palantir深度解析(八)
原创

Palantir Foundry 虚拟表
一、虚拟表的核心本质与架构价值
1. 架构图的核心含义
文档开篇的核心定义:虚拟表允许你直接查询外部源系统的表,无需先把数据同步、存储到Foundry的数据集中。
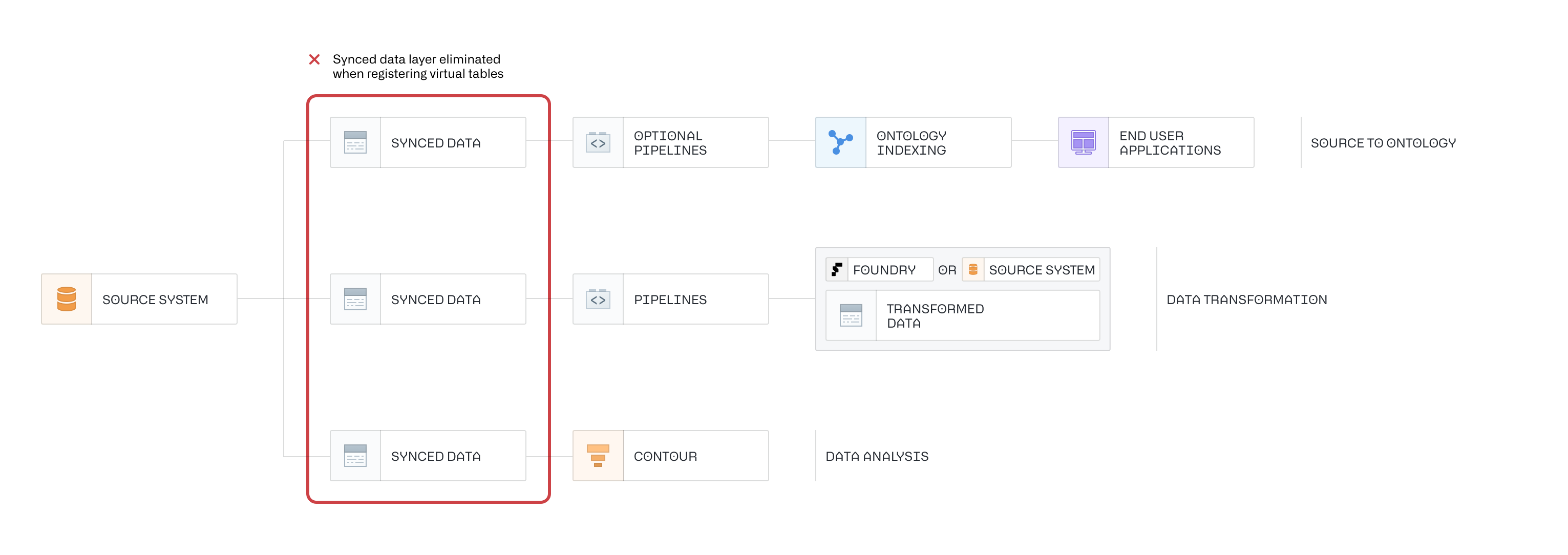
架构图里的红框Synced data layer eliminated,就是虚拟表最核心的突破:
- 传统Foundry数据链路:必须先把源系统的数据全量/增量同步到Foundry,生成物理的「Synced Data同步数据集」,才能做后续的分析、流水线、Ontology建模;
- 虚拟表链路:直接干掉了「同步数据层」,它只是一个指向源系统表的逻辑指针/快捷方式,不存储任何源数据,使用时直接实时查询源系统的最新数据,链路大幅缩短、无重复存储成本。
2. 架构图里的三条核心业务链路
虚拟表完整覆盖了Foundry的三类核心数据工作流,无需提前同步数据:
图
链路类型 | 传统模式 | 虚拟表模式 | 对应文档能力 |
|---|---|---|---|
Source to Ontology(业务应用链路) | 源系统→同步数据→可选流水线→Ontology索引→终端应用 | 源系统→(可选流水线)→Ontology索引→终端应用 | 支持通过Pipeline Builder基于虚拟表创建Ontology对象,直接支撑业务应用 |
Data Transformation(数据加工链路) | 源系统→同步数据→流水线→Foundry内变换数据 | 源系统→流水线→变换计算(可下推到源系统执行) | 支持Pipeline Builder/Code Repositories作为输入,查询逻辑可下推到源系统,减少数据传输 |
Data Analysis(探索分析链路) | 源系统→同步数据→Contour交互式分析 | 源系统→Contour直接分析 | 原生支持Contour直接基于虚拟表做探索分析,无需等待数据同步 |
3. 架构图里的关键细节
图中变换环节的FOUNDRY OR SOURCE SYSTEM,对应文档里的查询下推能力:虚拟表的计算逻辑可以直接推送到源系统(比如Snowflake)执行,只把最终计算结果传回Foundry,大幅减少跨系统的数据传输量,提升查询效率。
二、虚拟表实操配置全流程
文档明确:所有虚拟表的配置、注册,都在「数据连接(Data connection)」应用中完成,这和你之前学习的同步数据集的连接体系完全打通。下面按「自动注册→手动注册」的实操顺序,结合截图完整拆解。
(一)自动注册:全库级批量持续注册
文档定义:自动注册会定期扫描源系统,把有权限访问的所有表,自动注册到Foundry的指定项目中,文件夹结构完全镜像源系统,源系统新增表时会自动同步注册,适合大规模表的批量接入。
1. 自动注册的启用与配置
这是自动注册的初始化配置页面,完全对应文档的规则:
- Project details:设置自动注册生成的托管项目的名称、描述,文档明确「启用自动注册会创建一个新的Foundry项目」;
- Access权限配置:设置项目的默认访问角色(这里是
Tables Viewer),对应文档里的「启用自动注册时可以设置项目的权限和访问控制,后续可通过项目访问面板管理」; - 前置要求:文档明确「启用自动注册必须拥有Foundry的项目创建权限」,和界面要求完全匹配;
