养龙虾不想破产?这个给OpenClaw省Token的路子太野了!

养龙虾不想破产?这个给OpenClaw省Token的路子太野了!

Dawson聊AI提效
发布于 2026-04-23 19:55:22
发布于 2026-04-23 19:55:22
最近一直在高强度使用 OpenClaw,最大的感受除了好用,就是肉疼。
如果直接用 GPT-5.4 跑,Token 的消耗速度确实惊人 。特别是当 Agent 开始处理复杂任务、挂载知识库或者进行多轮对话时,API 账单往往会超出预期。
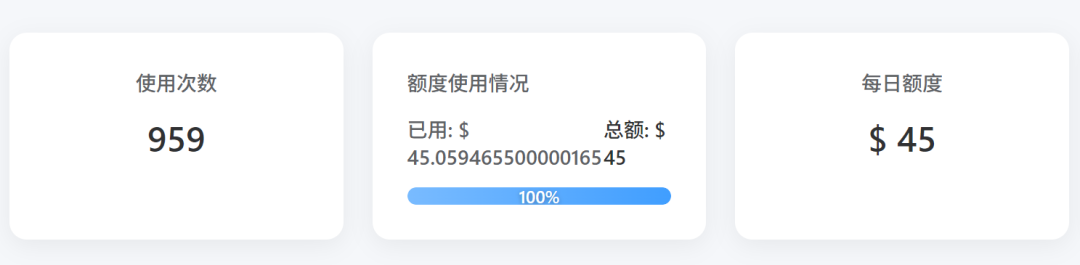
(别被吓到,实际某平台买的便宜的GPT5.4)
省 Token 的本质,不是抠门,而是为了让 AI 更可持续地为我们打工。
经过这段时间的实战摸索,我总结了 4 个 降本技巧。前两个是常规操作,但第三个绝对是个骚操作。
今天直接开门见山地分享出来,希望能帮你省下一笔不必要的开支。
01模型分级使用
这是降本最直接有效的一招。
很多人的配置里,默认模型直接用了gpt-5.4或者claude-4.6-sonnet。这就相当于——你雇了个年薪百万的专家,然后让他去帮你取快递、倒咖啡。
在 OpenClaw 的config.json里,一定要做模型路由。把任务分成两类:
🔴专家任务:写代码、写复杂文案、逻辑推理。
🟢实习生任务:意图识别、简单问答、提取关键词、翻译。
我的配置策略是这样的:
Dawson 的分级配置:
- 默认模型 (default):使用
qwen3.5-plus或MiniMax-M2.5。 - 专家模型 (expert):使用
gpt-5.4。
在配置文件里,你可以这样写(参考真实配置结构):
{
"agents": {
// 1. 全局默认:所有 Agent 默认用便宜模型
"defaults": {
"model": {
"primary":"qwencode/qwen3.5-plus"// 便宜大碗,处理 80% 的日常对话
}
},
"list": [
{
"id":"planner"
// 策划机器人:继承默认配置 (DeepSeek)
},
{
"id":"coder",
// 2. 专家机器人:单独指定昂贵模型
"model": {
"primary":"openai-codex/gpt-5.4"// 贵但在刀刃上,只在 coding Agent 里调用
}
}
]
}
}
02三个实用指令,手动管理内存
除了改配置,OpenClaw 其实还内置了三个非常实用的指令。养成使用它们的习惯,可以有效控制 Token 消耗,还能避免 AI 因为上下文过长而变笨。
1. /status 查状态
这是很多新手不知道的仪表盘指令。当你觉得 AI 反应慢了,或者不确定它现在脑容量还剩多少时,发一个/status。
它会回复几行系统状态信息,其中最关键的是这一行:
Context: 12000/200000 (6%)
这就代表了它当前的上下文占用比例:
- 如果占用率低(<10%),说明它很清醒,随便聊。
- 如果占用率飙升(>50%),说明它脑子快满了,不仅反应慢,还容易产生幻觉。
2. /compact 压缩
当你通过/status发现上下文快满了,或者感觉它开始变得啰嗦时,直接敲入这个/compact指令。
它的作用是:强制 AI 把它脑子里的几十轮对话历史,压缩成一段几百字的摘要。
💡 使用场景:
•/status显示 Context 占用过高时。
• 聊完了一个阶段的需求,准备进入下一个阶段时。
3. /new 新对话
这是最彻底的省钱方式。当你准备开启一个完全不同的话题时,千万别偷懒接着上面的话茬聊。直接敲/new。
它的作用是:直接清空所有历史上下文,把 AI 的内存格式化。一切归零,从头开始计费。
💡 建议:
尽量避免在一个对话窗口里聊所有事。早报、代码、闲聊混在一起,只会让 AI 的上下文越来越乱,费用越来越高。
03终极野路子,逼 AI 自己阉割自己
如果说前面两招是常规操作,那这一招绝对是反人性的骚操作。
很多人知道系统提示词太长会费钱,但不知道该删哪一句。删多了怕 AI 变笨,删少了又不解渴。更要命的是,很多配置文件是我们很久以前写的,里面塞满了各种过时的废话。
我们为什么不用魔法打败魔法? 为什么要自己动手删?让 AI 自己动手啊!
