存量用例太多是垃圾?用AI做"减法",自动识别冗余与无效功能用例

存量用例太多是垃圾?用AI做"减法",自动识别冗余与无效功能用例

AI智享空间
发布于 2026-04-21 21:01:19
发布于 2026-04-21 21:01:19
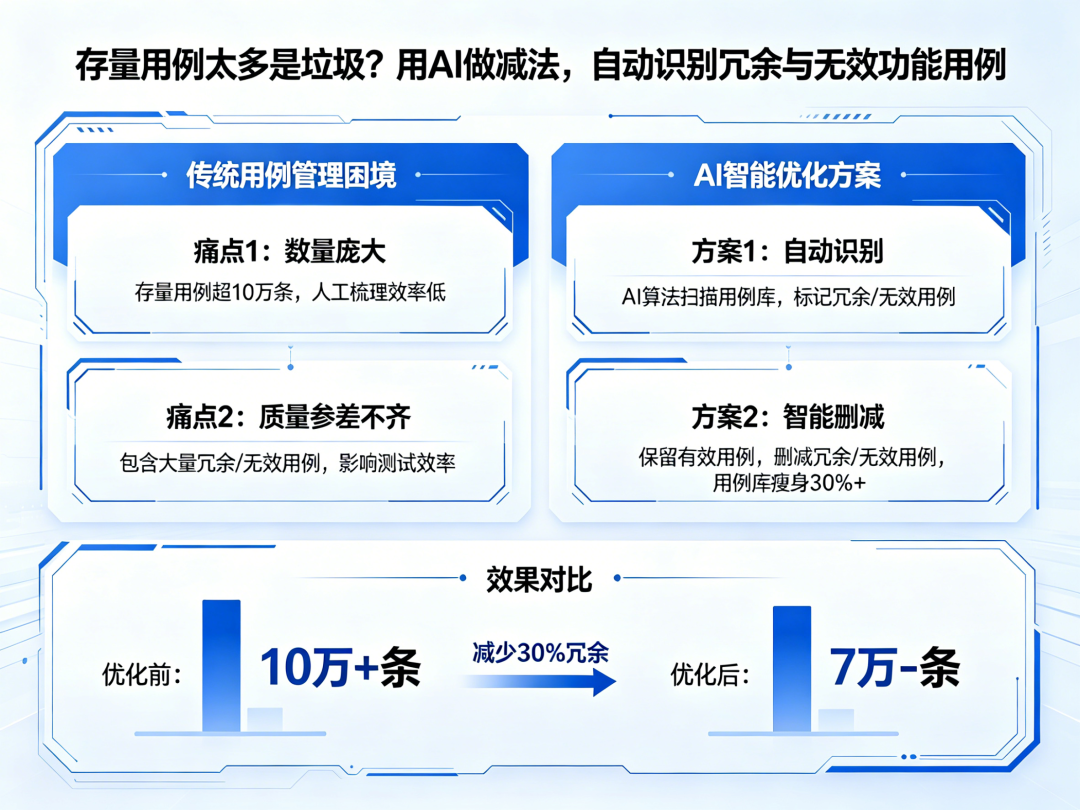
每个经历过产品迭代的技术团队都会面临一个共同的困境:测试用例库越来越庞大,执行时间越来越长,但质量问题依然层出不穷。打开用例管理平台,几千甚至上万条用例躺在那里,没人敢删,也没人真正搞清楚哪些还有用。
这背后藏着两种截然不同的管理思维:一种是“堆积型管理”——新功能上线就加用例,旧功能下线不敢删,抱着“宁可错杀,不可放过”的心态让用例库无限膨胀;另一种是“精益型管理”——把测试用例当作需要持续维护的技术资产,用数据和智能化手段识别真正有价值的部分,让测试投入产出比最大化。前者看似稳妥,实则是用战术上的勤奋掩盖战略上的懒惰;后者看似冒险,实则是用系统性思维构建可持续的质量体系。
本文将从三个维度展开对比分析:从“不敢删”到“敢删对”的决策思维、从“人工筛”到“AI识别”的技术路径、从“追求全”到“追求准”的目标导向,探讨如何用AI技术解决存量用例治理这个老大难问题。
目录
- 决策思维:从风险规避到价值判断
- 技术路径:从人工盘点到智能识别
- 目标导向:从覆盖率到有效性
- 行动指南:如何启动你的用例瘦身计划
一、从风险规避到价值判断
堆积型管理者的典型特征
“这个功能虽然没人用了,但万一哪天又要呢?”、“删掉后出了问题谁负责?”——这是堆积型管理者的口头禅。他们习惯于通过增加投入来降低风险,测试用例从200条涨到2000条,回归测试从2小时延长到2天,团队加班加点执行用例,却发现线上该出的问题还是会出。
某金融科技公司的案例很典型:产品经历了5年迭代,积累了8000+功能用例。测试经理每次都要求“全量回归”,结果是一轮回归需要一周时间,期间版本无法发布。更讽刺的是,统计显示近两年发现的线上问题中,有78%是新增功能或改动逻辑引发的,而这些问题恰恰在那8000条“全量用例”的盲区之外。
精益型管理者的破局之道
精益型管理者会问三个问题:这条用例覆盖的功能是否还存在?、这条用例在过去一年抓到过bug吗?、如果删掉这条用例,风险敞口有多大?他们明白,测试资源永远是稀缺的,与其把时间浪费在重复执行无效用例上,不如聚焦到真正有风险的地方。
一家电商平台的测试负责人用数据说话:通过分析近三年的用例执行记录和缺陷关联数据,他们发现40%的用例从未发现过问题,25%的用例覆盖的功能已经下线或重构。基于这个洞察,他们大胆删除了3200条冗余用例,回归时间从5天压缩到1.5天,而线上问题率反而下降了——因为省出来的时间被投入到了风险更高的新功能测试中。
核心差异在于:堆积型思维用“数量”对抗不确定性,精益型思维用“精准度”管理风险。前者是防御性的、被动的,后者是进攻性的、主动的。
二、从人工盘点到智能识别
人工盘点为何总是失败
很多团队尝试过人工清理用例库:开个会,拉个表,让大家认领自己负责的模块,标注哪些可以删。结果往往是雷声大雨点小——会议上大家都说“这个可以删、那个要保留”,真到执行时,因为害怕背锅,最后删掉的用例寥寥无几。
更要命的是信息不对称:写用例的人早已离职,现在的测试人员看着三年前的用例描述,根本不敢判断是否还有效;产品经理记不清某个边缘功能是否已下线;开发说“代码里还有这段逻辑”,但实际上已经被配置开关永久关闭了。
AI识别的三个核心能力
AI在用例治理上的价值,不是简单的关键词匹配,而是多维度的关联分析:
1. 代码-用例关联分析通过静态代码分析,将测试用例描述中的功能点与代码库中的方法、类、模块建立映射关系。如果某个用例关联的代码已被删除或标记为废弃(deprecated),这条用例大概率已失效。某互联网公司用这个方法识别出1200条“僵尸用例”,准确率达到89%。