- 右上角
Enable按钮:点击后正式启用自动注册,开始扫描源系统表。
2. 自动注册的管理面板
这是Snowflake连接的「Virtual tables」标签页,是虚拟表的核心管理入口,对应文档的所有注册规则:
- Auto-register virtual tables模块:显示自动注册已启用(
Disable按钮表示当前已开启),同时明确了自动注册的输出项目路径,对应文档里的「表会自动注册到这个文件夹中」; - Virtual tables列表:显示自动注册生成的所有虚拟表,比如
CUSTOMER、ORDERS、REGION等,路径完全镜像Snowflake源系统的库/表结构,和文档里的「项目文件夹层次结构反映源系统结构」完全一致。
3. 自动注册生成的托管项目
这是自动注册完成后,Foundry自动创建的托管项目,完全遵循文档的硬规则:
- 项目名称、描述和你在截图4里配置的完全一致;
- 项目内的
SNOWFLAKE_SAMPLE_DATA文件夹,1:1镜像了Snowflake源系统的数据库结构,对应文档的「自动镜像源系统结构」; - 文档明确的硬规则:该项目由Foundry管理,用户无法在其中手动创建/更新资源,只能把里面的虚拟表引用到其他业务项目中使用,界面里没有手动新建的入口,完全符合规则;
- 右侧权限面板:显示你拥有
Tables Owner角色,可对项目权限做后续管理,对应文档的权限配置规则。
自动注册的关键注意事项
- 源系统中新建表:会被定期扫描,自动注册到Foundry项目中;
- 源系统中删除表:Foundry里的虚拟表不会自动删除,但访问时无法加载任何数据;
- 自动注册的项目是只读托管的,所有修改必须在源系统中完成,Foundry仅做同步注册。
(二)手动注册:单表精准注册
文档定义:所有支持虚拟表的数据源都支持手动注册,你可以浏览源系统的表,选择单个需要的表注册到Foundry中,适合仅需使用少数几张表的精准场景。
截图3是CUSTOMER表的手动注册配置页面,完全对应文档里的虚拟表核心组成:
- Configuration配置区:对应文档里的「表定位器」,是虚拟表的核心组成之一,唯一标识源系统里的目标表:
Database:源系统的数据库名SNOWFLAKE_SAMPLE_DATA;Schema:源系统的Schema名TPCH_SF1;Table:源系统的表名CUSTOMER; 这三个参数,精准定位了Snowflake里的目标表,是虚拟表能找到源数据的核心。
- Confirm location of virtual table:对应文档里的「自定义注册位置」,你可以选择虚拟表在Foundry里的存放项目/文件夹,也可以使用连接里配置的默认位置。
- 右上角
Register table按钮:点击后完成注册,生成虚拟表,和普通数据集一样可在Foundry中使用。
三、虚拟表的核心定义与基础规则
1. 虚拟表的核心本质
虚拟表是Foundry指向外部源系统表的逻辑指针,它不会把源数据复制、存储到Foundry中,仅保存两个核心信息:
- 源系统连接:通过「数据连接」应用建立的源系统访问配置,包含源地址、加密存储的访问凭证,用户无需直接接触源系统账号密码;
- 表定位器:数据库+Schema+表名,唯一标识源系统里的目标表。
数据库 + Schema + 表名 完整通俗讲解
