一文看懂PCIe中断

一文看懂PCIe中断

FPGA技术江湖
发布于 2026-03-23 21:24:10
发布于 2026-03-23 21:24:10
前言
PCIe 中断机制主要分为两类:一类是继承自传统 PCI 的 物理中断线(INTx)中断,通过硬件引脚触发;另一类是 MSI(Message Signaled Interrupt)中断,通过向指定内存地址写入数据来通知系统。 很多人可能会好奇:为什么现代系统逐渐淘汰了传统中断?MSI 相比之下究竟有哪些优势?本文将带你逐一揭开这些问题的答案。
传统PCI中断
虚拟边带信号
在老式的 PCI 插槽上,主板是真的有四根物理信号线连着设备的,分别叫 INTA,INTB,INTC,INTD。
image
image
但是 PCIe 变成了串行的高速差分线,早就没有这四根物理引脚了。那老驱动怎么用呢?
报文模拟
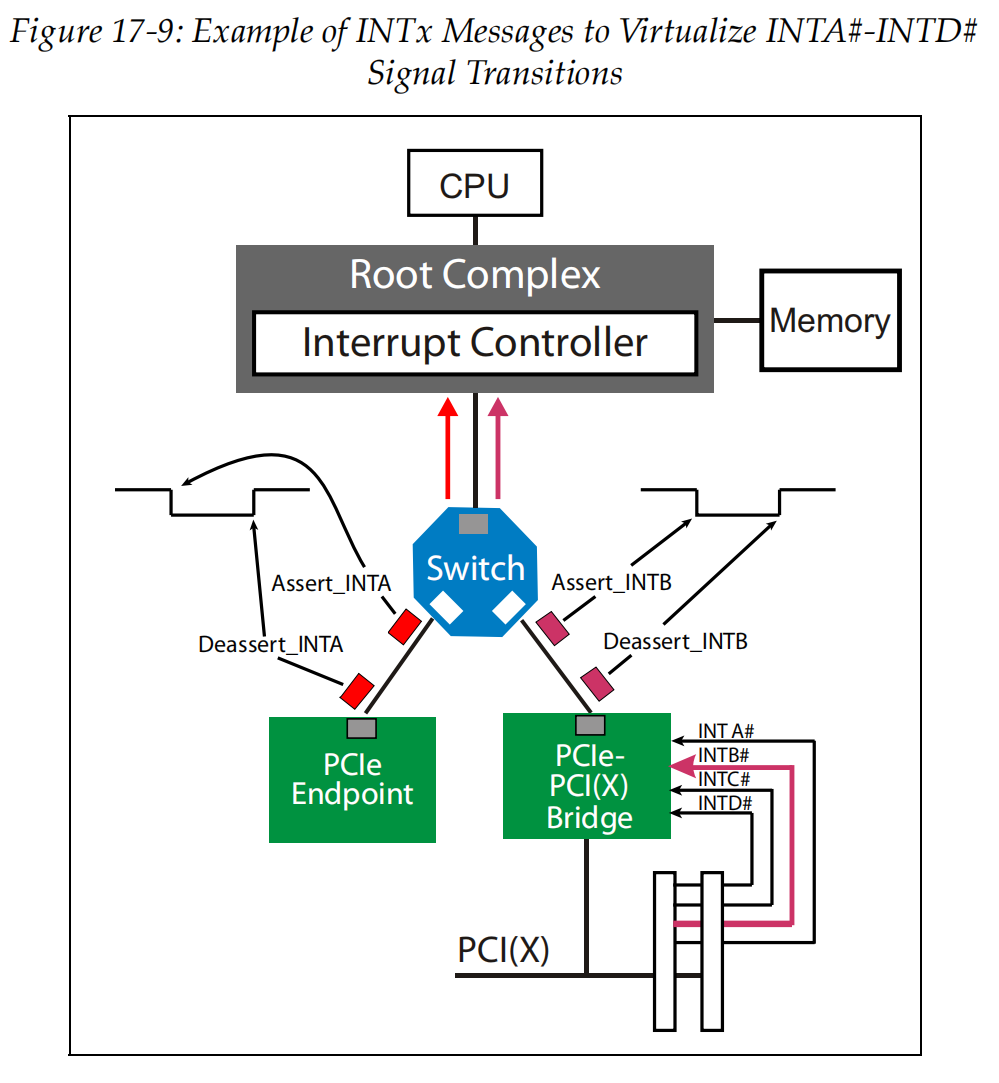
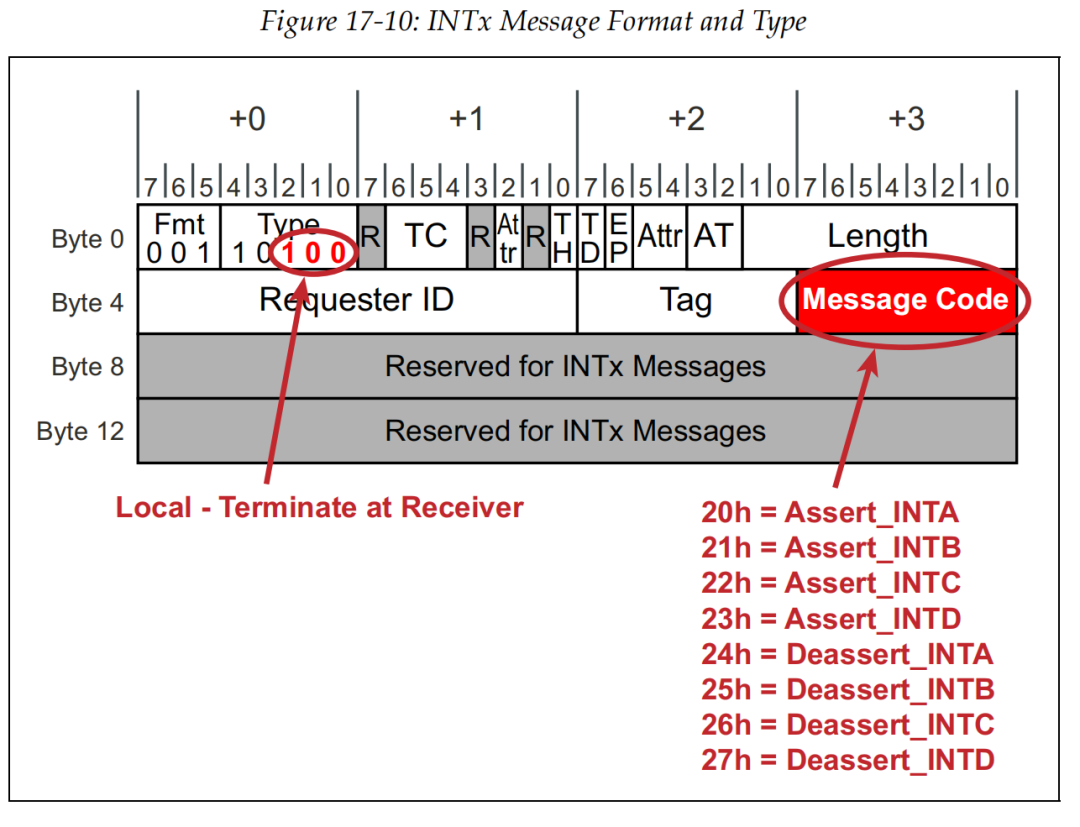
PCIe 规范发明了消息报文 (Message TLP) 来驱动 INTx 中断线产生中断。
image
image
电平模拟
物理线的电平有拉高和拉低。所以在 TLP 报文里,必须成对发送。
当你的设备想发中断时,硬件逻辑组装一个 Assert_INTA (消息码 20h) 的报文发出去,告诉主机我把线拉低了。
当主机处理完中断后,你的硬件逻辑必须再发一个 Deassert_INTA (消息码 24h) 的报文,告诉主机我把线松开了。如果忘了发 Deassert,系统就会一直被中断卡死。
image
image
配置空间
在 PCIe Header 的配置空间里有两个寄存器,Interrupt Pin (中断引脚) 和 Interrupt Line (中断线) ,这两个配置空间里的寄存器仅仅是为传统中断 (Legacy INTx) 服务的。
Interrupt Pin (中断引脚)
这是硬件管的。
它是由 Device 这一侧在初始化 IP 的时候配置好的。比如写 1 代表用 INTA,写 2 代表 INTB。
如果是 Xilinx 7 系列的 PCIe IP,并且是 Single Function(单功能设备),那么它只支持 INTA。所以你在配置 IP 时这个值通常写死为 1。
Interrupt Line (中断线)
这是软件的草稿纸。
它是一个 8bit (0~255) 的寄存器,里面存的是系统的 irq 编号。
这个编号是上位机软件(OS)根据系统中断路由分配后,通过 RC 下发配置包写进来的。
对于底层硬件设备来说,这个值完全没有用,它只是给上层软件驱动层留的一个存储位置,方便驱动程序自己去读,甚至发出去的 TLP 包里也根本不需要带这个值。
