白话Vision Transformer(ViT)的原理解析


Vision Transformer(ViT)是Transformer架构从自然语言处理跨界到计算机视觉的标志性成果,证明了“不需要卷积,纯Transformer也能在图像任务上取得顶级表现”。下面我为你系统拆解它的原理、价值和局限。
1
ViT是什么?
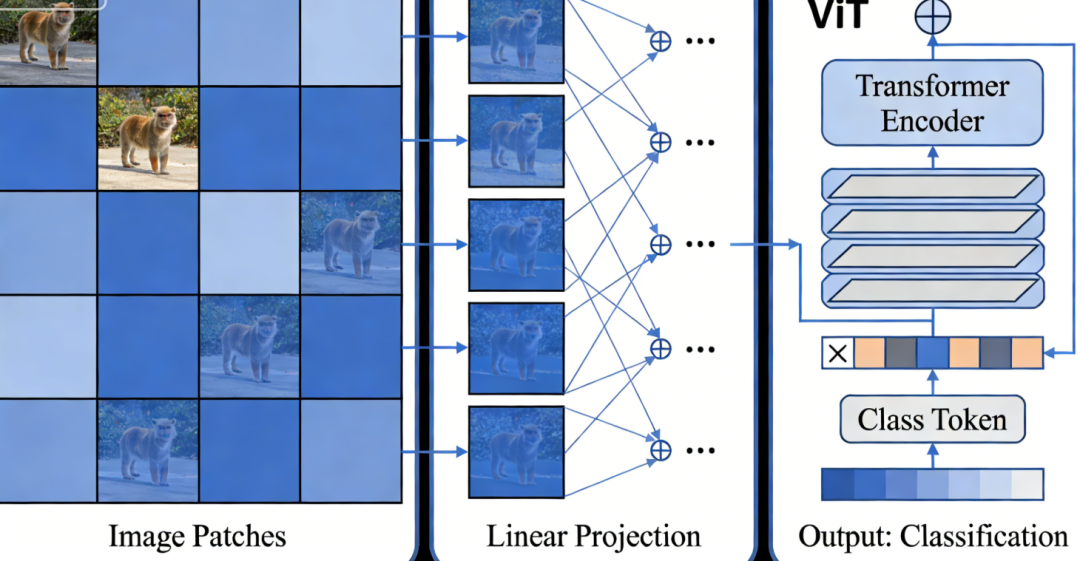
一句话定义 :ViT是一种将图像视为“序列”来处理,完全基于Transformer编码器进行图像分类的模型。
核心思想 :把一张图像切分成一个个固定大小的图像块(Patch),将这些块像句子中的单词一样排列成序列,然后输入到标准的Transformer编码器中。
在ViT出现之前,计算机视觉领域几乎被CNN统治。ViT的出现打破了这个局面,证明了Transformer凭借其强大的全局建模能力,同样可以成为视觉任务的基础架构。
2
ViT的原理
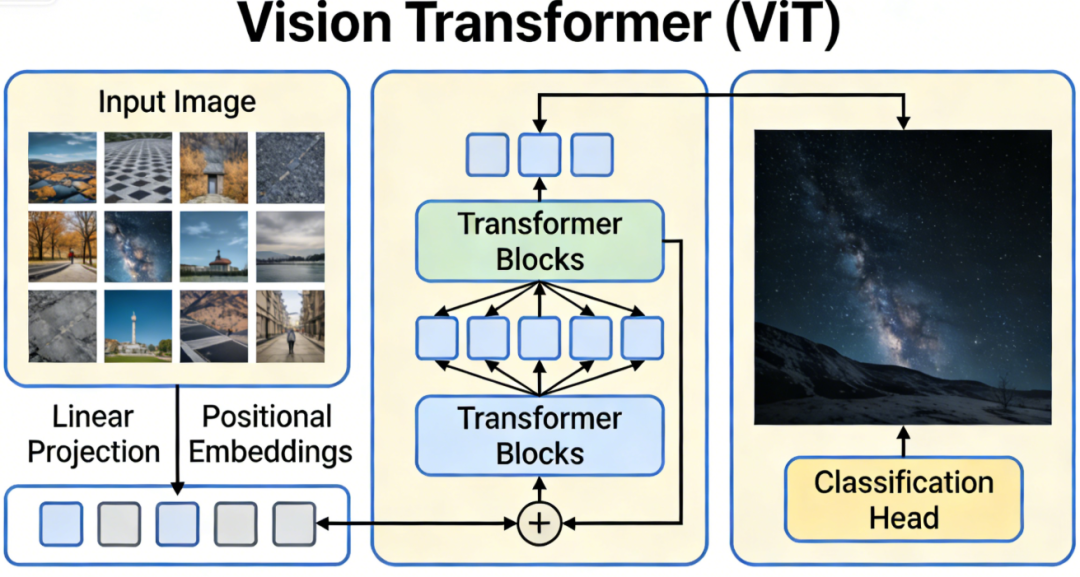
ViT的处理流程可以清晰地分为五个步骤,也是它区别于CNN的关键所在。
1. 图像分块
ViT不直接处理像素,而是将图像分割成一个个固定大小的“视觉单词”。例如,对于 一张 224×224 的图像,以 16×16 的块大小切分,就会得到 224/16×224/16=14×14=196个图像块。每个块的尺寸是 16×16×3(3是RGB通道)。
这一操作相当于将图像从 H×W×C的张量,转化为一个长度为 N(块的数量)的序列,序列中每个元素就是一个图像块。
2. 线性投影
在NLP中,每个单词会通过一个嵌入矩阵变成向量,ViT同样为每个图像块学习一个线性映射,将其展平后的像素值向 量(长度为 16×16×3=768)映射到一个 D 维的向量空间。这个 D 就是Transformer
模型内部的维度(如768或1024),这一步相当于为每个“视觉单词”生成了其初始的词向量。
3. 添加位置编码
和Transformer处理文本一样,ViT本身也无法感知图像块的顺序(哪个块在上、在下、在左、在右)。因此,必须为每个图像块添加位置编码。ViT使用 可学习的1D位置编码 , 为 N 个位置(加上一个特殊的 [CLS]标记)各学习一个位置向量,并与图像块的嵌入向量相加。
一个关键问题 :为什么ViT不用2D位置编码?实验表明,1D位置编码已经足够好,因为Transformer的自注意力机制有能力从数据中隐式地学习到空间结构。
4. 添加
[CLS]标记并送入Transformer编码器ViT完全复用了BERT的设计,在序列的最前面添加一个特殊的可学习向量 [CLS],整个序列([CLS] + 所有图像块)输入到标准的Transformer编码器中。经过多层编码器处理后,[CLS] 位置的输出向量(记为zL0)被设计用来聚合整个图像的信息,作为图像的最终表示,用于分类。