这是企业级关系型数据库(比如你截图里用的Snowflake,还有SQL Server、PostgreSQL、Oracle等)里,唯一锁定一张数据表的「三层地址定位器」,本质就像你寄快递要写的「国家→省份→详细门牌号」,或是找公司员工要写的「公司→部门→员工姓名」,只有把三层信息写全,系统才能精准找到你要的那张表,不会找错、不会冲突。
同时,这也是你之前在Foundry里注册虚拟表时,必须填写的三个核心参数——它就是文档里说的「标识源系统中表的定位器」,Foundry靠这三个信息,精准找到Snowflake里的目标表。
下面我们逐层拆解,同时100%对应你之前的Snowflake操作截图,让你完全对应上自己的实操。
一、第一层:数据库(Database)
核心定义
数据库是整个数据体系里最大的顶层容器/顶级文件夹,是数据隔离的最大单元,用来拆分完全独立的业务、环境、项目。
大白话理解
就像你电脑里的「C盘、D盘」,或是不同的大项目文件夹。企业里通常会按这个维度做最彻底的隔离,比如:
按环境拆分:生产库、测试库、开发库,互不干扰;
按业务拆分:销售业务库、财务业务库、供应链业务库,完全独立管理。
对应你的实操截图
你截图3里的SNOWFLAKE_SAMPLE_DATA,就是Snowflake里的一个顶层数据库,它是Snowflake官方提供的样例数据总容器,所有测试样例表都放在这个数据库里。
二、第二层:Schema(模式/架构)
核心定义
Schema是「数据库」下面的二级容器/子文件夹,是企业里做细粒度数据分类、权限管控的核心单元,也是避免表名冲突的关键设计。
大白话理解
就像你D盘下面的「工作文档」「私人文件」「项目资料」子文件夹,把同一个顶层数据库里的表,再按业务模块、团队、数据类型做更精细的拆分。
核心作用
分类管理:同一个销售业务库下面,可以拆分客户数据Schema、订单数据Schema、渠道数据Schema,让表的分类更清晰;
细粒度权限管控:可以给销售团队只开放「客户数据Schema」的查看权限,不给财务相关Schema的权限,实现最小权限管控;
避免表名冲突:销售部和财务部都需要一张叫user的表,放在不同Schema里就不会重名冲突,系统可以精准区分。
对应你的实操截图
你截图3里的TPCH_SF1,就是SNOWFLAKE_SAMPLE_DATA数据库下面的一个Schema,它里面放的是TPC-H标准测试数据集(缩放因子1的版本),所有客户、订单、供应商相关的样例表,都放在这个Schema里。
三、第三层:表名(Table Name)
核心定义
表名是Schema下面实际存储数据的最小单元,就是我们常说的二维表格,它有固定的表头(字段/列),一行行存储具体的业务数据,是我们最终要查询、使用的对象。
大白话理解
就是子文件夹里的具体Excel文件,文件里有固定的列标题,每一行是一条具体的业务数据。比如「客户信息表」里,有客户ID、姓名、电话、地址这些列,每一行对应一个客户的完整信息。
对应你的实操截图
你截图3里的CUSTOMER,就是TPCH_SF1Schema下面的客户表,里面存储了客户编号、姓名、地址、电话、账户余额等具体的客户明细数据,也是你最终要注册成Foundry虚拟表的目标表。
四、为什么必须把三者拼在一起?「全限定名」的核心作用
只有把「数据库名.Schema名.表名」三者完整拼在一起,才是这张表的唯一绝对地址(全限定名),系统才能精准锁定目标表,不会找错。
举个例子
你只说要查CUSTOMER表,系统会懵:
是SNOWFLAKE_SAMPLE_DATA数据库里的,还是你自己建的业务库里的?
