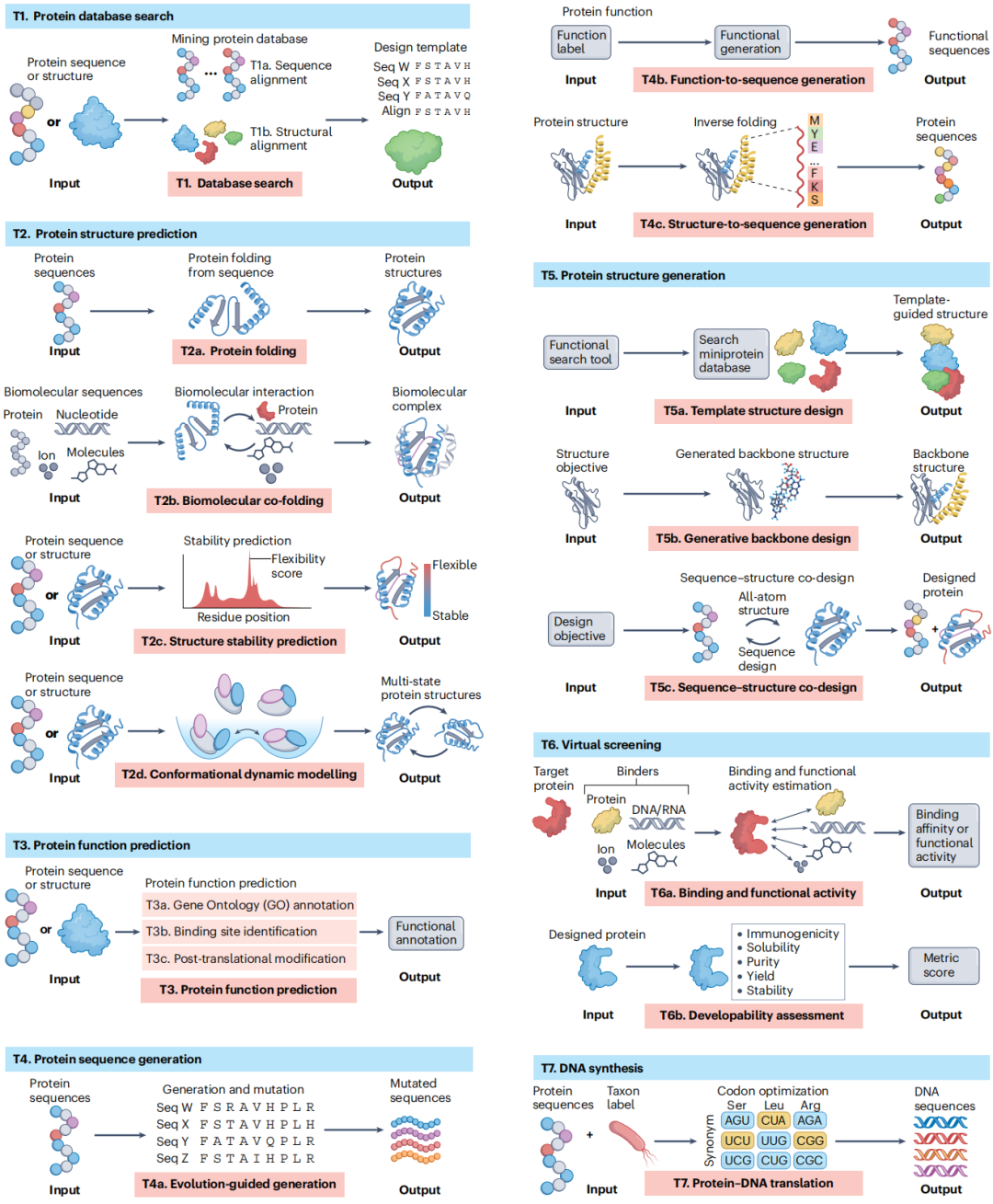

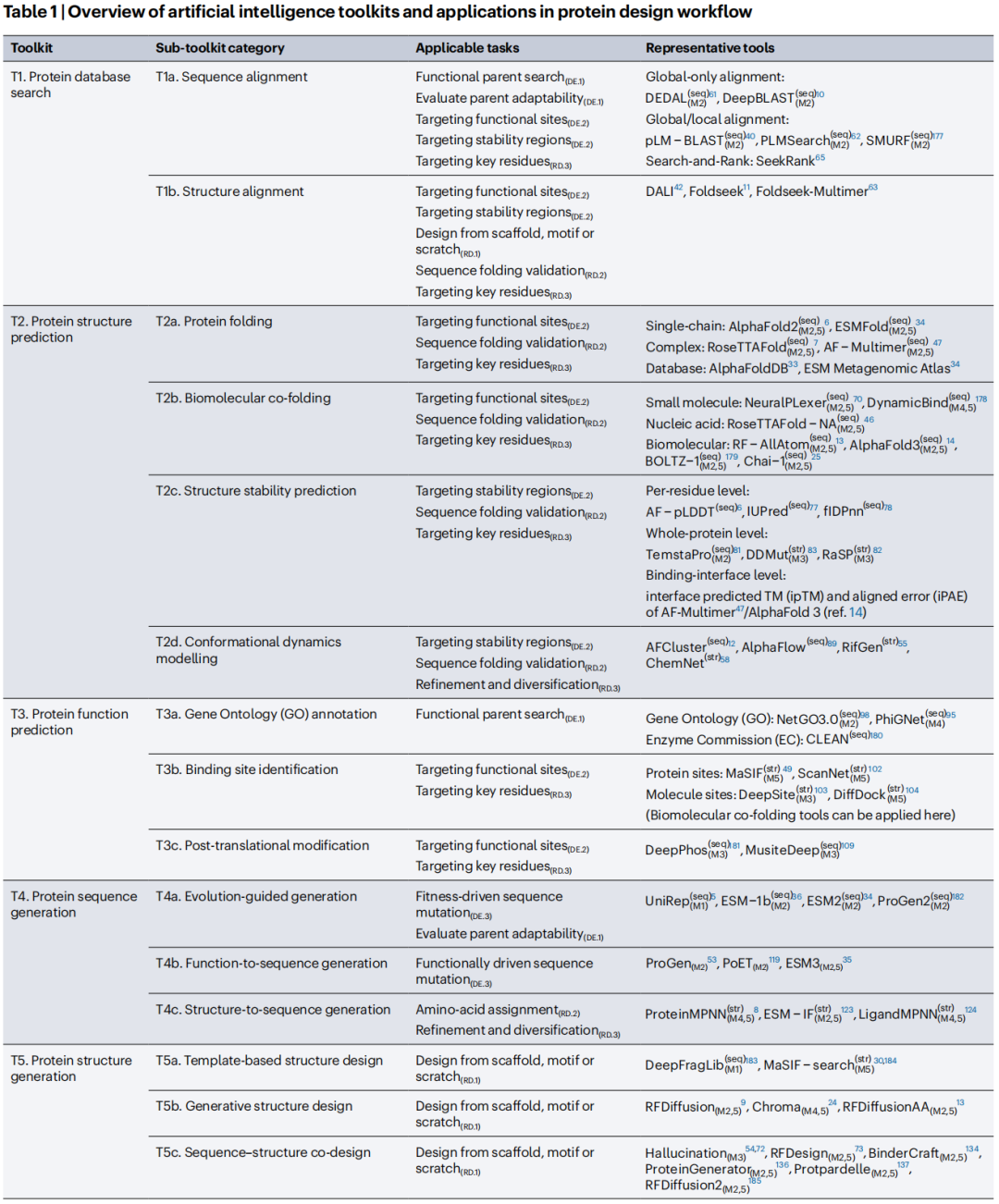
T1. 蛋白质数据库检索
功能定位:通过序列或结构相似性检索同源模板,为设计提供进化信息和结构先验。
T1a. 序列比对
传统BLAST依赖逐残基匹配,对保守替换和远程同源体识别能力有限。AI工具通过蛋白质语言模型嵌入(每个残基被编码为捕获结构、功能、进化信息的向量)实现更深层的相似性比较:
工具 | 方法 | 特点 |
|---|---|---|
DEDAL | 基于语言模型嵌入的全局比对 | 检测深层进化关系 |
pLM-BLAST | 语言模型嵌入直接比较 | 支持局部/全局比对 |
DeepBLAST | 从嵌入预测TM分数 | 单序列即可达结构比对精度 |
PLMSearch | 语言模型+TM分数预测 | 远程同源体的高精度检索 |
SeekRank | 数据库搜索+虚拟筛选联合 | "搜索–排序"一体化,直接输出按功能活性排序的候选 |
T1b. 结构比对
随着AlphaFold 2预测结构数据库(AlphaFoldDB,超1亿条)和ESM宏基因组图谱(超6.17亿条)的建立,结构比对的规模急剧扩展。核心工具:
- • Foldseek:使用VQ-VAE模型将3D残基–残基互作编码为离散"结构字母表",将结构比对转化为序列比对,速度比传统方法快4–5个数量级,可在数分钟内搜索数亿条结构。
- • DALI:经典结构比对工具,适用于深度同源体发现。
- • Foldseek-Multimer:支持蛋白质复合物的结构比对。
成熟度评估:✅ 成熟(Mature) — T1a和T1b均已在工业和制药设计流程中广泛验证。
T2. 蛋白质结构预测
功能定位:从序列推断三维结构和动力学特性,是AI蛋白质设计中最成熟、应用最广的工具包。
T2a. 蛋白质折叠
AlphaFold 2的发布标志着结构预测的革命性突破。其核心架构融合了Transformer(编码进化信号)和几何3D网络(预测原子坐标),对大多数蛋白质实现了近实验精度。
工具 | 输入 | 特点 |
|---|---|---|
AlphaFold 2 | 序列 + MSA | 近实验精度,原子级别预测 |
ESMFold | 单序列(无需MSA) | 速度更快,适合大规模批量预测;15B参数语言模型 |
RGN2 | 单序列 | 孤儿蛋白(无同源序列)预测更优 |
RoseTTAFold | 序列 + MSA | 多链复合物支持 |
AlphaFold-Multimer | 多链序列 | 多蛋白复合物结构预测,精度媲美基于实验单体结构的对接方法 |
ColabFold | 序列 | AlphaFold 2的高效化版本,大幅降低MSA检索时间 |
T2b. 生物分子共折叠
超越单蛋白预测,建模蛋白质与核酸、小分子、金属离子等多种生物分子的互作:
工具 | 覆盖范围 | 亮点 |
|---|---|---|
RoseTTAFold All-Atom | 蛋白质 + 小分子 + 核酸 | 引入全原子token类型,原子级精度 |
AlphaFold 3 | 蛋白质 + DNA/RNA + 小分子 + 离子 | 对多种互作类型优于专用工具 |
Chai-1 | 多分子互作 | 加入表位条件约束后预测精度翻倍 |
BOLTZ-1 | 蛋白质复合体 | 开源的生物分子互作建模工具 |
NeuralPLexer | 蛋白质 + 小分子 | 预测holo构象 |