2. 执行日志智能分析AI可以分析历史执行记录,识别出那些“永远通过”或“从不执行”的用例。前者可能是测试逻辑过于宽松,后者可能是被跳过或遗忘。同时,通过分析用例执行的时间趋势,能发现那些执行频率逐步降低的用例——这往往是功能重要性下降的信号。
3. 缺陷关联价值评估真正有价值的用例,应该在历史上发现过问题,或者覆盖的是高风险功能。AI可以分析每条用例的“产出率”:发现过几个bug、bug的严重程度如何、距离上次发现问题过了多久。某团队用这个维度评估后发现,80%的有效缺陷是由20%的核心用例发现的,这为精简方向提供了明确指引。
实施案例:某SaaS公司用开源大模型+私有化部署方案,输入了用例库、代码仓库、缺陷管理系统的数据,AI在3小时内完成了对6500条用例的评估,给出了明确的分类:22%高价值保留、35%可删除、43%需人工复核。团队花了两周完成复核和清理,用例库瘦身58%,回归效率提升3倍。
三、从覆盖率到有效性
覆盖率崇拜的陷阱
“我们的用例覆盖率达到了95%!”——这是很多测试团队向上汇报时的高光时刻。但没人追问:覆盖的是什么?、这95%里有多少是真实有效的?
覆盖率崇拜会导致两个恶果:一是为了数字好看而堆砌低价值用例,比如把一个登录流程拆成10个细粒度用例,看起来覆盖很全,实际上都在测同一段逻辑;二是忽视真正的风险盲区,比如复杂的异常场景、并发冲突、边界条件,这些难写难维护的用例反而被搁置。
有效性优先的新标准
精益型团队会建立新的度量体系:
- 缺陷发现率:每100条用例在过去一年发现了多少有效bug
- 风险覆盖度:核心业务流程、高频功能、历史问题多发区域的用例占比
- 执行投入产出比:用例执行耗时与发现问题价值的比值
- 用例鲜活度:用例的更新频率与代码变更频率的匹配度
某支付平台用“有效性评分”替代覆盖率考核后,团队行为发生了明显变化:测试人员不再追求“写满用例库”,而是主动分析哪里是风险点,集中火力设计高质量用例。三个月后,用例总数下降了30%,但新版本上线后的问题拦截率提升了40%。
本质区别在于:覆盖率是数量导向,容易陷入“为了指标而指标”的形式主义;有效性是价值导向,逼迫团队思考每一份投入是否真正降低了风险。
四、如何启动你的用例瘦身计划
认识到差异后,如何迈出实质性的第一步?这里不是让你在两种模式之间做选择题,而是提供一条从堆积到精益的演进路径:
1. 建立用例健康度看板不要上来就删用例,先让问题可视化。统计你的用例库里有多少条用例超过一年未更新、多少条从未发现过问题、多少条执行时间超过10分钟。把这些数据贴在墙上,让团队直观感受到“垃圾”的规模。
2. 小范围试点,建立信心选一个边缘模块或已下线功能做试点,用AI工具或人工方式清理一遍,观察三个月内是否出现问题。成功案例会打消团队的恐惧心理,为后续大规模推进积累经验。
3. 用AI辅助,但人机结合AI的价值是快速筛查和建议,但最终决策权要留给熟悉业务的人。建议采用“AI识别+人工复核+灰度删除”的三步走:AI给出分类建议,测试专家复核争议用例,先做逻辑删除观察一段时间再物理删除。
4. 配套机制调整把“用例有效性”纳入绩效考核,别让测试人员觉得“删用例是在否定自己的工作”。同时建立定期review机制,每季度审视一次用例库健康度,让瘦身成为常态而非运动式整改。
结语
从“不敢删”到“敢删对”,从“堆积”到“精益”,这不是一夜之间的革命,而是技术管理思维的逐步进化。那些真正优秀的团队,早已不再用用例数量证明自己的专业性,而是用更少的用例抓住更多的问题,把省下来的时间投入到真正有价值的探索性测试和风险分析中。
AI不是魔法,它解决不了所有问题,但它能成为你打破“不敢动存量”这个心理障碍的有力工具。当你开始用数据说话、用价值导向替代数量导向时,你已经走在了从测试执行者到质量架构师的转型路上。真正的专业,不是拥有最多的测试用例,而是始终知道哪些测试最重要。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号