就算是SNOWFLAKE_SAMPLE_DATA数据库里的,是TPCH_SF1Schema里的,还是TPCH_SF10Schema里的?
只有写全SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER,系统才能100%精准找到你要的那张表,不会出现重名冲突、找错数据的问题。
对应你的Foundry虚拟表场景
你之前学的文档里说「虚拟表由源系统连接 + 表定位器定义」,这个表定位器,就是「数据库+Schema+表名」。 Foundry就是靠这三个参数,告诉Snowflake:我要查询的是哪个顶层数据库、哪个二级Schema、哪张具体的表,就像快递员靠完整地址精准送货,Foundry靠这个完整地址精准对接源表,注册成虚拟表。
补充:不同数据库的细微差异
这个三层结构是Snowflake、SQL Server、PostgreSQL、Oracle等企业级数据库的通用标准;但像MySQL这类轻量数据库,做了简化,没有单独的Schema层,用「数据库名.表名」两层结构就能唯一定位表(MySQL里的数据库,就等价于其他数据库里的Schema)。
你当前使用的Snowflake,是严格的三层结构,所以必须填全数据库、Schema、表名三个参数,才能正确找到表。
当你查询虚拟表时,Foundry会通过连接实时向源系统发起查询,把结果返回给你,全程无需数据搬迁、无重复存储。
2. 权限与安全规则
文档明确:和Foundry里的所有资源一样,虚拟表受Foundry统一的安全与权限模型管控:
- 你可以给不同用户/用户组配置虚拟表的查看、使用、管理权限;
- 源系统的访问凭证统一加密存储在数据连接中,普通用户无需接触,避免凭证泄露;
- 所有对虚拟表的查询操作,都会在Foundry中留下完整的审计日志,满足企业合规要求。
3. 支持的数据源
文档明确了虚拟表的支持范围,和你截图里的Snowflake完全匹配:
数据源类型 | 具体源 | 手动注册 | 自动注册 | 支持的格式 |
|---|---|---|---|---|
云原生数仓 | Snowflake | ✅ | ✅ | 表、视图、物化视图 |
云原生数仓 | BigQuery | ✅ | ✅ | 表、视图、物化视图 |
云对象存储 | Amazon S3 | ✅ | ❌ | Avro、Delta、Iceberg、Parquet |
云对象存储 | Azure ADLS Gen2 | ✅ | ❌ | Avro、Delta、Iceberg、Parquet |
云对象存储 | Google Cloud Storage | ✅ | ❌ | Avro、Delta、Iceberg、Parquet |
同时文档重点强调了对Apache Iceberg开放表格式的原生深度支持,可直接对接AWS Glue、对象存储、Unity Catalog等Iceberg元数据目录,无缝对接企业已有的数据湖,无需数据搬迁。
四、虚拟表的支持工作流与能力边界
核心原则是:虚拟表可作为绝大多数核心工作流的输入,不支持的能力可通过「虚拟表→流水线→输出Foundry本地数据集」的方式100%补齐。
1. 原生支持的工作流
Foundry应用 | 支持的核心能力 |
|---|---|
数据连接 | 源系统配置、虚拟表的手动/自动注册 |
Contour | 直接基于虚拟表做交互式探索分析、可视化 |
Pipeline Builder | 作为流水线输入源;支持输出数据集/Ontology对象;支持快照搭建、仅追加模式的增量搭建 |
Code Repositories | 作为Python变换的输入源;支持快照搭建、仅追加模式的增量搭建,API和普通数据集完全一致 |
数据沿袭 | 查看虚拟表的上下游全链路血缘,满足合规审计要求 |
Ontology | 通过Pipeline Builder基于虚拟表创建Ontology对象,支撑业务应用 |
2. 明确不支持的能力
- 不支持基于代理的源连接,必须和源系统直连;
- 不支持流式搭建;
- Code Repositories中不支持Java变换、SQL变换;
- 不支持直接在Ontology Manager中基于虚拟表创建对象;
- Contour中不能直接把分析结果保存为虚拟表,只能输出为Foundry本地数据集。
3. 官方兜底兼容方案