RoseTTAFold-NA | 蛋白质 + 核酸 | 专门针对RNA/DNA-蛋白互作 |
T2c. 结构稳定性预测
- • 残基水平:AlphaFold 2的pLDDT分数(>90为高可信稳定区域,<50提示柔性/无序区);IUPred2A和fIDPnn直接从序列预测无序区;
- • 全蛋白水平:TemStaPro(基于语言模型,从序列预测热稳定性变化);RaSP和DDMut(基于野生型结构,预测点突变引起的ΔΔG);
- • 复合物界面水平:AlphaFold-Multimer和AlphaFold 3输出的ipTM和iPAE分数,可用于估计界面结合自由能变化。
T2d. 构象动力学建模
蛋白质的功能往往依赖多构象态或动态转换。当前AI工具在这一方向仍处于快速发展阶段:
- • AF-Cluster:通过对MSA按序列相似性聚类,引导AlphaFold 2采样多种高可信构象;
- • AlphaFlow:在分子动力学衍生的构象集合上重新训练AlphaFold 2,增强构象采样能力;
- • AI2BMD:基于量子力学数据训练的3D几何网络,直接模拟全原子分子动力学,计算成本低于传统力场;
- • 重要局限:AlphaFold 2预测的构象不反映Boltzmann能量分布,对折叠转换蛋白的预测准确率仅约35%,对训练集外蛋白几乎失效。
成熟度评估:T2a/T2b/T2c ✅ 成熟;T2d ⚠️ 进阶(仍有局限)
T3. 蛋白质功能预测
T3a. Gene Ontology(GO)注释
将蛋白质映射至生物过程、分子功能、细胞组分三个维度的标准化功能本体。UniProt中仍有数百万条目功能未知,凸显了计算注释的重要性:
- • NetGO 3.0:整合Transformer语言模型嵌入,超过BLAST-KNN基线;
- • PhiGNet:将残基表示为图节点,以协同进化链接为边,通过图神经网络提升预测;
- • CLEAN:基于对比学习的酶委员会(EC)编号预测。
T3b. 结合位点识别
区分两类关键任务:识别靶蛋白上的结合口袋(用于结合剂设计)和识别设计蛋白中需要优化的功能残基:
- • MaSIF 和 ScanNet:基于3D几何网络,从结构表面学习互作指纹,用于蛋白质–蛋白质互作位点预测;
- • DeepSite:3D卷积神经网络,预测小分子结合口袋;
- • DiffDock:扩散模型,盲对接预测小分子结合位点;
- • AlphaFold 3 / RoseTTAFold All-Atom:生物分子共折叠工具的副产品,天然支持多类型结合位点发现。
T3c. 翻译后修饰(PTM)预测
超过400种已知PTM作为分子开关调控蛋白质活性:
- • MuSiteDeep:CNN扫描磷酸化等PTM位点;
- • PTMGPT2:Transformer架构,克服CNN受限感受野的缺陷,捕获长程依赖;
- • MIND-S:融合序列和AlphaFold 2预测结构,结构感知的PTM位点预测;
- • PTMdyna:通过分子动力学模拟PTM对构象动力学的影响。
成熟度评估:T3a/T3b ⚠️ 进阶;T3c ❌ 初步(实验验证有限)
T4. 蛋白质序列生成
T4a. 进化引导生成
蛋白质语言模型通过预测被遮蔽或下一个残基,学习进化上保守的序列规律,形成"进化可信性"先验:
- • UniRep:首批蛋白质语言模型之一(next-token预测),证明语言模型嵌入可驱动多种AI设计工具;
- • ESM-1b / ESM2:掩蔽语言模型,规模从数亿到150亿参数,捕获深层进化信号;
