OpenClaw 助力 fabless 芯片设计提速:内网部署,无需GPU
原创
OpenClaw 助力 fabless 芯片设计提速:内网部署,无需GPU
原创
Challensys
修改于 2026-04-06 17:10:40
修改于 2026-04-06 17:10:40
物理隔离挡不住 AI Agent 的火热,内网部署本地大模型实现“token 自由”:AI 加速芯片设计真的来了
Fabless 芯片设计环境的 AI Agent 部署特点
与很多互联网公司不同,fabless 芯片设计往往是在内网进行研发的。在物理隔离的内网中,服务器无法访问互联网上的 token 供应商,因此通常采用本地部署大模型来提供 token。
Fabless 芯片设计环境通常也包含了本地的服务器集群。在一些前沿的 fabless 部门,本地服务器上已经安装了足够数量的 GPU,此时可直接让大模型在本地 GPU 上跑。在更普遍的情况中,本地服务器集群中的 GPU 数量不足,此时也可以选择用 CPU 来跑本地大模型。
CPU vs GPU 跑大模型的速率差别
大模型的运行速度可从 Prefill 和 Generation 两个维度来描述。以 Qwen 3.5 35B A3B UD-Q4 模型的典型速率为例:
Prefill 是指大模型处理输入提示词的速率。对 OpenClaw 框架来说,其初始提示词就达到 11000 个 token 左右,随着对话的演进还会持续增加。GPU 处理 Prefill 的速率大概在 1000 token/s 以上,而服务器 CPU(核数较多时)处理 Prefill 的速率只在 50 token/s 的量级。新硬件往往对 Prefill 有更大的加速效果,比如苹果 M5 的 Prefill 速度可达到 M4 的 3-4 倍。