INTX的困境
INTx 实在太慢、太难用了。它不仅需要来回发 Assert/Deassert 两次报文,而且 4 根线常常需要和主板上的其他设备共享,导致 CPU 每次收到中断还得挨个去查到底是哪个设备触发的。
如果是做网卡这种需要处理海量网络高并发数据的芯片,如果用 INTx,系统性能直接就崩溃了。现代的网卡设计,起步就是MSI,或者是支持成千上万个中断向量的 MSI-X。
现代PCIe中断
用写内存代替拉信号线
在 MSI 机制下,你的芯片不再需要去拉扯虚拟的信号线(像 INTx 发送 Assert/Deassert 报文那样)。
当设备需要触发 CPU 中断时,它直接往一条特定的总线地址发送一个 Memory Write TLP (内存写报文) 。
就像送快递。INTx 是你在楼下按门铃大喊有快递,CPU 得自己下楼看是谁的;而 MSI 则是你直接把写着你名字的包裹塞进 CPU 指定的专属信箱里。
MSI Capability 结构
既然是往特定地址写特定数据,那这个地址和数据怎么来呢?这就要靠配置空间里的 MSI Capability Register 了。
在系统启动枚举 PCIe 设备时,操作系统和你的硬件会这样配合

image
image
Message Address (消息地址)
软件(驱动)在系统的内存空间(通常是 CPU 的 APIC 中断控制器映射的一段空间)里申请好一个专属地址,然后把这个地址写入你配置空间里的 Message Address 寄存器。如果系统是 64 位的,就会用到带 Message Upper Address 的 64-bit 结构。
Message Data (消息数据)
这是一串特定格式的数据包。不同的 CPU 架构对这个数据格式有不同的定义,内核可以通过 API 获取,填入这个寄存器,为了让 CPU 能区分到底是哪个具体的向量触发了中断,PCIe 硬件在发送报文时,会动态地把向量的编号(0~31)作为偏移量,加到这个基准 Message Data 的低位上。
当你网卡的某个业务模块(比如收到一个网络包)产生中断请求时,你的 PCIe MAC/应用层逻辑,就会去读取这两个寄存器里的 Address 和 Data,把它们拼成一个 Memory Write TLP,直接发给 Host。
Mask & Pending

image
image
既然 MSI 支持了多达 32 个 Vector,那自然就需要一个 32 bit 的 Mask Bits 来让软件挨个控制这 32 个中断源谁该静音,以及一个 32 bit 的 Pending Bits 让硬件挨个记录谁在静音期间举手了。为了不让 CPU 被海量的中断请求淹没,PCIe 规范定义了这套 Mask(屏蔽)和 Pending(挂起)的机制。