- • ProGen2:专为蛋白质序列生成设计,支持多样化蛋白质家族;
- • 应用逻辑:将突变体与野生型的序列概率之比作为"适应度"代理信号,在无需任何实验数据的情况下预测有益突变(零样本学习)。
T4b. 功能到序列生成
绕过结构中间体,直接从功能标签生成序列:
- • ProGen:利用Pfam标识符和UniProtKB注释作为功能"标签",生成针对特定蛋白质家族的序列;
- • ESM3:多模态模型,融合序列、结构、功能注释(InterPro/GO),支持多维度条件生成;
- • PoET:将蛋白质家族视为序列的序列,推断家族内序列模式,提出功能变体。
T4c. 结构到序列生成(逆向折叠)
给定3D骨架(N–Cα–C坐标),生成能稳定折叠进该骨架的氨基酸序列——是理性设计从结构到实验的关键桥梁:
工具 | 架构 | 亮点 |
|---|---|---|
Structured Transformer | 图Transformer | 首个AI逆向折叠工具,超越Rosetta |
ProteinMPNN | 图神经网络(边更新) | 序列恢复率>50%(vs Rosetta 41.2%),工业标准工具 |
ESM-IF | Transformer + GVP | 利用1200万条AlphaFold 2预测结构扩充训练集 |
LigandMPNN | ProteinMPNN扩展 | 支持小分子、DNA、RNA、金属离子配体的协同设计 |
MPNNsol | ProteinMPNN扩展 | 专门优化溶解性 |
成熟度评估:T4a ⚠️ 进阶;T4b ❌ 初步;T4c ✅ 成熟(工业级部署)
T5. 蛋白质结构生成
T5a. 基于模板的结构设计
利用已有实验结构数据库作为功能基序和骨架模板的来源。MaSIF加速了基于3D几何网络的模板检索,可在PDB数亿条结构中以20–200倍于传统对接的速度完成模板匹配,已成功用于SARS-CoV-2刺突蛋白、PD-1/PD-L1等靶点的de novo结合剂设计。
T5b. 生成式骨架设计
基于扩散模型——从随机3D坐标出发,通过逐步去噪生成满足功能约束的蛋白质骨架:
- • RFDiffusion:在RoseTTAFold基础上引入扩散学习,支持无条件生成(de novo蛋白)和条件生成(功能基序脚手架化、蛋白质结合剂生成、对称寡聚体设计等);
- • Chroma:嵌入可编程"扩散条件器",允许用户通过用户自定义约束(几何特征、功能线索等)引导骨架生成;
- • RFDiffusionAA:全原子扩散模型,将小分子或核酸配体互作直接整合进扩散过程,用于配体结合剂设计。
T5c. 序列–结构协同设计
同时建模骨架和侧链,捕获两者的相互依赖——侧链身份对功能性质有决定性影响:
- • Hallucination / RFDesign:从随机/部分序列出发,通过折叠–评估–突变迭代循环优化序列,已用于活性位点脚手架化、环状寡聚体设计等;
- • BindCraft:将fold-evaluate-mutate循环专门化用于蛋白质结合剂设计;
- • ProteinGenerator:扩散框架内同时去噪氨基酸身份和骨架几何,支持多构象态设计;
- • Protpardelle:全原子模型,在每个残基位置维持所有可能侧链旋转异构体的叠加,连续演化骨架;
- • RFDiffusion2:新一代工具,已用于酶活性位点的原子级别脚手架化。
成熟度评估:T5a/T5b/T5c 均为 ⚠️ 进阶(已有实验验证)
T6. 虚拟筛选
T6a. 结合与功能活性预测
三种层级的虚拟筛选策略:
(i) 开箱即用工具