Generation 是指大模型开始输出首字符之后的输出速率。使用 GPU 时 Generation 的速率大概在 50 token/s 以上,而服务器 CPU 在 Generation 阶段的输出速率往往低于 10 token/s。
从整体来看,使用 CPU 跑大模型会比 GPU 慢十几倍。特别是对 OpenClaw 的 11000 token 初始提示词的处理,CPU 跑 Prefill 通常就需要耗费 4 分钟左右,OpenClaw 聊天对话框的第一个回复会显得格外的慢。
但由于 KV Cache 的存在,多轮对话中可以用复用之前的 Prefill 运算结果,纯 CPU 跑 OpenClaw 从对话的第二轮开始就不会卡那么久了。
虽然 CPU 跑大模型比 GPU 慢十几倍,但用 CPU 跑至少解决了“能用”的问题。而且只要 OpenClaw 完成任务比人工更快,比如写一段脚本 GPU 需要 3 分钟、CPU 需要 30 分钟,而人工需要 2 小时,那用 CPU 跑也是有其价值的。毕竟芯片设计工程师已习惯了动辄几小时的 EDA 工具运行时间,没必要一定去追求几分钟就出结果的 GPU 速度。
量化模型的选择
不同的量化方法对精度的损失影响很大。很多文章中推荐的 Q4_K_M 量化在处理芯片设计任务时很可能结果欠佳,比如让 AI 编写 SDC 约束时可能出现更多的命令幻觉和开关幻觉。根据实测结果,芯片设计的 AI Agent 更适合使用 UD_Q4_K_XL 量化,其 Unsloth Dynamic 量化方法相比普通的 4 位量化具有更高的精度。
CPU 跑本地大模型 + OpenClaw 的特别注意事项