我们可以从控制权和工作流的角度,把这两个寄存器的作用拆解得清清楚楚:
Mask Bits (屏蔽位)
他是软件的静音键
谁来控制: 由上层软件 (OS / 设备驱动) 负责读写。
有什么用: MSI 模式最多支持 32 个中断向量 (Vector),这里的 Mask Bits 恰好是 32 bit,每一位对应一个向量的掩码。当软件把某一位写为 1 时,就表示屏蔽 (Mask) 对应的中断向量。
实际场景: 比如 CPU 现在正在处理一段非常关键的代码,或者正在批量处理网卡刚刚收上来的网络包,不想被打扰。驱动程序就会把对应的 Mask Bit 置为 1。这时候,你的网卡硬件就算有天大的事,也不能往主机发那个中断 TLP。
Pending Bits (挂起/未决位)
他是硬件的未接来电记录
谁来控制: 由你的硬件 (DPU 的 RTL 逻辑) 负责置位 (Set) 和清零 (Clear)。软件只能读,不能写。
有什么用: 它是用于挂起中断的标志。如果在 Mask Bit 被置 1 (静音) 的这段时间里,你的 DPU 内部刚好产生了一个中断请求,因为被静音了发不出去,你的硬件逻辑就会把对应的 Pending Bit 拉高。
实际场景: 这相当于给 CPU 留了一个“未接来电”。它保证了在软件屏蔽中断的期间,硬件产生的新中断不会丢失。
系统设计的联动过程
在系统设计中,处理这两个寄存器的联动逻辑通常是这样的:
正常情况 (Mask = 0): 硬件产生中断请求 -> 检查对应的 Mask Bit 为 0 -> 直接组装一个 Memory Write TLP (即 MSI 报文) 发给主机 -> Pending Bit 保持 0。
屏蔽情况 (Mask = 1): 硬件产生中断请求 -> 检查对应的 Mask Bit 为 1 -> 阻断 TLP 的发送 -> 将对应的 Pending Bit 置为 1。
解除屏蔽 (Mask 1 -> 0): 软件忙完了,决定放开中断,通过读取Peding寄存器知道设置掩码时挂起了一个中断请求。软件在合理时机清除 Mask Bits,你的硬件逻辑检测到 Mask Bit 从 1 变 0,且对应的 Pending Bit 为 1,就会立刻发送积压的 MSI 报文,并同时把 Pending Bit 清零。
MSI的最大优势
MSI 有个巨大的优点:它支持多达 32 个配置的 vector (向量) 。
INTx 因为只有 4 根线,经常几个设备共用一根,CPU 收到中断后还得一个个问 是你叫我吗?。
32 个 vector 意味着你的网卡可以分配 32 个完全独立的中断源。
比如:你可以让 Vector 0 专管网口 0 的接收,Vector 1 管网口 0 的发送,Vector 2 管错误报警