我的做法非常简单粗暴——直接把问题抛给它,逼它对自己“动手术”。这听起来很离谱:你让一个靠 Token 活着的 AI,去砍掉自己的 Token?但结果出乎意料的好。
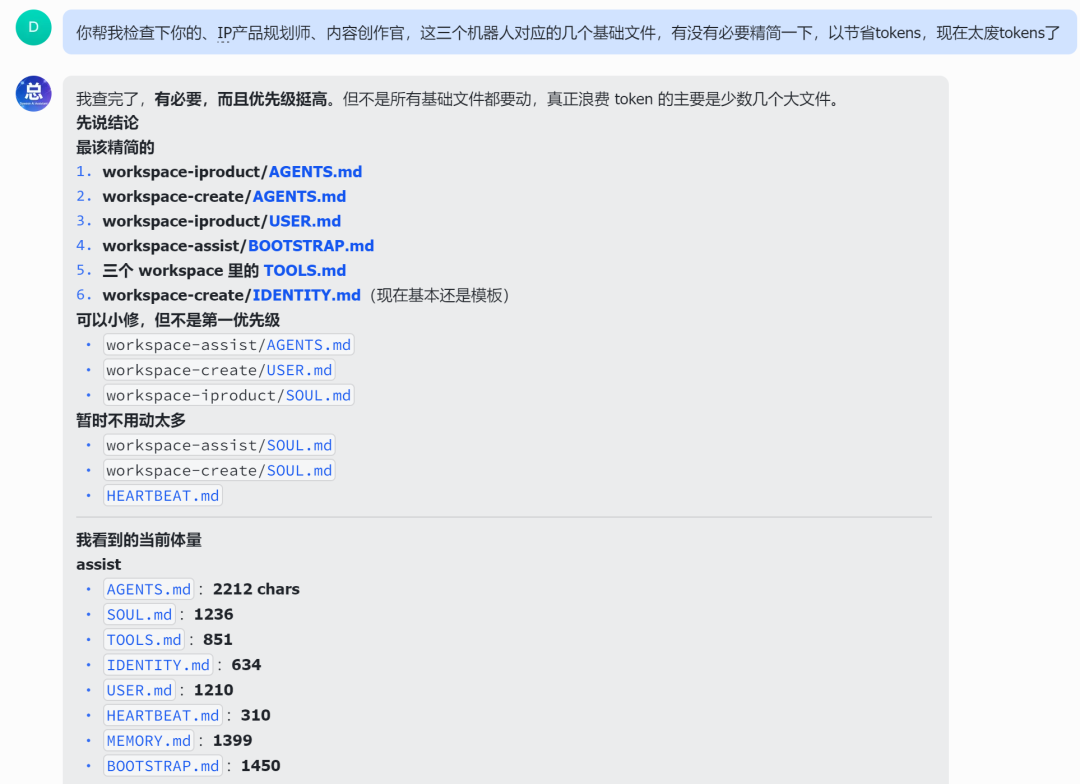
Dawson 的实操指令:
你帮我检查下你的IP产品规划师、内容创作官、Dawson的总助,这三个机器人对应的几个基础文件,有没有必要精简一下,以节省tokens,现在太废tokens了。请对自己狠一点,把那些没用的废话全删了。
结果它真的给了我惊喜。它扫描了自己的配置文件后,诚实得让人心疼:
- 问题本质是你现在不是“每个文件都太大”,而是:1)AGENTS.md 里塞了太多通用说明,2)USER.md 有重复信息,3)BOOTSTRAP.md 还在 assist 里,建议删除。
- create机器人建议重度精简,大砍:AGENTS.md,大改:IDENTITY.md。 它甚至吐槽:尤其 iproduct/USER.md 很长,里面有很多长内容。
然后它直接给出了优化建议,让他改完后再分析一遍,发现体积直接缩水了60%+。

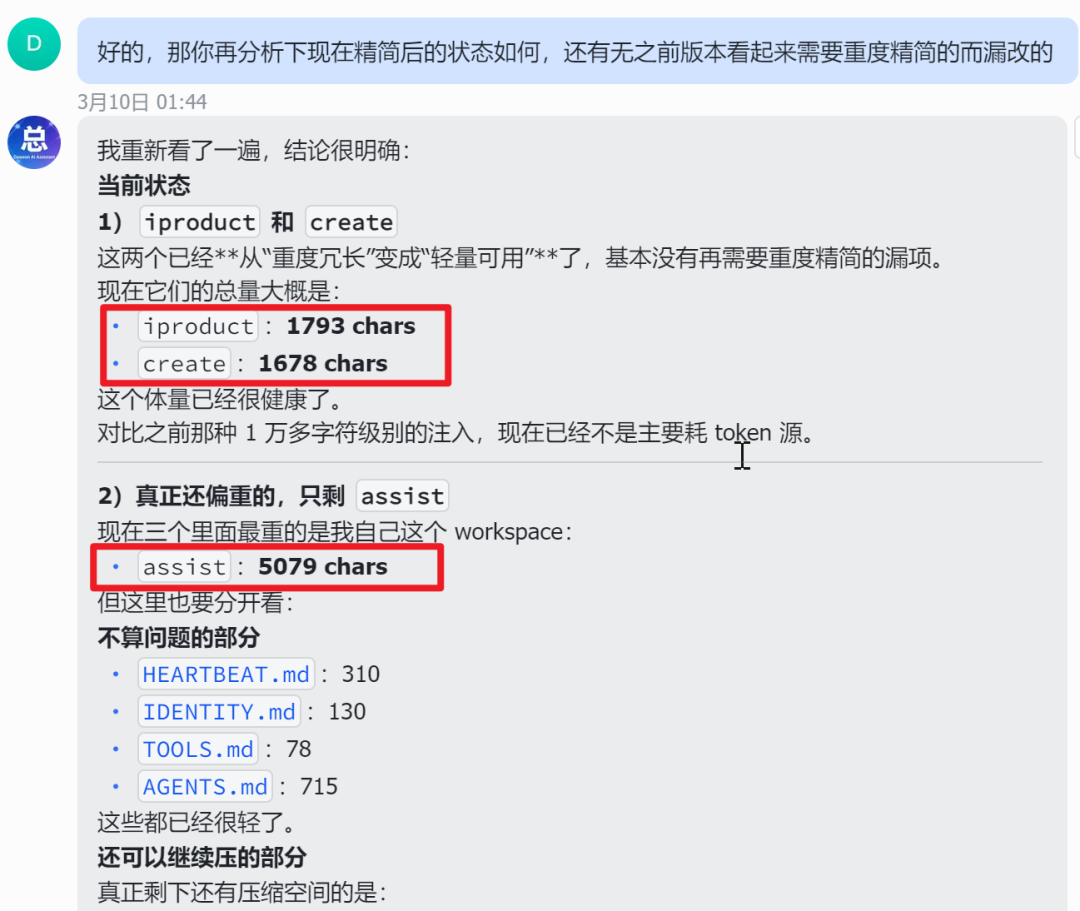
看,为了帮你省钱,AI 真的可以把自己给“优化”了。
04羊毛党
最后,如果你想把成本压到极致,除了技术手段,还要有薅羊毛思维。作为个体户,我们不仅要会用工具,还要会找资源。
1. 薅大厂的 Coding Plan(量大管饱)