哪怕虚拟表不支持某些能力,你只需以虚拟表为输入,搭建流水线,把查询结果输出为Foundry本地的物理数据集。输出后的数据集和普通数据集完全一致,支持Foundry所有能力(分支、版本控制、健康检查、调度等),兼顾了虚拟表的便捷性和本地数据集的全能力支持。
五、Code Repositories中使用虚拟表的前置要求
明确了在代码仓库中使用虚拟表的两个必须开启的前置配置,必须在对应的「数据连接」源设置中启用:
- 代码导入(Code imports):允许该源被导入到Code Repositories中使用,是基础开关;
- 导出控制(Export controls):配置哪些权限标记、组织可以在Python变换中使用该虚拟表,是安全合规管控开关。
一、先建立核心认知:这两个配置是「Code Repositories用虚拟表」的两道门
虚拟表默认可以在Contour里直接分析、在Pipeline Builder里当输入;但要在Code Repositories(代码仓库)的Python代码里用虚拟表,必须过两道安全门,这两个配置就是这两道门的开关:
第一道门:代码导入(Code imports) —— 「能不能连」的总开关,决定这个外部源(比如Snowflake)的数据,有没有资格被“引进”到Code Repositories里用;
第二道门:导出控制(Export controls) —— 「谁能用」的细粒度开关,决定Foundry里哪些人、哪些组织、哪些权限标记的用户,能在Python代码里真正用这个虚拟表的数据。
二、第一道门:代码导入(Code imports)—— 「能不能连」的总开关
核心含义
默认情况下,哪怕你在数据连接里建了100个虚拟表,Code Repositories里也是完全看不到、用不了这个源的任何虚拟表的。 代码导入,就是给这个外部源(比如你的Snowflake样例数据源)开一个「准入许可」:允许这个源被“导入”到Code Repositories的生态里,让代码仓库能识别、访问到这个源里的虚拟表。
Code Repositories = 你的「汽修厂核心维修车间」,你要在里面写Python代码做「配件需求预测」「维修工单智能分析」;
Snowflake里的虚拟表 = 「外部供应商的配件库存系统」「总部的全国维修工单数据库」;
代码导入开关 = 「车间的网络接入许可」:
不开这个开关:车间的电脑连不上供应商的库存系统,你写代码时根本找不到这个数据源;
开了这个开关:车间的网络通了,你写代码时才能看到、引用供应商的库存表、总部的工单表。
不开的后果
你在Code Repositories里写Python代码,用Input引用虚拟表路径时,系统会报错:找不到这个数据源,或者没有权限访问这个源。
三、第二道门:导出控制(Export controls)—— 「谁能用」的细粒度安全开关
先澄清一个名字误区
这里的“导出”,不是把数据导出到Foundry外面,而是指把外部源系统的数据,“导出/引入”到Foundry内部的Python变换代码里使用——因为要把外部数据拿到Foundry的代码里跑计算,必须做严格的安全管控,所以叫“导出控制”。
核心含义
开了第一道门(代码导入),只是让源能连进Code Repositories了;第二道门是管「谁能在代码里用这个数据」,通过两个维度做细粒度限制:
权限标记(Markings):你之前学过,Foundry可以给数据打安全标签(比如“机密”“内部公开”“仅财务可见”),这里可以配置:只有打了哪些安全标签的用户/项目,才能在代码里用这个虚拟表;
组织(Organization):配置Foundry里的哪些组织/部门(比如“财务组”“核心运营组”“普通维修站”),能在代码里用这个虚拟表。
假设你有两个敏感的虚拟表:
配件采购价格表(Snowflake里的虚拟表):只有财务组、你这个核心运营者能看,普通维修站的人绝对不能看;
全国维修工单表:内部公开,所有加盟维修站的技术负责人都能看。
导出控制开关 = 「车间的门禁卡权限」:
对于配件采购价格表:你在导出控制里只给「财务组」「核心运营组」开权限,普通维修站的人哪怕进了Code Repositories,写代码引用这个表时也会报错,看不到数据;
对于全国维修工单表:你在导出控制里给「所有加盟维修站」开权限,大家都能在代码里用这个表做分析。
为什么必须有这个开关?