预测类型 | 代表工具 | 输入模态 |
|---|---|---|
蛋白质–蛋白质结合 | DOVE, DeepRank-GNN | 结构 |
抗体–抗原结合 | IgLM, NetTCR | 序列 |
蛋白质–小分子结合 | GNINA, PSICHIC | 结构/序列 |
蛋白质–核酸结合 | NucleicNet | 结构 |
功能活性预测 | ESM-1v, ProMEP | 序列/结构 |
PSICHIC仅凭序列(蛋白质SMILES)预测蛋白质–小分子结合亲和力,速度和精度均优于或媲美结构依赖方法。
(ii) 少样本定制化
当通用工具对新蛋白/新功能效果欠佳时,用少量标记实验数据精调大模型:
- • FSFP:从蛋白质语言模型初始化,利用公开深度突变扫描数据校准进化约束,再用少量in-house数据精调,实现高效的功能排序;
- • SeekRank:语言模型嵌入+随机森林,少量标注样本即可实现功能预测。
(iii) 实验室闭环(Lab-in-the-loop)
AI预测与实验测量形成迭代反馈循环:
- • EVOLVEpro:语言模型嵌入+随机森林+主动学习,每轮从组合库中选择最具信息量的候选进行实验测试,每批新数据持续精化模型;
- • ALDE:基于主动学习的定向进化框架,通过贝叶斯优化引导采样。
T6b. 可开发性评估
将蛋白质从实验室到实际应用所需的关键物化特性纳入虚拟筛选:
- • 热稳定性:TemstaPro(熔点Tm预测),神经网络预测聚集温度Tagg;
- • 溶解性:DeepSoluE、PLM_Sol(从序列预测溶解性,降低表达失败率);
- • 聚集性:AggreProt(识别易聚集区域);
- • 免疫原性:NetMHCpan-4.1(MHC-肽结合预测,T细胞表位识别);DeepImmuno(肽免疫原性预测);Hu-mAb(抗体人源化序列建议)。
成熟度评估:T6a ✅ 成熟;T6b ❌ 初步(多为in silico验证)
T7. DNA合成优化
功能定位:将设计好的蛋白质序列反向翻译为适合特定宿主的优化DNA序列,最大化表达水平。
密码子使用偏好因物种、基因长度而异,未优化的密码子可能降低翻译效率、引入翻译错误、阻碍实验验证。主要工具:
工具 | 策略 | 覆盖范围 |
|---|---|---|
BiLSTM-CRF | RNN,大肠杆菌数据训练 | 原核生物 |
mBART | Transformer语言模型 | 真核/细菌/人类宿主 |
CodonBERT | BERT + 交叉注意力 | 密码子优化 |
CodonTransformer | 多物种训练(164种生物,近百万对) | 全覆盖,捕获宿主特异性密码子偏好 |
CodonMPNN | 直接从骨架结构优化DNA | 绕过序列中间体,适合理性设计流程 |
Variational Synthesis | 优化实验室合成参数 | 支持宠亿级别(10¹⁷)蛋白质合成,成本降低达万亿倍 |
成熟度评估:⚠️ 进阶(合成成本仍是瓶颈)
5. AI蛋白质设计路线图
论文的核心实用价值在于将上述七大工具包整合为一张可操作的设计路线图,分为库设计和筛选优化两个阶段、共六个步骤。
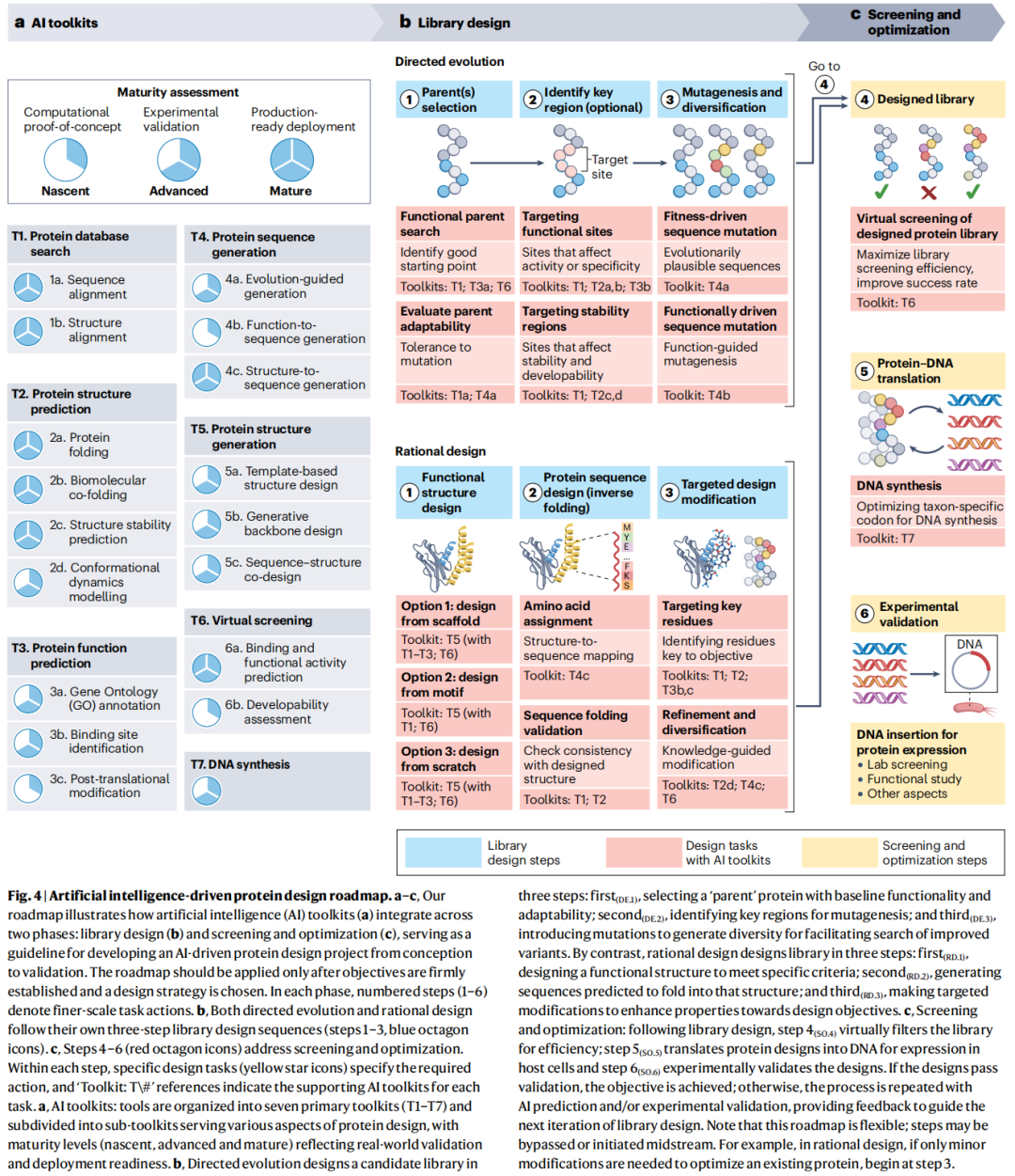
5.1 定向进化路线(DE)
DE.1 亲本蛋白筛选
├── 功能性亲本搜索:T1(数据库检索)+ T3a(GO注释)+ T6(虚拟筛选)
└── 可进化性评估:T1a(序列比对)+ T4a(进化引导生成,评估突变耐受性)
↓