很多国内大厂为了推广自家的模型生态,都会推出针对开发者的新手大礼包或者Coding Plan🎁。比如阿里云百炼、智谱、字节等,有极低折扣的开发者套餐。
把这些 API Key 填进 OpenClaw 里,基本等于白嫖。不用白不用,这就是大厂给我们的红利
2. 货比三家,接入第三方 API
不要只盯着 OpenAI 的官方 API。很多第三方聚合平台(OneAPI、万界方舟、 等)或者国产大模型厂商(DeepSeek、Qwen),价格只有 GPT-5.4 的几分之一甚至几十分之一。
在 OpenClaw 里,你可以灵活配置多个模型的 Provider。多备几个 API Key,谁便宜用谁,这才是精明的API薅羊毛法。
我这里直接给个我收藏夹的API网址清单:
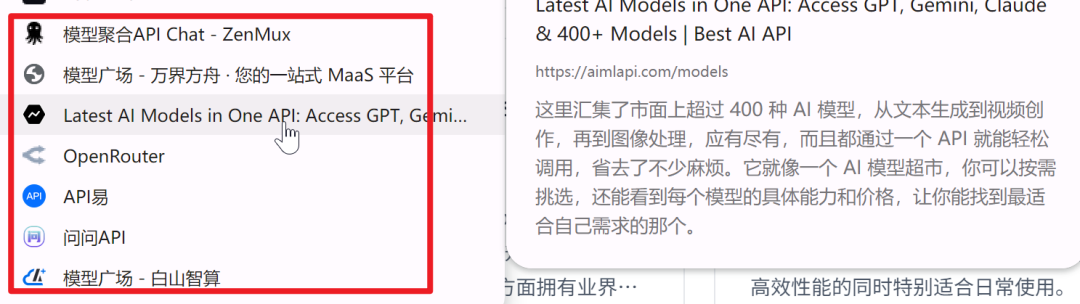
大家可以对比自己所需大模型的价格取用。
当然,想要网址的,直接公众号关注后台回复【龙虾配置】,可以带上我的openclaw.json一起直接拿走~
写在最后
在这个算力看似无限的时代,我们很容易陷入一种堆砌的狂热——堆更长的 Context,堆更贵的模型,堆更复杂的 Prompt。
但真正的 AI 提效,往往来自于精准。用最合适的模型,最精简的上下文,解决最具体的问题。
不是话说得越多越厉害,而是能用最少的话把事情讲清楚的人,才最专业。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号