5. 分类输出
最后, 只需在 [CLS] 向量后接一个分类头(通常是一个多层感知机MLP),就能输出最终的分类结果。
3
ViT的作用
1. 核心应用
- 图像分类 :这是ViT的主战场,在ImageNet等大规模数据集上,ViT可以超越ResNet等最先进的CNN。
- 作为视觉骨干网络 :ViT可以取代CNN,作为目标检测(如ViT-FRCNN、DETR)、语义分割(如SETR)等下游任务的骨干网络。
- 多模态模型的基础 :ViT是CLIP、Flamingo等图文多模态模型的图像编码器,是实现图文跨模态理解的核心组件。
- 自监督学习 :MAE(Masked Autoencoders)等自监督方法以ViT为骨架,通过重建被遮挡的图像块来学习强大的视觉表征。
2. ViT相较于CNN的优势
特性 | CNN | ViT | 为什么ViT有优势 |
|---|---|---|---|
感受野 | 局部,随层数增加而扩大 | 全局,第一层即可看见整张图 | ViT能直接捕捉长距离依赖,更容易理解全局结构 |
归纳偏置 | 强(平移不变性、局部性) | 弱(需要从数据中学习空间结构) | 当数据量足够大时,弱归纳偏置让模型更灵活,性能上限更高 |
扩展性 | 性能提升逐渐饱和 | 模型越大、数据越多,性能提升越明显 | ViT表现出更强的“规模效应”,更适合超大模型和大数据 |
架构统一 | 与NLP架构不同 | 与Transformer一致 | 便于构建多模态模型,实现视觉与语言的统一处理 |
3. ViT的局限性
- 需要大量数据 :在小数据集上(如CIFAR-10),ViT的表现不如同等规模的CNN,因为它缺乏CNN固有的归纳偏置。
- 计算复杂度高 :自注 意力的复杂度是 O(N2),其中 N 是图像块的数量。对于高分辨率图像,这个计算开销会非常大。
- 位置编码 :目前主流ViT使用绝对位置编码,对于训练时未见过的高分辨率图像,位置编码可能无法很好地泛化。
4
在机器人项目中的应用
应用方向 | 说明 |
|---|---|
强视觉骨干 | 如果机器人需要处理复杂的视觉环境(如识别杂乱桌面上的特定物体),ViT的全局感受野可能优于CNN。 |
多模态交互 | 结合CLIP等模型,机器人可以利用ViT将视觉内容与语言指令对齐,实现“把那个蓝色的方块递给我”这类精细操作。 |
自监督学习 | 通过MAE等方式,可以利用大量无标注的机器人摄像头数据预训练ViT,减少人工标注成本。 |
实时性考量 | ViT的计算量较大,在Jetson等边缘设备上直接部署可能困难,但可以考虑轻量化ViT变体(如MobileViT、Swin Transformer的移位窗口策略)或部署在云端。 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号