截至发稿时,Github Issue #46049 的 Prefill 1 分钟超时问题仍未得到修复。纯 CPU 跑大模型时,处理第一轮对话的 11000 token 需要耗费 4 分钟左右,几乎必然会遇到这个问题。当触发这个问题时,OpenClaw 对话框会卡住不回复,而 llama.server 的 Log 则会显示其处于 cancel-idle 的状态。
根据实测,修改 json 配置往往不太凑效,可以通过全局 javascipt 劫持来 workaround 这个超时问题。
OpenClaw 加速芯片设计:实际效果
我们尝试在内网服务器 CPU 开 32 核,让 OpenClaw 帮我们编写 STA 报告的后处理脚本:
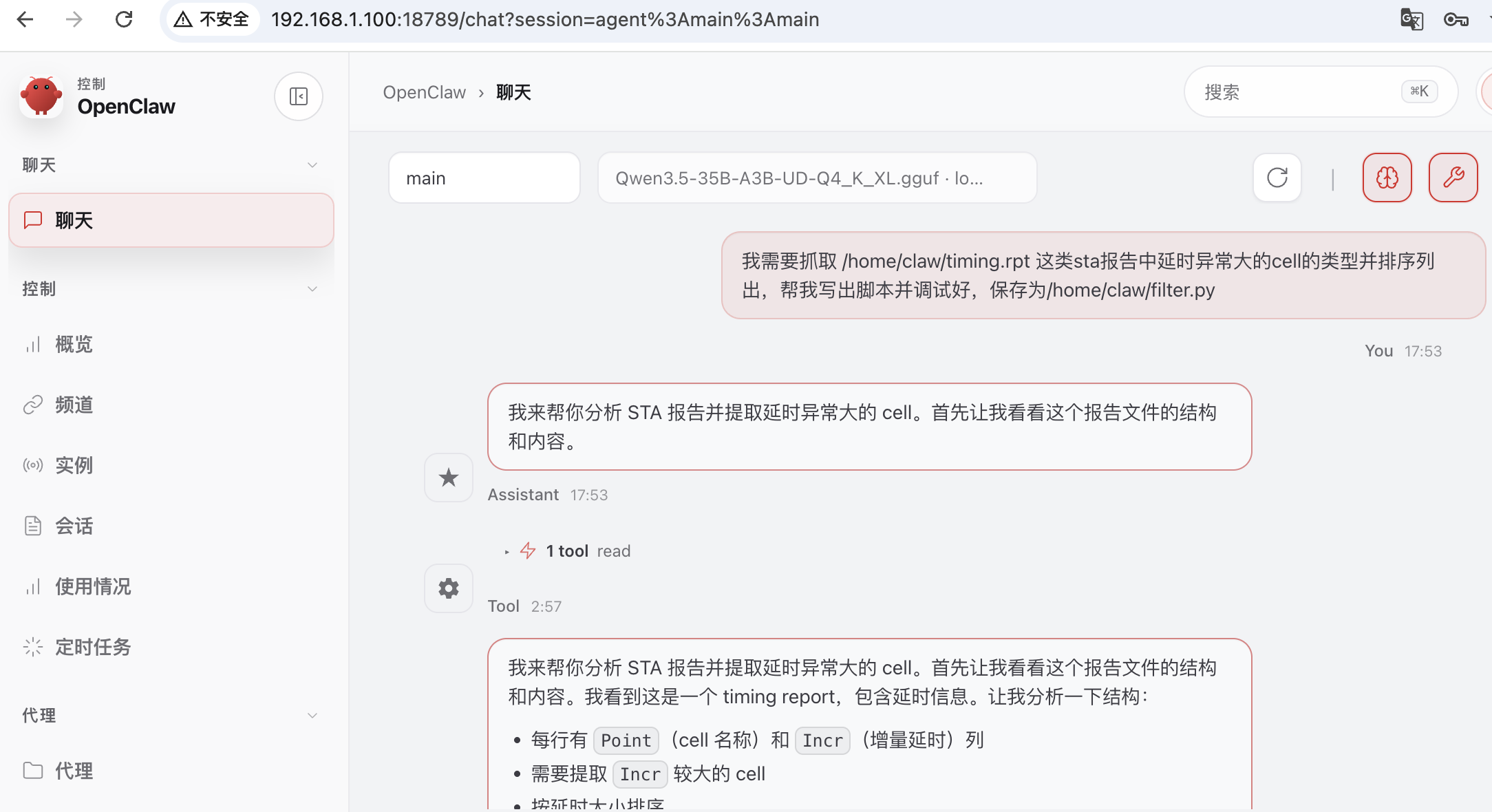
内网部署OpenClaw编写STA报告后处理脚本
试运行 OpenClaw 写好的脚本:
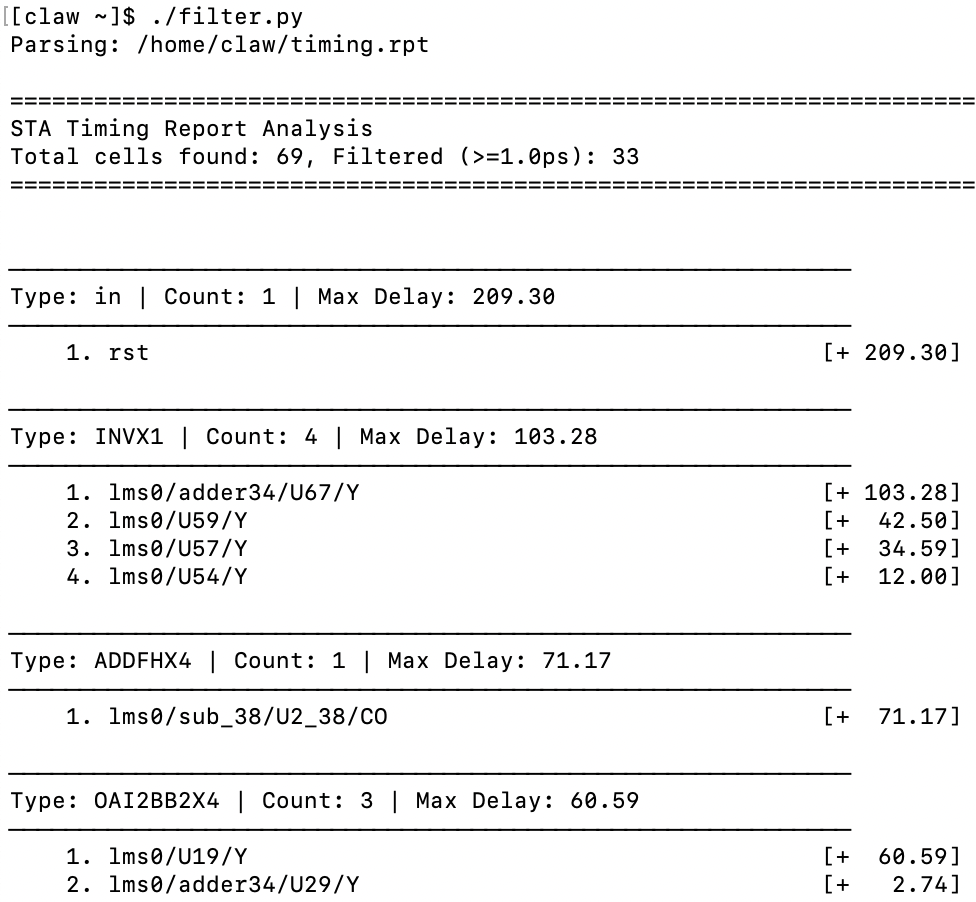
OpenClaw编写的STA后处理脚本运行效果
OpenClaw 内网部署方法
由于 OpenClaw 高度依赖于 npm,实际上只能采取同操作系统下,外网装好拷进内网的方法进行安装部署。
为方便大家在芯片设计的内网部署 OpenClaw,轻思科技提供了内网纯 CPU 大模型的 OpenClaw 预编译安装包,它可以支持:
- RHEL7/8 / CentOS7 / Rocky8 系统
- 解压可用
- 删除即卸载
- Prefill 超时 Patch 到 10 分钟(独家提供)
- 内网运行
- 纯 CPU 运行
目前可以通过我们的公众号获得安装包的下载链接。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号