DE.2 关键区域识别(可选,降低搜索空间)
├── 功能位点定位:T1 + T2a,b(结构预测)+ T3b(结合位点识别)
└── 稳定性区域定位:T1 + T2c(稳定性预测)+ T2d(构象动力学建模)
↓
DE.3 突变与多样化
├── 进化适应性驱动突变:T4a(进化引导生成)
└── 功能导向突变:T4b(功能到序列生成)5.2 理性设计路线(RD)
RD.1 功能骨架结构设计
├── 选项1(基于脚手架):在已有骨架上重设计功能位点 → T5(以T1–T3和T6辅助)
├── 选项2(基于基序):从已知活性基序出发构建新骨架 → T5(以T1和T6辅助)
└── 选项3(从头设计):完全从头生成新骨架 → T5(以T1–T3和T6辅助)
↓
RD.2 蛋白质序列设计(逆向折叠)
├── 氨基酸分配:T4c(结构到序列生成)
└── 折叠一致性验证:T1(数据库比对)+ T2(结构预测验证正确折叠)
↓
RD.3 靶向精修
├── 关键残基识别:T1 + T2 + T3b,c(功能/PTM位点)
└── 精修与多样化:T2d(构象采样)+ T4c(序列变体生成)+ T6(虚拟筛选评估)5.3 筛选与优化阶段(共享)
SO.4 → 虚拟筛选候选库(T6):预测结合亲和力、特异性、稳定性、溶解性
SO.5 → 蛋白质–DNA翻译(T7):密码子优化 → 高效合成DNA
SO.6 → 实验验证:湿实验筛选 → 功能研究 → 数据反馈到下一轮设计路线图的设计强调灵活性:步骤可跳过或从中间启动(如优化已知蛋白的活性位点可直接从RD.3开始),两种范式可在同一项目中组合使用。
6. 四大实战案例深度解析
6.1 AAV衣壳的AI驱动定向进化
背景与挑战:腺相关病毒(AAV)衣壳是基因治疗的核心递送载体。传统理性改造受限于结构认知的局限,序列多样性不足,难以有效规避患者体内预存的中和抗体。
AI工作流:
- 1. 亲本:野生型AAV2(首款FDA批准基因治疗药物Luxturna的基础);
- 2. 靶区域:三重对称轴区域28个残基(位置561–588),负责基因组包装和宿主细胞互作;
- 3. 虚拟库:在靶位点进行随机计算突变,生成10¹⁰个AAV2变体序列库;
- 4. AI筛选:定制化CNN+RNN集成模型(T6a)预测衣壳功能性和包装效率,将10¹⁰个候选缩减至201,426个;
- 5. 实验验证:其中110,689个(58.1%)经实验证实为有功能的变体,部分含多达29个突变,全程无需任何结构引导。
意义:证明AI可在无结构信息的情况下生成超越天然血清型多样性的功能性衣壳变体,重塑基因治疗载体工程范式。
潜在改进方向:用进化引导生成(T4a)替换随机突变,进一步提高库的功能密度;引入DNA合成工具(T7)降低实验验证成本。
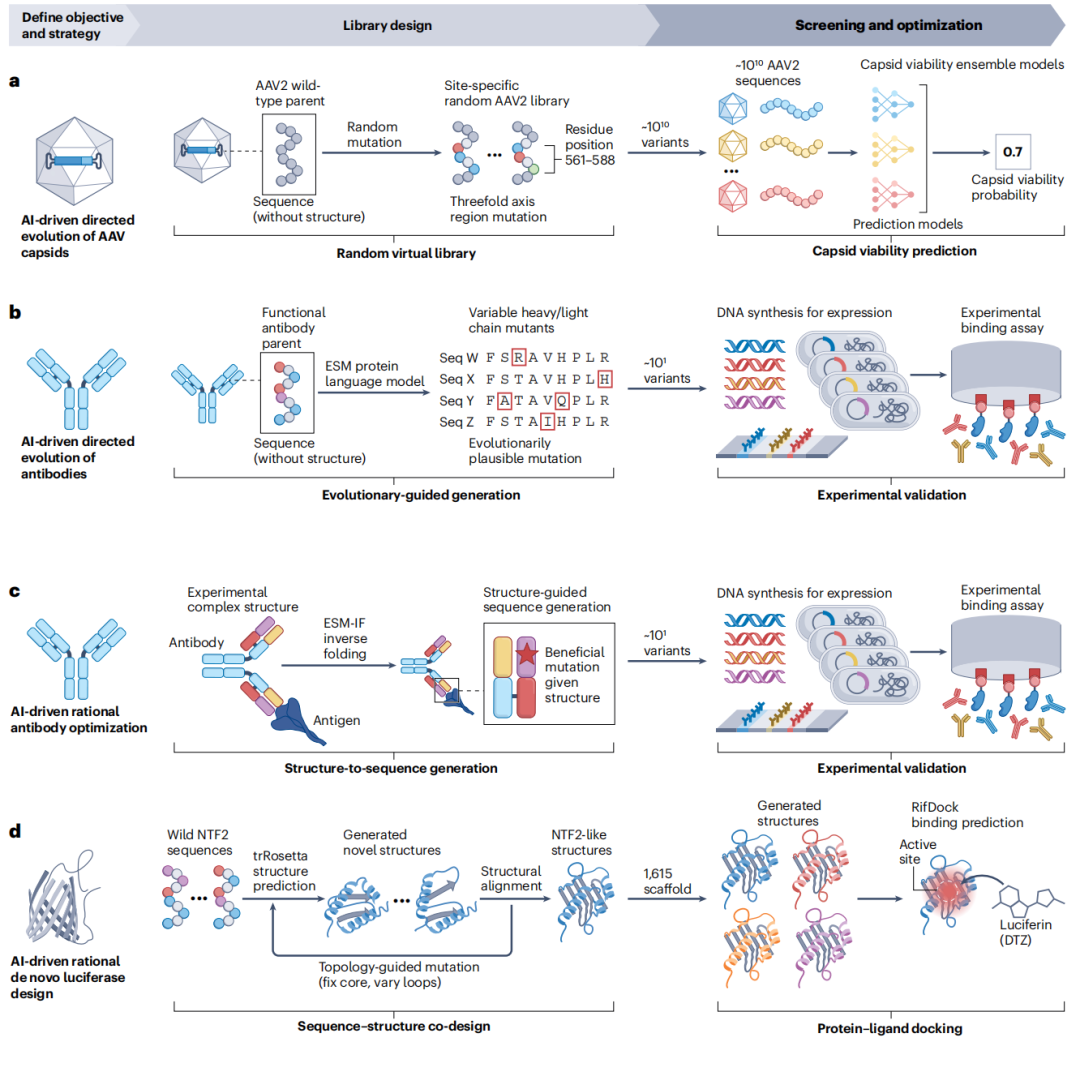

6.2 抗体的AI驱动定向进化
背景与挑战:临床验证的成熟抗体(如抗流感A的MEDI8852、抗埃博拉的mAb114)结合亲和力有限,需要进一步成熟化。
AI工作流(直接从DE.3开始,亲本选择和区域识别已知):
- 1. 突变策略:用ESM蛋白质语言模型(T4a)对可变重链和轻链进行突变,生成进化上可信的候选(非随机突变);
- 2. 注意:ESM模型仅在通用蛋白质序列上训练,并非抗体特异性;
- 3. 结果:仅两轮筛选(每轮实验不超过20个候选),4种高度成熟抗体结合亲和力提升最高7倍,3种未成熟抗体提升最高160倍;
- 4. 泛化性:该工作流已验证对其他蛋白质家族的普适性。