这是企业级数据安全的核心要求:
避免敏感数据(比如采购成本、客户信息)被不该用的人在代码里随意访问、导出;
满足合规审计要求:谁在什么时候用了什么敏感数据,都有完整记录;
实现最小权限原则:只给真正需要的人开权限,其他人用不了。
四、两个配置的层级关系总结
配置 | 层级 | 核心作用 | 类比你的场景 |
|---|---|---|---|
代码导入(Code imports) | 源级别(总开关) | 允许这个外部源被Code Repositories识别、连接 | 给车间开“外部供应商系统的网络接入” |
导出控制(Export controls) | 数据级别(细粒度开关) | 限制哪些人/组织/标记能在Python代码里用这个源的虚拟表 | 给不同的人开不同的“车间门禁卡”,敏感区域只有特定人能进 |
五、结合你的Foundry操作,这两个配置在哪里开?
你之前学过,这两个配置必须在**「数据连接(Data connection)」应用的源设置里开**:
打开你连接Snowflake的那个数据连接;
进入源的设置页面(Connection settings);
找到「代码导入(Code imports)」开关,打开它;
找到「导出控制(Export controls)」配置项,添加允许使用的权限标记、组织;
保存配置后,你才能在Code Repositories的Python代码里正常引用这个源的虚拟表。
配置完成后,在代码中使用虚拟表的方式和普通数据集完全一致,示例如下:
from transforms.api import transform, Input, Output
# 虚拟表和普通数据集一样,直接用Input引入路径即可
@transform(
output=Output("/your/project/output_dataset"),
customer_virtual_table=Input("/your/project/CUSTOMER") # 虚拟表的Foundry路径
)
def compute(customer_virtual_table, output):
# 直接读取虚拟表的数据,API和普通数据集完全一致
df = customer_virtual_table.dataframe()
# 数据清洗、过滤等业务逻辑
active_customer_df = df.filter(df["is_active"] == True)
# 输出结果到Foundry本地数据集
output.write_dataframe(active_customer_df)六、虚拟表 vs 同步到Foundry数据集:官方选型指南
两种模式不是互斥的,而是可以结合使用、互为补充,核心选型原则是基于具体的业务工作流选择合适的集成模式。
1. 优先使用虚拟表的场景
- 超大规模表,存储成本敏感:PB级的历史数据表,重复存储成本过高,且访问频率不高;
- 数据实时性要求极高:需要查询源系统的最新数据,无法接受分钟/小时级的同步延迟;
- 临时探索分析、快速原型验证:临时需要分析源系统的表,不想等待全量同步,快速验证业务逻辑;
- 跨源联合查询:需要同时查询分散在多个不同源系统中的表,无需把所有数据都同步到Foundry。
2. 优先使用同步到Foundry数据集的场景
- 生产级核心流水线:需要稳定的性能、严格的版本控制、分支协作、故障回滚能力的生产流水线;
- 高频交互访问:业务分析师、BI报表需要频繁、低延迟访问的数据,本地数据集的性能更稳定可控;
- 源系统资源受限:源系统是生产业务库,无法承受频繁的查询压力,避免虚拟表的查询影响业务系统运行;
- 需要完整的平台能力:需要使用分支、版本控制、事务历史、健康检查、增量搭建等数据集专属能力的场景。
3. 官方推荐的最佳混合模式
企业级项目中最常用的是「虚拟表+同步数据集」的混合架构:
- 用虚拟表做快速的探索分析、原型验证,确认业务逻辑;
- 验证通过后,搭建流水线,把核心业务数据从虚拟表物化输出为Foundry本地数据集,用于生产流水线、BI报表;
- 低频访问的海量历史数据、实时性要求高的表,保留虚拟表模式,无需同步。
七、文档里的关键避坑规则
- 自动注册的表删除规则:源系统中删除表后,Foundry里的虚拟表不会自动删除,仅会在访问时无法加载数据,需要手动清理;
- 查询计算分配规则:虚拟表的查询计算会在Foundry和源系统之间分配,具体取决于源系统支持的下推能力,尽量把过滤、聚合逻辑下推到源系统,减少数据传输;
- 存储成本注意事项:虚拟表仅节省源数据的重复存储成本,下游流水线输出的数据集、Ontology对象,依然会占用Foundry的存储;
- 性能依赖:虚拟表的查询性能完全依赖外部源系统的处理能力和网络带宽,高频复杂查询可能会给源系统带来额外的计算压力。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号