硬件发 MSI TLP 时,会根据具体的业务,把对应的 Vector 编号(0~31)动态叠加到前面软件配好的 Message Data 的低位里。CPU 收到报文,瞬间就能精准定位是网卡的哪个队列触发了中断。
MSI-X
刚才聊了 MSI 最多只能支持 32 个 Vector。对于一块普通的网卡可能够了,但对于动辄几百上千个网络队列(Queue)并发的智能网卡来说,32 个中断源简直是杯水车薪。
MSI-X 作为升级版,每个 Function 支持的 Vector 数量直接飙升到了 2048 个。这意味着你的网卡逻辑可以为每一个独立的业务队列分配一个专属的中断通道,彻底告别中断拥挤。
MSI 只支持一个 MSI address。回忆一下刚才 MSI 的配置空间,系统只分配了一个基地址(Message Address)。如果设备要发不同的中断,只能去修改数据包(Message Data)的低位来区分 Vector。
这导致所有的中断报文最终都挤向了同一个内存地址(通常对应 CPU 的同一个处理节点)。
MSI-X 可以支持多个 address。在 MSI-X 的架构中,不再把地址写在配置空间里了,而是直接在你的芯片内部(通常是 BAR 空间)开辟一块专门的内存区域,叫做 MSI-X Table。在这张表里,你可以为这 2048 个 Vector 中的每一个,都单独配置独立的 Address 和 Data。
MSI-X 最大的实战价值是对于多核CPU可以均衡地分配资源。
在服务器环境里,CPU 都是几十上百核的。 如果用 MSI(单地址),网卡几百个队列产生的中断全都会砸到同一个 CPU 核心上,导致这个核心忙死(100% 负载),而其他核心闲死,网络吞吐量直接卡住。 用了 MSI-X(多地址),系统软件就可以在 MSI-X Table 里,把 Vector 0 的地址配给 CPU 核 1,把 Vector 1 的地址配给 CPU 核 2……以此类推。这样网卡的硬件并发就能完美映射到 CPU 的多核并发上,真正实现性能的起飞。
写在最后
PCIe 中断机制的发展,本质上是一条非常典型的工程演进路径——从兼容历史 到 追求性能 再到 面向并行扩展
INTx 诞生在一个设备数量少、并发需求低的时代,它解决的是 能不能通知 CPU这个最基础的问题。而当系统进入高速网络、NVMe 存储、多队列 DMA 的时代,中断不再只是通知机制,而是系统性能链路中的关键一环。
这时,MSI 用一次内存写入替代信号线拉扯,让中断从 共享广播 变成 精准投递;再往后,MSI-X 进一步把中断从 可区分 升级为 可扩展,让硬件并行度能够真正映射到多核 CPU 架构上。
而这,正是 PCIe 体系最核心的设计哲学之一:让数据更快地流动,让事件更精准地到达,让并行真正发挥价值。
END
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号