意义:以极小的实验规模实现大幅的亲和力成熟,证明进化引导生成在抗体工程中的高效性,且方法具有普适性。
6.3 基于结构的抗体理性优化
背景与挑战:面对快速进化的新冠变异株(BQ.1.1、XBB.1.5),临床成熟抗体亟需优化。
AI工作流(直接从RD.3开始):
- 1. 结构输入:实验确定的抗体–抗原复合物3D结构;
- 2. 逆向折叠:ESM-IF1(T4c)从实验3D骨架出发,生成预测改善复合物稳定性的突变序列;
- 3. 虚拟筛选:通过预测的结构–序列兼容性评分筛选候选;
- 4. 结果:实验验证前30个突变体,对BQ.1.1和XBB.1.5变异株的结合亲和力最高提升37倍。
意义:展示了将实验结构知识与AI逆向折叠工具结合的范式,可迅速响应变异株出现,是个性化治疗开发的高效框架。
6.4 从头设计荧光素酶
背景与挑战:合成荧光底物二苯基四嗪(DTZ)在生物成像中具有独特优势,但天然蛋白质几乎不能高效催化DTZ发光反应,传统理性设计难以应对这种功能在自然界中无模板可循的挑战。
AI工作流(完整的三步理性设计路线):
第一步(RD.1):功能骨架生成(序列–结构协同设计)
- • 以已知强力DTZ结合的NTF2家族蛋白为参考,从PDB(T1)检索NTF2结构,并用Rosetta(T2a)预测更多NTF2结构;
- • 用trRosetta(T5c)进行"家族级幻觉"(family-wide hallucination)——保持核心折叠拓扑,允许环区自由变化;
- • 产出1,615个具有比天然DTZ结合蛋白更优几何和化学特性的新支架。
第二步(RD.2):序列验证
- • 由于序列与结构协同设计,新序列直接可用;结构预测工具验证折叠一致性。
第三步(RD.3):活性位点精修
- • RifGen(T2d):采样数百万种侧链置位方式围绕结合位点;
- • RifDock(T6a):对每种置位进行配体对接和互作评分,保留最优候选;
- • ProteinMPNN(T4c):进一步精修和多样化候选序列,生成最终设计库;
- • 实验筛选发现多个活性变体;LuxSit 表现突出:熔点**>95°C**(热稳定性极优),对DTZ化学发光反应催化高效且特异。
意义:这是AI驱动de novo蛋白质设计在创造"自然界不存在的功能"方面的标志性案例,全流程整合了T1、T2a、T2d、T4c、T5c和T6a共六个工具包。
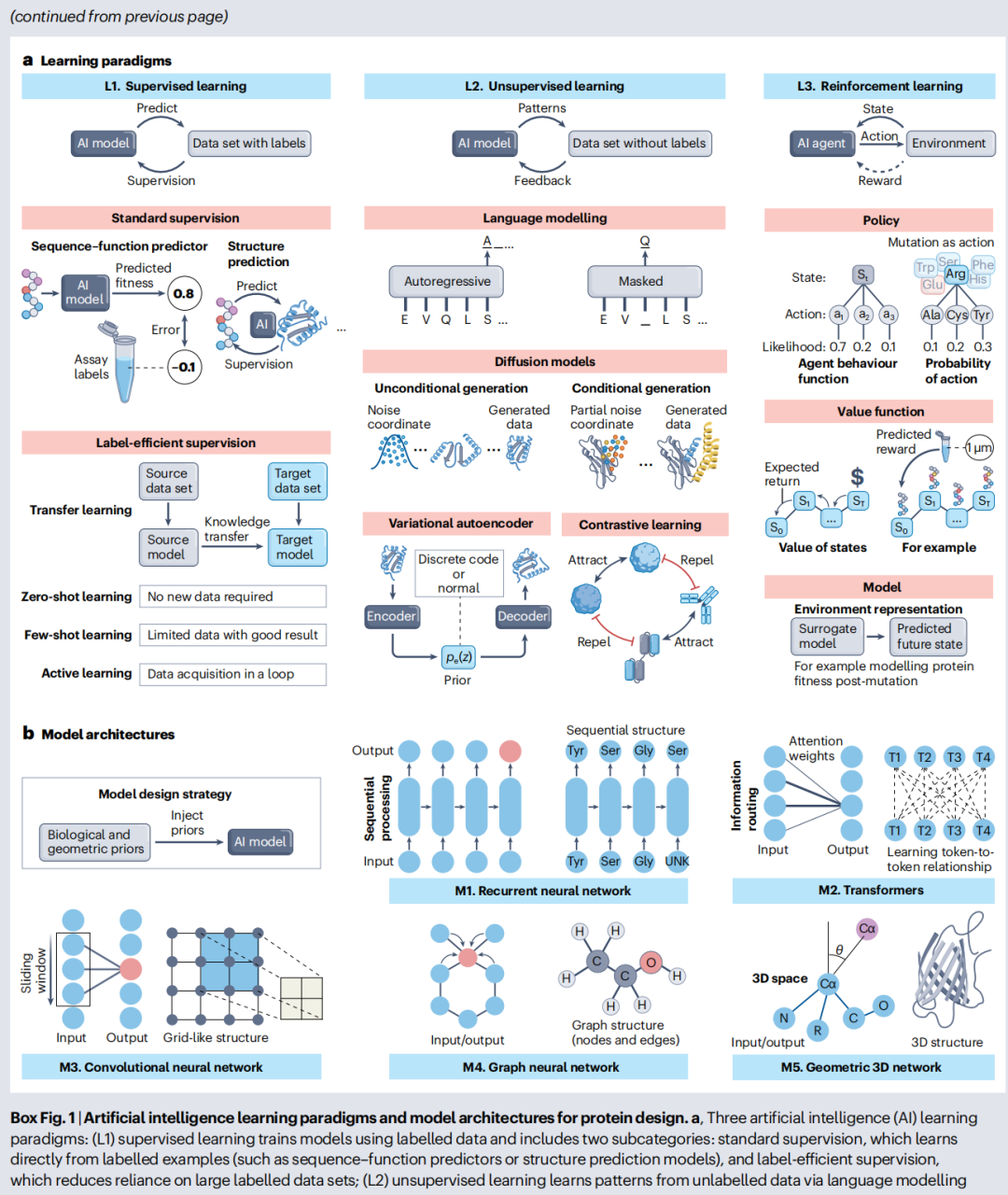
7. AI学习范式与模型架构基础
7.1 三大学习范式
监督学习(L1)
用标注数据(输入–输出对)训练模型。分为标准监督(AlphaFold 2以PDB结构为标签)和标签高效监督:
- • 迁移学习:源域预训练 → 目标域微调(少量标注数据);
- • 零样本学习:无新标注样本即可泛化(ESM-1v零样本预测突变效应);
- • 少样本学习:少量标注样本即达高精度(FSFP少量实验数据精调);
- • 主动学习:迭代选择最具信息量的样本进行标注(EVOLVEpro的主动采样策略)。
无监督学习(L2)
从无标注数据中学习有意义的表示:
- • 语言建模:自回归(预测下一个残基,如UniRep、ProGen)或掩蔽语言模型(预测被遮蔽残基,如ESM系列);
- • 扩散模型:学习反转噪声损坏过程(RFDiffusion从随机坐标去噪生成骨架);
- • 变分自编码器(VAE):学习概率潜空间,VQ-VAE用离散码本压缩数据(Foldseek的结构编码);
- • 对比学习:区分相似与不同样本(蛋白质表示学习)。
强化学习(L3)
AI智能体通过与环境交互学习最优长期策略:
- • EvoPlay:将蛋白质序列视为状态,单位点突变视为动作,用代理模型(AlphaFold 2)提供奖励信号,策略网络迭代优化突变选择;
- • Top-down RL:自上而下设计折叠多聚体结构。
7.2 五大模型架构
架构 | 特点 | 蛋白质设计应用 |
|---|---|---|
M1. 循环神经网络(RNN) | 逐token序列处理,保留历史记忆 | UniRep序列生成;DNA密码子优化 |
M2. Transformer | 自注意力机制,同时建模所有pairwise token关系;擅长长程依赖 | AlphaFold 2进化信号编码;ESM系列;ProteinMPNN序列解码 |
M3. 卷积神经网络(CNN) | 检测局部空间模式,平移不变性 | DeepSite结合口袋预测;AAV案例的功能性分类器 |
M4. 图神经网络(GNN) | 以图结构建模实体关系(残基为节点,互作为边) | ProteinMPNN骨架图;PhiGNet蛋白质功能预测 |
M5. 几何3D网络 | 整合旋转和平移不变性,预测与方向无关 | AlphaFold 2的结构预测模块;MaSIF表面指纹;RFDiffusion骨架生成 |
8. 工具成熟度评估与现实差距
论文对每个子工具包给出了明确的成熟度评级,这对于研究者选择工具具有重要参考价值:
成熟度 | 定义 | 工具包示例 |
|---|---|---|
✅ 成熟(Mature) | 计算概念验证 + 实验验证 + 生产级部署 | T1a, T1b, T2a, T2b, T2c, T4c, T6a |
⚠️ 进阶(Advanced) | 计算概念验证 + 实验验证,但尚未广泛生产部署 | T2d, T3a, T3b, T4a, T5a–c, T7 |
❌ 初步(Nascent) | 主要为计算概念验证,实验验证有限 | T3c, T4b, T6b |
关键观察:
- • 结构预测(T2a/T2b)和数据库检索(T1)已达到工业级成熟度,是整个AI设计流程的基石;
- • 生成式骨架设计(T5b)和序列–结构协同设计(T5c)实验验证充分,但仍在快速迭代;
- • 可开发性评估(T6b)和功能到序列生成(T4b)是当前最需要加强的方向;
- • DNA合成优化(T7)虽有进展,但合成成本和通量仍是整个流程的瓶颈之一。
9. 当前挑战与未来方向
9.1 数据质量与偏差
训练数据的质量直接决定模型的上限。当前主要挑战包括:
- • 进化采样偏差:蛋白质语言模型因生命树不同物种序列采样不均衡而存在系统性偏差;
- • 验证数据代表性不足:不具代表性的验证集会掩盖模型的真实局限,误导开发方向;
- • 关键属性数据稀缺:稳定性和免疫原性的实验数据尤为匮乏,限制了T6b工具的发展;
- • 动态整合新数据:如Chai-1通过引入表位条件约束使预测精度翻倍,展示了动态整合新型实验约束的潜力。
9.2 可解释性黑箱问题
大多数深度学习工具以黑箱方式运作,其设计决策难以解释。这不仅影响研究者对工具的信任,也限制了从AI预测中提取生物物理学洞见的能力。早期探索方向包括:
- • 稀疏自编码器(Sparse Autoencoders):用于发现蛋白质语言模型中的可解释特征(InterPLM),初步展示了窥探模型"思维"的可能性;
- • 可解释机器学习:SHAP值等方法在特定预测任务中的应用。
9.3 结构动力学建模的差距
当前模型在构象动力学方面存在根本性局限:AlphaFold 2和AlphaFold 3的构象采样并不反映热力学Boltzmann分布,对折叠转换蛋白的预测主要依赖训练集记忆。这对于设计依赖多构象态或别构调控的功能蛋白构成重大挑战。
9.4 合成生物学与多功能蛋白设计
当前AI工具在以下复杂场景仍面临挑战:
- • 大型多域装配体:多域蛋白的协调设计,兼顾域间相互作用;
- • 复杂别构网络:设计具有精密信号传导功能的蛋白质,需要建模全局构象变化;
- • 非天然化学骨架:非天然氨基酸或全新化学骨架(非肽键)的蛋白质设计;
- • 遗传网络的整体优化:合成生物学中蛋白质-细胞系统的协同设计,涉及突现行为和细胞背景复杂性;
- • 全蛋白质组设计:基因组语言模型Evo已开始概念化整个蛋白质组的设计,但所产生的蛋白质组尚不具备功能。
9.5 精准治疗的未来图景
在方法论瓶颈逐步突破的基础上,AI蛋白质设计有望开启以下应用场景:
- • "不可成药"靶点:癌症相关蛋白(如KRAS、p53等)缺乏明显小分子口袋,蛋白质-蛋白质相互作用抑制剂和蛋白质降解剂将成为突破口;
- • 个性化治疗:AI加速设计–制造–测试–分析循环,推动针对患者特异性抗原的个体化蛋白质药物;
- • 工业酶工程:极端环境稳定酶、绿色化工催化剂的高效设计;
- • 新材料与生物传感器:具有全新功能的从头蛋白质作为下一代生物材料基础。
10. 对研究者的启示
10.1 如何使用这篇综述
这篇综述最核心的实用价值在于其路线图框架(图4)。建议以如下方式使用:
- 1. 首先明确设计目标:在功能、结构、可开发性三个维度上定义目标,决定采用定向进化还是理性设计策略;
- 2. 按路线图索引工具:根据所处设计阶段(亲本筛选/骨架生成/序列设计/虚拟筛选等),在对应步骤下查找适用工具包;
- 3. 参考成熟度评级:优先选用已有工业级验证的成熟工具,对初步工具保持合理预期;
- 4. 组合使用工具包:案例表明,单一工具包的效果远不如系统组合(如T1+T2+T4c+T5+T6的联合使用);
- 5. 保持迭代意识:AI工具仅提供虚拟筛选,实验验证和数据反馈仍是闭环的不可缺少的组成部分。
10.2 初学者入门路径建议
阶段 | 推荐工具 | 理由 |
|---|---|---|
结构理解 | AlphaFold 2 / ColabFold | 成熟、免费、有界面,是理解蛋白质的起点 |
序列分析 | ESM2嵌入 / pLM-BLAST | 功能强大,API友好 |
逆向折叠 | ProteinMPNN | 工业标准,文档完善 |
骨架生成 | RFDiffusion | 功能最全的骨架生成工具 |
功能筛选 | ESM-1v(零样本)+ 少量实验数据微调 | 低实验成本的起点策略 |
10.3 尚待解决的核心科学问题
- • 如何将AI工具的预测能力与对蛋白质生物物理学的真正理解相结合,而非仅仅依赖统计规律?
- • 如何在构象动力学建模方面实现突破,支持别构调控和动态功能蛋白的设计?
- • 如何建立更具代表性的蛋白质稳定性和免疫原性实验数据集,推动可开发性预测工具的成熟?
- • 如何在不损失泛化能力的前提下,提升AI工具对全新(训练集之外)功能和结构的预测可靠性?
总结
这篇综述的贡献不仅在于梳理了一个快速迭代领域的现状,更在于提供了一套系统化的认知框架和实操指南。随着AlphaFold 3、RFDiffusion 2等新工具持续涌现,这一框架提供的分类逻辑——而非具体工具——将具有更持久的参考价值。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号